
刘华(Kenneth),就职于世界500强银行,负责基金服务业务软件开发与交付,DevOps团队负责人。敏捷、精益、DevOps领域专家,精通极限编程、Scrum、看板方法、测试驱动开发、持续集成、行为驱动开发、DevOps工具栈。著有《猎豹行动:硝烟中的敏捷转型之旅》一书。
前段时间,我一直在看东方卫视的《急诊室故事》。那段时间刚好是我接手我们核心系统 IT 负责人的时候,这个角色的其中一个重要职责就是运维。
急诊室和运维的相通与不同
我发现急诊室和运维有很多相通的地方:
急诊室每天都有如潮水般涌来的病人,运维每天也会收到铺天盖地的故障或请求;
急诊室的医生和床位永远不足,运维的人手也是捉襟见肘。
因为请求太多,资源太少,急诊室要做的第一件事就是通过观察病人的病情,判定轻重缓急,优先处理重症患者。
但运维面对的困难是,由于业务与IT存在巨大的知识鸿沟,加上业务过程本身就很复杂,每个国家或地区又有不一样的情况,我们也无法身处现场,所以要理解每个故障或请求本身就比较困难。
加上我们未必有能力判断某个故障或请求对业务的真实影响,只能相信业务方的“一面之词”。
如果只有一个业务方,这还好办,所有请求都来自于他们,让他们排个队就好了。但我们是一个系统支撑亚洲和欧洲共十个国家或地区的业务,每个国家和地区都会说他们的请求,而且没有一个业务代理人能代表他们给出一个全球的统一优先级,此时负责运维的还是我们这一小撮人,这就是我们比急诊室更难的地方。
我们曾经试图定义一些标准问题,通过让业务回答这些问题来判定业务影响,但效果不佳。
首先,如果问题太空泛,得到的答案也不会有什么价值。其次,如何提出更具体的问题,也是一个难题。
如果没有清晰的价值判定,我们很容易陷入这样的窘境:
一方面我们这边非常忙碌地清理积压的故障和请求;
另一方面业务看不到我们在处理他们认为最重要的事情。
最后大家都不愉快。
通过看板原则确保处理优先级
我想到了看板方法的限制在制品原则。
我们面对的最大问题是,业务方有十个国家或地区,他们各自有自己的请求,但是他们之间是不会有相互协商的统一的优先级的。
然而,每个国家或地区内部是可以对他们自己的所有请求进行排队的。这些国家或地区之间的业务量也不太一样,有四个国家或地区的业务量最大,我们戏称他们是“四大家族”,其余的则要小得多。
于是,我们做了这样的调整。
在我的团队里,每个人负责指定的一个或多个国家或地区;在业务方,也要求每个国家或地区指定一个或两个和我们的对接人,从而形成一对一的对接模式。那些业务方对接人就负责对他们所在国家或地区的请求进行排序。
然后我们设了一个“潜规则”——对每个国家或地区限制在制品。因为我们人手实在有限,对于“四大家族”,我们只处理他们队列中的头两个请求;对于其他国家或地区,我们只处理他们队列中的队列中第一个请求。
举例说明:
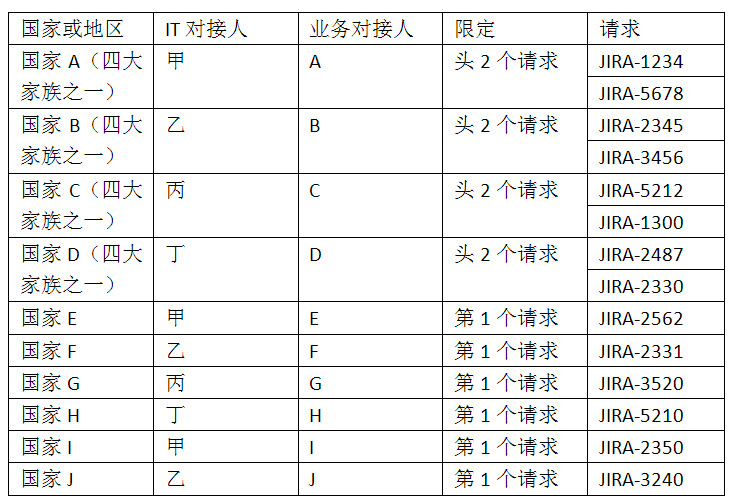
这样,便可以确保我们一直在处理每个国家或地区认为最紧急的故障或请求。一旦上表中某个国家或地区的任何一个故障或请求处理完了,相应的IT对接人便从该国家或地区的队列中拉入下一个优先级最高的故障或请求。
在急诊室,虽然对于大多数病人来说,等待时间都会很长,但因为有排号系统,你起码能知道自己排在哪里,有个心理预期。因此,我们也会把上表公开给业务(通过 Confluence 与 JIRA 结合形成一个动态实时页面),让他们能看到我们在处理哪些故障和请求。
当然,重大的故障,需要我们所有人停下手头工作全情投入的,可以打破这个“潜规则”,被优先处理。
通过这个手段,我们解决了不同国家或地区优先级无法统一的问题,确保我们一直在处理每个国家或地区认为最紧急的故障或请求。
重要事情没人管?
借用 Scrum 时间盒理念显神功
作为 IT 系统负责人,我们需要应对的事务有很多,既有紧急的事务,也很多重要非紧急的事务。如果不进行有效管理,我们每天的时间都会被紧急的事务全部占据,没有时间进行持续改进,陷入只有“苟且”,没有“诗和远方”的窘境。
我们要应对的事务大致可以分为以下这些类别:
日常运维(包括生产环境故障处理和业务请求);
各种开发请求;
故障数据分析;
故障处理完毕后的跟进(包括如何避免重现与 Bug 的修复);
遗留问题的跟踪与修复;
实现部署流水线,实现自动化部署;
增强自动化监控;
OS 补丁与升级;
灾备演练;
数据备份与恢复演练
……
我们在进行 DevOps 转型后,开发运维一体化,已经不再像过去那样有一线、二线、三线的运维体系。
在过去,一线运维把紧急问题处理完,业务影响消除后,就可以交由二线、三线团队负责后续跟进。这一点很像急诊室,急诊室对重症病人进行简单处理,待病人生命体征稳定后,便会交由住院部相应科室进行后续处理。
现在我们和急诊室不一样的是,作为 IT 系统负责人,除了处理一线的故障和运维请求外,系统的一切事物也都需要处理,包括紧急的和重要非紧急的。如何在资源短缺的情况下平衡和处理好所有事物,对我们是极大的挑战。
在上面罗列的事务中,除了头两项,其余的都是重要非紧急的事务。面对着每天扑面而来的各种故障和请求,我们很容易陷入被动。
那么如何才能让团队在应对紧急事务之外,还能持续地关注重要非紧急事务,实现持续改进呢?
经过我们的实践,借用 Scrum 的时间盒理念,通过固定周期的循环例会,可以确保我们对重要的事务保持关注与维持进度。
一般来说,每日站会都是用来跟进日常工作的。
在我的另一篇文章《我家的供应商系统又多又旧,能实现持续交付吗?》中提到,我们有了搭建部署流水线实现自动化部署,从而解放我们在部署上的人力和实现持续交付的思路。
但是,由于日常的交付和维护工作占用了我们几乎全部的工作时间,这类重要而不紧急的事情通常都会无疾而终。为了避免这种情况,我们利用每日站会来讨论落地细节和跟踪进度。
我们把站会分为两类:一、三、五讨论日常工作;二、四讨论这个流水线的实施。

这样我们便可确保每天都有进度,并在一个多月的时间内实现了预定目标。
当这个想法实现了以后,我们继续利用周二、四的例会讨论和跟进其他的重要改进点。
每周,我们都会有固定的回顾会议,分别进行故障数据分析、讨论故障处理完毕后的跟进以及遗留问题的跟踪与修复。这样确保我们能持续关注这些重要而不紧急的事务,实现持续改进。
目前,我们的每周固定会议有:
每周故障分析会议——回顾本周收到的故障与业务请求,以及后续跟进情况,趋势分析;
每周遗留问题跟踪——作为全球金融机构,我们有严格的风险管控,包括针对IT系统的,每一个潜在的安全风险问题必须在期限内修复,确实无法在短期修复的,也要遵照严格程序获取延期豁免。这些都需要持续跟踪,避免过期;
每周回顾会议——针对日常运维发现的其他潜在问题和可改进点进行具体讨论,落实具体改进方案,并进行追踪。
所有的事情都和时间与资源分配有关,而时间和资源,永远是紧缺的。通过固定周期的持续关注,能够确保我们日常不留意的重要改进能够持续进行,而这个周期也不能过长,超过两周就会陷入无疾而终的状态。
总结
运维和急诊室一样,资源永远是短缺的。
通过看板的限制在制品原则,确保我们聚焦在各业务方最紧急的故障和请求上。
借用 Scrum 的时间盒理念,通过固定周期的循环例会,确保我们能对重要非紧急的事务保持关注,实现持续改进。
番外篇
利用 Sprint 理念进行个人精力管理
我们经常说时间管理很重要,但其实另一句话更有道理:要管理精力,而不是时间。时间是无法管理的,每个人的时间都有固定的上限,但精力关乎单位时间的效率。
一天的工作时间,少说都有 7-8 个小时,如果你一直坐在工位上持续地工作,很快你就会筋疲力尽,很难再有饱满的精力应对接下来的工作。
在 Scrum 里,每个迭代都叫 Sprint,而 Sprint 就是“冲刺”的意思。因此,通过 Scrum 的方式做一个产品或项目就是一次又一次冲刺的过程。
既然长时间持续工作不可持续,那么把一天的工作拆成一个又一个 Sprint,每个 Sprint 间有个小憩,是否是更有效的工作方式呢?
相信有些朋友也听说过番茄工作法,也就是每工作 25 分钟,小憩 5 分钟,而在那工作的 25 分钟里,集中精力完成一件事情。
但是我们知道,很多时候我们很难把所有工作切成 25 分钟为一个单位。因此,我们可以把它改良一下:以一个小的工作目标或任务作为一个 Sprint,在 Sprint 中,集中精力只完成这个小目标或任务,然后就彻底放下工作,小憩几分钟,回血一下,再开始下一个 Sprint,完成另一个小目标或任务。每个 Sprint 的时间不应该超过一个小时。
通过这种方式,劳逸结合,同样的工作时间,精力和效率则可能完全不一样。这也是我们可以从 Scrum 中借鉴的理念。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721