
编者按:在别的地方搜索一下这个看不出性别的简介真心没多大意思。陈爱珍,DBA+社群中间件云用户组联合发起人,上海中间件用户组负责人,新炬网络技术专家,7年运维经验,涉及电信、金融、税务等行业,精通主流中间件技术,精通以业务为导向的端到端性能优化,熟悉私有云平台建设。
红色三月的节气,发点生活照来应应景。

再来一些未披露的才艺。

(不知道为啥画的是杀阡陌,而不是被囚禁的尊上和胡歌!捂脸~)

(新时代女性,可以写代码,也能下厨房~)

偶然在朋友圈看到文章《放假了 过节了 寂寞了》, 忘记是谁转发的。12月25日发表,一个寂寞的日子。文章属于抒情式的小诗,作者描述的心情让我有共鸣,文体非常喜欢。再看了看公众号——流浪不是我的初衷,文艺女青年就果断地关注了。因为流浪也不是我的初衷,虽然这几年一直在四处流浪。平常自己也喜欢写点抒情的文章小诗,就热情的问是不是可以投稿,结果右军说,你写个《开发人员应该懂多少运维》吧。纳尼!说好的文艺范呢,说好的流浪呢!
好吧,谁让我自己说要投稿的,自已挖的坑只能自己填了。做运维这么多年,也经常和开发人员打交道。下面就根据我自己的见解,跟大家聊聊开发人员应该懂多少运维。从一个邮件开始讲起吧:

收到开发给我回复的这个邮件,我的内心是崩溃的。编码不符合规范却要求中间件修改底层的编译方法来兼容,中间件不是为你一家开发的好吗!开发发布了一个应用包,有三个不同的接入渠道,其中有两个接入渠道都能正常访问,而另一个不能正常访问,且只有部分页面不能访问。
当时跟开发沟通,对应用平台来说,只要应用包可以正常的发布,有两个接入渠道可以访问,就说明应用平台本身是没有问题的,应该要去核实代码的问题。而开发却一直跟我强调这个应用包在其他的应用平台是可以正常访问的,只是迁移到这个平台运行才异常,一定是与平台有关。在中间件的日志里一直在抛找不到文件,但文件却是真实存在的,可以找到。代码跑在平台上有问题,不能证明平台没有问题,就只能想办法证明代码有问题了。让他把代码发过来review,一眼就看出问题了。
代码如下:
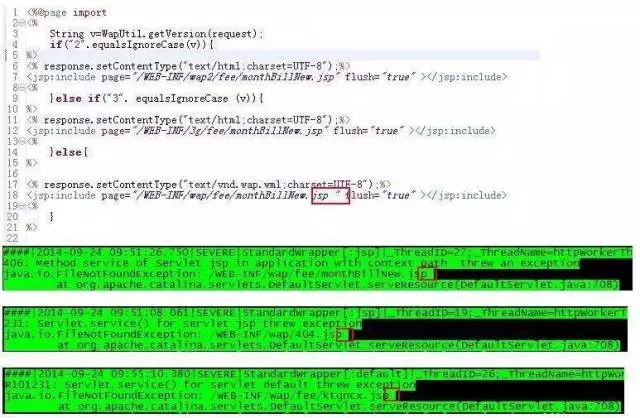
那么显眼的空格都没有看到,还反复跟我强调应用代码没有问题,遇上这样的开发,我也是醉了。在故障分析时,日志只有通过选中以高亮的方式显示才能看出文件路径中多了一个空格,如果不是拿代码来review,从中间件的角度真的是没办法继续排查。从这个事件可以看到,代码只有按照规范去编写才能很好的迁移到各种平台上。像这个案例,他们很多地方都是这么编写,得把全部的代码review一遍进行修改,所以按标准要求编写代码非常重要,否则就是给自己埋坑。这是最常见的dev与ops交流的场景,应用代码交付部署失败导致业务中断。其实如果dev开发的程序质量高一点,ops是没有机会接触到dev。但是往往dev把ops当不良coding习惯的发现者,当程序bug的挖掘者。ops在做troubleshooting时,最常听到dev的一句话就是:代码很多,这个方法很多模块都调用了,能帮忙定位到具体代码吗?所以我认为开发至少要懂得运维分析代码异常的方法。
在很多“外人”的眼中,运维工程师的工作不过是装软件、部署上线、处理故障、7×24小时值班,感觉简单而又枯燥至极。但事实并非如此,运维工作涵盖很多技术领域,运维工程师要掌握硬件、软件、操作系统、开发等多方面的知识。核心目标是确保系统稳定运行的同时,提高系统的质量,为亿万用户使用的产品保驾护航。需要在代码不断的更新发布过程中,在不中断和破坏当前服务的基础上,确保功能部署成功,同时也可以快速检测和修复缺陷,提高可用性,提高变更成功率,减少故障等等。开发人员开发的程序只是整个系统的一个部分,而运维要搭建,维护系统提供全部的功能,所以ops要掌握的知识多且杂。
做运维得懂系统软件(中间件,数据库等),运维脚本编写(Shell,Python等),操作系统管理(AIX,HP,SUN,LINUX等),各种故障分析工具(HA,JCA,Hpjmeter,MAT等)。运维自动化工具开发,应用系统服务架构也得了解,还要有很强的运维意识,生产操作安全(携程2015年故障据说就是因操作不当导致数据全部强制rm ),备份容灾高可用等等。如果应用程序写得不好,还要能对代码做review,配合开发一起排查。写到这里我都觉得自己好牛了,做运维不容易啊。
什么是ops?度娘的解释是:将开发交付的业务软件和硬件基础设施高效合理的整合,转换为可持续提供高质量服务的产品,同时最大限度降低服务运行的成本,保障服务运行的安全。简单来说,开发提供的是功能性需求,而运维提供的是非功能性需求,主要是以下几个方面:
项目管控:总体设计把关,包括高可用,容灾备份,集成规范,集成质量管控
容量管理:资源容量管理,服务容量管理,业务容量管理
应用维护:测试,发布部署,问题处理,性能调优
监控管理:提前预警,性能监控,可视化监控
安全管理:操作规范,权限管理,安全漏洞,应急演练
就拿双十一淘宝的保障和12306春运的保障来说,开发实现了相关的业务功能开发将代码交付给运维之后他们就没事情了,而运维的工作则关系到系统的可用性,稳定性,安全性,业务的价值能否良好的传达取决于运维。比如系统瘫痪是否能迅速恢复,比如高并发能否及时扩容,比如代码问题是否能够不中断的进行回退,这些都和运维息息相关。如果开发只关注应用新功能实现,当代码开发完成被部署到生产上时问题不断,就要依靠IT运维来收拾残局,缺陷和已知错误在生产上不断递归,迫使IT运维不停的救火,所以开发需要看到他们工作和变更带来的下游变化,以IT运维的视角来思考代码的构建,从而达到一个全局的目标。所以开发要懂多少运维呢?我觉得是以下几个方面:
1、了解程序运行到生产环境后对资源的使用不当会造成什么样的后果。比如对内存的使用,在开发阶段没有业务压力,什么东西都可以往内存里放,但是拿到生产时并发量上来,很容易造成内存溢出或系统运行缓慢,所以在资源申请一定要仔细考量。资源包括什么?内存、CPU、磁盘、网络、文件描述符、外部API、缓存、数据库等;编程语言是如何管理资源的、合理的算法/架构保证了资源的合理使用;malloc/free分配内存、connec、close使用网络等等。
2、了解当程序运行异常时做故障处理的思路。这样在开发阶段就能知道什么样的信息要暴露,什么样的信息不要暴露。有的开发什么日志都输出,做故障分析的时候看得眼花也找不到个核心的信息,但重要的信息又不打印。开发模式和生产模式不一样,不要把开发调试的模式发布到生产。大量的日志输出也可能导致实例挂起,停止服务。
3、了解不良的coding习惯会给运维带来怎么样的麻烦。比如申请内存不释放,数据库连接池申请了不关闭,慎用同步锁造成线程堵塞,死锁之类。绝不传递一个已知缺陷至下游,绝不因小失大。
4、站在容易维护的角度编写代码,包括容易配置、容易部署、容易监控、容易扩展,只需要简单的增加资源(CPU、内存、磁盘、机器等)就行,不需要太多人工迁数据、修改配置。
1、对运行平台的产品有基本的了解,比如tomcat,weblogic,websphere。了解这些系统软件的基本运行原理,特性,比如不同版本对java的要求,不同操作系统平台java的配置参数。
2、从软件交付的全局出发,加强各角色之前的合作,提交软件交付的成功率和效率。打破开发与运维之间存在的信息"鸿沟"。开发人员应让运维人员了解架构设计,细心听取运维人员的建议,了解系统上线方面运维的需求,进行技术改造,使部署工作更加快捷有效。
3、深刻理解运行平台基本没有问题。应用代码的运行平台是指一个容器,承载着业务代码的运行,负责提供相关资源的调度和分配。如果应用代码能够正常的部署在平台上,实例可以正常启动,那么一切不能正常访问的异常都是源自代码编写的问题。一个生产环境中往往是有很多套系统都运行在这个平台上,其他系统可以正常访问,那平台本身是不会导致异常,这里指的是产品bug类,无关配置。
1、了解一些基本的故障分析工具的使用,因为并不是每一个运维都能做代码review。如果开发不懂分析故障,运维不懂代码review,就是死锁。比如说threaddump,javacore,headdump文件代表是什么,怎么产生的,怎么分析,使用什么样的工具。如果开发能了解这些东西,和运维一起做troubleshooting时效率也能快速提升。
2、了解一些应用性能分析的方法,在开发阶段对核心的业务功能就关注性能情况,避免提交到生产环境在大并发的情况下存在严重明显的性能问题。
3、开发人员一定要记住,如果出现了问题,那么有90%的可能性是开发人员自己的错误。
以上想表达的是开发需要在源头上解决质量问题,减少技术债务从研发转向运维,并了解运维负责的“非功能性需求”,化解掉一部分风险。两方相互之间紧密合作,才能为业务提供稳定,安全及可靠的IT服务。
最后借用网红互联网运维杂谈老王的一张图展示一下Dev与Ops的关系。在非DevOps模式里用是防火墙来隔离dev与ops,彼此不懂。其实开发的程序作为运维体系里的一部分,应该要了解运维,了解程序跑在什么样的环境上,才能让程序更好的服务业务。现在DevOps模式炒得很火,老王把DO关系分成三个阶段。
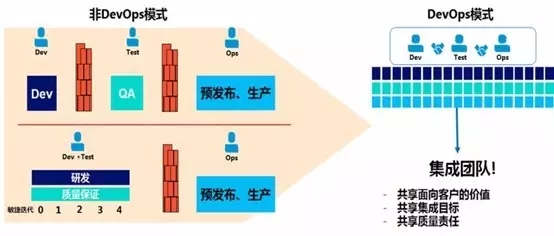
第一个阶段:DO混合。大家的职能交织在一起,运维是研发的附属过程,运维的职责就是资源交付。
第二个阶段:DO分离。研发和运维走向分离,一些维护的压力逐渐浮现出来,专业的运维如何更好的做好运维,定规范,建平台,收数据等等。
第三个阶段:DO融合。注意不是混合。融合是指一种能力的流动,运维的能力已经是研发过程自然而然考虑的一部分的了。另外随着平台、规范、流程的完善,此时研发都可以具备真正的运维能力。
当未来发展到DO融合阶段时,DO是不分的,中间不会再有那道防火墙。开发人员会具备运维能力,运维人员具备开发能力,双方共同肩负着质量的责任。
作者介绍:于君泽(右军)
蚂蚁金服高级技术专家、支付核算技术部负责人、成都研发中心技术团队创建者之一。
先后负责或参与过转账类业务、账单类业务、社区支付、开放平台、支付平台、资金核算平台类、营销类支付工具的建设。
有数年电信业务研发经验,涉及BSS|OSS|针对性营销等平台。
个人感兴趣的方向:高并发、分布式系统、稳定性模式;内建质量、技术型管理。
作者授权转载
来源:流浪不是我的初衷订阅号
链接:http://mp.weixin.qq.com/s?__biz=MzIxMzEzMjM5NQ==&mid=402757679&idx=1&sn=ca36f5c4b230f07ecf062db56db227d1&scene=1&srcid=0303KqCkeNtMDQ9M7uXold3z#wechat_redirect
(本篇是右军策划的女神系列Part2,欢迎继续追看n(*≧▽≦*)n)
全球敏捷运维峰会【杭州站】

2016 年4月16日,与你相约杭州,来一场敏捷与运维的美丽邂逅!DBA+社群联合三墩IT人开启全球敏捷运维峰会第一站:杭州站!峰会力邀来自互联网与传统企 业的资深专家,各路大咖齐聚,汇聚500+行业精英,聚焦架构、敏捷、运维三大主线,开启一场专属于IT人的年度之约!
专家阵容:或行业资深派、或著书力作派、或传统转型派、或一线实战派,总有一款是你喜欢!
绝对干货:聚焦架构、敏捷、运维三大主线,共讨传统企业在技术转型过程中的实践与困境、互联网企业在前沿技术方面的应用与心得、技术服务型企业在新老技术之间如何切换与落地,拒绝无营养的广告,绝对干货,精彩不容错过!
连接联动:汇聚社群数百顶级专家人脉,携数万社群成员声势,联合数十家媒体单位,共同打造一场连接敏捷与运维圈子的年度之约!
门票:免费!(限时限额)
VIP票:199元(限3月20日前)








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721