
温峥峰,百田信息运维技术专家,DevOps Team Leader,超过8年互联网运维经验,曾就职于网易游戏,经受过各类海量规模互联网业务模式的历练,专注于运维自动化、DevOps实践、运维服务体系建设与SRE时代下的运维价值挖掘。
知乎专栏:https://zhuanlan.zhihu.com/hiphone-devops

「可量化」是一个严谨的技术人员需要追求的客观准则,用一个更加高级的词汇来描述是「可计价」。一切行为都是有价值的,特别是对线上环境的各种的运维操作、变更,会造成怎样的影响,我们如何判断其价值所在?
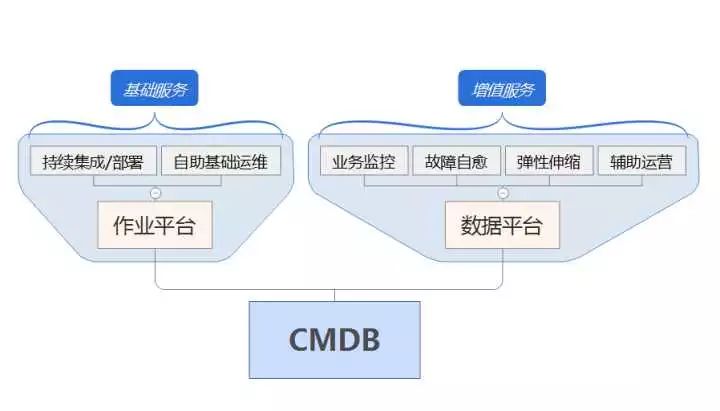
作者之前所写的《中小型运维团队如何设计运维自动化系统》主要讲述了 DevOps体系中最核心的两大模块:CMDB和作业平台。其次核心是数据平台 ,无论是监控、辅助运营、智能伸缩、故障自愈等高级功能都要依赖数据来驱动实现。
在运维自动化体系里面,数据是一个非常核心且是承上启下的重要元素,它即可以反映运维服务的效率、故障比例、可用性,也可以衡量业务运维状态的质量、稳定性、成本、速度等。
而且在前文的最后部分,就有一个利用作业平台执行数据来挖掘运维价值的例子,因为和本文主题相关,所以也推荐给读者,这两个例子分别是关于运维人力价值和故障分析价值。
除了上述两个例子以外,怎样利用数据来提供运维团队的增值服务,本文通过几个实战例子来描述说明。
技术栈的选择
关于数据收集、处理和展示,业界比较常见的技术栈主要这几类:
第一类是著名的ELK,即 Elasticsearch、Logstash、Kibana(或者EFK,F 是 Fluentd 代替 Logstash,毕竟Logstash因性能问题所以口碑不咋的);
第二类是 Flume + Kafka + Storm,Java系的技术团队会比较倾向选用这套工具集;
还有一类比较少见的是用 Scribe 作为收集工具;
以上是主流的技术选型方案,但本文的重点不是介绍各种数据分析技术的优缺点,这是属于「怎么做」。
本文的主要目的是介绍「做什么」,哪些数据值得我们分析?以及数据背后价值是什么?
通常来说,分析这类数据在技术上都不会存在多大的障碍,有各种现成的开源的技术解决方案可以供我们随意选择。但是如何挖掘自家业务该有哪些数据值得分析却没有一个统一的业界标准或者参考,更多的是需要运维工程师深入理解自家业务后,通过系统运维技术加上业务运营理解的双重纬度结合才能得出一套比较完整、立体化、精细化的分析方法。
业务的诞生过程
一个站点或者App,大致经历着这样的诞生过程:PM设计出产品原型,交给 Dev 开发实现,然后交付给 Ops 部署到线上运行,最后供用户使用。
在这几个简单步骤中却涉及了众多的人、角色、交付等对象,这是一个完整、复杂的系统工程,而任意一个环节的失误都可能影响最终呈现给用户的体验以及效果。但是我们却不可能一个个子步骤都去加监控、加数据分析,这样做是非常吃力不讨好的事情,甚至会产生很多监控冗余的情况,所以我们要做的是抓住核心指标。
什么是监控冗余
随着我们的业务发展慢慢变得庞大、复杂,其需要监控的点会变得越来越多,如果我们对每个环节、每个组件可能的异常都做对应的监控,那么一台host可能会要有数十个监控项,这是不太科学的做法。
监控的意义在于迅速发现问题,如果存在过多的冗余监控,可能会影响运维人员对于告警的敏感性。例如每天好几百条告警短信接收下来,又没有非常准确地发现真正的故障情况的话,这个告警就没有存在的意义。
因此,我们该如何监控,首先是找到核心指标。
什么是核心指标
核心指标对于不同角色会有不同的侧重点:
对于PM:PV、UV、日活、月活、ARPU等
对于Dev:Bug、TPS、QPS、JVM、消息队列等
对于Ops:服务可用性、机器负载、带宽流量等
以上都是核心指标,但是缺偏偏少关注了一个重要角色——用户。对于用户来说,他们不会关心站点的PV、日活,也不会关心TPS,更加不会关心我们线上用了多少机器多少带宽。
用户只关注我们的业务产品更否提供稳定的、快速的、高质量的服务,用通俗的语言来描述,就是我打开网站是否秒开,登录app是否秒进,购物付款是否快速完成等等。
从用户的角度分析问题,才算是真正的通过运维技术加上运营理解来保证服务的高效稳定运行,这就是所谓的技术运营需要关注的。
那么问题来了,到底什么才是用户关注的核心指标?
不同业务形态有不同的用户关注指标:
对于信息类站点(例如门户网站等):首屏时间、完整首页时间
对于电商类站点:首屏时间、登录时间、付款时间
对于页游:首屏时间、登录时间、进服时间
对于手游:启动时间、登录时间、进服时间
这需要不同业务形态的运维工程师从用户角度来分析,通过技术手段来挖掘、定位出一些核心的步骤,然后在这些核心步骤作出可监控的方法,如 URL拨测、服务端监控API、页面JS被动检测等方式。
业务监控
前面铺垫了那么多内容,目的就是要引出业务监控这个概念。
监控的作用是对业务具有全面的诊断能力,按各种层次各种维度的监控方法,建立一套立体的监控模型,对影响业务的各个核心数据指标进行采集、分析、建模、展示、处理,最终得到一套可量化可计价的业务运行状况,以确保业务正常稳定运行以及最佳的用户体验效果。
而监控的工具很多,如 Zabbix、Nagios 等,是否用这些工具就够了呢?
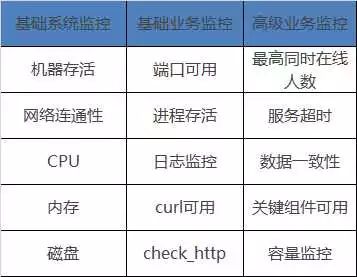
一般运维团队都可以做到基础系统和基础业务监控,然而高级业务监控才是衡量运维团队能力水平的指标。
业务监控—PCU
【最高同时在线人数】即 PCU(Peak Concurrent Users),对游戏项目来说是标配的关键业务监控项,该指标在运营角度反映了游戏业务的受欢迎程度,在系统运维的角度反映了整个线上环境的运行负载状态如服务器机器的负载情况、网络带宽使用情况、数据库的压力情况等。
一般PCU数据都可以从业务数据库或者后端API获得,然后在运维平台通过图表展示,但是这个数据只是展示出来供运维偶尔看看的话,就没发挥到它的真正作用。
历史对比
可以把 PCU 和历史对比,如上周同期、上月同期 或者 去年同期。通过对比可以根据偏差值自动判断 PCU 是否有异常,有异常则告警通知运维同事review线上环境情况。
对于偏差值的阈值设定需要比较复杂的判断,比如历史同期是公众假期或者寒暑假会使得 PCU 剧增,或者 PCU 本来偏低(如100以下)则不能按百分比来作判断条件等等。
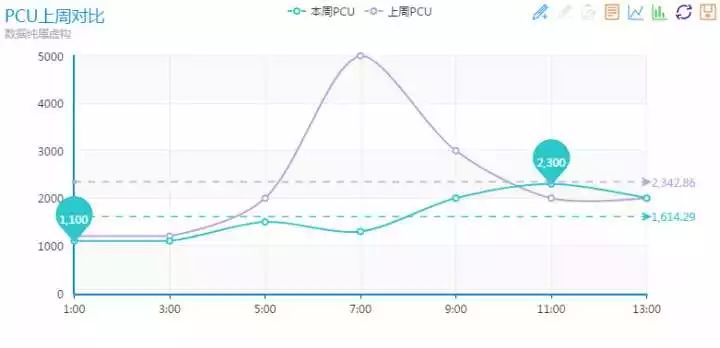
如图所示,紫色线为上周PCU,绿色线为当天PCU,可以看出在7:00有个异常的下降,通过平台自动判断并告警通知,当然实际的监控时间粒度可以设置为1分钟或者5分钟,让监控更加及时且不会太影响系统性能。
举一反三,其实不止 PCU 这个数值可以这样利用,还有其他如新增注册人数、新增登录人数等也可以用类似的方法来分析。
业务监控—模拟用户行为
一个互联网产品可以看作由一系列独立且具有特定功能的模块组合而成,这些模块间的相互作用构成了整个产品的所有功能。而任意模块的故障都会影响整个业务的正常运行,所以我们都会对产品的关键模块会重点关注。
对于关键模块,我们可以要求 Dev 提供监控接口,通过 curl 或者 API 的形式,定期获取响应码以及响应时间,保存历史数据并制作图表。
监控接口应该是完整的,可以模仿用户行为的,比如一个电商站点,一个用户必然会做这些操作:
注册
登录
添加购物车
生成订单
付款
这些步骤都属于用户级别的核心体验指标,必须提供相应的监控接口供运维长期监控其正常运行,监控数据也需要可视化处理,任何异常都能直接通过图表反映出来,后期也根据实际情况建立相应指标的告警模型和容量管理模型。
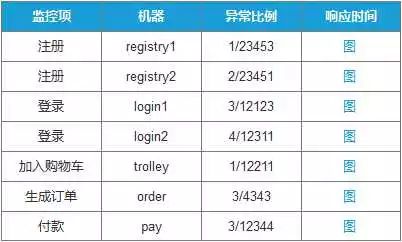
例如,点击某个监控项的图,可以看到具体的响应时间监控曲线。
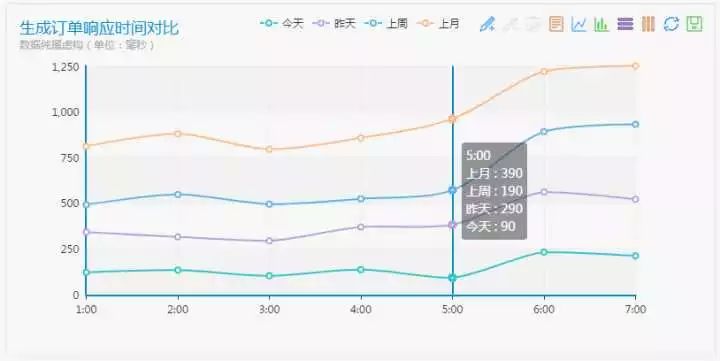
业务监控-用户来源分析
用户来源分析也是一个非常实用的业务级监控,通过各种客户端技术获取用户真实IP,如果是通过HTTP协议则需要 x-forwarded-for 来跟踪用户的真实IP,收集好IP信息和用户对应关系后,通过数据分析IP库得出用户所在地区、ISP等信息,然后就可以得出我们实际业务的当前用户地区、ISP分布图,然后结合中国地图前端控件制造图表。
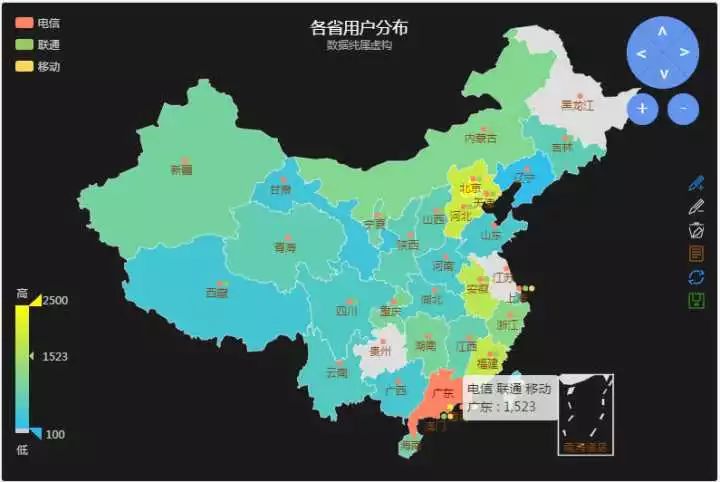
只是展示还是不够的,还要结合类似前面例子的历史对比方法,如果发现某省份或者某ISP的用户比上个对比周期剧减了,那就反映了当地骨干网、DNS或者CDN等发生故障,让运维工程师可以迅速定位故障源头。
智能伸缩与辅助运营
辅助运营的说法是运维业界近几年才提出来的,以往的辅助运营的工作一般是交给BI数据团队负责,他们把线上数据收集分析并出报表,得到 日活、月活、各种留存率、ARPU等业务数据供 PM 或者运营同事分析并做业务决策。其实运维部门也可以用技术方法辅助运营,下面就用游戏项目的开服合服作为实践例子。
游戏行业经常有开服、合服的操作,用通用的说法就是扩容和缩容,因为一个游戏的生存周期很短,从内测、公测、引入期、成长期、成熟期到衰退期说不定总共就一两年的时间,扩容和缩容操作的高效、快速反映了运维团队的服务能力,也对公司的运营成本节约有着重大的意义。
开服,即扩容的操作一般经常发生在引入期和成长期;合服,一般是在成熟期和衰退期。
开新服是游戏运营中的一种刺激玩家人数增长的良好手段,因为在老服中排名相对一般的玩家,去新服往往可以获得更多的进步空间和利益,刺激用户消费来换取用户成就感。
而合并老服务器,可以把N个活跃人数较低的鬼服组合在一起重新焕发生命力,游戏必须基于一定的人数才能完全体现游戏价值,这样用户才有继续升级的欲望。
开服策略
那么怎样选择最佳的开服时间,运维部门怎样利用技术手段协助判断?
根据运营策略,开服的最佳时间是用户登录数最高的时间段,因为这样用户才更高的概率发现有新服开了并进入新服。
在前面的业务监控部分,我们已经掌握了各种业务指标数据,当然必须包含用户登陆数这个重要数据。
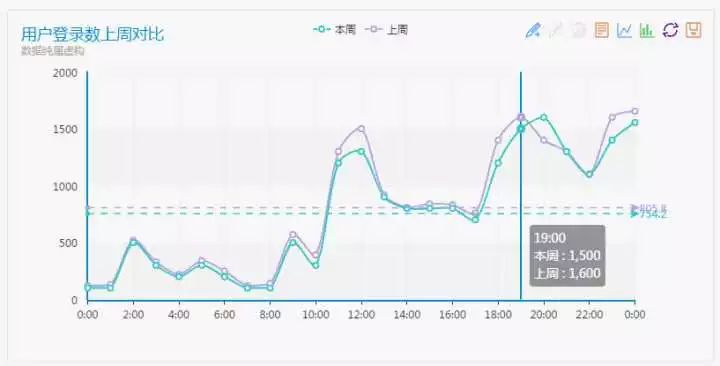
可以看出,对于手游来说用户登录数在12点、19点以及23点左右都有一个峰值出现,分别对应午休、下班和临睡觉的三个时刻,我们该如何选择呢?
一般在开服前,运维工程师已经对机器初始化完毕,并部署好业务代码,联调各种辅助系统并交给QA测试。测试完毕后会经过清档、业务活动配置、再次测试等流程。这些环节都需要技术同事和运营同事共同参以确保整个流程正确无误,所以开服时间理论上放在工作时间会比较好,因为这个时间大家都在公司可以更好地沟通交流。
如果游戏是联运项目还需要和第三方供应商联调,就更加需要在双方都在线的时间比较好,否则一旦出现异常情况就会影响处理的响应时间。
综上,开新服时间定在12点或是19点比较合适,至于具体的精确时间,可以根据历史峰值所在的时刻自动触发即可,这在技术层面很容易实现。
合服策略
对比开服,合服是一个更加复杂的业务操作,能否正确选择哪些服该合并既反映了运营人员的业务水平的高低,也对公司的业务运营情况有正面促进的作用。我们也可以通过系统运维的角度来协助分析,利用数据指标来给他们提供更优的选择。
合服需要考虑的指标大概有以下两大类:业务指标和系统指标。
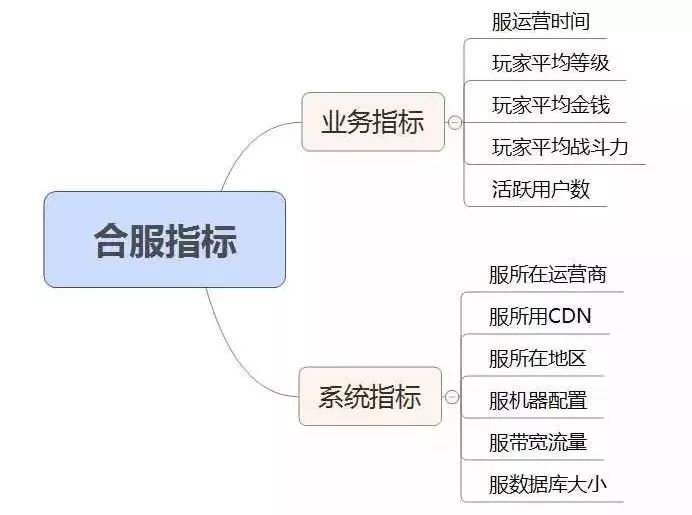
其中业务指标大多数需要通过业务数据库统计获得,而系统指标需要根据 CMDB 的各种信息统计,最终可以匹配出一系列适合合服的服列表信息。
至于具体的判断算法和评判标准,需要和 运营、开发 等业务部门同事反复讨论确定,因为各家业务情况不同,这里不多作展开。
总结
我们可以看出,上面例子在实践中并没有很高的技术门槛,只是需要我们稍微具备一些业务方面的产品优化或者运营策略知识即可,只要运维部门走出一小步,就可以为整个业务团队作出非常大的贡献。

另外,在现在云计算技术的普及,让大多数中小型企业瞬间具备了弹性计算的能力,让运营成本利用率最大化和用户体验价值最优化都有了可落地的技术基础。
紧接下来我们继续思考以下内容:
线上服务器以及带宽等硬件资源是否已经达到最优利用率?我们有没有可量化的分析方法并持续优化?
业务是否有不科学的功能点在极度浪费线上硬件成本资源或者对用户体验不佳,运维部门如何量化并反馈业务部门整改?
如果运维团队能做到以上内容,我们的定位就不再是一个支撑后勤岗位,不再是成本中心,而是作为一个可以理解运营策略且可以为业务部门作出价值贡献的核心环节。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721