
J,网易游戏高级开发工程师,负责智能运维的算法和工程开发。
21 世纪的今天,我们已经离不开各式各样的游戏,网站和软件。这些服务的背后,是一个又一个的服务器,运行着形形色色的程序。这些服务器只不过是普通的电脑,他们也有普通电脑的烦恼,例如内存泄露,磁盘满了和系统出错等。就算服务器本身没有出问题,服务器里运行的程序,也是会出故障的。
想象一下,你在火车上吃着火锅,唱着歌,突然间游戏的服务器崩溃了,并且长时间都没有恢复,你可能会气得再也不玩这游戏了。现实中服务器总是会出现未知的故障,我们无法完全避免这样的情况,所以运营维护,是提供稳定服务的重要基础。

运营维护中,我们为了检测服务器的故障,会记录下很多的指标来帮助我们识别服务器的异常,例如游戏的在线人数,服务器的 CPU 占用率,内存占用率,磁盘占用率,磁盘写入速度等。
这些指标所提供的信息,可以在很大程度上帮助我们识别我们提供的服务是否还在正常状态。但是大量的服务器和指标是无法靠纯人工进行检测的,所以我们借助了电脑程序来进行自动化的异常检测。
异常检测可以利用程序检测大量的指标,例如 CPU 暴增,内存暴增,内存占用比例超过了一定的数值等单一指标的规则,来检测服务器是否出现了异常。但是这些检测只能应对简单的情况,很多的异常并不能准确地被检查出来,例如在线人数的来回小幅度抖动,并不会触发在线人数暴增或者爆减的条件检测,但是这可能是潜在的服务器异常造成的。
再者,简单的规则,并不能应用到所有的场景,而同一个指标可能由于服务的切换造成场景更改,规则就变得不再适用,用专业的术语来说就是没有泛化性。这样的异常检测需要花费大量人工来适配大量场景,得到的检测结果也没有特别好。
在 2019 年的今天,我们早已进入了机器学习的时代,那么异常检测能不能搭上机器学习的顺风车呢?事实上,把机器学习和运维结合起来是近几年的事情,这是一片没有怎么开发的疆土,有能力把机器学习和运维结合起来的公司并不多。那么机器学习为什么能应用到运维上呢,和传统的运维相比又有什么优势呢?

传统规则的异常检测,需要由对业务非常了解的专家来制定规则,这些规则往往是单个规则,或者寥寥几个规则结合定义异常。超高维度的规则需要考虑的情况非常多,人类并不具有精准处理高纬度规则的能力。相反,只要有足够多的准确标注的数据,机器学习模型可以轻易地在高纬度组合各种规则精准分类数据,不需要开发者对业务有绝对充足的经验。

在传统规则的异常检测里面,需要考虑不同的场景制定不同的规则,并且在场景更换的时候需要手动匹配或者制定新的规则,维护成本非常高。相反,单一的机器学习模型可以灵活识别出不同场景的异常,轻易地适应场景的变换,在长期维护中只需要少量人力便可以更新迭代,优化模型。为什么机器学习可以实现低成本的异常检测?机器学习到底有什么特点?

机器学习的模型和传统的数学模型不同,机器学习是一种仅依赖数据的特性,而不根据特定的规则来构建模型的方法。意味着,只要我们有足够多,足够好的数据,便可以让模型学习到数据的规律,自动生成一系列的规则来建立数学模型。
我们可以使用非常多的特征去描述数据,模型自动根据特征来划分匹配正常和异常数据。相比于人类经验构建规则,机器学习的模型可以在更高维度上解决问题。最重要的是,只要数据标注得当,不需要非常多的业务知识也可以实现高准确率的模型。只要数据充足,同一个模型可以精准检测不同场景的异常检测。
那么在 AIOps 中,什么样的数据会被标注为异常呢?
一种通俗的认知是,如果今天的数据和昨天的同一时段的数据不一致,同时和上一周的同一时段的数据也不一致,那么这个数据就是异常数据。
可以确定的是,这个定义十分不清晰
同一时段是多长时间呢?
不一致的表现又是什么呢?
对于上面这两个问题,业界并没有一个准确的答案,这无形中为异常检测带来了很大的难度。在实际的操作中,我们对异常数据的定义并没有非常清晰,只能不断通过和业务沟通来获得较为贴近业务认知的答案。有时候为了保证异常检测报警的精准度,我们只能漏掉一部分不明确的潜在异常,以免异常检测报警错误率过高,导致业务信任度下降。
下图为一个骤降的异常:
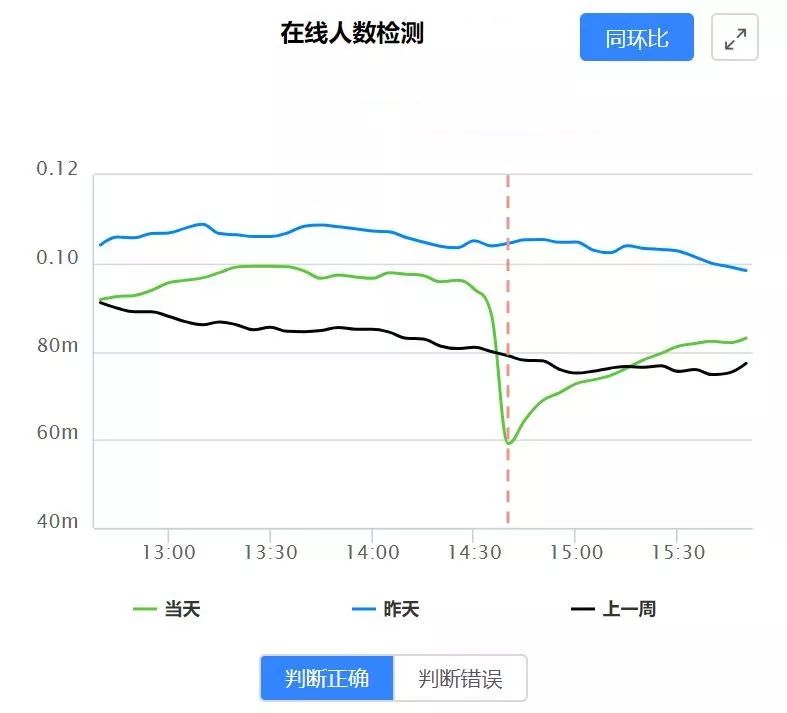
根据我们的经验,我们的异常检测模型使用了以下特征以及他们的变形:
差分
偏度
锋度
标准差
方差
波动性
移动平均
预测特征
分类特征
拟合特征
高通滤波
小波特征
周期差值对比特征
周期比例对比特征
统计特征
根据这些特征,和准确标注的数据,模型能够准确区分不同的场景下的异常,而根据模型实际运行状况,我们只需要往数据库里面加入样本点,便可以优化模型,逐渐贴近业务需求。
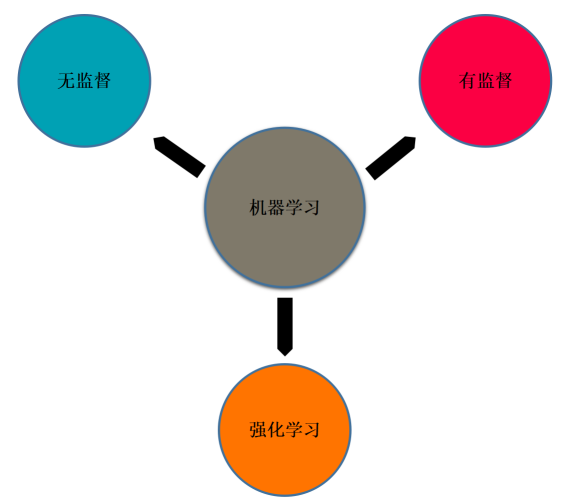
在机器学习的领域中,存在着三种模型,有监督模型,无监督模型和强化学习模型。首先排除强化学习模型,因为从理论上强化学习不适合处理异常检测的问题。无监督和有监督模型中,无监督模型因为其简单易用,具有比较强的解释性,而被广泛应用。
在无监督异常检测中,我们使用了两种模型。
Three sigma rule:

Isolation Forest:

从我们的测试效果来看,无监督模型可以快速且低成本地找出异常点,但是这些异常点并不一定是业务想要的异常点。如下图,实际上我们检测的曲线并没有发生异常,无监督异常检测模型报警是因为今天的值高于昨天值和上周的值,但业务方并不认为这是异常。
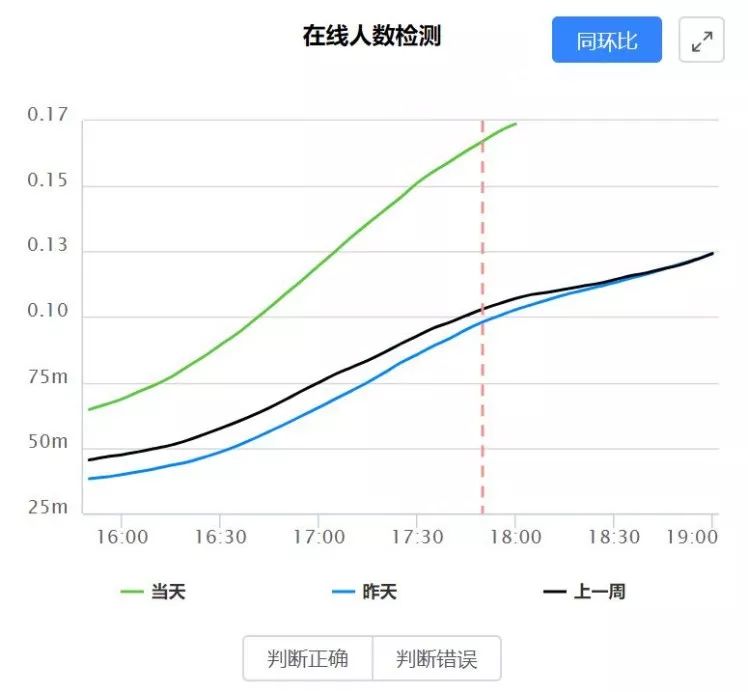
为了可以更加贴合业务的需求,我们需要谨慎地修改无监督建模的特征和参数,但结果并不一定往我们预期的方向改进。根本原因是我们遇到的业务问题并没有和模型本身产生一个正反馈的闭环。这是由于无监督模型的特性,根据人类经验修改特征和模型参数,很难直接更改业务要求的特定数据的预测结果。
因为上述原因,我们采用了拥有完整数据闭环的有监督集成模型,为了使模型更加稳定,我们采用了集成模型,模型包括
XGBoost
Random Forest
GBDT
SVM
Logistic Regression
用有监督模型,我们可以在误报漏报的时候,往样本库添加误报漏报的样本。有监督模型在学习到了误报漏报的样本后,可以针对指定类型的样本修改模型。每一次的迭代都让模型往我们预期的方向优化,这样一来,业务的需求便得到最及时的反馈。
我们的有监督建模流程如下图:

1、抽样下载曲线数据
我们可以接触到巨量的监控数据,但处理所有的数据是不太现实的,我们要做的第一步就是从监控数据里面随机抽取出人类能处理的数量。
2、人工根据曲线类型去重
抽样下载的曲线类型重复率很高,我们从里面找出尽量多的曲线类型,每一种类型取 10 条曲线左右作为曲线样本。
3、数据预处理
数据里面的缺失值需要被替换成有效值,然后在进行归一化标准化后,分割成今天,昨天,上周数据,以便后面的特征计算。
4、根据isolation forest结果分层抽样
Isolation forest 可以给曲线的每一个样本点预测一个异常得分,我们可以根据这个值进行划分,并从每一层进行抽样,这样可以较为均匀地抽出不同类型的异常和非异常点,减少人工标注时间。
5、把抽样人工分类成异常和非异常
Isolation forest 检测出来的异常并不一定是业务认为的异常,所以人工根据 isolation forest 的结果,结合业务需求进行标注是非常重要的。
6、有监督样本库
有监督样本库储存着带有标记的正常和异常样本,后续优化和维护只需要增加或者删减数据库里的数据,便可以实现模型修改迭代。
7、计算特征
为了方便后续更改特征,以及减少样本库储存所需空间,特征是在训练模型之前,实时计算的。
8、训练模型
单一模型的结果在某些时候会变得不可靠,为了让结果更加稳定,我们结合了多种模型,集合了多种模型的结果做异常检测。
9、异常可视化
为了给异常做可视化,我们做了一个网站来显示今天,昨天和上周的数据对比。业务可以根据看到异常的数据,并且快速判断是否为真的异常。
10、人工筛选并下载误报漏报数据
根据业务的反馈和我们的经验,我们可以筛选出误报漏报的数据,把误报漏报数据加入到样本库,快速响应业务需求,对我们的模型进行优化。
在异常检测中,基于机器学习的异常检测相对于人工规则检测,有着以下的优势:
更低的开发和维护成本
更高的精准度
更好的泛化性
更好的自动化
在模型选择上,尽管有监督的标注成本会很高,有监督模型比无监督模型更加容易贴近业务需求,在后期的更新迭代中占有了绝对的优势。
一个成熟的异常检测系统,应该配备着一个和业务衔接的闭环,这些也是人工规则和无监督模型所不具备的。在模型建立和迭代的过程中,免不了一定的人工,我们曾经尝试过很多的自动化流程,但是增益效果并不大,甚至有些起了反效果。
经验告诉我们,不断将漏报误报加入样本库中,是优化模型最好的方法。我们的有监督集成异常检测模型,为 10 万多条曲线提供了高达 85% 精准度的全自动异常检测,为异常检测提供了一个全新的维度。
活动推荐
2020年4月17日,北京,Gdevops全球敏捷运维峰会将开启年度首站!重点围绕数据库、智慧运维、Fintech金融科技领域,携手阿里、腾讯、蚂蚁金服、中国银行、平安银行、中邮消费金融、中国农业银行、中国民生银行、中国联通大数据、浙江移动、新炬网络等技术代表,展望云时代下数据库发展趋势、破解运维转型困局。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721