
本文根据岑崟老师在〖2019 DAMS中国数据智能管理峰会〗现场演讲内容整理而成。

(文末可获取完整PPT)
讲师介绍
岑崟,现任东方财富运维主管,负责应用运维,对DevOps抱有极大热情。曾任好买财富系统运维部副总监,负责应用运维及DevOps运维平台研发和运营,任职期间推动运维团队从传统的运维向DevOps转变,带领运维从只关注产线到服务“全环境”,深刻体会DevOps落地实践中给运维带来的笑与泪,品尝行为转变到思想转变的酸甜苦辣。
分享概要
1、中小型企业如何进行灾备建设
2、运维自动化的作用
3、思考和尝试
如果你要我用一个字来形容初次接触灾备建设的感受,那就是:闷。不像在搞定高并发大流量优化后,带给你的酣畅淋漓的感觉;做灾备时的感受,犹如今天会场外天气一般,让人喘不过气。但它不仅是运维最后一道防线,又是灾难发生时的救命稻草,让你不得不硬着头皮去完成它。
我还清晰记得,领导给我灾备建设任务时,第一个反应是:为什么是我?但在做了四年的灾备建设后,突然感到灾备建设是一件很有趣的事。
上周参加其他大会,陆金所分享他们的一键机房切换,4分03秒就完成机房主备切换。他们怎么做到的?除开技术原因,他们在灾备建设这件事情上进行了大量资源的投入,不管是人的资源还是机器的资源。
一、中小型企业如何进行灾备建设
那么中小型企业在极其有限的资源下该如何进行灾备建设,怎么让灾备建设能在可用性和成本之间求得一个平衡,是我接下来演讲的主要内容。
先做个背景介绍,好买财富是专门做基金销售的,并不是做P2P,因为很多人听到财富两个字自然会往那个方向想。既然我们是跟基金相关,那我们受证监会的相关监管,两地三中心就肯定逃不走,所以公司就会有这方面的诉求:把灾备建好,并且保证灾备是可用的。
在四年前,老板让我重建灾备机房时,我最初的想法是:很简单嘛,照着主机房原样拷贝一份,应该很快就能把灾备建设完成。然而,花了近一年的时间,才把第一个交易核心系统的灾备建起来。
下图是现实做灾备建设过程中遇到的种种挑战:RTO/PRO,数据同步、负载、切换模式、网络互联和第三方外联等等。举个例子:金融企业的第三方外联,当前你的支付接入50家银行,在灾备建设时,这50家银行需要再接入一遍,突然有家银行告诉你:我同时只支持一个key,这意味着当灾难发生的时候,要么这家银行就被我放弃掉,要么人跑到主机房拔下key,再马上打车到灾备机房插上去才能用。
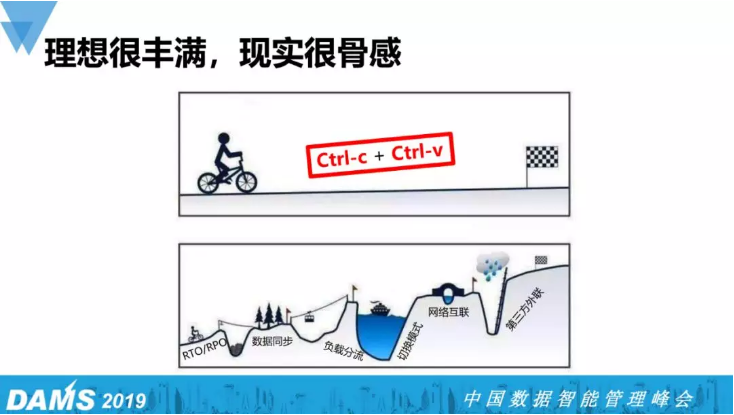
通过这个例子我发现,灾备建设过程中是在梳理整个运维的核心点、痛点、难点,当你把这些理完,整个运维的水准也悄然提升。
下面是一个业务连续性管理的6R模型,为什么要提到这个模型?让我们回到最初的目标,你会发现灾备建设只是实现这个目标其中一环:业务连续性。

大家可以从图中看到,灾备建设基本处于第三或者第四个环节,每一个环节时间要求不同,我这边摘录了一本书上写的时间供大家参考。
整个灾备建设过程不断前行中,随着持续不断的灾备演练,恢复时间会在自动化工具的协助下不断逼近极限,但是自动化的建设又是一个长期且需要大量投入的事情。
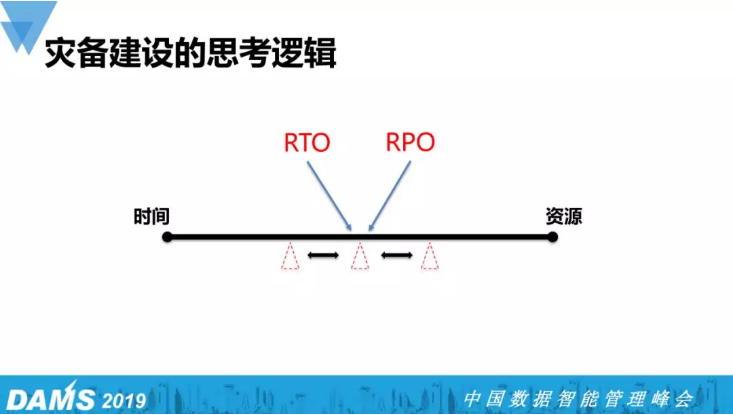
所以我们灾备建设的思考逻辑是:在恢复时间和投入资源之间寻找一个平衡点。那谁是砝码呢?RTO和RPO,当你期望多久能恢复,容忍多少数据损失,大体就能知道你的灾备建设投入多少的资源。
二、运维自动化的作用
接下来就是今天的正题,从灾备建设痛点着手,讲清楚运维自动化的作用。
第一个痛点,如果说主节点基建状况就像图中小昆虫运送的东西一样,那你在灾备建设过程中,只是多几个同样的东西而已,并且灾备机房越多,这状况被复制的就越多,但人的资源不会相应增加,结果到最后把所有的运维小伙伴,甚至研发同学一起拖死,所以在灾备建设过程中要以本地资源建设为优先。

对于中小金融企业来说,本地应急资源建设也是灾备的一环,你可以先做应用高可用、数据库高可用、网络冗余、硬件冗余等本地应急资源建设,这样只要不是发生机房级别的灾难,就能很快恢复正常运作。

那么我们的经历是怎么样的?我们分了三步走:
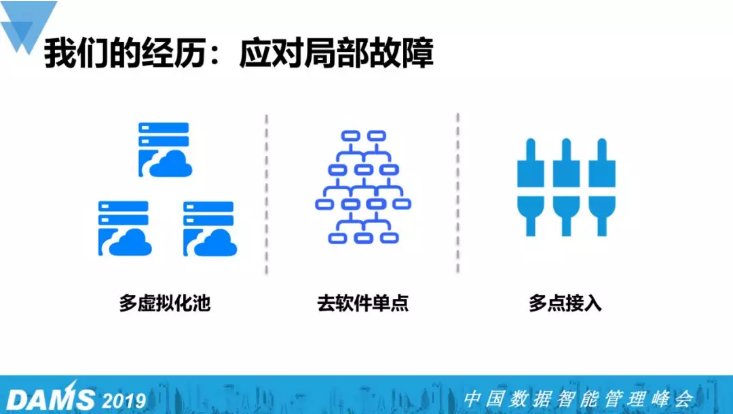
① 多虚拟化池
在2016年年底的时候已基本实现除数据库外,其余服务均虚拟化。但我们发现只有一个私有化虚拟池,这个池一但出状况就会造成大面积问题,是一个巨大的隐患,所以我们把一个虚拟化池拆成多个虚拟化池。
② 去软件单点
对于现代的互联网化应用来说,软件单点问题基本已不存在。但是要考虑到金融行业中不少软件是第三方开发,在开发过程中并未考虑高可用,那就需要你自己怎么把外购的软件也做成具备一定程度的高可用。
③ 互联网入口多点接入
随着整个灾备建设推进,从原本单一机房线路接入,到现在三个不同机房的接入点,这三个接入点都是对外提供服务的,只要其中任何一个点出问题了,其他两个点马上就能顶上来提供对外服务。
第二个痛点,灾备机房的可用性。一般我们在做主机房的时候会做的特别棒,但是回过头来看看灾备机房,我们会看到犹如还未学会走路的婴儿般弱小的灾备系统。当灾难突然发生的时候,我们才发现灾备机房根本就没法正常对外提供服务。为什么?原因有很多种:你的主要精力没在这儿,你的软件未同步更新,甚至你的数据有可能也大幅落后。

怎么办呢?我们提出来的想法是:应用双活。对于大公司,他们会选择用户体验更加好的业务双活。但对中小企业来说,没有资源去实现业务双活,那我们该怎么办?
可以先做应用双活,把所有对于数据库的读写均回到主机房,可能部分中间件的访问也会回到主机房,而应用会在两个机房同时承担流量,只是备流量会比较小一些。

这是我们现在的做法,这张图是借用自赵成老师的《进化》。
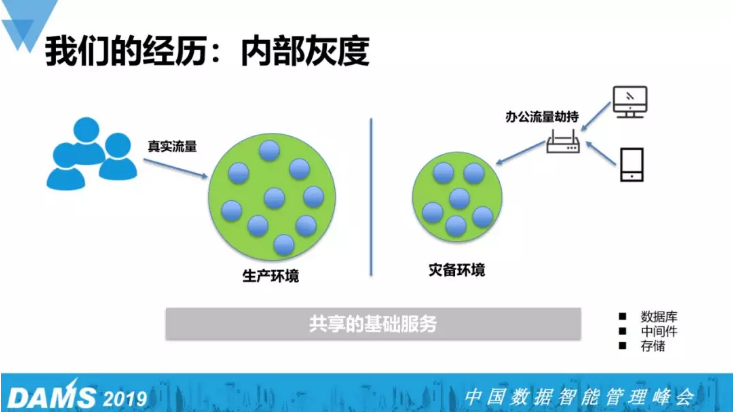
整体的结构如图所示,真实的流量在生产环境,我们通过劫持办公室DNS解析,将办公室流量引至灾备环境,应用更新会现在在灾备环境当中进行,业务验证通过之后再正式上产线。
这样的好处是,比仿真更进一步,在仿真验不出的业务性的流程,比如完整的走一次下单、撤单的流程,因为中间涉及支付,往往在仿真环境中是验不到的。我们现在的灾备环境,其实就是生产,只是这个不对外开。当然因为数据就是产线的真实数据,需要有预案来应对在验证过程中万一产生脏数据后的情况。
第三个痛点是制度流程上的:度量。不知道大家有多少人参与过灾备演练,想想演练过程中的RTO和RPO是如何填写的:很多银行在做灾备演练时,每人发一张纸,大家手填演练过程记录,最后再把所有人纸收上去进行统计。

所以往往在做的过程中会遇到这些问题:比方说有些人随便填一个数据,或者在演练过程中发生错误但不填写。对于老板来说没有这些数据,不知道演练是否成功,为了保证数据完备性,就要将演练数据填写写进KPI里面。在KPI的压力下,大家更容易选择:老板让你填,我就填一个,KPI就到手了。
为什么产生这样的情况?一是数据的生产者不会关心这些数据的价值在哪儿,演练成功与否跟我没有太多关系,反而会比较关心不填写所给带来的收益或者惩罚,这就造成他有动机去隐瞒一些事实。
度量的意义大家很清楚,PDCA环也都耳熟能详,就是想看一下现状怎么样,我与目标的GAP有多大,原理很简单,但落地却有重重困难。

我们也在做度量,循序渐进:第一个,原来手工填写改成探针式,由程序收集;第二个从KPI变成了OKR,为什么要OKR?先来看一个例子,这是今年我们运维定的一个OKR:应用双活的方式重建灾备环境,并完成灾备提升。这是一个O,而O下面的KR可以不断被调整的。有些人可能会问,你用了OKR,你怎么考核他?

我举一个可能不那么贴切的例子,假设你有一个女儿,你女儿已经6岁了,你天天“996”没有时间跟她进行交流,你给自己定一个目标:我要在一个月里面提升我跟女儿之间的亲密程度。如果是KPI该怎么写?内容大体会是每天我跟女儿交流不少于半小时,每周跟她谈一次心,每两周带她去玩一次。最后考评时,就看上述任务做没做到位。
那换成OKR呢,会怎么写?KR的内容跟KPI相同,但不一样的地方是每周你会复盘一下KR完成情况,并判断对O产生影响,比如你发现每天陪半小时没什么效果,一复盘发现原来你虽然陪伴了,但是一直拿着手机。
通过复盘,你就会把这个KR换成对O有帮助的其他KR。通过这种方式来提升整个度量的质量,能达到一个更好的效果。

第四个痛点,灾备往往是一年干一次,一次干一年。我在好买四年干了三次灾备建设,在整个灾备建设过程中采用敏捷的方式,不断交付价值,持续改进。采用这种方式,老板能不断看到阶段成果,而且做事情的小伙伴的信心也会持续提高。

这个是我们的经历,基本我们每年都有一定产出:
在2015年把交易核心部分进行重建,这时候伴随着运维的工具我们做了哪些?第一个制品库,第二个发布工具。因为我们觉得灾备更新要有保障,不能靠人工操作,那就让程序帮你。

到了2017、2018年的年初我们做了一次主备机房切换,这时候我们有很多准备工作要做,所以我们先做了一个事,配置版本化,保证两边推送的配置模版一致。第二个我们将部署动作做了工具化,使得灾备应用搭建速度非常快。

这是2019年正在做的,灾备机房要正式承担一部分产线流量,所以我们做了两个事,第一个资源数据的闭环,第二个发布流水化。原来发布流程靠人驱动,现在由系统来指导你一步一步往下,保障你不会遗漏灾备变更。CMDB是数据闭环的重要组成部分,原来由人保障的数据正确性,现在更多的是依赖流程来保障:机器从你申请开始,一直到你完成回收,都会在这个闭环中进行流转。
最后是我们正在做的,当时运维内部提出了两个要求:第一个配置模板化,第二个产线变更零SSH。相信大多数运维的同学喜欢通过SSH直接在产线做变更操作,在做完主机房变更之后,他很可能忘了灾备机房也需要做同样的变更操作。这就造成灾备机房跑着跑着跟主机房越差越远、做演练花一个月提前准备的主要原因。

三、思考与尝试
不可变基础设施的概念正好契合这两个要求,而容器化将这个概念很好地落地:所有的变更都会通过镜像进行变更,然后推送到各个环境,这样就能保证整个环境的一致性。
目前我们在测试环境有一个研发团队所有的测试环境都已经跑在容器环境中,我们用了这五个工具:Kubernetes、Docker、Harbor、Wayne、Jenkins,组成的工具链来支撑测试环境。
那效果如何?工具本身效率很好,但是使用者的体验很差。为什么?因为容器化后,改变了他们直接登录测试环境机器操作的习惯,所有的变更均通过重新制作镜像的方式进行,比如:配置没有接到配置中心那只能使用configmap或重打镜像的方式,而我们对configmap进行了封装,对操作人员来说,我只想改一行配置就要把前面的流程重新走一遍,即便执行是自动化的。
最后我们在思考灾备建设未来使用容器的方式来替代虚拟机。
① 更快速的环境重建
一是因为容器化能更快的把环境重建起来。比方说现在老板跟你,我们要把机房从一个云迁到另外一个云,如果在容器化技术支撑的情况下,你的迁移速度就更加迅速一些;
② 更高效的资源使用
二是更高效的资源使用,运维往往就是一家企业的成本中心,灾备建设为什么很多的公司不做?很多的金融公司不得不做?那是因为对于资源的占用非常的大,性价比不高,而今年基金信息技术管理办法里面更是要求灾备机房的算力跟主机房是对等的,换句话主机房花了5000万建成,灾备机房基本需要再花5000万,这对中小金融公司来说是个不小的负担。通过容器化技术,外加依托云的情况下,这个资源的使用会更有效,成本更低。
③ 更标准的环境管理
三是更标准的环境管理,所有的变更你不得不通过镜像变更去完成,这样会让你的变更有迹可寻,同时容器使用起来非常方便,不用在意应用程序的环境是如何被初始化的,只要把镜像运行起来就好了。
Q&A
Q1:刚才您提到灾备机房的请求,在灾备机房可以连接到主机房,如果数据库是单中心怎么是灾备呢?
A1:数据库在灾备机房以只读的方式存在,通过常规的手段进行灾备,比如主从,DG等,正常情况下不使用。
Q2:主备流量是通过DNS做的?
A2:我们只劫持办公流量,外部流量主备线路的流量按比例分发,由我们前面用CDN供应商完成。
Q3:备机房到主机房有网络带宽的,专线可能会有拥堵。
A3:在主机房、备机房请求基本上是闭环的,只有一些要写数据库的操作才回到主机房,如果不是大型的互联网企业不会遇到这种问题,你的带宽绝对够。如果像我们这种金融企业流量一直比较平稳,当然我们也很希望金融突然有一次热卖,那个时候带宽不是问题,你要1G就给1G,10个G就给10个G。其实我们会从成本考虑,这根线路会尽量避免读的操作,你可以通过监控会发现其实写的量不是这么大。
Q4:你刚才说在灾备环境下测试,如果把灾备环境破坏了怎么办?
A4:流程上还是会先上仿真,但是它比面对最终外部用户的生产事故好一些,因为仅仅影响的是公司内部的用户,很多补救措施实施起来也方便很多,压力没有那么的大。
PPT下载链接:https://pan.baidu.com/s/13XF6YG3zQj854UUuYP1n8w








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721