
文根据王青老师在〖Gdevops 2018全球敏捷运维峰会成都站〗现场演讲整理而成。

(点击“此处”获取王青演讲完整PPT)
讲师介绍
王青,JFrog中国首席架构师,曾在新浪、爱奇艺、IBM、HPE、VIPKID从事研发架构和咨询工作,曾在中兴通讯、宜人贷、顺丰、易保科技等大型企业负责DevOps落地。专注于微服务架构、持续集成、持续交付、DevOps、容器化平台建设等等。
大家好,我是来自JFrog的王青,今天主要想跟大家分享一下关于传统企业如何真正落地DevOps的实践经验,首先会带大家简单看看几家传统企业实施DevOps的典型案例,再重点介绍如何使用一些工具链迈出DevOps落地的一步。
主题简介
1、DevOps现状
2、传统企业DevOps案例
3、DevOps工具链落地之路
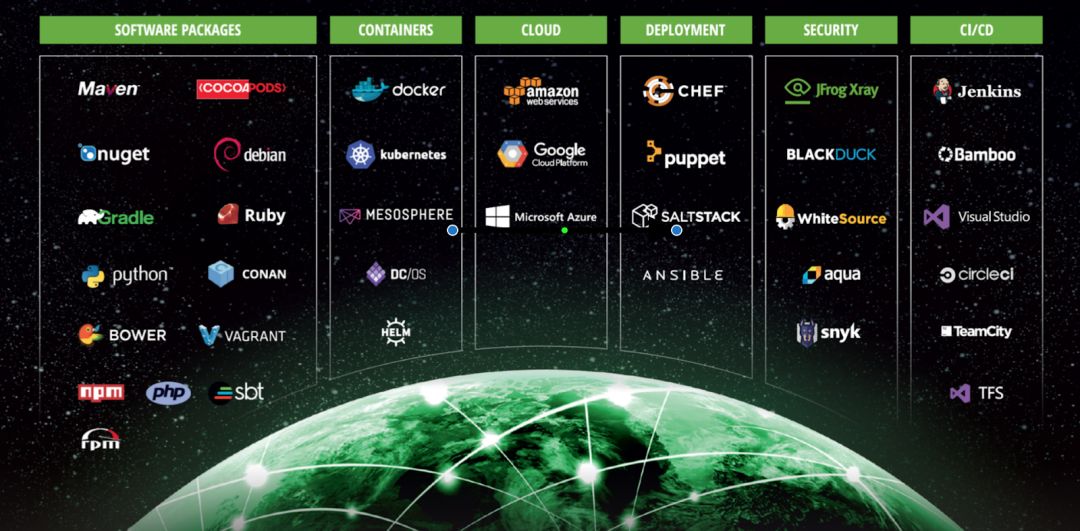
上图是做持续交付需要掌握的工具。以前研发这一块用到的技术比较多,现在可以看到,如果要做微服务的部署,运维要掌握的技能是越来越多。这里面比较有意思的是研发与运维的博弈,如果你的运维能力跟不上,就会引起研发的吐槽,觉得你支持得不够好,他就会往后推自己的DevOps工具链,所以研发与运维之间会有博弈在这里面,是一件挺有意思的事情。
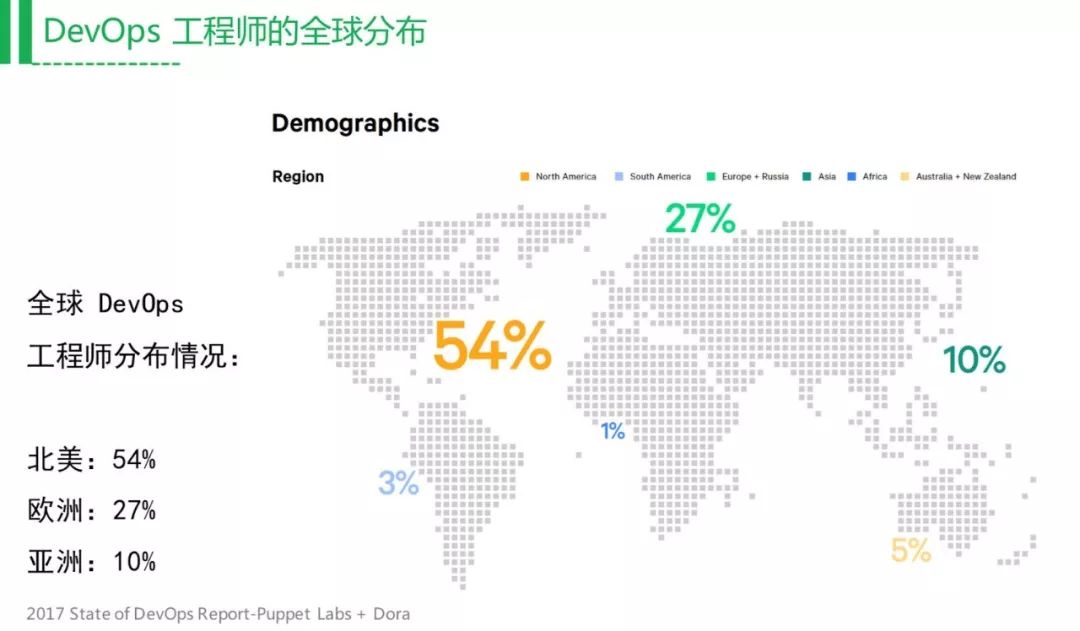
从全球的角度来看DevOps的现状,上图是17年Puppet Lab发布的数据,可以看到,占最大比率的是在北美,因为硅谷这块有大量的DevOps工程师在里面,但亚洲只占到全球的10%,今年我相信这个数据肯定要大很多。
从薪资的角度来看,Stack Overflow网站做了一个统计,从全球调研了6万名工程师,排名第一的大家肯定没有想到,是DevOps专家,第二是机器学习专家。如果你是做DevOps的,那你可以给领导看一下是不是应该涨工资了。

要评价企业的IT效能,部署频率高效的是一天部署多次,低效的是一个月部署一次来算的。从代码提交到上线,这个时间概念很重要,大家可以自己内部去收集一下数据,如果是小于一小时,那就相当超前了;然后是故障恢复率,如果小于一小时,也说明是高效能的企业。
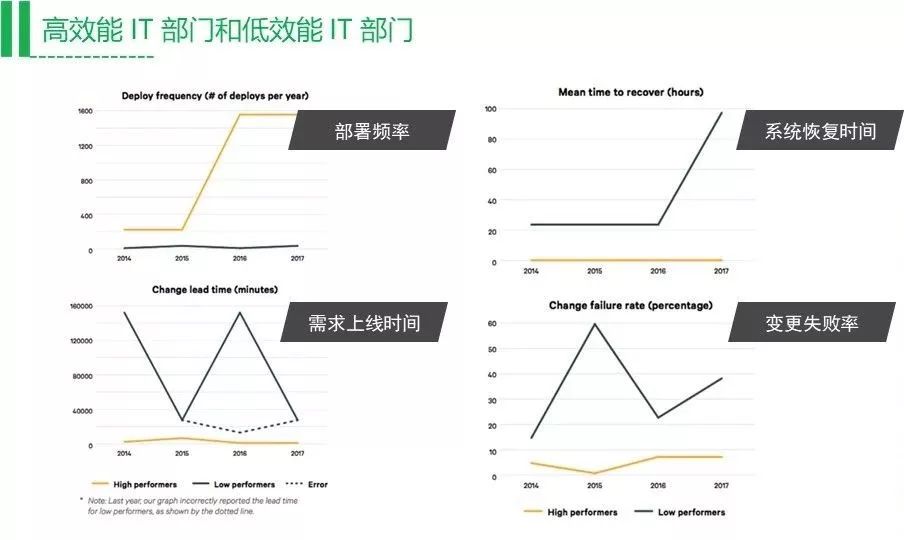
从上图可以看到,黄线是高效能的团队部署频率,从16年到17年,它的部署频率是越来越高,黑线的低效能团队则没有什么变化。但是低效能的团队从16年到17年,它部署系统的恢复时间越来越长了,这是因为现在业务压力越来越大,一次性上线的东西越来越多,交付的东西变多了,就肯定会出问题。这个数据是公开的,在网上可以搜得到。

传统行业,比如说ING,是一家非常超前的公司,13年开始就做DevOps,所以DevOps不是说落地,而是一个很长时间的旅程。他们600人的研发团队,是很难管理的,13年的时候他们就是手工来做,现在完全达到了自动化的流水线交付方式。德国工业制造4.0的概念对我的影响很大,因为交付方式已经发生了变化。在工业4.0的流水线里,人与人之间是不说话的,他们怎么去协作?完全依赖系统,每个人的工作台上有一个大屏幕,屏幕会把在他前面的所有交付信息呈现出来,前面发生了什么事情、有什么需求、下一个环节要发到什么地方……所有软件工程和现实中的工业工程的理念是一样的。

上图是ING目前所用的工具,可以看到非常多编排和检查的工具,一个团队很难管理这些东西。交付方面也有不同的部署工具需要支持,这样就带来一个什么问题呢?开发团队想用的工具,运维团队支持不了,那开发就说我可能不需要运维支持了,因为申请一个Jenkins机器跑测试,到运维这边发账号过来需要一个星期,但是开发可能等不了这么长时间,所以开发会考虑自己搭一套,可能半天就搭好了。这样会导致一个什么情况?
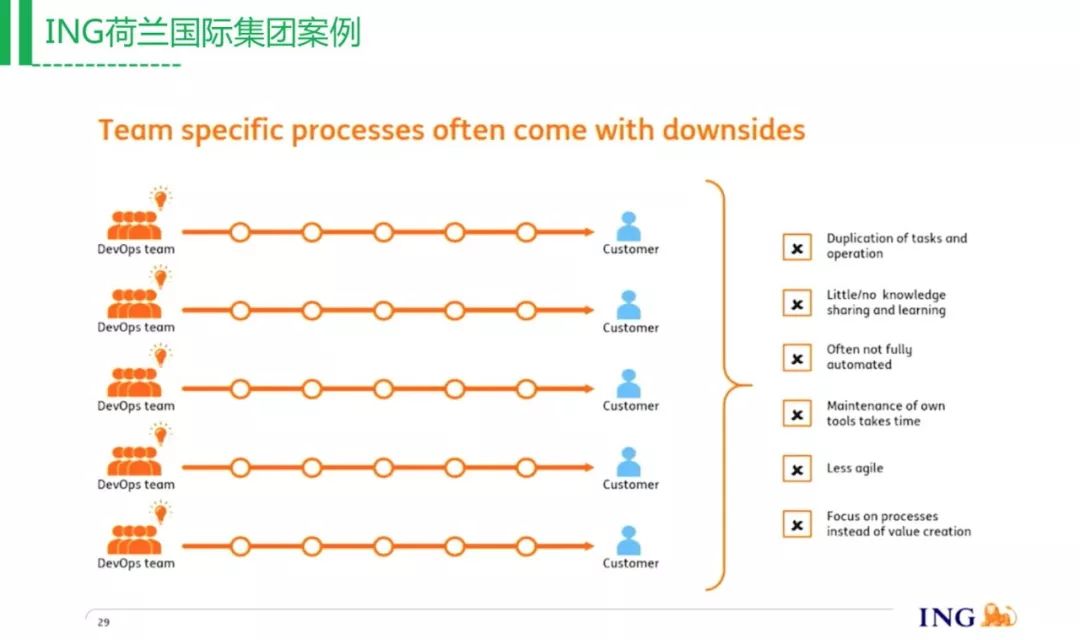
每个团队自己维护自己的交付流水线、自己运维,这时运维做的事情就很被动,这个研发要这样部署,那个研发要那样部署。这样运维想从后往前推交付规范,是根本推不动的。
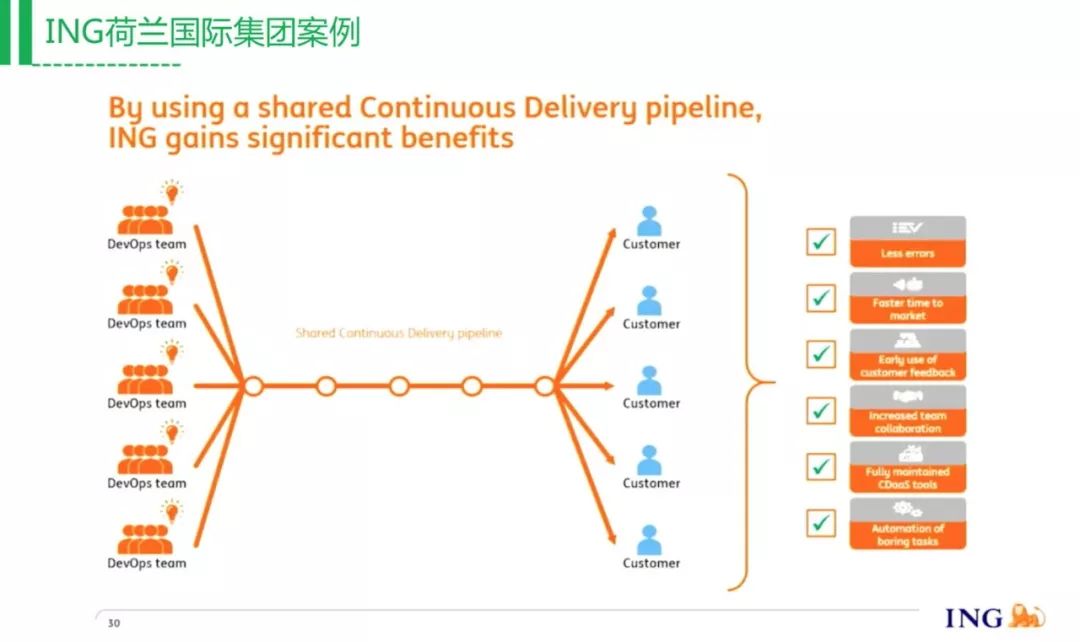
ING的解决方案就是,不改变开发现有的流程,还是让你去用,只不过让你来用运维团队的工具,把账号、权限等设置好,之前怎么做的还是怎么做。你可以看到这个时候运维的能力和价值就体现出来了,不光是运维你的应用,还要把前面的工具管理起来,这是运维从后往前推的成功案例。
其实研发也不愿意去管这些工具,他们每天压力很大,有问题还要每天去重启。所以运维做的这个事情是价值很大的。管理工具现在还不够,ING内部还有一个社区,他们会邀请一些团队上来做一些实践,比如说同种类型的,会给你列出来怎么做,然后其他团队来复用这个流程。这样是一种见效快、对业务改造少的方式,不管用什么语言,都用这个方式来做。他们落地这个方案,所有的服务都会统一管理。
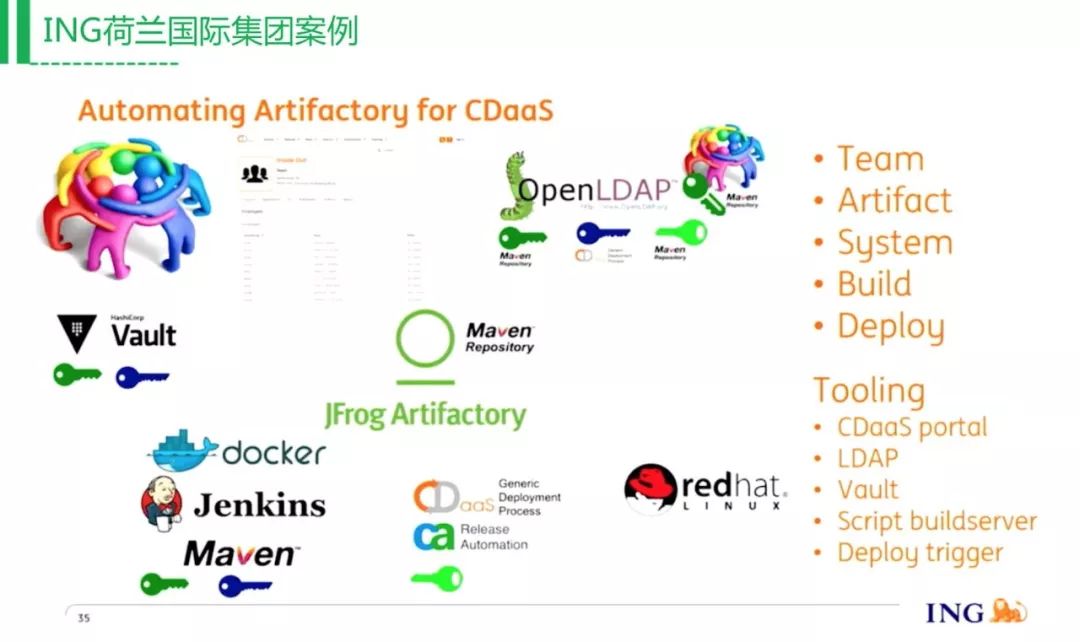
打通整个过程也比较直接,因为这些开源工具都比较支持LDAP打通认证,它们对密钥的安全要求比较高,所有的密钥通过Vault去进行加密存储。回到公司的角度来看整个流程,每个业务团队看到的流程都是一样的,代码扫描,把这些扫描的结果放到二进制里面,再做后面的东西。银行业对这个要求比较高,他们也有一定的需求。最后总结的是,ING DevOps落地大概有4年的时间,发布频率每个月达到12000次,但是减少了50%的线上发布事故。

美国的数字化银行CapitalOne的报表工具Hygieia也是很出色的,他们的痛点也是从传统开发方式转型,用5年的时间做了这个规划,实现每天发布4次。他们有很多的测试开发,从手工测试的角度变成写case、写自动化脚本的角色。所以他们从手工部署慢慢转型变成了自动部署,也有公有云的一些服务。他们会设置很多质量关卡,比如说用Sonar进行静态分析,这个也是开源工具,像腾讯也会使用Sonar去扫每个人提交的代码。
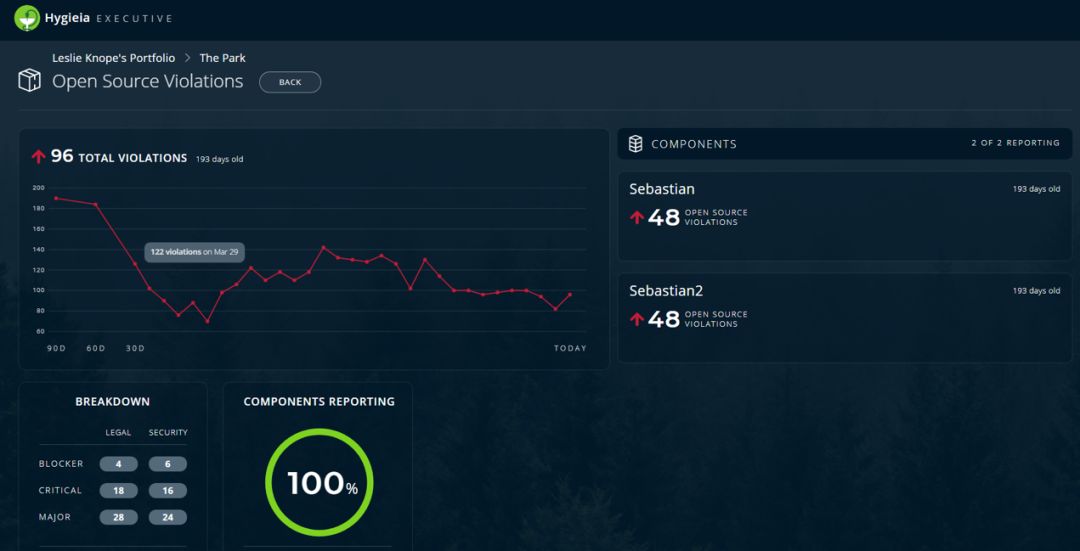
他们开发了基于持续交付工具提供的报表,提供了软件交付生命周期里面的一些可视化页面,比如说频率、代码、从构建到上线的一些数据化的指标,都是通过这个大屏显示出来。这是开源的,大家可以去安装测试一下,也是JAVA开发的。它能收集各个工具的数据,基于这些数据做一些查询、做报表的展示。CapitalOne在5年之内实现了刚才的这些转型,所以一个银行能做到这种以社区为中心、能够推动这种自主研发能力是非常难得的。

国内一个比较大的银行最开始是用FTP管理二进制包,这样做有很多痛点,研发的部分在不同的地点,各个中心很难协同。比如说你的包比较大,那达到50Gb/s时基本就挂了,所以要经常维护。首先评估,用一个专业的工具去管理起来,还有镜像的实时分发。使用Artifactory之后,可以实现持续交付,根据环境,每个环境有一定的仓库权限。现在互联网上有大量的开源软件漏洞,公司内部要提供一个统一受监管的仓库,不是什么包都可以直接下载。
那么,怎样迈出DevOps的第一步、用一些工具去做公司内部的实践?我接下来将分享一些工具链落地的经验。
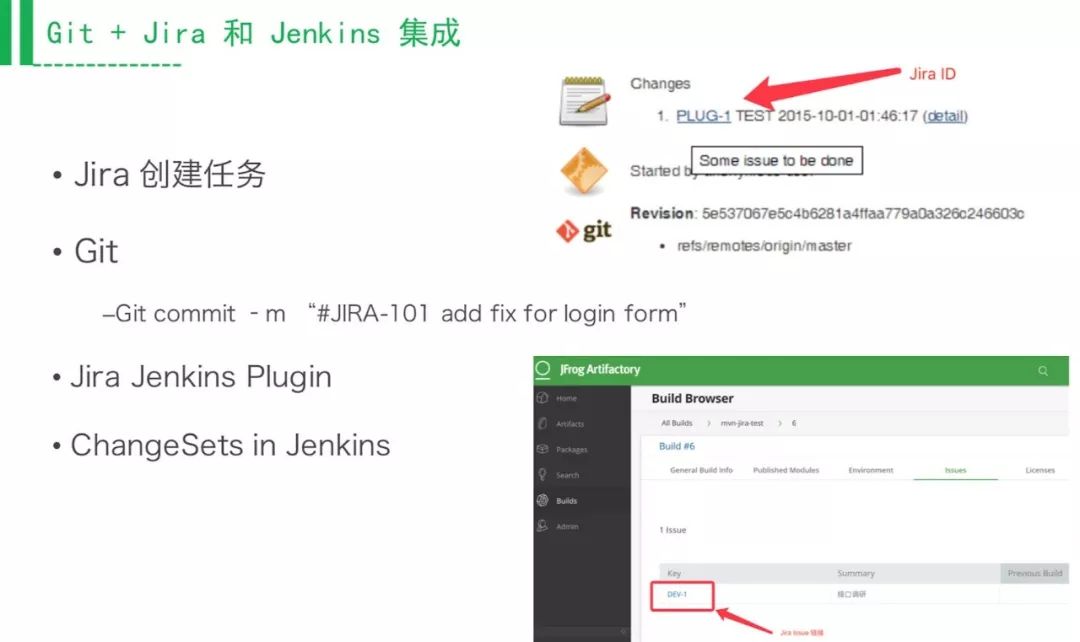
代码和需求要进行关联,关联之后才能看到需求从代码提交、需求创建、测试再到上线这个平均时间是多少,还有就是提供给运维部门包相关的信息,以前拿到这个包什么都不知道,这个包解决什么问题和需求都不确认。如果把代码提交时把需求ID带上,就可以用Jira-Jenkins插件把Jira信息收集起来。Artifactory上面会有一个记录,是可以点到一个内容上面去,同样的数据,用其他的管理工具也是可以做到的。
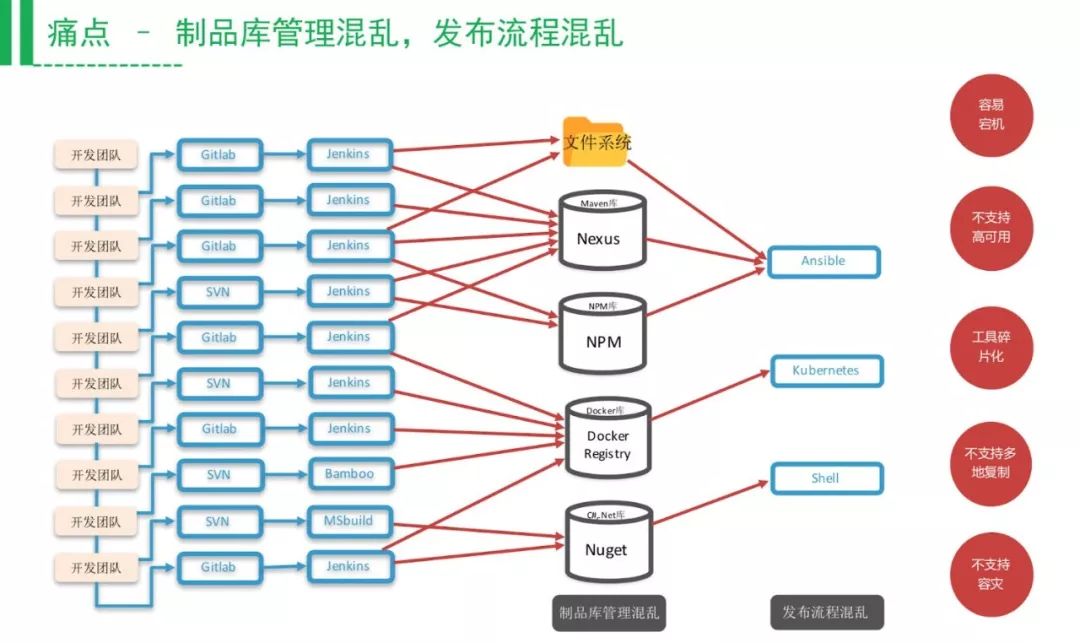
上图是很多大公司的痛点,公司内部有各种各样的私服,需要独立维护,配置权限、高可用、容灾备份、配置管理,同时你的部署脚本要对接各种私服,难以标准化你的CICD流水线。

第一步应该把这些进行统一管理,在构建的时候统一存在一个地方,这样有什么好处呢?以前需要指定版本去发包,现在可以让机器自动地找到这一次适合发包的一个最新版本。这也是工业生产线的一个概念,京东、亚马逊的物流都是机器人在送包,现在京东的无人车已经送到大学里面了。
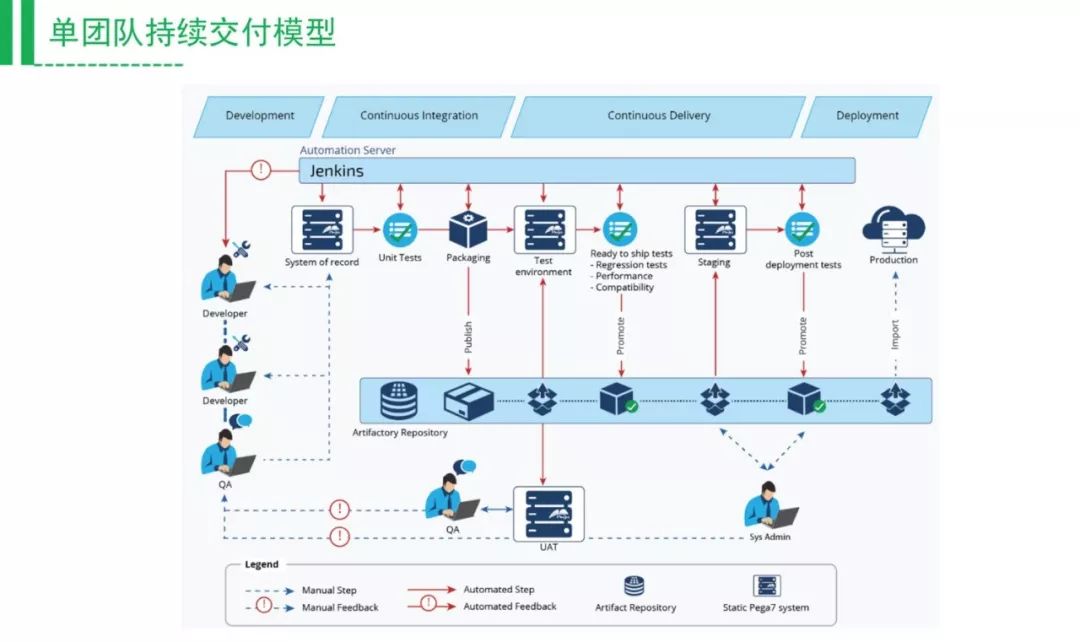
以上这个流程是单团队实时交付的一个模型,实现的是自动化交付的流程。我建议大家可以根据自己企业的情况,在公司内部画一个这样的图,看看自己公司是什么样的状态。在上面的研发构建代码之后,做代码合并,合并到主干做一个构建,需要把这些信息记下来。比如说需求的ID、构建的代码地址、单测是否过了,还有覆盖率也会集中在这个上面。
把你的包上传到二进制仓库,如果通过单元测试,测试会收到通知,进行测试环境的验证,验证通过了,会记录通过的元数据到包上。可以手动,也可以自动化,测一些兼容性接口。很多工具的测试接口,可以把它的结果分析出来,再写到你的仓库里面。这样做之后,开发、测试及运维之间无需沟通交流。之后我们再发布到新的测试环境,模拟的一个生产环境去测试,同样这些测试的信息,手工的测试覆盖率是70%,也写在这个包上。最后运维拿到这个包,会拿到测试团队的一个评价,是不是能够上线,之后运维用自动化脚本把包放到生产环境。
这是单团队交付的一个流程,通常这个流程会配合工具来调度,这里面包含了很多自动化的步骤,当然也支持人工的步骤,很多的环境是需要人工的,比如说审批、审核测试。
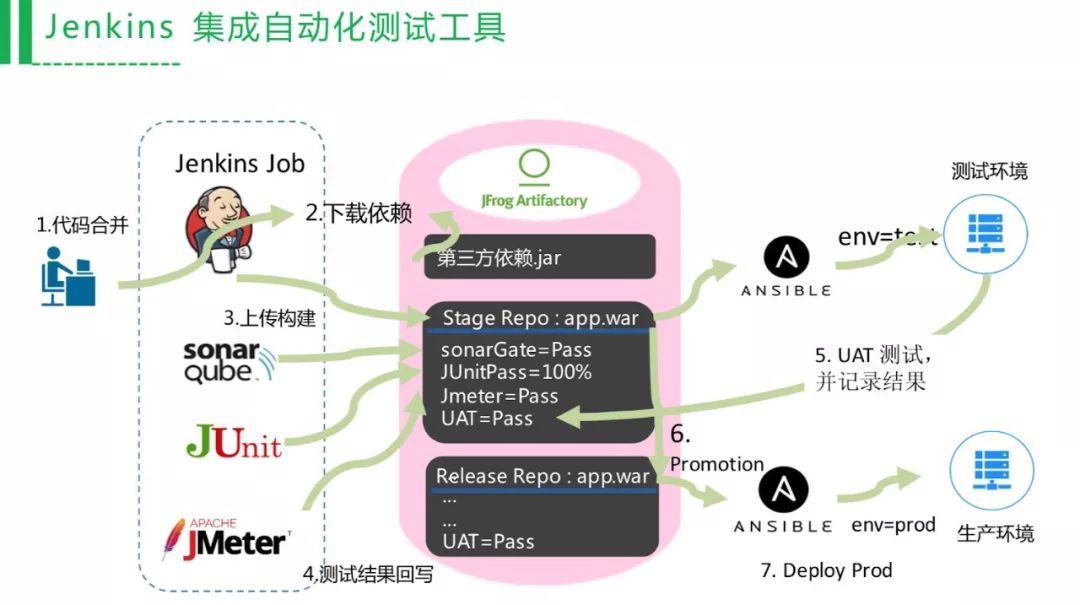
从二进制包的角度来看,Jenkins构建的时候,应该是统一下载受信任的第三方包,不应该是从多个的文件夹/私服去拉取依赖包,保证每个人提交的时候,依赖都是一样的。避免同一个版本,有的用1.0有的用2.0。测试环节的数据都是写在交付件上的,会根据拿到的这些数据进行自动化的测试环境的发布,通过了之后,会升级到生产环境仓库,同时可以自动触发生产环境的发布,减少手工部署环节。
所以在公司内部,我们运维团队就是定义这个质量关卡。流水线落地的时候,可能研发团队不愿意配合,所有最开始的标准不能定得太高,可能覆盖率最开始只有20%,没有关系,就从20%开始。雅虎花了一年时间,把单元测试从0上升到90%。
从二进制的交付角度来看,交付流程里会记录所有的测试结果,这是流水线里的信息共享,打通研发测试信息沟通的一个屏障,打通部门墙。这个事情是很难的,但是我们可以从信息系统上去做信息的分享。前面讲的是写了很多元数据,但是怎么去消费,让机器自动化挑包来做环境部署?根据质量关卡去写部署的脚本,去帮机器过滤,让机器知道这个包应该是什么环境,而不是去向测试团队确认。

光有应用还不够,还要有环境的配置,应用相关的配置文件怎么去做到不同环境不同配置?不同测试环境的应用配置应该存在不同的代码分支里,然后在部署应用时,把这些配置文件从不同的分支拉下来,这里是通过配置中心实现统一管理。还有数据库版本化的脚本,这些脚本也是存在的,数据库的每一次变更应该变成一个版本化的变更,运维拿到这个包的时候,同样从一个分支拿到相对应的变更列表,保证每一次发布拿到的是全量的东西,包含所有变更历史,而且可以进行自动化特定版本的发布。
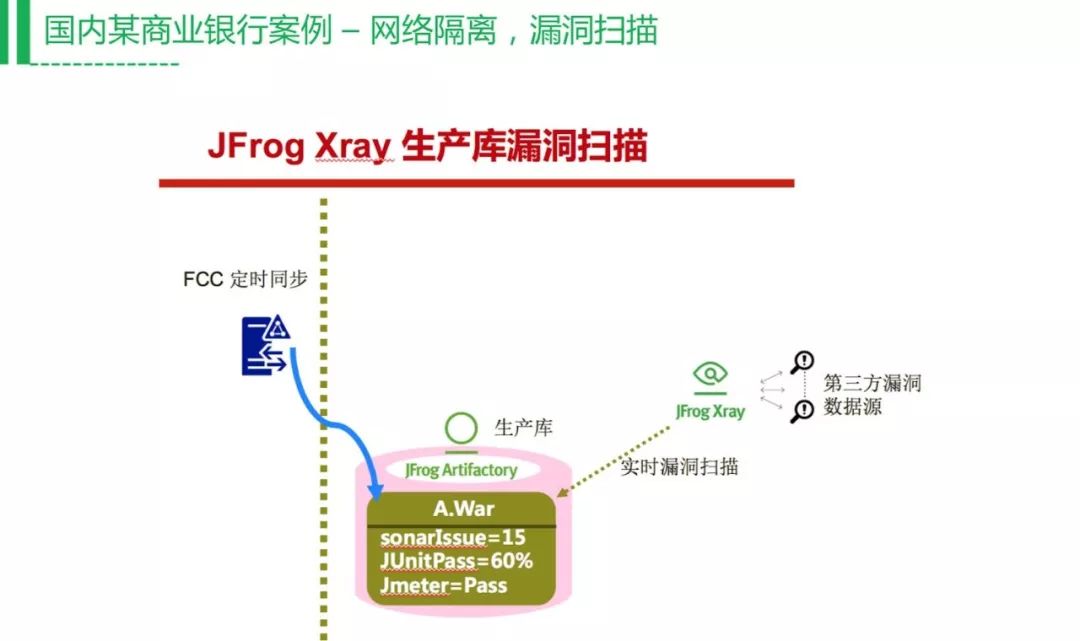
现在比较火的就是容器,但容器里有很多漏洞,大家会去关心容器镜像漏洞扫描,这个也是银行案例,会去做包的第三方依赖的漏洞扫描。如果没有漏洞才会推到生产环境,同样的到生产环境,他们的安全级别比较多,所以还要做第三方软件漏洞扫描,保证线上环境的安全。
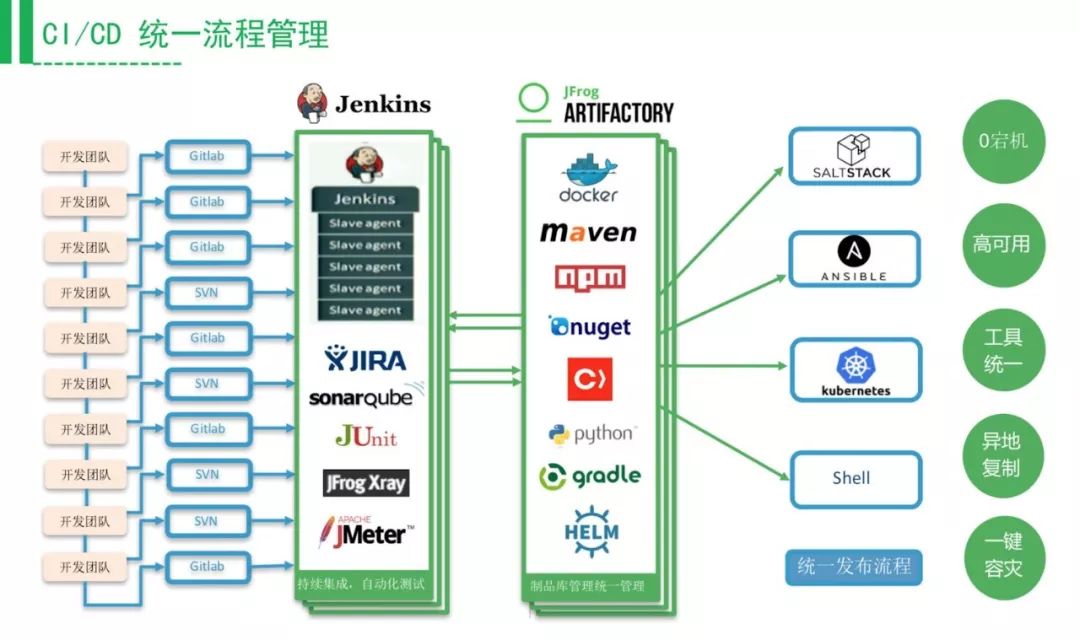
有了配置、运维、数据库的统一化管理,可以考虑再往前面推,提供公司基本的CICD工具。这个时候一般是一个团队一个团队地落地DevOps,绝对不是强制性地去做这个事情。部分团队落地之后,不需要研发任何的改造,上来就可以看到扫描的结果,就会看到效果了。可以把这个报告发给各个业务团队的领导,他们就会知道每个团队的成熟度,会去要求研发提高代码质量。由此,运维团队的责任会越来越大,因为他们负责整个公司的流水线,而研发则越来越轻松,他们要关心的就只是业务了。
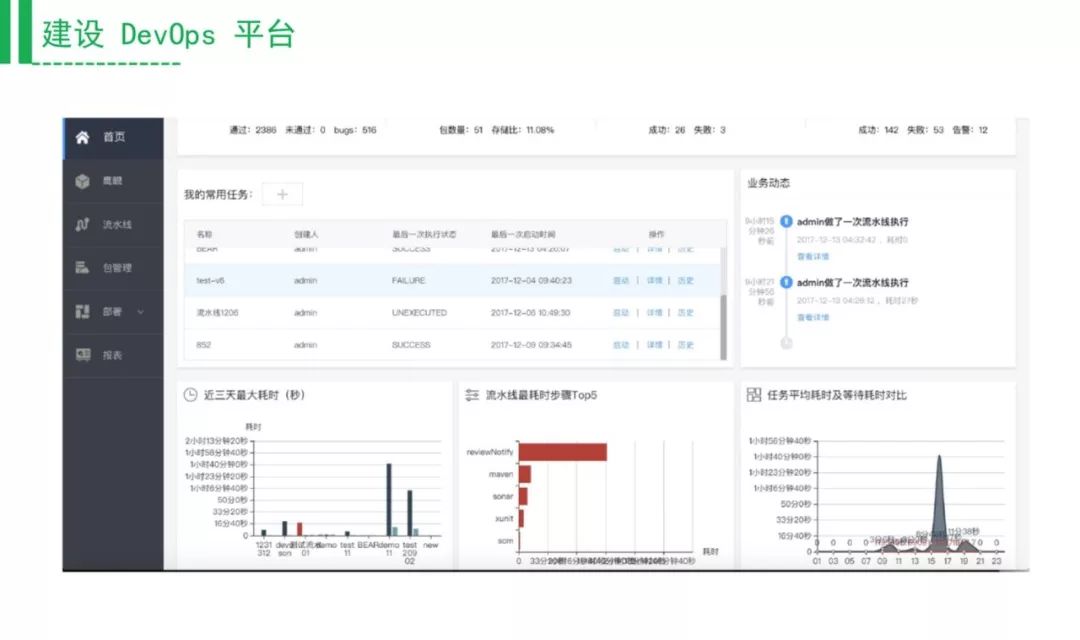
再往前走一步,当管理了所有工具之后,你的需求比较明确了,就可以自己研发一个DevOps平台。这适合研发能力比较强的企业,当然你也可以运用第三方来做,可以实现整个公司的耗时展示,可以调接口来做这个事情。然后你的研发效率是不是碰到瓶颈了,有了这个工具之后,可以进行封装。这是包含成本的,我们建议先打通工具链,确认你的研发比较平稳了再做这个设计,并不是一开始就来平台改造大量的业务交付流程,需要有一个过渡的过程。
有了这个平台之后,可以做很多想做的事情。底层的这些开源工具给你接口返回数据,你的代码平均测试通过率,可以做一个团队交付能力的画像,看看团队的交付能力是什么样的,发现了问题如何做改进。这里面可以看到,你可以定义一些曲线,曲线就是同行业的平均指标,通过这个可以看到你的企业是否达到业界平均水平。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721