
本次将主要为大家介绍我们项目发布系统重构过程中,技术选型的考虑以及实践过程中遇到的一些问题和解决方案。
一、背景
荔枝后端微服务化进程较早,目前已有上千个服务模块,绝大多数是Java。得益于良好的规范,旧的运维平台实现了一套简单的自动化部署流程:
对接Jenkins进行编译打包和版本标记
把指定版本的jar包,配置文件,启动脚本一起发布到指定的机器上裸机运行
通过对Java进程的管理来完成重启,关闭应用等运维操作
但是随着开发人员,项目数量,请求量的增加,旧的运维平台逐渐暴露出以下一些问题:
Java实例部署所需资源没有清晰的统计和系统层面的隔离,仅仅依赖于启动脚本中的JVM参数来进行内存的约束,新增实例或新上项目时,往往需要运维人员靠“感觉”指定部署的机器,没有有效地分配机器资源,项目之间资源争用会导致性能问题。
虽然大多数应用依赖的环境只有JDK 7和JDK 8,但一些JDK的小版本差异,以及一些自研发Java agent的使用,使得简单地指定JAVA_HOME目录的方式很难有效地管理运行环境。
开发人员的服务器权限需要回收。一个服务器上可能运行多个不同部门的项目,相关开发人员误操作可能会导致其他项目被影响。
上述问题虽然也可以通过一些技术和规范约束来解决,但天生就是为了解决环境依赖和资源管理的容器技术是当下最合适的方案。
二、技术选型
核心组件方面,Docker和Kubernetes是当下最成熟的开源容器技术。我们对强隔离没有太多的需求,所以没有使用KVM等虚拟机方案,直接在裸机上部署Kubernetes。
分布式存储方面,容器化的项目大多是无状态的云原生应用,没有分布式存储的需求。极少数项目需要分布式存储的场合,我们会把已有的MFS集群挂载到宿主机,由宿主机挂载到容器里提供简单的分布式存储。
容器本地数据卷方面,使用Docker默认的OverlayFS 2。
我们服务器操作系统主要是CentOS,DeviceMapper在生产环境必须使用direct-lvm模式,该模式需要独立数据设备,对已有的SA自动化管理有一些影响。而OverlayFS 2在Linux内核4.17以上已经比较稳定,也不需要太多复杂的配置,开箱即用。
日志收集方面,我们已有一套基于ELK的收集方案,对应用日志也有一定约束(必须将日志打印到指定目录下)。
传统的基于控制台输出的Docker日志方案需要修改应用的日志输出配置,并且海量的控制台日志输出也会影响dockerd的性能,所以我们通过挂载日志数据盘的方式即可解决问题。
监控方面,原有的监控设施是Zabbix,但在Kubernetes监控设施上Zabbix的方案显然没有亲儿子Prometheus成熟和开箱即用。所以在Kubernetes的监控方面,我们以Prometheus+Granfana为核心,使用kube-state-metrics采集Kubernetes运行数据。
相比于Heapster,kube-state-metrics是Kubernetes生态的一部分,从Kubernetes的资源角度去采集数据,维度更多,信息更全面。
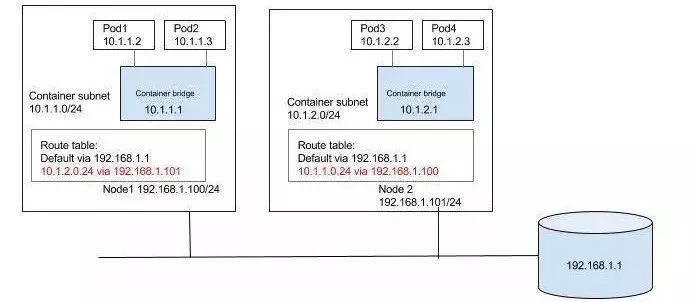
最后是比较重要的Kubernetes网络方面,我们使用了比较新的网络方案kube-router。kube-router是基于三层Routing和BGP的路由方案,其优点如下:
比Flannel等在数据包上再封装一层通信协议(常见是VXLAN)的网络实现性能上更优秀。
比同样是基于BGP和三层路由的Calico来说更轻量简单,易于部署。
Macvlan技术会使宿主机网络和Pod网络隔离,不太符合我们的需求。
在开启Service Proxy模式后可以取代默认组件kube-proxy,Service Proxy的实现是IPVS,在性能上和负载均衡策略上灵活度更高(在Kubernetes 1.8后kube-proxy也有IPVS的实现支持,但到现在还是实验性质)。
当然kube-router也存在一些不足:
项目比较新,现在最新的还是v0.2.5,使用过程=踩坑。
节点间网络必须二层可达,不像Calico提供了IPIP的解决方案。
依赖于iptables,网络要求高的场景Netfilter本身会成为瓶颈。
对于Pod IP的分配,Pod之间网络的ACL实现较为简单,无法应付安全要求高的场景。
基于三层路由的CNI解决方案:
三、业务落地实践
搭好Kubernetes只是一个开始,我们这次重构有个很重要的目标是尽可能让业务开发方无感知无修改地把项目迁移到Kubernetes上,并且要保证实例部署和容器部署同时并行过度。
理想的项目应该有Dockerfile声明自己的运行环境,有Jenkinsfile解决编译打包,有对应的Deployment和Service来告诉Kubernetes如何部署,但现实很骨干,我们有上千个项目,对应上千个Jenkins编译打包项目,逐一地修改显然不太现实。
自动化运维的前提是标准化,好在项目规范比较严谨,符合了标准化这个充分条件。
重新设计后的部署流程如下图所示:
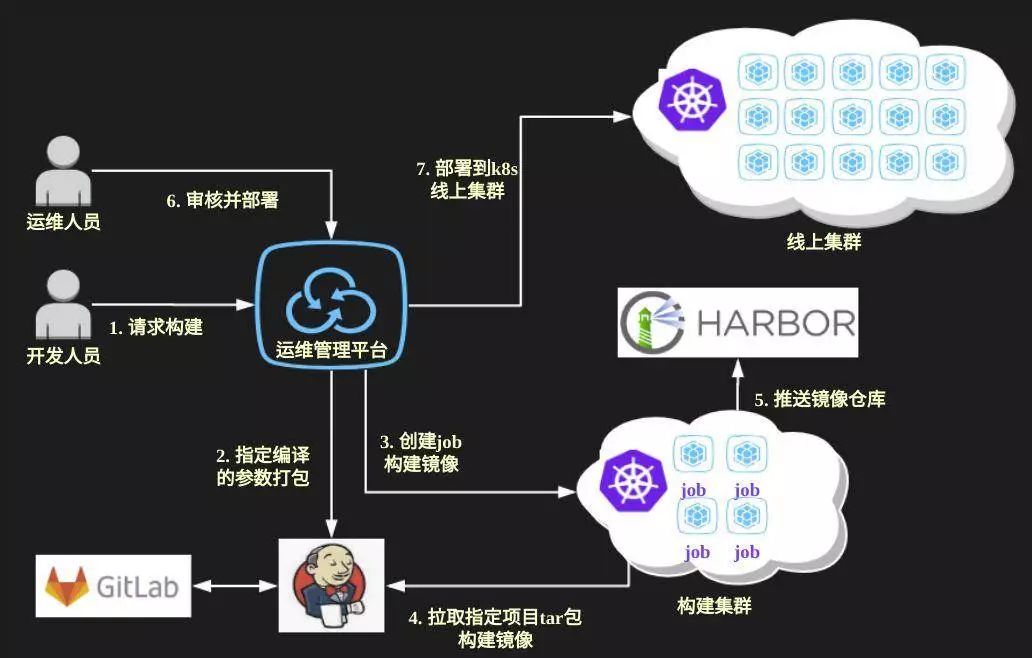
构建方面,项目统一使用同一个Dockerfile模板,通过变更基础镜像来解决一些不同环境项目(比如需要使用JDK 7)的问题。
基于Kubernetes Job和dind技术,我们开发了一个构建worker来实现从Jenkins拉取编译后的应用包并打包成镜像的流程,这样Jenkins打出来的应用可以同时用在实例部署和容器部署上。
在运维后台上即可完成版本的构建:
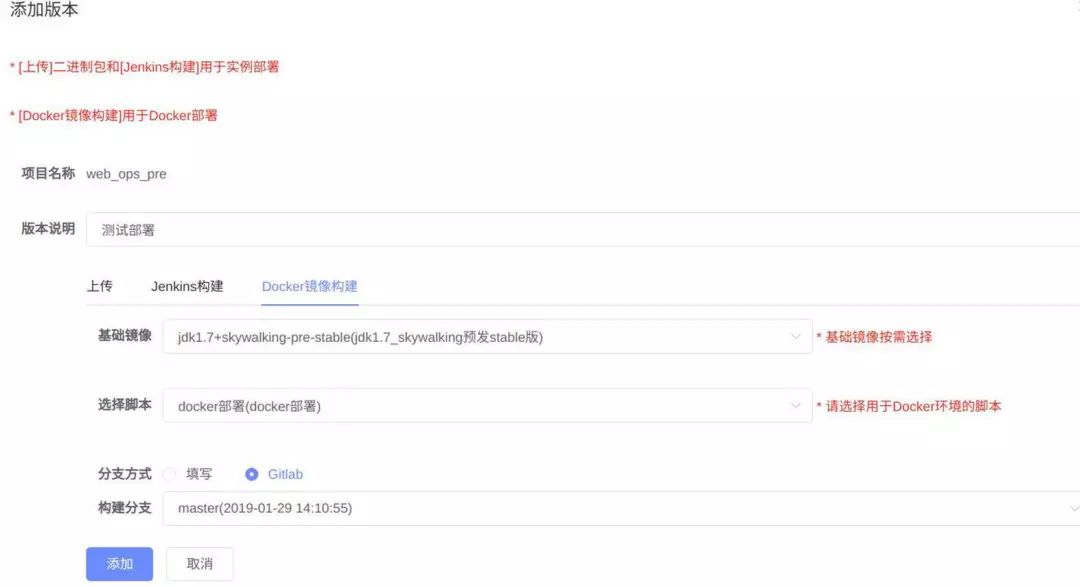
部署方面,项目的部署配置分成两方面。
资源配置一般不经常修改,所以仅仅只是在运维平台上修改记录。经常变更的版本变更和实例数变更则与部署操作绑定。
将Kubernetes复杂的对象封装成扩展成原有项目对象的资源配置参数,执行部署时,根据项目资源配置,版本和实例数生成对应的Deployment和Service,调用Kubernetes API部署到指定的Kubernetes集群上。
如果项目有在运维平台上使用静态配置文件,则使用ConfigMap存储并挂载到应用Pod里。
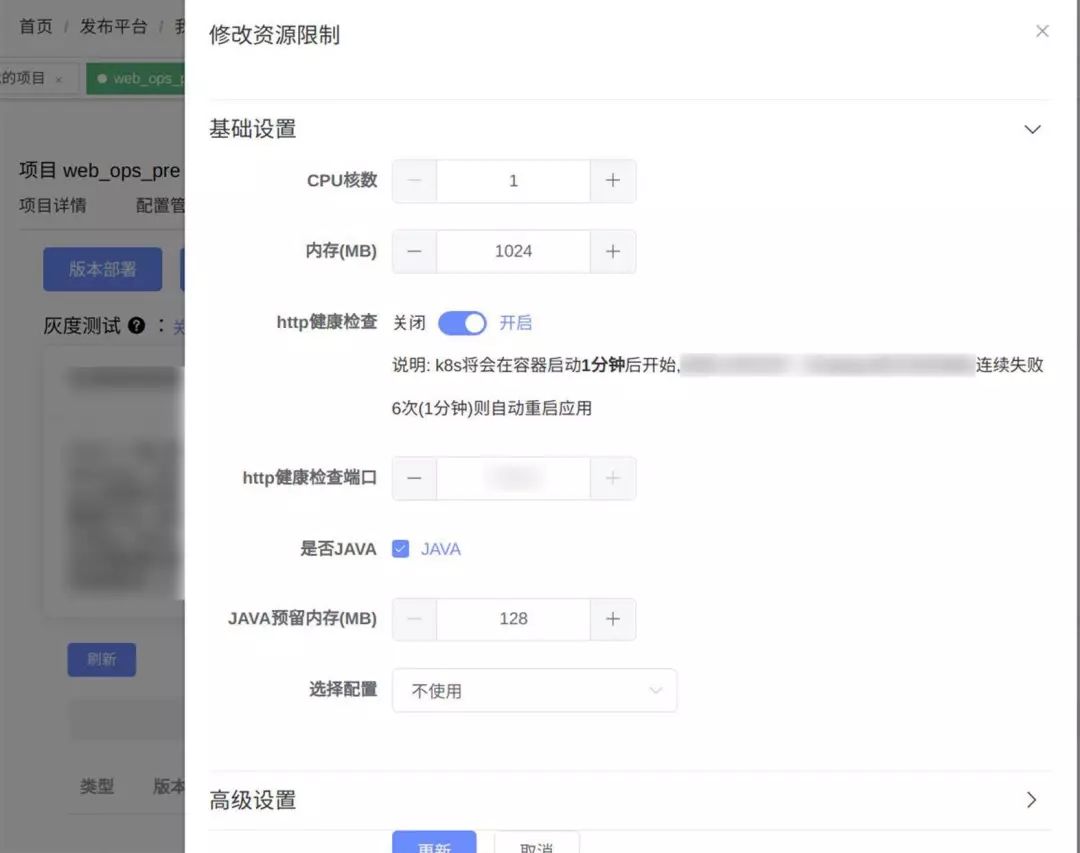
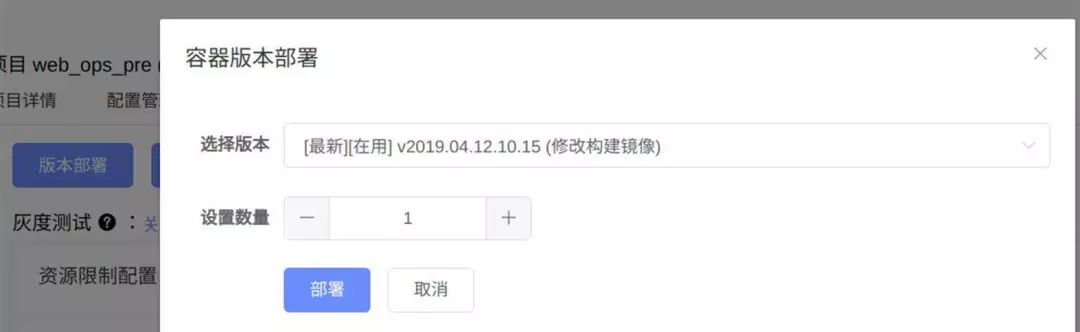
在运维平台上提供Pod列表展示,预发环境debug应用、灰度发布、状态监控和webshell,方便开发观察应用运行情况,调试和日志查看,同时也避免开发SSH到生产环境服务器上,回收了服务器权限。
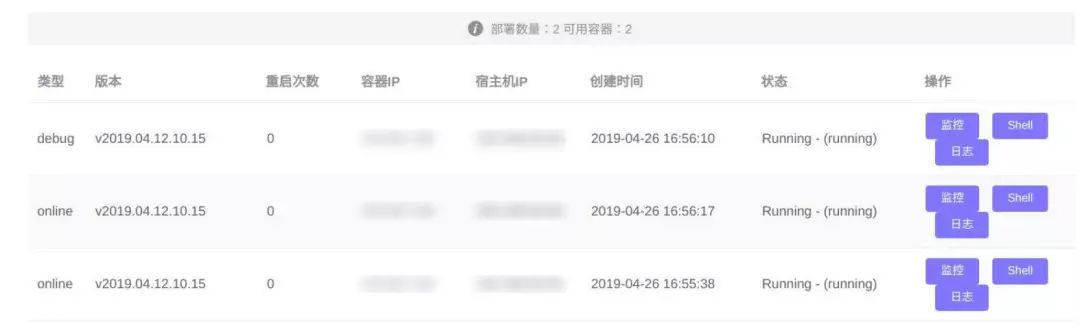
在应用从实例部署迁移到容器部署的过程中主要遇到以下几个问题:
1、Kubernetes集群内的Pod和集群外业务的通信问题。
为了风险可控,实例部署和容器部署之间将会存在很长一段时间的并行阶段,应用方主要使用Dubbo做微服务治理,Kubernetes集群内的Pod和集群外业务的通信就成为问题了。
kube-router是基于三层Routing实现,所以通过上层路由器指定Pod IP段的静态路由,或对接BGP动态交换路由表来解决问题。
2、JVM堆内存配置问题导致OOMKill的问题。
因为JVM的内存不止有Xmx配置的堆内存,还有Metaspace或PermSize,以及某些如Netty等框架还有堆外内存,把Xmx的配置等同于容器内存配置几乎是一定会出现OOMKiil,所以必须放宽容器内存限制。
以我们的经验来说,容器内存比Xmx多20%左右一般可以解决问题,但也有部分例外,需要额外配置。
3、Pod启动失败难以排查的问题。
有一些Pod一启动就失败,输出的日志难以分析问题。我们构建和部署的描述文件都是运维平台动态生成的,很难使用传统docker run目标镜像的方式进行调试。
所以我们在运维平台上提供了debug容器的功能,新建一个和原有deployment一样的debug部署,仅去掉健康检查相关的参数和修改command参数使pod运行起来,业务开发方即可通过webshell控制台进入Pod调试应用。
四、未来
开发经常需要使用的一些调试工具比如Vim、Arthas之类的,现在我们是打包到基础镜像中提供,但这样不仅增加了镜像的体积,而且需要重新打包新的镜像。目前看到比较好的解决方案是起一个调试用的容器并加到指定Pod的namespace中,但还需二次开发集成到webshell中。
跨机房Kubernetes集群调度。当现有资源无法满足峰值需求时,借助公有云来扩展系统是比较好的选择,我们希望借助Kubernetes多集群调度功能做到快速扩容到公有云上。
峰值流量的自动扩容和缩容,Kubernetes提供的HPA策略较为简单,我们希望能从更多的维度来计算扩容和缩容的数量,做到精准的控制。
Q1:容器的Pod网络和外部网络全部打通吗,如何实现的?
A1:因为kube-router是基于三层路由,所以只要在顶层交换上指定Pod IP的静态路由即可,比如宿主机是192.168.0.1,该宿主机上的pod ip range是10.0.0.1/24,那只要在交换机或需要访问Pod的外部主机上添加路由10.0.0.1/24 via 192.168.0.1 ...即可。
Q2:你们如何去保证io的隔离?
A2:目前网络和硬盘的io没有做隔离,暂时还没有这方面的刚需。kube-router对网络IO这方面控制比较弱。硬盘IO方面Docker支持IOPS控制,但Kubernetes我还不太清楚是否支持。
Q3:Job和dind如何配合去实现打包镜像的呢?
A3:首先是dind技术,通过挂载宿主机的docker client和docker sock,可以实现在容器内调用宿主机的Docker来做一些事情,这里我们主要就用于build。Kubernetes的Job则是用于执行这个构建worker的方式,利用Kubernetes的Job来调度构建任务,充分利用测试集群的空闲资源。
Q4:你们Kubernetes里面 统一配置是用的ConfigMap还是集成了第三方工具,例如Disconf。你们在Kubernetes中,APM用的是什么呢?Pinpoint还是Sky还是Jeager?还是其他?
A4:过去的项目配置文件是放运维平台上的,所以只要ConfigMap挂进去就可以了。后来新的项目开始采用携程的Apollo,Kubernetes上就只要通过ENV把Apollo的一些相关敏感信息传给Pod即可。APM方面因为我们是Java栈所以使用的skywalking,也是开篇提到的Java agent技术。
Q5:Macvlan和IPvlan性能非常好,几乎没有损耗,但默认都是容器和宿主机网络隔离的,但是也有解决方案,你们这边是没有考虑还是使用了一些解决方案发现有问题又放弃的?如果是后者,有什么问题让你们选择放弃?
A5:Macvlan之类的方式需要交换机层面上做一些配置打通VLAN,并且性能上并不会比基于三层的解决方案要高非常多,权衡之下我们还是选择比较易用的基于三层的方案,甚至为了易用而选择了更为激进的kube-router。
Q6:容器的多行日志收集如何解决?或者是,很多业务日志需要上下文关系,但是ELK只能查询到单条,这种情况怎么处理呢?
A6:容器多行日志的问题只存在于标准输出里,我们应用的日志是输出到指定目录下的,Filebeat有一些通用的多行日志解决方案。因为日志是存放在ES里的,所以可以通过调ES接口拿到某个Pod一个时间段里的日志,在UI上把它展示出来即可。
Q7:请问用的存储是什么?如何集成的?存储架构是怎样的?有考虑过Ceph吗?
A7:只有极少部分项目需要接分布式存储,并且对存储的管理,IOPS限制等没有硬性要求,所以我们把已有的MFS集群挂载到宿主机,再挂到容器里来实现。
Q8:Jenkins的Slave是用Pod Template创建的吗?Slave是Job共享还是需要时自动创建?
A8:Jenkins还是传统的master-slave单机部署模式,因为版本比较旧连Kubernetes Slave都不支持,所以我们只是调用了Jenkins的API来完成这个部署的过程。
Q9:请问镜像大小是否有做优化?生产中有用alpine之类的base镜像吗?
A9:暂时没有,我们镜像的大小大约在100-300M之间。而且比起镜像大小的优化,运行环境的稳定和调试的便利更为重要。镜像有分层的策略,即使是很大的镜像,只要每次版本部署时更新的是最底层的镜像就不会导致每次都要拉取完整镜像。
作者:陈偲轶,荔枝研发中心DevOps工程师
来源:Docker订阅号(ID:dockerone)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721