
本文由王雪燕根据京东资深架构师沈建林在51CTO第14期“Tech Neo”活动分享整理而成
人肉阶段的运维,理想与现实有天壤之别,同时还有背不完的锅,填不完的坑。人工、自动、智能运维相互交叠是当前运维领域的现状,智能运维是大势所趋,但真正的落地实践并不多。
为什么要做服务监控?
业务规模不断扩大、微服务化、频繁变更这三方面现实需求,是做服务治理和监控的重要原因。
为保证这三方面的正常进行,需要做很多事,重点包括如下几点:
如何快速发现问题?采用哪些技术?
如何梳理服务依赖?面对京东过万的服务,如何进行梳理,具体实现过程是怎么样的?
如何判断依赖合理性?微服务之间相互依赖,采用什么样方式判断依赖是否合理?
如何实现实时容量规划?传统的方式是在 618 前两月进行封网,不允许上线,利用这段时间进行线上压测,得到应用的容量,随后根据现实情况进行扩容。
这样的方式耗时耗力,所有研发不让上线,成本很难评估。现在的做法是基于历史数据,机器学习,自动运算,那具体是如何实现的?
如何判断故障影响范围?也就是故障定位问题,如何能知道哪个节点发生故障,响应了哪些业务?
如何实现业务级监控?京东金融会和很多第三方支付机构打交道,如何去监控和合作伙伴之间交易的服务质量?
综上都是服务监控要完成的使命,下面我们先从服务监控设计原则、自主监控的基本要素、服务依赖关系梳理、调用链分析、容量规划、根源分析等方面来看看服务监控的应用。
服务监控的应用实践
1、服务监控设计原则
服务监控与治理软件的设计原则主要有以下五个方面:
微内核。设计产品时把内核设计的非常小,称之为微内核。采用 Plugin 模式,所有功能采用微内核方式,把自己也当做第三方去扩展,这样的产品,不管是开源或商用,别人扩展时也会更加便捷。
乐观策略。不能因为监控影响业务,一旦影响业务采用抛弃策略,监控项要全部异步处理。通过 SoftReference(软引用)的方式,在内存吃紧的时候优先释放掉监控本身所占用的内存。
零侵入。简化研发使用,实现业务、中间件、监控完全独立。
约定大于配置。自动发现:部署规范,配置规范默认返回码、描述。
动态路由。日志传输节点远程控制,无限扩容。
2、自主监控三剑客
做自主监控有三个最基本要素,分别是调用量、性能、成功率。后期的一些监控扩展,都是基于这三个指标。
如下图,是监控的细节:
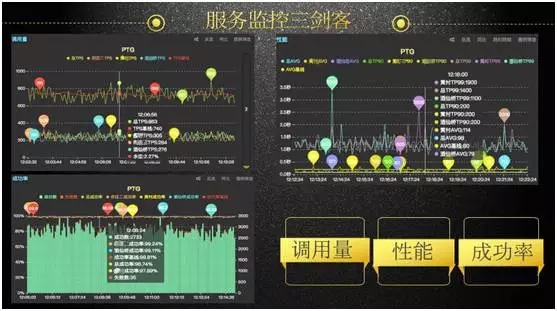
如图中所示,红颜色的线条被称之基线,通过波动可知当前这个服务的响应时间、调用量、成功率等情况。基线计算很复杂,基于以前历史数据,利用异常检测算法,推算当前的量应该是多少。
如下图,是监控分层的细节展示:
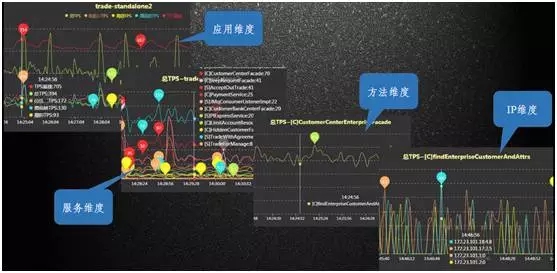
如图中所示,每一条线都可以下钻,钻进去就可看到某个应用里有哪些类正在被监控,进一步下钻可以看到方法、IP 级别。
当出现某一台服务器故障,影响整个响应时间时,从 IP 级别的图中就可以快速定位,看到是哪个 IP 出现了问题。
3、服务依赖关系梳理
分享服务梳理方法之前,先来了解如下两个概念:
依赖强度。指服务之间的依赖关系强弱。比如购物必须要交易,交易必须经过支付后才发货,交易对支付就是强依赖,支付系统出故障,交易也不能幸免。
依赖频度。指对某一个服务的调用次数,调用频繁,就是高频依赖。
基于这两个概念,可以进一步对方法、应用和业务线之间的依赖关系进行分析,如下是某场景依赖关系的全拓扑图:
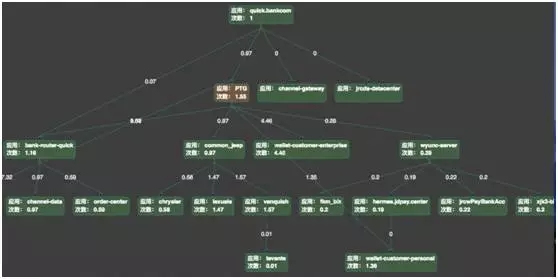
从图中,可以很清晰地看到整个调用的拓扑,所有应用相互之间的依赖强度,通过连线之间的数字来描述应用之间的依赖频度。
如下,是依赖关系的主流程图:
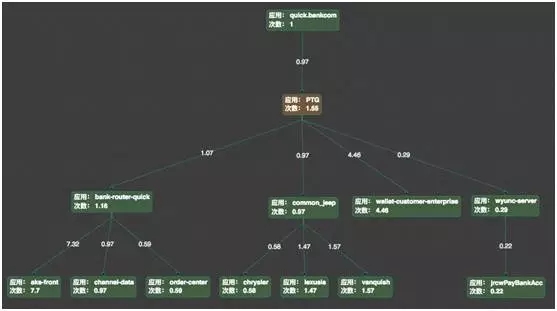
把弱依赖及依赖频度较小的应用去掉以后,可以看到主流程,主流就是核心系统,如果出现故障,影响会非常大。
4、调用链分析
如下图,是调用链分析:
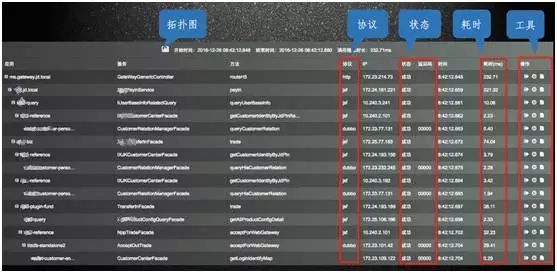
这是整个服务监控中相对重要的环节,当触发一次请求,如用户在京东购物,用户付款这个动作要经过哪些 IP 来处理,IP 上有哪些方法进行处理,通过哪些协议去调用,耗时是多少,每一次调用都要跟踪,每天有千亿以上类似的调用。
整个调用链都处于监控中,如出现故障,告警就会通过短信、邮件的方式把链接推送给运维人员。运维人员点开链接就可知晓故障位置,同时还有一些工具辅助处理问题。
5、容量规划
容量规划方面,传统的方式是应用上线之前做压测,但很多时候一上线容量就变了,导致之前设置的数据都是没有意义了。
如下图,是现在的实时容量规划方式:

如上图左侧所示,在 618,双 11 等大促时,把这些拓扑图实时数据和性能指标都摆放在大屏上,当水位、响应时间等任何一个指标出现异常,运维人员就会及时发现问题,并快速进行问题解决。
如下图,是服务访问慢,出现异常的快速定位案例:

当服务访问慢时,系统会计算到 IP 上的指标,很多时候是一两台服务器过慢,可通过邮件看到是哪个服务器出问题。
点开邮件链接,就可以看到从什么时间开始慢,什么时间结束,平均的响应时间是否偏高。进一步下钻,可看到什么样的问题导致响应时间偏高,这里会引用一些智能故障分析工具。
6、根源分析
根源分析可基于自动学习的拓扑关系、数据库与应用的关系、应用与 IP 的关系等确定性因素来做,如下图,是一个非常典型的磁盘 IO 导致日志打印慢的问题。

这样因一台机器由于打印日志排队造成堵塞,导致后面好多应用出现调用性能下降的简单问题。如果没有根源分析,要靠人为分析去定位根本原因还是非常困难的。
综上所述是服务监控的应用,下面我们从日志采集方案对比、分布式服务跟踪的挑战、整体技术架构等方面来看看技术实现。
服务监控的技术实现
1、日志采集方案对比
所有的服务监控是基于一条日志,日志采集方案有很多。如下图所示,分为四个阶段:
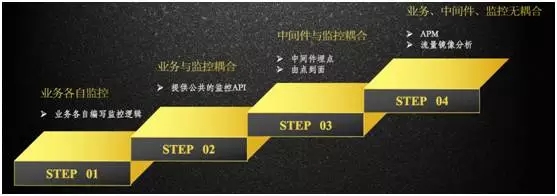
最原始的阶段,是业务各自监控,自己编写监控逻辑,业务上埋点,输出自己的监控日志。
第二阶段,是业务与监控耦合,提供公共的监控 API,通过 API 的方式自动产生这条日志。
第三阶段,是中间件与监控的耦合,通过中间件埋点方式来产生这条日志。
第四阶段,是业务、中间件、监控无耦合,采用 APM 或流量镜像分析的方式。
流量镜像分析,是从设备上把流量镜像下来,分析服务之间的关系,但存在的问题是,流量分析出来的是一个结果,当应用调整或服务依赖发生变化,结果会受到很大影响。APM 是目前主流的方式。
2、分布式服务跟踪的挑战
在分布式追踪上,我们碰到了一些问题,这里主要分享如下三方面:
跨线程。在设计过程中,服务被访问时,可能会启动新线程去处理,跨线程去追踪会有些难度。
以 Java 语言举例来说,同线程之内,可借助现有 ThreadLocal 非常方便的去追踪。如某个服务有一部分代码逻辑是放在另一个线程上执行的,就要去修改 JDK 对线程的一些实现逻辑。
跨协议。通常情况下,追踪链都很长,一个正常的交易要由很多应用串起来,提供服务。这时就要跨很多协议如 RPC、HTTP、JMS、AMQP 等去追踪。
扩展性。当新增协议、与其他企业框架不同怎么办?这需要自定义的扩展性描述语言来解决。
3、服务监控平台的整体技术架构
如下图,是服务监控平台的整体技术架构:

服务监控平台的核心是产生日志的 Agent,采用 Java Bytecode 的方式进行自动增强。由统一的 Config Server 下发监控指令,Agent 在应用启动时或者运行时动态增强需要监控的方法。
日志产生后由路和模块决定发送到哪里,可以是本地磁盘、消息队列、Collector 等。随后进行流水计算,实时汇聚结果,存入 NoSQL,然后由页面进行展示。
文章来源:51CTO技术栈订阅号
讲师介绍 沈建林
京东金融集团资深架构师。现任京东金融集团资深架构师,负责基础开发部基础中间件的设计和研发工作。擅长基础中间件设计与开发,关注大型分布式系统、JVM 原理及调优、服务治理与监控等领域。
曾在多家知名第三方支付公司任职系统架构师。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721