
一、监控系统Flink的现状
eBay的监控平台Sherlock.IO每天处理着上百亿条日志(log),事件(event)和指标(metric)。通过构建Flink Streaming job实时处理系统,监控团队能够及时将日志和事件的处理结果反馈给用户。当前,监控团队维护着8个Flink集群,最大的集群规模达到上千个TaskManager,总共运行着上百个作业(job),一些作业已经稳定运行了半年以上。
二、元数据驱动
为了让用户和管理员能够更加快捷地创建Flink作业并调整参数,监控团队在Flink上搭建了一套元数据微服务(metadata service),该服务能够用Json来描述一个作业的DAG,且相同的DAG共用同一个作业,能够更加方便地创建作业,无需调用Flink API。Sherlock.IO 流处理整体的架构如图1所示。

▲ 图1 Sherlock.IO 流处理整体架构
目前,用这套元数据微服务创建的作业仅支持以Kafka作为数据源,只要数据接入到Kafka,用户就可以定义Capability来处理逻辑从而通过Flink Streaming处理数据。
元数据微服务框架如图2所示,最上层是元数据微服务提供的Restful API, 用户通过调用API来描述和提交作业。描述作业的元数据包含三个部分:Resource,Capability和Policy。Flink 适配器(Adaptor)连接了Flink StreamingAPI和元数据微服务 API,且会根据元数据微服务描述的作业调用Flink StreamingAPI来创建作业,从而屏蔽Flink StreamAPI。
因此,用户不用了解Flink StreamingAPI 就可以创建Flink作业。未来如果需要迁移到其他的流处理框架,只要增加一个适配器,就可以将现有的作业迁移到新的流处理框架上。
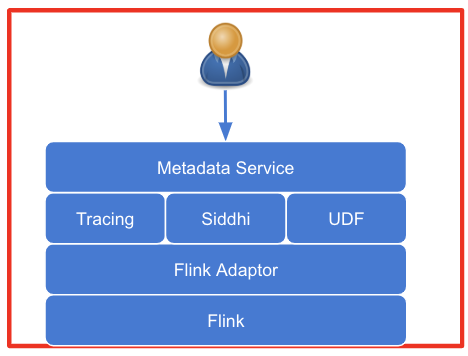
▲ 图2 元数据微服务框架
1)Capability
Capability定义了作业的DAG以及每个算子(Operator)所用的Class,图3是事件处理(eventProcess) Capability,它最终会生成如图4的DAG。事件处理Capability先从kafka读出数据,再写到Elasticsearch中。该Capability将该作业命名为“eventProcess”,并定义其并行度为“5”,其算子为“EventEsIndexSinkCapability”, 其数据流为“Source –> sink”。

▲ 图3 eventESSink Capability
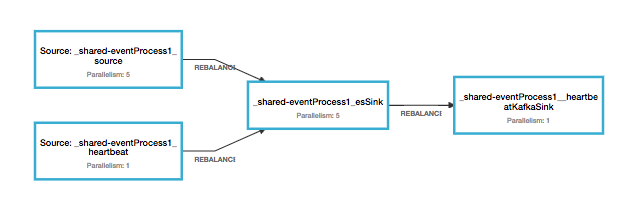
▲ 图4 生成的Flink作业
2)Policy
每个命名空间(Namespace)需要定义一个或多个Policy,每个Policy指定了相应的Capability,即指定了用哪一套DAG来运行这个Policy。Policy还定义了这个作业的相关配置,例如从哪个Kafka topic中读取数据,写到ElasticSearch的哪个索引(Index)中,中间是否要跳过某些算子等等。
其次,Policy还能作为一个简易的过滤器(Filter),可以通过配置Jexl表达式过滤掉一些不需要的数据,提高作业的吞吐量。
另外,我们还实现了Zookeeper定时更新的机制,使得Policy修改后不再需要重启作业,只要是在更新时间间隔内,该命名空间的Policy修改就会被自动应用到作业上。图5是命名空间为paas的Policy示例。

▲ 图5 paas alertESSink Policy
3)Resource
Resource定义了某个命名空间所需要的资源,比如Flink 集群, Kafka broker,ES 集群等等。我们有多个Flink集群和ES集群,通过Resource配置,作业可以知道某个命名空间的日志应该写到哪个ES 集群,并可以判断该命名空间的数据应该从哪个Kafka 集群读取。
为了减少作业数量,我们可以让相同的DAG复用同一个作业。我们先给不同的Policy指定相同的Capability,在该Capability资源足够的情况下,这些Policy就会被调度到同一个作业上。
以SQL的Capability为例,每个Policy的SQL语句不尽相同,如果为每个Policy都创建一个作业, Job Manager的开销就会很大,且不好管理。因此,我们可以为SQL Capability配置20个Slot,每个Policy占用一个Slot。那么该Capability生成的作业就可以运行20个Policy。
作业运行时,从Source读进来的数据会被打上相应Policy的标签,并执行该Policy定义的SQL语句,从而实现不同Policy共享同一个作业,大大减少了作业的数量。
用共享作业还有一个好处:如果多个命名空间的数据在一个Kafka topic里,那么只要读一遍数据即可,不用每个命名空间都读一次topic再过滤,这样就大大提高了处理的效率。
三、Flink 作业的优化和监控
了解元数据驱动后,让我们来看看可以通过哪些方法实现Flink作业的而优化和监控。
在Flink 集群 的运维过程中,我们很难监控作业的运行情况。即使开启了检查点(checkpoint),我们也无法确定是否丢失数据或丢失了多少数据。因此,我们为每个作业注入了Heartbeat以 监控其运行情况。
Heartbeat就像Flink中用来监控延迟的“LatencyMarker”一样,它会流过每个作业的管道。但与LatencyMarker不同的是,当Heartbeat遇到DAG的分支时,它会分裂并流向每个分支,而不像LatencyMarker那样随机流向某一个分支。另一个不同点在于Heartbeat不是由Flink自身产生,而是由元数据微服务定时产生,而后由每个作业消费。
如图4所示,每个作业在启动的时候会默认加一个Heartbeat的数据源。Heartbeat流入每个作业后,会随数据流一起经过每个节点,在每个节点上打上当前节点的标签,然后跳过该节点的处理逻辑流向下个节点。直到Heartbeat流到最后一个节点时,它会以指标(Metric)的形式发送到Sherlock.IO(eBay监控平台)。
该指标包含了Heartbeat产生的时间,流入作业的时间以及到达每个节点的时间。通过这个指标,我们可以判断该作业在读取kafka时是否延时,以及一条数据被整个管道处理所用的时间和每个节点处理数据所用的时间,进而判断该作业的性能瓶颈。
由于Heartbeat是定时发送的,因此每个作业收到的Heartbeat个数应该一致。若最后发出的指标个数与期望不一致,则可以进一步判断是否有数据丢失。
框图6描述了某Flink作业中的数据流以及Heartbeat的运行状态:

▲ 图6 Heartbeat在作业中的运行过程
有了Heartbeat,我们就可以用来定义集群的可用性。首先,我们需要先定义在什么情况下属于不可用的:
1)Flink作业重启
当内存不足(OutofMemory)或代码运行错误时,作业就可能会意外重启。我们认为重启过程中造成的数据丢失是不可用的情况之一。因此我们的目标之一是让Flink作业能够长时间稳定运行。
2)Flink作业中止
有时因为基础设施的问题导致物理机或者容器没启动起来,或是在Flink 作业发生重启时由于Slot不够而无法启动,或者是因为Flink 作业的重启次数已经超过了最大重启次数(rest.retry.max-attempts), Flink作业就会中止。此时需要人工干预才能将作业重新启动起来。
我们认为Flink作业中止时,也是不可用的情况之一。
3)Flink作业在运行中不再处理数据
发生这种情况,一般是因为遇到了反压(BackPressure)。造成反压的原因有很多种,比如上游的流量过大,或者是中间某个算子的处理能力不够,或者是下游存储节点遇到性能瓶颈等等。虽然短时间内的反压不会造成数据丢失,但它会影响数据的实时性,最明显的变化是延迟这个指标会变大。
我们认为反压发生时是不可用的情况之一。
针对以上三种情况,我们都可以用Heartbeat来监控,并计算可用性。比如第一种情况,如果作业重启时发生了数据丢失,那么相应的那段管道的Heartbeat也会丢失,从而我们可以监测出是否有数据丢失以及粗粒度地估算数据丢了多少。对于第二种情况,当作业中止时,HeartBeat也不会被处理,因此可以很快发现作业停止运行并让on-call及时干预。第三种情况当反压发生时,HeartBeat也会被阻塞在发生反压的上游,因此on-call也可以很快地发现反压发生并进行人工干预。
综上,Heartbeat可以很快监测出Flink作业的运行情况。那么,如何评估可用性呢?由于Heartbeat是定时发生的,默认情况下我们设置每10秒发一次。1分钟内我们期望每个作业的每条管道能够发出6个带有作业信息的heartbeat,那么每天就可以收到8640个Heartbeat。
因此,一个作业的可用性可以定义为:
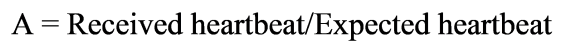
Slot是Flink运行作业的最小单位[1],每个TaskManager可以分配一个至多个Slot(一般分配的个数为该TaskManager的CPU数)。根据Flink作业的并行度,一个作业可以分配到多个TaskManager上,而一个TaskManager也可能运行着多个作业。然而,一个TaskManager就是一个JVM,当多个作业分配到一个TaskManager上时,就会有抢夺资源的情况发生。
例如,我一个TaskManager分配了3个Slot(3个CPU)和8G堆内存。当JobManager调度作业的时候,有可能将3个不同作业的线程调度到该TaskManager上,那么这3个作业就会同时抢夺CPU和内存的资源。当其中一个作业特别耗CPU或内存的时候,就会影响其他两个作业。
在这种情况下,我们通过配置Flink可以实现作业的隔离,如图7所示:
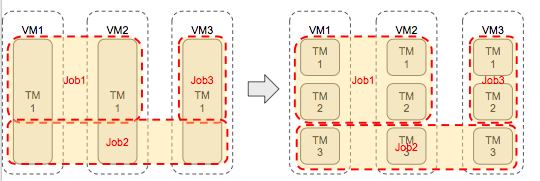
▲ 图7 Flink作业隔离前后的调度图
通过配置:
“taskmanager.numberOfTaskSlots: 1”:可以设置每个TaskManager只有一个Slot;
“cpu_period”和“cpu_quota”:可以限定每个TaskManager的CPU个数;
“taskmanager.heap.mb”可以配置每个TaskManager的JVM的内存大小。
通过以上配置,可以限定每个TaskManager独占CPU和内存的资源,且不会多个作业抢占,实现作业之间的隔离。
我们运维Flink集群的时候发现,出现最多的问题就是反压。在3.2中提到过,发生反压的原因有很多种,但无论什么原因,数据最终都会被积压在发生反压上游的算子的本地缓冲区(localBuffer)中。
我们知道,每一个TaskManager有一个本地缓冲池, 每一个算子数据进来后会把数据填充到本地缓冲池中,数据从这个算子出去后会回收这块内存。当被反压后,数据发不出去,本地缓冲池内存就无法释放,导致一直请求缓冲区(requestBuffer)。
由于Heartbeat只能监控出是否发生了反压,但无法定位到是哪个算子出了问题,因此我们定时地将每个算子的StackTrace打印出来,当发生反压时,通过StackTrace就可以知道是哪个算子的瓶颈。
如图8所示,我们可以清晰地看到发生反压的Flink作业及其所在的Taskmanager。再通过Thread Dump,我们就可以定位到代码的问题。
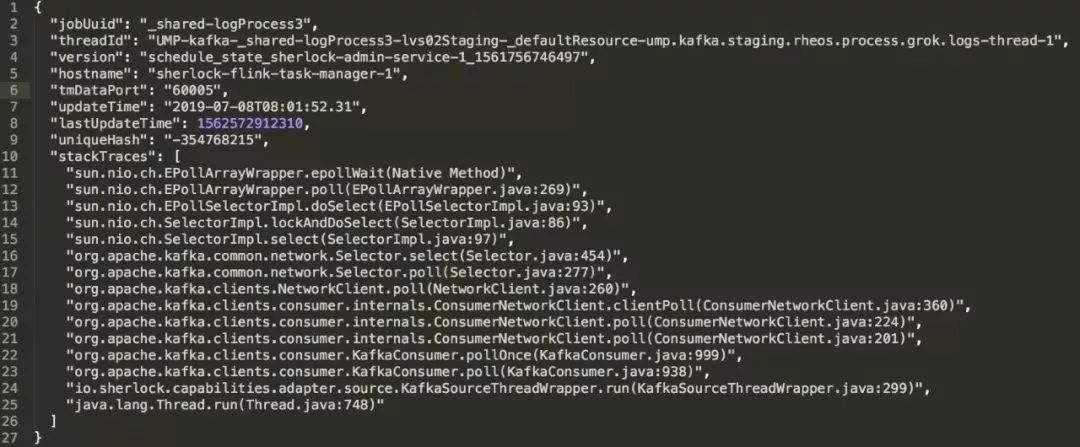
▲ 图8 发生反压的StackTrace (点击观看大图)
Flink本身提供了很多有用的指标[2]来监控Flink作业的运行情况,在此基础上我们还加了一些业务上的指标。除此之外,我们还使用了以下工具监控Flink 作业。
1)History server
Flink的History server[3]可以查询已完成作业的状态和指标。比如一个作业的重启次数、它运行的时间。我们常常用它找出运行不正常的作业。比如,我们可以通过History server的attempt指标知道每个作业重启的次数,从而快速去现场找到重启的原因,避免下次再发生。
2)监控作业和集群
虽然Flink有HA的模式,但在极端情况下,例如整个集群出现问题时,需要on-call即时发觉并人工干预。我们在元数据微服务中保存了最后一次提交作业成功的元数据,它记录了在每个Flink 集群上应该运行哪些作业。守护线程(Daemon thread)会每分钟去比较这个元数据和Flink上运行的作业,若发现JobManager连不通或者有作业运行不一致则立刻发出告警(Alert)通知on-call。
四、实例
下面介绍几个已经运行在监控系统上的Flink流处理系统的应用:
当前监控团队是基于Flink Streaming做事件告警(Event alerting),我们定义了一个告警算子EventAlertingCapability,该Capability可以处理每个Policy自定义的规则。如图9定义的一条性能监控规则:

该规则的含义是当性能检测器的应用为“r1rover”, 主机以“r1rover”开头,且数值大于90时,就触发告警。且生成的告警会发送到指定的Kafka topic中供下游继续处理。

▲ 图9 Single-Threshold1 Policy (点击查看大图)
Eventzon就像eBay的事件中心,它收集了从各个应用,框架,基础架构发过来的事件,最后通过监控团队的Flink Streaming实时生成告警。由于各个事件的数据源不同,它们的元数据也不同,因此无法用一条统一的规则来描述它。
我们专门定义了一套作业来处理Eventzon的事件,它包含了多个Capability,比如Filter Capability,用来过滤非法的或者不符合条件的事件; 又比如Deduplicate Capability,可以用来去除重复的事件。
Eventzon的所有事件经过一整套作业后,会生成有效的告警,并根据通知机制通过E-mail、Slack或Pagerduty发给相关团队。
Netmon的全称为Network Monitoring, 即网络监控,它可以用来监控整个eBay网络设备的健康状态。它的数据源来自eBay的交换机,路由器等网络设备的日志。Netmon的作用是根据这些日志找出一些特定的信息,往往是一些错误的日志,以此来生成告警。
eBay的每一台设备都要“登记造册”,每台设备将日志发过来后,我们通过EnrichCapability 从“册子”中查询这台设备的信息,并把相关信息比如IP地址,所在的数据中心,所在的机架等填充到日志信息中作为事件保存。当设备产生一些特定的错误日志时, 它会被相应的规则匹配然后生成告警,该告警会被EventProcess Capability保存到Elasticsearch中实时显示到Netmon的监控平台(dashboard)上。有时因为网络抖动导致一些短暂的错误发生,但系统过一会儿就会自动恢复。
当上述情况发生时,Netmon会有相应的规则将发生在网络抖动时生成的告警标记为“已解决”(Resolved)。对于一些必须人工干预的告警,运维人员可以通过网络监控平台(Netmon dashboard)手动点击“已解决”,完成该告警的生命周期。
五、总结与展望
eBay的监控团队希望能根据用户提供的指标、事件和日志以及相应的告警规则实时告警用户。Flink Streaming能够提供低延时的处理从而能够达到我们低延时的要求,并且它适合比较复杂的处理逻辑。
然而在运维Flink的过程中,我们也发现了由于作业重启等原因导致误报少报告警的情况发生,从而误导客户。因此今后我们会在Flink的稳定性和高可用性上投入更多。我们也希望在监控指标、日志上能够集成一些复杂的AI算法,从而能够生成更加有效精确的告警,成为运维人员的一把利器。
参考资料
https://ci.apache.org/projects/flink/flink-docs-release-1.7/monitoring/metrics.html
https://ci.apache.org/projects/flink/flink-docs-release-1.4/monitoring/historyserver.html
作者:Unified Monitoring Platform 顾欣怡[译]
来源:eBay技术荟(ID:eBayTechRecruiting)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721