
作者介绍
轻维软件:敏捷运维找轻维!轻维软件致力于以先进的互联网技术,为传统企业打造敏捷运维体系。立足于企业实际应用场景,团队规模200+,拥有丰富的大规模集群设备运维经验。主要技术方向包括自动化运维平台(智能监控、自动化运维、CMDB)、运维工具(数据库运维管理、SQL审核、应用性能管理)、DCOS及DevOps。
据国家信息安全漏洞共享平台(CNVD)报道,英特尔X86处理器在底层设计方面存在“崩溃”(Meltdown)和“幽灵”(Spectre)两个高危漏洞。1995年后生产的所有英特尔处理器,以及使用这些处理器的Windows、Linux和MacOS等操作系统都可能受到影响。
此外,ARM、AMD两种处理器也受到影响。利用该漏洞的攻击者可以在其登陆的设备上越权窃取数据,还可以突破云平台的虚拟化隔离,跨账户窃取其他虚拟用户的数据。目前,此漏洞的攻击利用工具已经在互联网上传播,危害较高。
现在,操作系统厂商通过在其产品内核引入内核页面隔离(KPTI)技术来修复Meltdown和Spectre漏洞。CNVD建议用户密切关注操作系统、虚拟机、浏览器等产品官方网站发布的安全公告,并及时下载补丁进行更新。各厂商的修复情况和参考链接如下:
微软:已为windows 10已供修复包,并对windows 7和windows 8进行在线更新
https://support.microsoft.com/en-us/help/4073235/cloud-protections-speculative-execution-side-channel-vulnerabilities。
浏览器安全补丁已发布
https://portal.msrc.microsoft.com/en-US/security-guidance/advisory/ADV180002
RedHat:已发布补丁
https://access.redhat.com/security/vulnerabilities/speculativeexecution?sc_cid=701f2000000tsLNAAY
Ubuntu:已提供修复补丁(https://insights.ubuntu.com/2018/01/04/ubuntu-updates-for-the-meltdown-spectre-vulnerabilities/);
SUSE:已陆续发布补丁
https://www.suse.com/support/kb/doc/?id=7022512
Vmware:发布安全公告及补丁
https://www.vmware.com/us/security/advisories/VMSA-2018-0002.html
Citrix XenServer:发布安全补丁
https://support.citrix.com/article/CTX231390
什么是 Meltdown 和 Spectre?
传送门:https://www.redhat.com/en/blog/what-are-meltdown-and-spectre-here%E2%80%99s-what-you-need-know
预测执行漏洞对性能的影响 - 针对 CVE-2017-5754、CVE-2017-5753 和 CVE-2017-5715D 的安全补丁对性能的影响。
传送门:
https://access.redhat.com/articles/3307751
http://tech.163.com/18/0110/15/D7Q3KMBM00097U7T.html
受影响的产品更新及注意事项
传送门:
https://access.redhat.com/zh_CN/security/vulnerabilities/3314391
最新消息,英特尔官方表示漏洞将会使服务器变慢2%-14%,但安全显然也同样重要!
纠结归纠结,最后大家估计还是得要打,安全是要命的事,服务器变慢的问题留给英特尔及各操作系统厂商去考虑。但这么大量的服务器,这要命的补丁打起来也很要命。
补丁君曾在许多大型企业服务过,每年的安全加固、安全整改都是要运维脱几层皮的事,还好咱人多,不行人肉。但这次,不管什么机型、版本几乎全受影响,而且是内核级的补丁,全要重启,真的要命啊。估计得到这个消息后,所有运维都要哭晕在厕所了。
补丁君此前也深受这种重复劳动的折磨,于是在此前就积极投身到公司自动化运维平台的建设当中来了,希望能把运维从传统的体力劳动中解脱出来,这次在以身试范,看如果用上自动化工具,看如何解救大家于水火之中。
补丁君公司的内部研发环境,有300多个LINUX 虚拟机,当然老板没发话,也不敢全部就打了,咱们也担心性能问题。那就先搞些边缘环境测试一下,找了30多个不太重要的环境来完成本次的测试。
因为涉及重启操作,在各企业相信重启服务器都是件很大的事,重启前肯定要进行相关的服务检查、请求隔离等操作,重启的过程也需要根据应用的集群情况,进行灰度补丁更新(咱们编排流程是支持嵌套编排的,嵌套编排一下就能达到灰度发布的效果啦=。=),最小化对业务的影响。但本次是个测试,最重要是抛砖引玉,就没有做集群的灰度更新模拟。
本次测试的逻辑过程如下:

内核升级脚本通过server下发对应补丁文件到各主机,各agent 执行脚本进行批量内核升级操作,同时返回是否完成该操作的返回码;
收到操作成功的返回码后,需要人工确认才会继续执行批量重启操作;
批量重启后,检查升级情况脚本会从server端执行一个判断agent是否在线的操作(在设置编排流程的时候设置好该步骤的超时时间,大于超时时间则返回操作失败),只有正常在线的agent才会执行检查升级操作。
查看流程执行日志,检查执行情况。
下面我们来看看通过自动化运维平台,如何来完成该项工作:
1、新建脚本
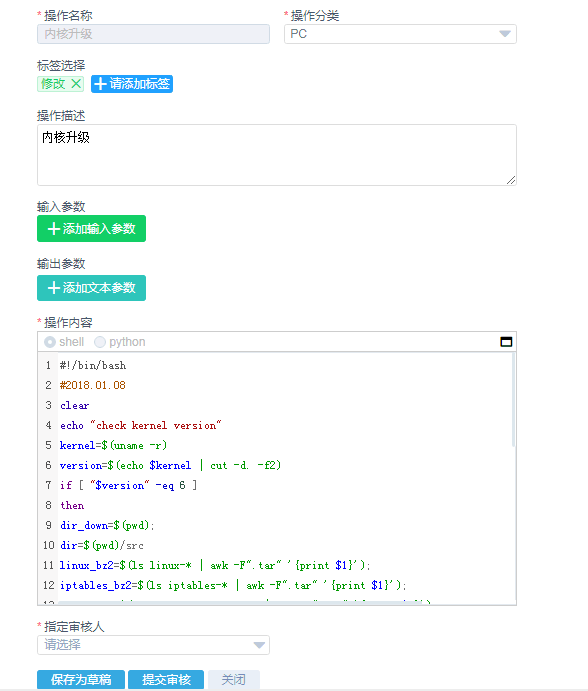
2、提交审核
危险命令可以高亮显示并自动划分为危险级别,针对不同用户组进行授权操作(审核-分级-授权)。此处跟Ansible和SaltStack等开源工具不一样,工具加入了对所有脚本的审批流程,所有批量执行的脚本应该是经过审核的安全的脚本。否则一个危险操作批量下去,就出大事了。
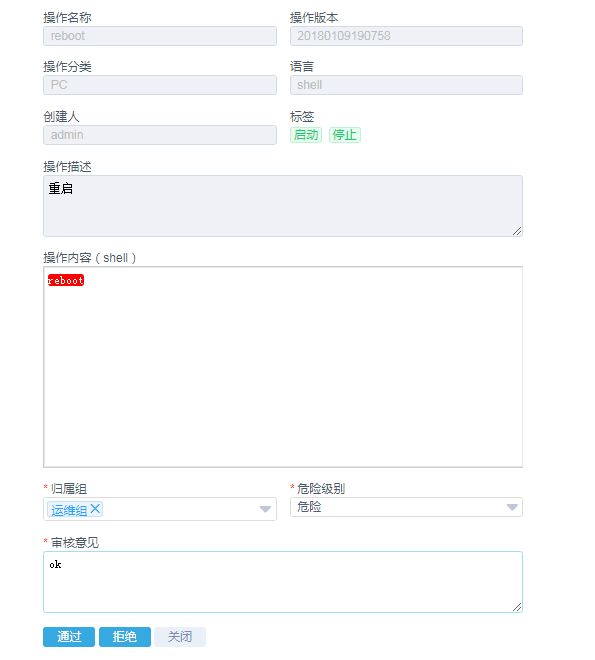
(工具会将reboot自动识别为危险操作,并作标识)
在对应的脚本里选择需要执行的实例
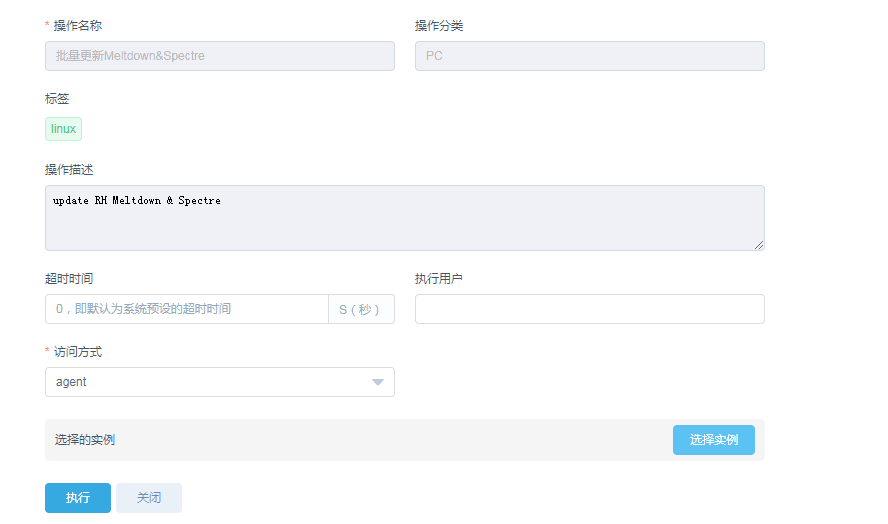

3、通过编排功能将已经审核好的升级脚本组合在一起。
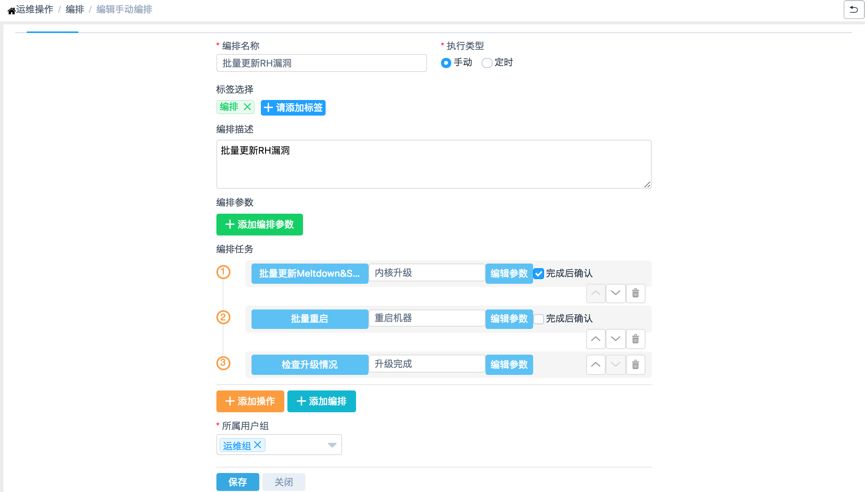
平台支持将各种操作按一定的顺序组合成一个大的操作流程,支持各种复杂的操作调度。平台内置的流程里还可以设置在执行完步骤1后需要确认再执行步骤2,在重启前进行确认。这里也是跟相关开源工具不一样的地方,平台会对各个步骤进行二次管控,包括再确认,再审核,执行步骤完成之后进行短信通知、二次确认等,确保整个流程执行过程的安全可控。
4、执行批量更新场景



执行完步骤2(重启)后,步骤3的脚本会检测资源是否上线,并检查当前内核版本以及升级动作是否已经完成。
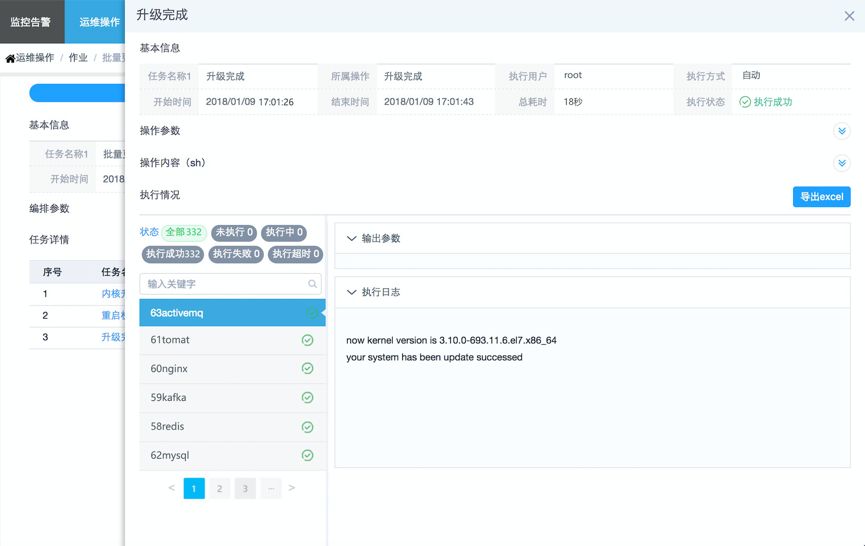
整个过程就这么简单,30台机器不到20分钟就轻松完成,当然因为是批量操作,就算300台或更多,估计也就20-30分钟搞完了。后面还可以加入业务验证步骤,及更新升级失败的回退子编排流程等,大家可以发挥自已的小宇宙,通过丰富的原子脚本快速组合成各种流程,完成相关任务。
通过自动化的工具平台,能帮各位运维的同学,快速搞定各种批量、重复的体力劳动。同时在企业级环境中,对安全的考虑至关重要,通过灵活的权限控制,也可以实现对批量操作的二次管控。效率与安全兼得!
这几年从人工到纯脚本再到自动化的运维,补丁君切身体会到,通过使用自动化运维平台带来的好处,包括人力的解放、运维效率提升、运维质量的提升等。目前补丁君也在投身公司自动化运维平台建设,包括智能监控告警、自动化运维、统一资源管理、大数据日志分析等能力,欢迎大家一起探讨。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721