
本文根据马致杰老师在2018年3月23日【DBAplus广州站运维技术沙龙】现场演讲内容整理而成。
我们都知道目前大多数互联网公司已经实现了内部的DevOps平台,但我今天的内容主要是非互联网公司如何实现DevOps、用DevOps去解决什么痛点。我会从三方面来分享,首先是我们做DevOps转型的背景,然后是传统企业的一些案例分享,最后是如何落地DevOps。希望今天分享的内容能对大家有所帮助。
一、我们为什么转型做DevOps
JFrog成立于2008年,总部在硅谷,2016年底开始做中国的业务。我们认为统一的二进制管理是一个刚需,所以我们专门成立了一个团队去服务国内各个行业的顶级公司。目前我们的客户遍布各行各业,他们通常会基于JFrog的产品去做全公司的DevOps平台。
我们做的是统一的包管理系统对接到DevOps整个生态,所以对接DevOps整个工具链并且落地CI&CD,都是通过JFrog的平台去实现。因此,我今天会分享如何在公司内部实现这样的统一的DevOps平台。之前很多公司也会在YouTube上分享他们的DevOps案例,大家有兴趣可以去了解。
在正式分享案例之前,我想讲一下为什么我们要转型去做DevOps。
去年有一家公司做了一个部署和管理工具,他们每年都会出一个报告。去年他们的报告为这些公司做了一些“画像”,将这些落地了DevOps的公司和世界500强公司作对比,划分为高效率、中效率还有低效率的三种类型。他们统计了每个公司的部署速度,代码提交到线上的时间等参数,还有比较关键的是考察维度是回滚,就是解决线上问题的时间。
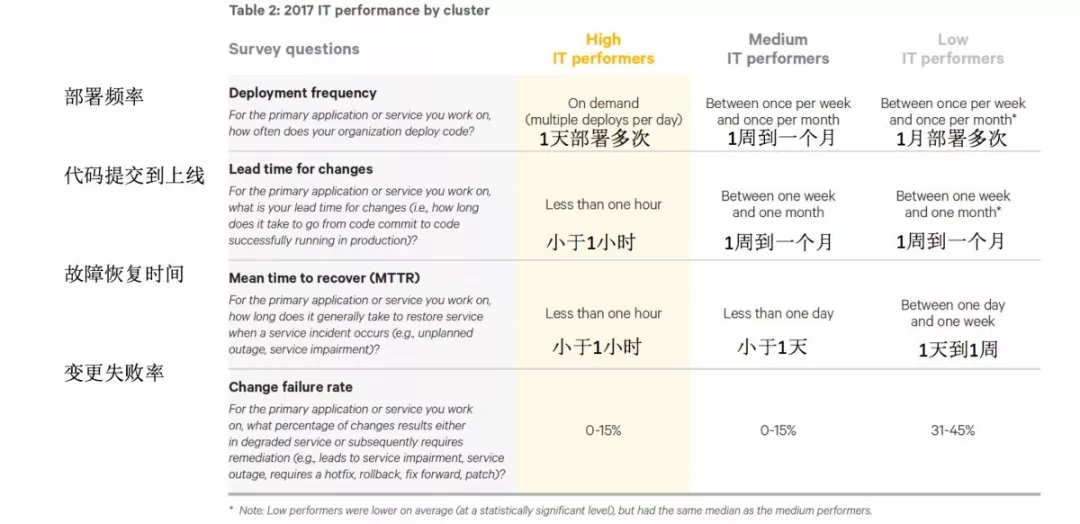
如上图所示,对于高效率的公司,他们可以一个小时之内解决一个线上的问题,因为他们已经实现了持续交付、快速回滚。部分公司之前也是低效率的,但落地DevOps后,回滚周期从一周、一天减少到一小时,都是一两年之内实现的事情。
所以今天我会分享这些公司如何从低效率转变为高效率。
也许很多人会问我为什么需要快速发布?这是因为他的公司并不是一个互联网公司,解决线上的问题只是众多应用场景中的一个,对此我可以做更多的分享。
二、传统企业案例分享
第一个案例是CapitalOne。CapitalOne是一家成立了20年的银行,虽然跟美国一些大银行比历史比较短,但他们现在也是上百亿美金收入的规模,是一个非常大的银行。
他们最近发布了一个开源的DevOps报表平台,并总结了一些痛点,如下图所示:

首先是他们无法统计交付流程的一些数据:比如开发团队代码的速度,部分流程是纯手工的(部署、测试都是手工的),这些痛点会产生很多问题。他们的多模块集成、发布频度都是一个月一次,所以之前这是一个发布比较低效率的公司。转型后他们是每个季度做一次生产发布。
他们的转型是在五年之内从瀑布开始到敏捷,从手动构建、测试和部署到自动化(下图1),虽然美国的银行都会用公有云去做,这个跟国内有点不一样,但是他们也都会用开源工具,之前都是比较封闭的去做DevOps,现在都是全开源工具链,去实现他们的DevOps平台。
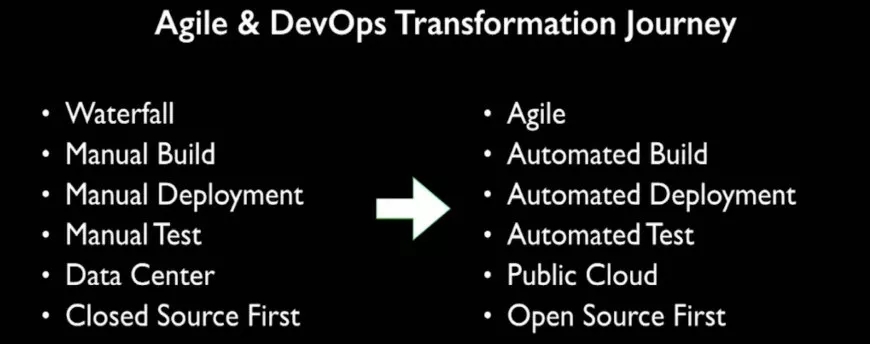
(图1)
他们制订了一个规范,也就是他们的流水线质量关卡,在公司内部打通同一个流水线。如下图所示:

一个中央团队搭建了一个流水线,这个流水线有16个质量关卡。也就是说,一个包要过16个质量关卡才可以上线,这个也会涉及到组织中人员审批环节。当然,上线的速度只是一部分,还有另一部分就是漏洞扫描。
版本控制、集成测试、性能测试都是在同一个流水线去做的,所有的产品线都要过这16个关卡。比如,如果代码的测试覆盖率不能够达到80%,中央团队有权不让产品上线,所以他们根据上线规范制定了16个质量关卡,这些数据都是基于Jenkins、JFrog API去统计。

Hygieia是最近很火的开源项目,Hygieia也是基于Jenkins、JFrog这些开源工具去做一个可视化报表平台。这是一个开源的项目,所以你们也可以去下载试用,或者基于你们的工具去做一些定制。
通过Hygieia,我们可以看到每个流水线阶段的耗时等信息,这样可以开发可视化的页面、发现每条流水线的问题或者瓶颈。哪个团队效率最低,每个产品线都可以有一个可视化的页面。

现在他们转型之后,通过Hygieia的一些数据和报表,实现了自动化测试、自动化部署,然后每个生产环境的部署发布都是一个Sprint一次。所以一周一次的发布,代码提交都是一天上百次,从他们的这些数据来看,效果还是非常明显的。
ING是一个欧洲的保险公司,他们有600个团队,人员规模特别大。他们从2013年到现在落地了一个全公司的DevOps平台。
之前他们每个产品线都会独立维护一个Jenkins、JFrog、Gateline,每个产品线都是自己做部署,各自维护他们的工具,所以中央团队无法去评估公司的效率,无法推广标准化的最佳实践。有可能某一个团队下载一个有漏洞的包,然后发布到线上环境,安全团队、中央团队、领导层无法知道如何控制风险,也无法落地最佳实践。
他们的落地策略是通过权限去打通工具链,所以现在不同的产品团队,会向中央团队提供的Jenkins集群、Gataline、Github去做发布。
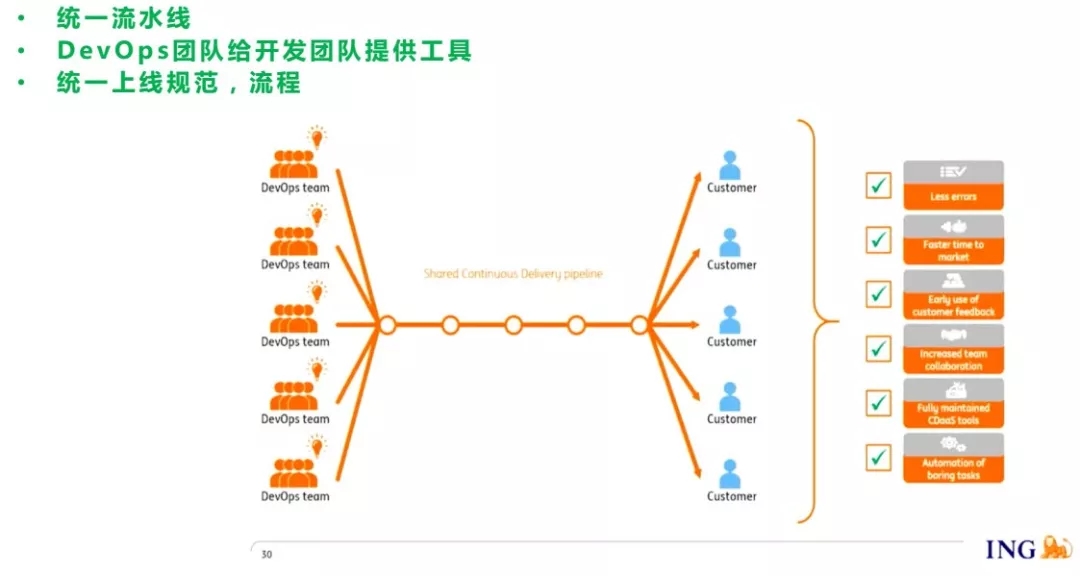
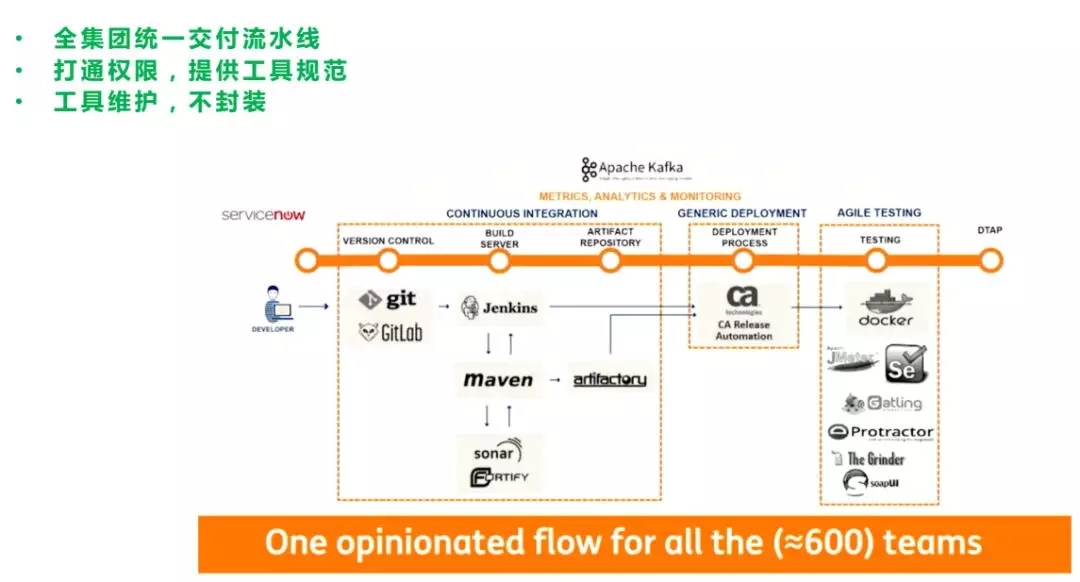
ING并不封装工具在云平台上提供服务,而是打通工具链的权限。现在他们可以实现统一的规范、统一的控制和流程,下图是ING荷兰国际集团的做法,值得大家去借鉴。

对接了工具之后,会收集CI和CD各个流程中的数据做一些统计和分析。他们提供的工具链平台叫CDaaS,上面不止是有认证,也有一些社区、wiki、最佳实践,所以这个平台变成社交DevOps,每个人都会在上面分享自己的最佳做法,整个文化氛围也会变得更加开放。
他们现在支持了500种应用交付,都是通过一个平台做报表分析、漏洞扫描的控制,从提交需求到上线小于6周,线上的事故也大幅度减少了,所以这是一个值得去做的事情。

一个这么大规模的保险公司,而且是非互联网公司,已经实现了每个月上万次的发布,这样的案例很值得参考。
之前Adobe是做桌面的软件,他们的Photoshop很多人都用过。从1992年开始,他们开始做一些Cloud Based的软件,也就是转型到公有云软件提供商。Adobe的研发团队有近一万人规模,他们让每一个发布的包,不管是一个JAR包、WAR包或者一个镜像,跟需求、构建等绑定,它还会进行漏洞扫描,确认通过再做发布,这些都是通过同一个流水线去做。
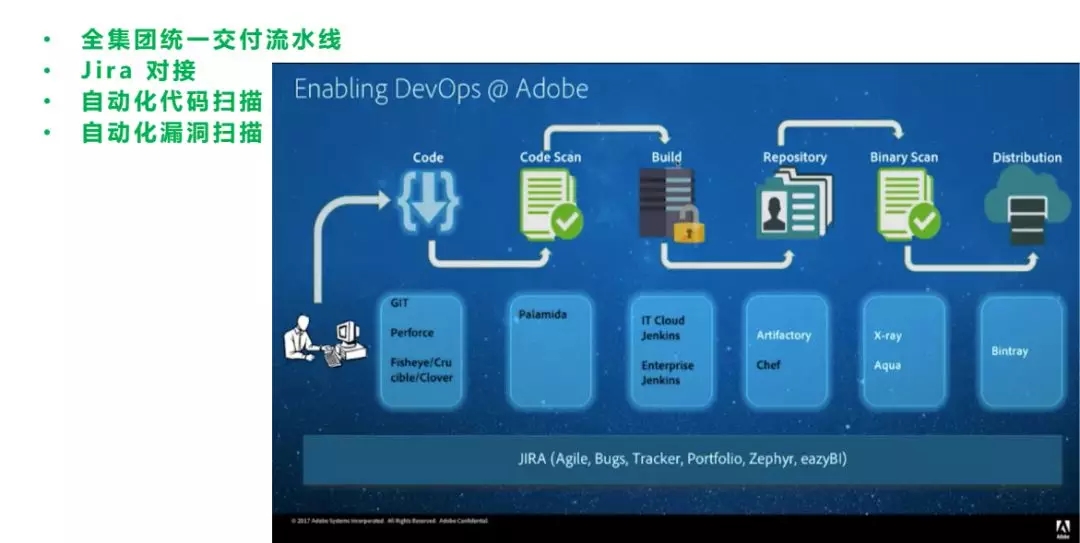
Adobe的工具链比较多,底层是他们的基础设施运维的流水线,上层是应用开发的流水线。开发人员自己会做单元测试,集成之后分库进行包管理。他们的工件有权限,例如:DEV库只有开发能访问、QA测试库只有测试团队能访问、Release发布仓库只有部署人员可以访问等等。这些都基于Artifactory可以去实现,在此基础上打通认证和权限,所以这是Adobe的架构和工具链。
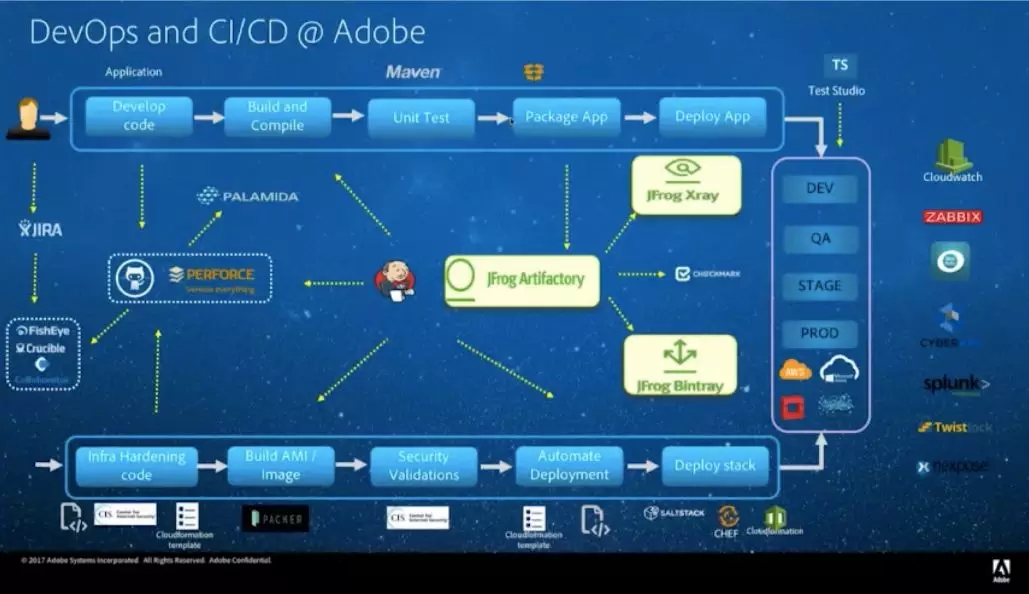
他们封装了这些工具,团队不必登录Jenkins、Artifactory就能拿到最核心的功能,然后在云平台上提供能力。
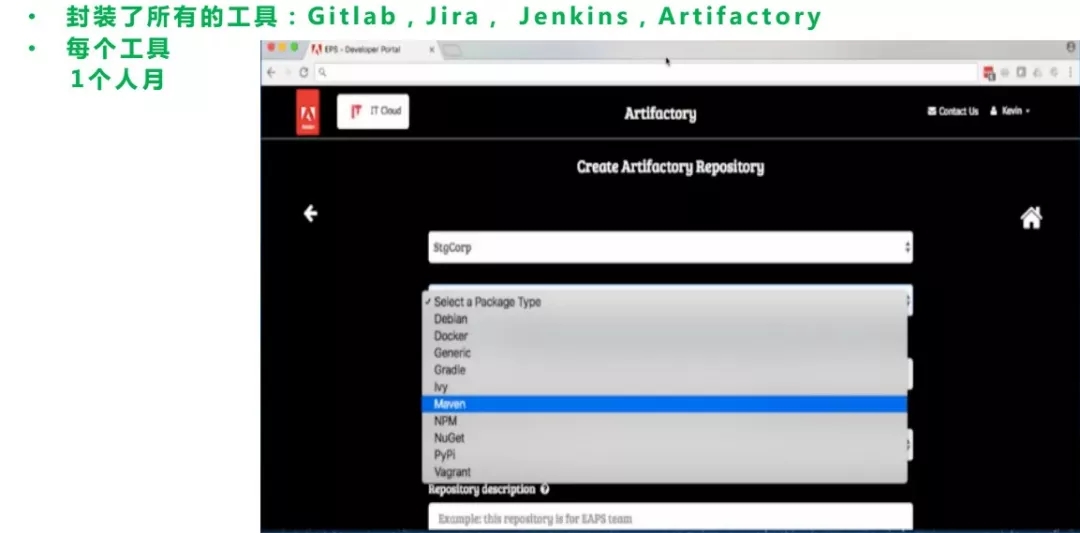
这个案例就是他们封装了Artifactory包管理功能,都是通过Artifactory去对接,而不必去管理各种语言的私服。所以这个工作量比ING要大一些。ING做法是打通权限,还需要登录各种工具,但是像Adobe封装了这些工具。
接下来的一个案例来自国内某银行,他们有一部分应用使用了容器,所有产品线都要对接到同一个平台去做上线。目前已经有两千多研发,分布在成都、上海、深圳、广州,他们的模式是领导要求产品线必须通过这个平台去上线,所以现在全公司所有的总行业务都是通过这个平台。
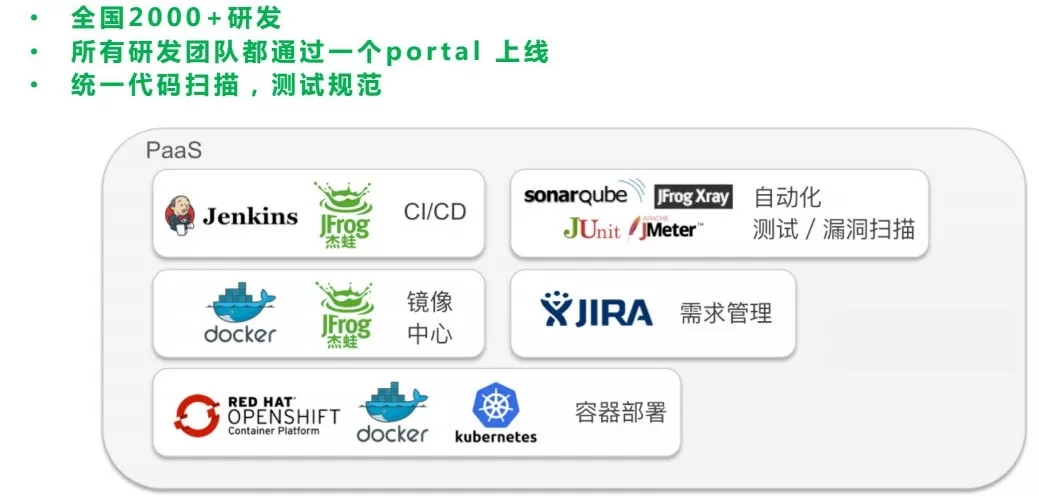
他们有60人的工具团队负责制定上线规范:比如SonarQube代码重复率阈值、Xray扫描且不能引入有高位漏洞的第三方包。他们一部分容器是用红帽的OPENSHIFT,对接容器云需要一个镜像中心,Artifactory可以无缝对接到OPENSHIFT。

这个平台要支持外包团队、内部团队,杭州、成都等多个地域的研发,所以他们用Artifatory的高可用容灾备份以及复制的能力去实现全国的协作,Artifactory要用多个节点去做流量的分流,提供高并发支持。
还有一个比较典型的案例来自于国内另一银行,典型特征是研发与生产环境隔离。
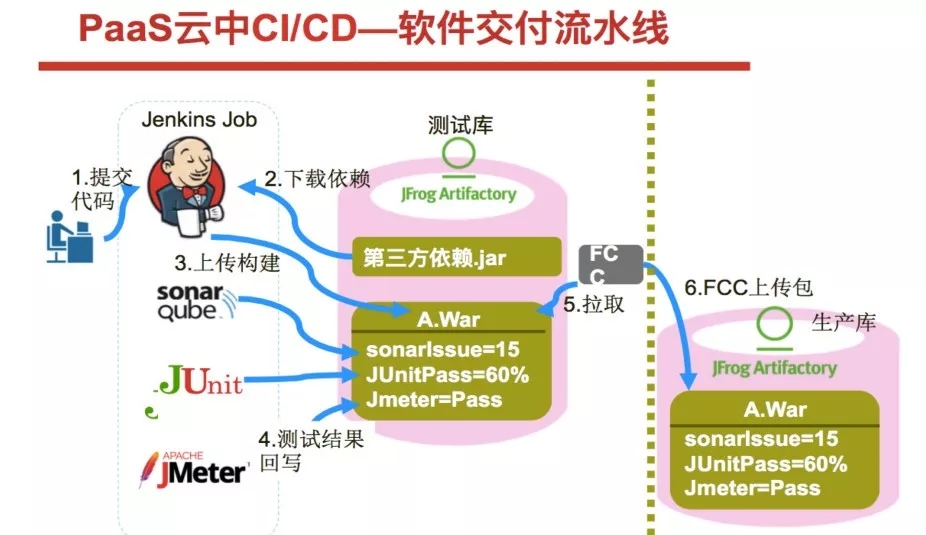
他们在隔离网络间用FCC去做加密传输复制,通过这种方式解决网络隔离问题。在研发和测试阶段,他们是用元数据和质量关卡决定是否上线。因此,他们会收集各个工具的数据,将交付物从“黑盒子”变成带有丰富元数据信息的“透明白盒子”。
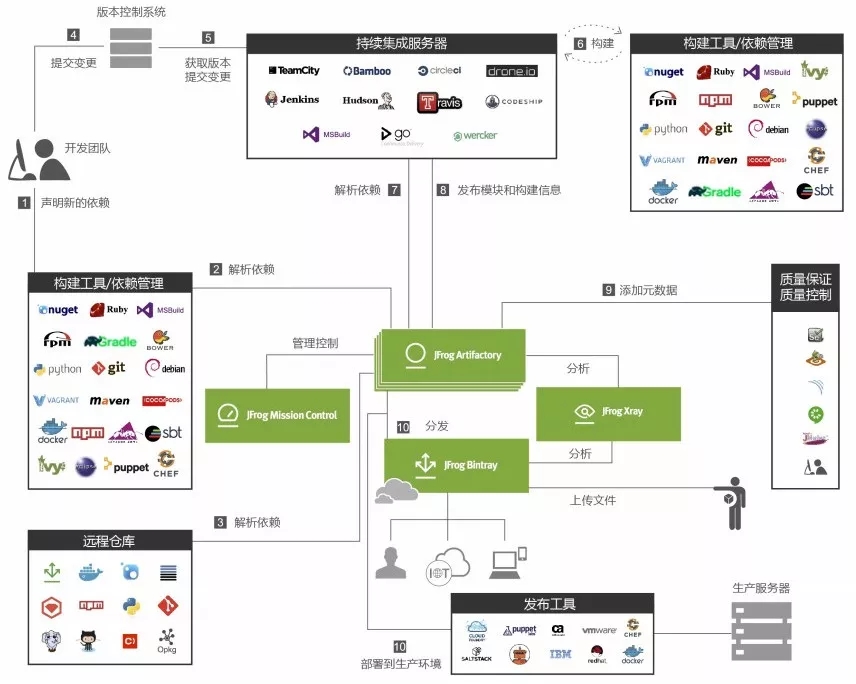
Artifactory会做全语言的包管理,同时对接各种持续交付相关的工具链,并收集工具链相关的元数据,基于这些元数据和质量规范打造持续交付流水线,同时还支持漏洞扫描和异地二进制分发,具备高可用、容灾和高并发能力。
三、如何落地DevOps
现在我就来说说落地DevOps的最佳实践。之前我们分享过的互联网公司和非互联网公司都是通过这些步骤去落地的。
第一步:全语言的统一CI&CD管理
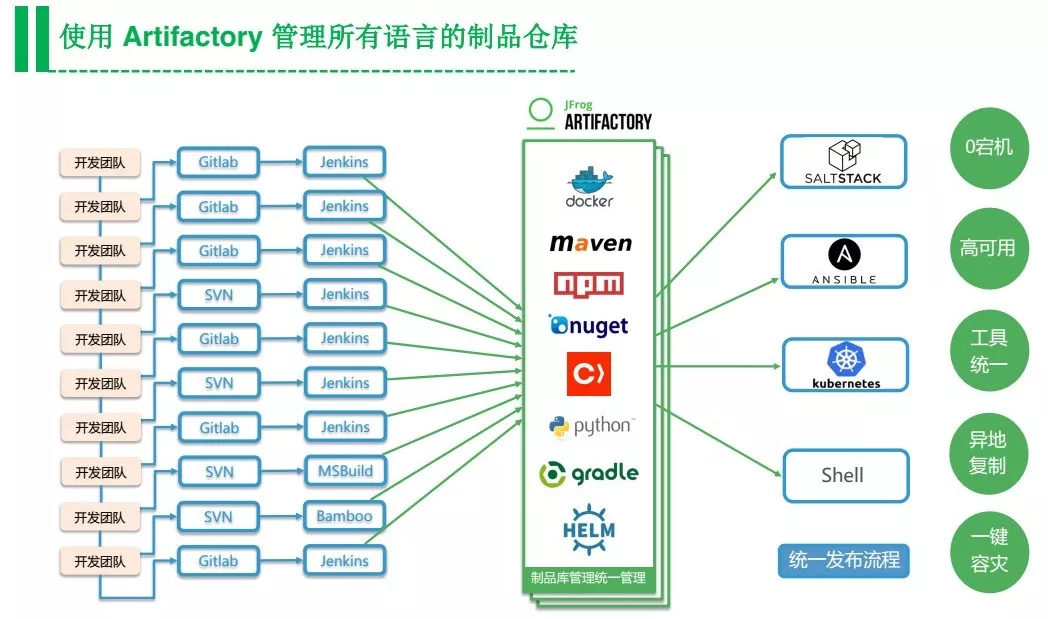
第一步是做全语言的CI&CD管理。统一管理的好处很多,最重要的是可以针对痛点规范化工具、流程和交付物。

在具体实现的时候,这三者可以统一在一个平台上来做,这就是Artifactory所做的事情,支持各种语言的集中式管控。
然后是统一管Jenkins,很多企业想设立独立团队去管理他们的Jenkins集群,通过这样的方式去做资源的分配,Jenkins能做的事情很多,比如编译、测试等等,所以管理好Jenkins很重要。
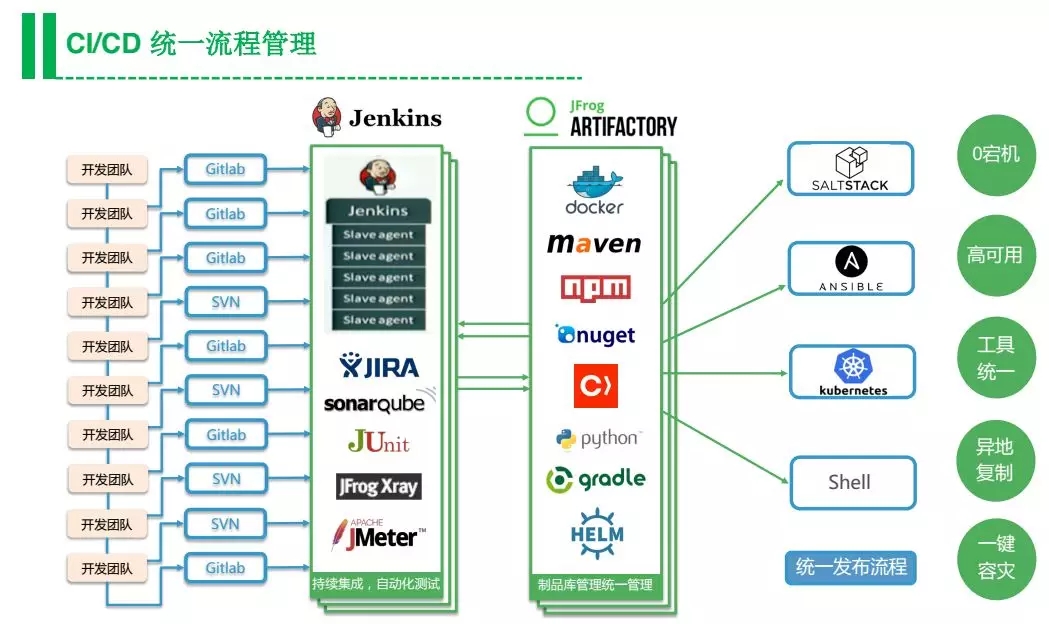
我们也有很多关于如何通过Jenkins运行测试并且收集元数据的最佳实践,后面我们可以分享。我们推荐把Jenkins跑在容器里面,上万开发规模的企业都是将Jenkins Slave跑在一个Docker容器里面,任务结束容器就会销毁,而不会长时间占用资源。
把CI/CD打通之后,第二步是开始收集数据,这些需求、开发、测试和漏洞扫描的结果都要开始收集,通过元数据去决定是否上线,当然也要结合质量关卡。不同公司会收集不同的数据,谷歌最近联合JFrog、IBM发布了一个元数据的标准。

对于不同阶段和成熟度的项目,可以适度进行取舍,但通常都会包括需求、开发、构建、测试和部署几个部分内容,更细节的内容可以进一步深入分享。

质量关卡确定了每个阶段交付物必须满足的条件,所以跟每个阶段都相关。比如测试阶段结束后,必须具有测试类型、测试平台、测试结果和QA审核等相关元数据,只有都满足相应的质量关卡——比如必须单元测试通过、必须在Win和Linux平台测试、必须覆盖率达标且必须QA负责人审核通过——满足则进入下一个阶段,否则则终止流水线。

Artifactory在这里面会提供多个仓库分别给每个团队维护自己的流水线,基于API把这些数据和二进制包关联,交付物会基于既定的一个流水线去上线。很多公司都会通过这个仓库架构去做环境的隔离,任何上线的包已经是经过了相应的测试,并且测试结果是满足上线规范的,因为我们设置了质量关卡。只有通过所有质量关卡的包才会被部署到虚拟机环境或者Kuberentes,也支持Shell脚本去做部署。
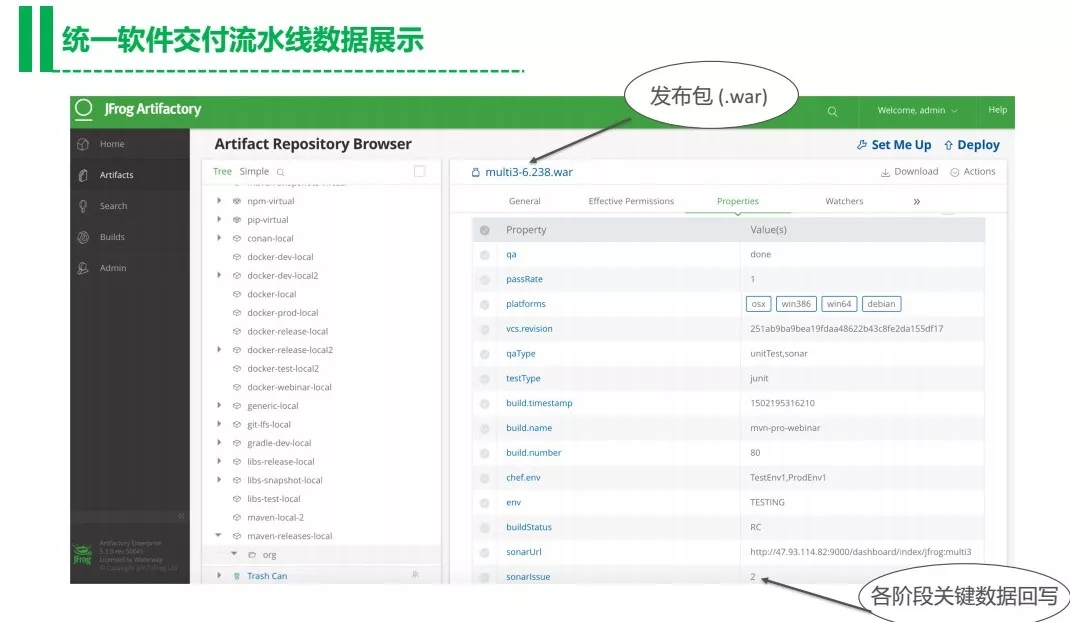
第三步是深度挖掘DevOps大数据的价值。分析瓶颈在哪里、分析有哪些改进措施和分析改进后会带来的收益等等。比如分析Jenkins每个阶段花了多长时间,然后进一步流水线通常在哪个环节失败。所以优化的第一步是定位问题,其次才是考虑如何解决。
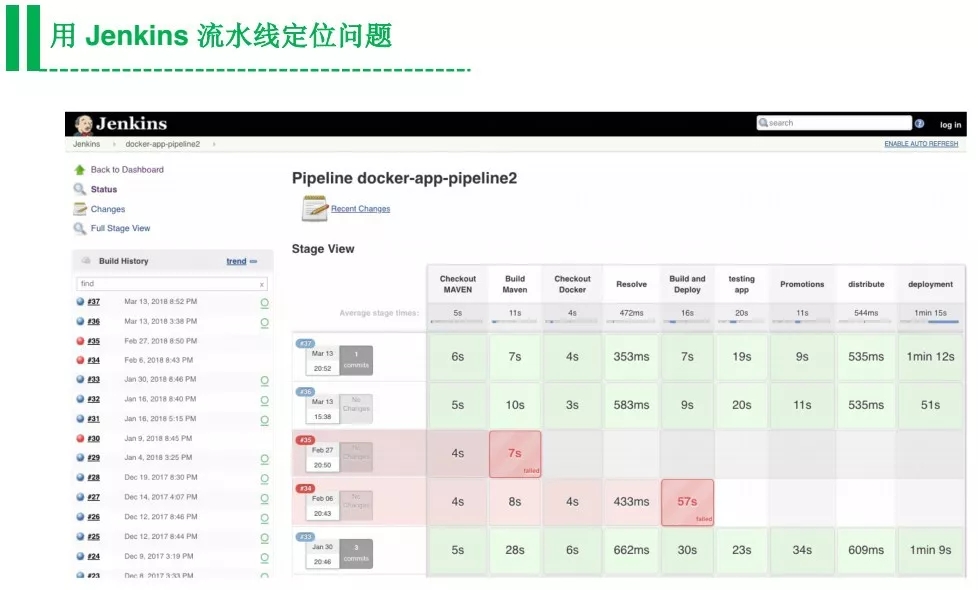
比如甲骨文,他们是通过数据去发现问题、去分析团队效率。

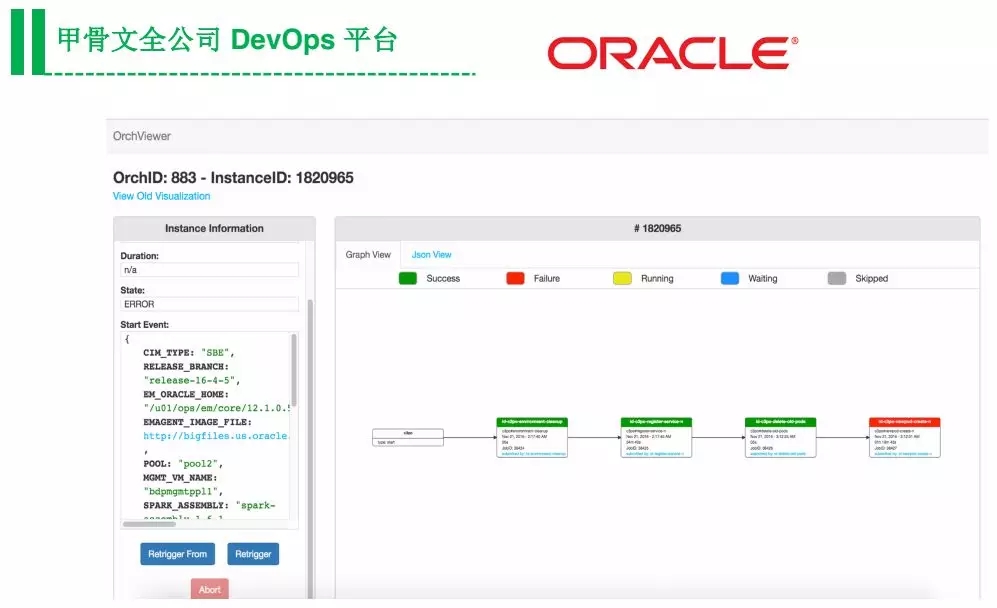
由于他们内部三万研发都是在这个平台去做上线、部署,所以它可以看到每个任务要花多长时间,对于待优化的团队,可以直接可以找这个团队,告诉他某个任务有问题需要优化。
华为内部也有类似的平台,也是基于相同的理念,通过可视化的编排,他们很方便地知道哪些任务失败且需要优化。每个团队有自己的一个Pipeline可以去看,很方便做跨团队的对比分析。
基于数据的报表平台都可以基于这些工具的API去做,这并不是一个很难的事情。提供一个统一的平台给团队是带来价值的,可视化是将价值直观化最有效的手段。
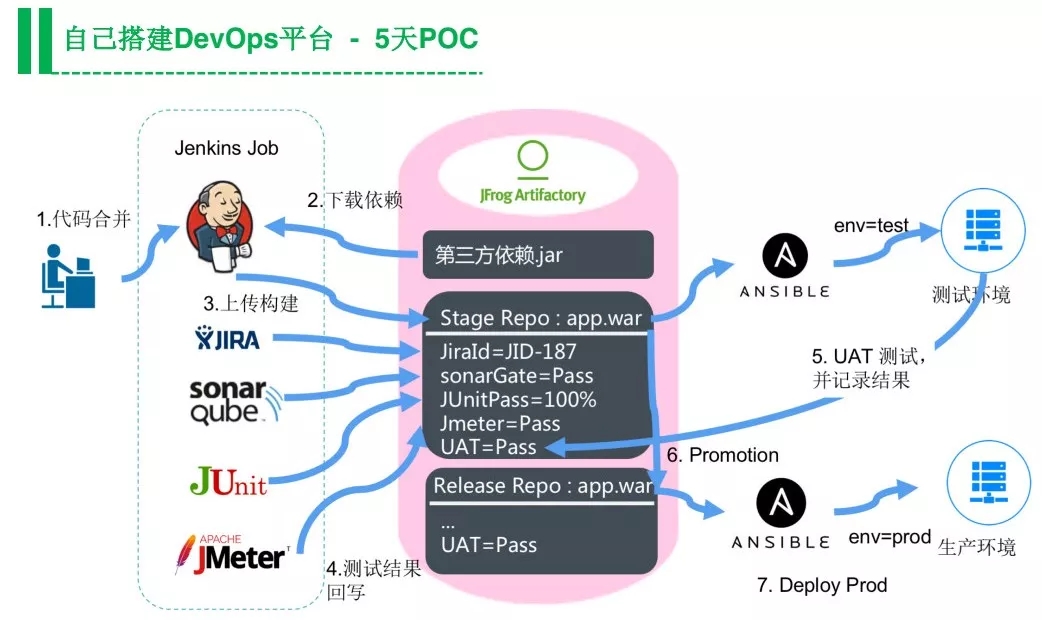
我们认为能够快速上手的落地方式是自己找这些工具,给一个团队去搭建一个流水线来做POC,5天之内可以看到这个团队上了统一的工具链之后的收益,比如现在不用邮件和电话去沟通,不用加班做部署,这些信息都会变得很透明,这是可以很快度量的一个POC,所以值得大家都来试一下。
PPT链接:https://pan.baidu.com/s/1Xi5i3FOnIMqrA8yayg4vjw








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721