
本文根据DBAplus社群第121期线上分享整理而成。
主题简介:
浅析ITOA运维体系和大数据分析体系建设步骤
正确姿势搭建大数据日志分析平台
今天分享的主题是《构建智能化的大数据日志分析平台》,首先我们来聊聊运维体系和大数据分析体系建设思路,大家也可以看看自己所在企业大概处于哪个位置,然后我会和大家分享下如何去正确搭建大数据分析平台,今天我们会稍微侧重于日志分析这个领域。
一、企业IT的发展趋势
企业IT的发展趋势,目前来看存在如下3点比较明显的新模式:
1、为了解决研发和运维之间的壁垒,引入了DevOps,开发者和运维人员在实现各自目标的前提下,需要为业务交付提供最大化价值及最高质量成果,完善软件变更在构建、验证、部署、交付等阶段中的活动,同时通过软件开发者和系统运维人员之间所进行的沟通、协作完成持续集成和自动化。
2、传统的运维人员正在探索容器化、自动化、云计算、开源架构等转型之路,进入“互联网+”的时代;传统运维向互联网运维转变的同时在也在借鉴许多比较成熟的商业产品设计思维、平台架构和先进的技术手段。
3、大量原来采用商业软件的企业,在软件定制化和商业开发人工成本不断增加的大趋势下,也在思考向开源社区需求帮助,甚至有些企业和单位的信息技术部门还把开源研究作为信息化建设的任务或考核指标。
下面我们来简单探讨下传统企业和互联网企业IT运维的共同点和区别。首先,传统运维和互联网运维并非对立,两种运维表面上差异很大,但本质是一样的,总是需要无穷无尽的加班熬夜,随时准备充当救火队员,而压力山大的同时经常性背下黑锅又是在所难免,总之比较苦逼。
两者各自的特点:

在相关业务的核心应用环节使用IOE硬件;
业务需求非常明确,用户数量固定。具有明显的行业应用特点,与业务的结合很深,要求供应商既要懂得技术又要懂得业务,软件解决方案偏向成熟的商业产品并长期使用;
运维人员单一领域素质较高,培训体系完善,职责稳定、技术压力小,薪酬不高但是稳定且福利好。

硬件选型偏向X86服务器为主,以通用的产品为体系,以开源可控的产品和技术为核心,在高可用、自动化、大数据等领域大量使用开源软件为主要的解决方案;
采用通用的技术,面向广大的互联网用户,业务使用对象复杂,需求繁复,对象数量庞杂,对自动化运维、资源弹性扩缩的要求较高。
人员的技术水平良莠不齐、薪酬浮动空间较大、运维人员知识的学习多数借助互联网自学,并且对应职责领域较广。
二、运维体系建设步骤
经过我们十余年对企业运维体系的建设步骤的理解, 从企业运维的最佳实践上来看,通常分为以下四个阶段:
第一阶段,搭建基础架构的监控,形成相关监控告警,以ITIL流程驱动和相关运维管理实现最基础的IT管理工具,这是现在大部分企业已经建设或者正在不断完善的;
第二阶段,解决方案与工具阶段,通过这个阶段用户可以建立起如企业资产配置与管理CMDB、性能管理、容量管理、故障管理,以及自动化运维、日志分析等从而提高IT管理分析能力;
第三阶段,则是将各个独立的方案和工具进行整合,为分散的系统建立标准的,统一的的规范,根据相关规范接入到整合的系统中,从而形成整体平台的运维能力,例如综合网管、PaaS云平台、综合大数据分析平台。
最后,在这个大平台的基础上,我们可以对各种相关的基础数据以业务维度提升价值为核心,形成跨平台的融合IT管理能力,为用户带来如业务感知、关联分析、闭环管理、人工智能等各种应用场景。
依据我们多年的大型企业维护经验来看,企业的运维体系建设必然经历这4个阶段。
首先,终极目标是明确的,IT运维是以业务维度为核心的,为业务服务的,从成本中心向价值中心转变。
其次,务必按部就班的建设,目前大部分的企业是处在第二阶段向第三阶段过渡,即从解决方案和工具建设过渡到平台整合,而不少企业尝试做一些更激进的举动,例如跳过数据的整合直接向人工智能进发,这种冒进往往是得不偿失的。
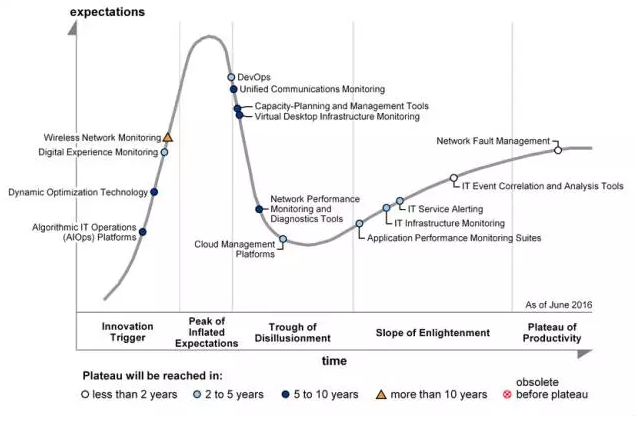
谈到现在最火爆的人工智能,在我们今天讨论的大数据分析领域,通常称之为AIOps,Artificial Intelligence for IT Operations,人工智能IT运营,全球最知名的第三方IT咨询公司Gartner称之为Algorithmic IT Operations,基于算法的IT运营。数据算法开始被应用到IT领域的分析和管理上,利用数据科学和机器学习来推进日益复杂的企业数字化进程。
现在AIOps的风口已经出现,Gartner预测到2020年,将近50%的企业将会在他们的业务和IT运维方面采用AIOps,远远高于今天的10%。我们可以参考Gartner在2016年发布的IT基础架构可用性和性能管理生命周期发展曲线,AIOps正朝着炒作的顶峰出发:
回到今天我们要讨论的数据分析领域,具体的建设思路也可以分成4个步骤:
集中管理:搭建大数据采集和存储平台,实现对各类日志数据的采集和集中存储、提供大数据搜索和分析能力;
数据规范化:建立数据规范,实现数据信息的标准化,将数据的采集和提取按照规范的标准形成有效的数据信息,提升数据价值的含金量。
场景的建设和展现:根据相关的业务内容,设计遵照业务规律的可视化分析场景,通过分析平台的数据统计分析功能,实现对业务数据的实时洞察。
业务感知/人工智能:不再从设备的维度而是从业务的维度来管理,关联或打通了业务和设备的逻辑关系。并且通过人工智能,强化训练,深度机器平台自主学习和对业务进行敏捷分析,挖掘业务场景分析价值,在这一个层级企业已经在某种程度上脱离了对专家的依赖,而是通过最新的技术手段越越了人的经验和人脑的容量能处理的能力,向机器管理机器目标发展。
三、建设思路
下面就如何以正确的姿势搭建大数据日志分析平台进行探讨,开始之前先总结下我们在传统日志分析领域遭遇的困境:
收集和管理困难:日志产生于各业务部门和多种设备上,数据隔离严重,分散存储,形式多样,存在各种格式规范;
缺乏海量日志处理能力:动辄上TB级别的海量数据无法高效处理和进行实时分析,非结构化数据更是难以处理;
缺乏可视化展现手段:展现手段陈旧、传统。缺乏可视化报表系统,难以有效展现数据信息,无法结合实际运维和业务场景展现数据价值;
无法进行安全合规审计:各种未授权访问等安全事件无法统计,缺乏事件回顾和调查途径,无法进行安全合规审计;
存在大量的信息孤岛,信息直接的价值无法关联,信息价值无法叠加。无数有价值的信息长期散落孤岛中被忽略。
所以,如何才能应对这些挑战?这里提到的仅仅是传统日志分析的问题,具体到实际工作的数据源,往往更复杂,我们称之为异构数据。
运维体系的异构数据,日志是一种典型的非结构化文本数据,还有已经结构化的关系型数据库的数据,还有现在应用很广的旁路抓包解码的数据,可以看到这些来自生产系统的数据基本都是非侵入式产生的数据,收集的时候不会影响系统运行,但又存在巨大的价值一直没有被挖掘,放在被遗忘的角落。
此外,还有很多现有IT运维的系统数据可以进行整合,比如监控报警平台、自动化运维、CMDB、应用性能监控等,都可以通过API接口把数据输送过来,联合日志,结构化数据,解码数据进行统一分析展现。
这就是今天要和大家重点探讨的,如何搭建海量异构大数据的日志分析平台,为企业提供各类型数据统一接入、存储和分析的能力,提供一个完整、统一、实时的高效异构数据分析平台。
应该使用何种技术来实现这个平台呢?
问题1:可以用传统的关系型数据库去实现吗?答案是否定的,传统关系型数据库对海量数据的处理性能捉襟见肘,更难以应对非结构化的数据。只有将各类数据统一到文本型数据分析平台,集中进行存储和分析是最佳的解决方案。
问题2:可以用ELK去实现吗?ELK在互联网领域比较流行,拿来即用,要求不高,但对于传统企业来说,就不太合适了。这里也稍微对ELK为什么不适合传统企业做一下说明:
ELK由Elasticsearch、Logstash和Kibana三部分组件组成,目前是开源界最流行的实时数据分析方案之一。
Elasticsearch是个开源的实时全文搜索和分析引擎,主要特点如下:
支持实时检索、亿级数据秒级返回结果;
属于分布式系统,节点对外表现对等,加入节点自动均衡;
输入/输出格式为 JSON;
可根据不同的用途分索引,可以同时操作多个索引;
基于Apache Lucene搜索引擎库
Logstash是轻量级的日志处理框架,负责日志的搜集、过滤、传送,主要特点如下:
分布式集群架构、模块化设计。
安装部署方便,支持不同操作系统。
扩展性强,支持自定义插件,内置120多个正则格式。
output插件,自带90多种插件。
性能配置性强,通过配置方式组合各类插件。
支持不同的输入源及输出,自带的各类input、filter。
数据处理灵活性强。
Kibana负责前端图形界面的可视化展现,主要特点如下:
报表配置灵活,易于共享
集成丰富的图表库,支持复杂的分析报表
自由展示报表大小及位置
数据的实时统计分析
可以说ELK的这些特性可以非常好的满足互联网行业简单快速且具备一定开发能力的场合,而且越往后维护的成本越高,最重要的是ELK不少功能缺陷并不适合为传统企业进行大数据平台搭建。
例如消息队列缓存存在数据丢失隐患;用户认证及权限管理太弱,这个在开源界合适,但在企业场景是很难被接受的;不支持关联统计分析; ELK是三个独立的系统没有统一的部署、管理工具,无自身监控能力;无运维场景;无行业经验积累;难以定制性开发;无数据脱敏;无法即开即用等。
四、如何搭建
基于前面的分析,我们推荐真正可以满足企业海量异构日志数据实时分析的大数据平台应该是下面这个样子的:
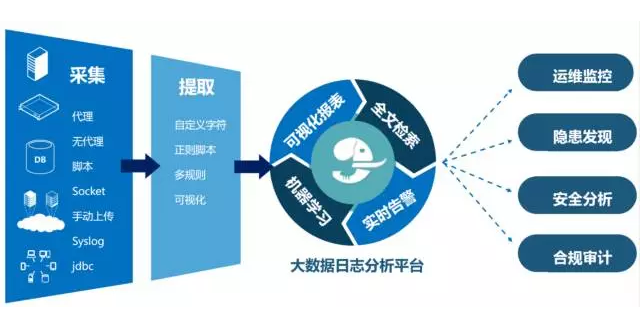
概括来说就是通过多种数据采集的途径,从各个地方收集海量各种类型日志数据。通过强大的字符提取方法对文本数据进行切割提取,结合大数据平台的可视化报表、全文检索、实时告警、机器学习等功能,搭建适合企业应用的各种大数据分析场景,例如运维监控、隐患发现、业务分析,合规审计等,真正把平台的能力在企业运维工作中落地实施。
那么,构建这样一个大数据日志分析平台,应该要具备哪些基本的能力?
1、集中存放、分布式存储
传统的网络存储系统采用集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,也是可靠性和安全性的焦点,不能满足大规模存储应用的需要。分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
2、实时搜索
平台通过底层的大数据分布式系统和大规模并行IO读写的能力,提供接近物理IO极限的处理性能,拥有卓越的实时在线分析能力数十倍于传统关系型数据库,提供真正意义上的实时大数据,例如对数十亿数据进行暴力搜索扫表,仅需数十秒即可返回检索结果。
3、增强搜索处理语言
平台需支持搜索处理语言,语言使一般用户也能快速熟悉分析语言,提供在线统计分析、算法、挖掘功能,进行各种问题回朔和取证。支持相关逻辑表达式(“and, or,<,>,<=,>=,+,-,in”)的关联运算,同时也支持聚合函数的运算(如count,sum),字符串/数字/时间操作函数。
同时需要支持在搜索结果界面直接展示分布图,对结果进行图形化的下钻展示和取样操作。语法需灵活易学,可以让平台的使用者快速上手并迅速掌握。
4、权限管理
平台需支持灵活的权限和安全管理,权限跟用户组和用户角色级别相关。同时可配置数据的脱敏规则,根据用户设置脱敏权限,脱敏规则可以通过页面划取进行配置,提高的系统的易用性及安全性。
5、机器学习
平台具备机器学习的能力,用大数据的方式采样和分析,为企业实现对异常状态的智能洞察和预测。
6、能力落地
最后需要强调,再强大的平台,也需要把平台能力在企业中进行落地,一切没有场景驱动的运维平台建设都是假大空,所以在考虑平台搭建时,必须要谨慎选择可以提供落地运维场景和端到端服务的合作伙伴。
五、我们的经验
依靠多年的运维经验,轻维软件建立了一整套完整的运维和分析体系,这个体系包括了监控、运维、应用/数据库性能分析、大数据日志分析等多个产品,产品之间既可以依照实际需要与各模块灵活组合,也可以轻松与企业现有的IT系统进行对接。
其中IVORY大数据日志分析平台,即是按照以上建设思路进行搭建,支持快速的数据结构化接入,为客户提供对海量日志数据实时搜索的能力和可视化展现,并且在这个基础上为用户提供包括机器学习在内的高级功能,IVORY大数据日志分析平台开箱即用,同时为用户提供独有的端到端的产品定制化服务,是大数据日志分析落地的最佳选择。
下图即是通用落地场景,主要包括运维监控、隐患发现、业务分析和合规审计四个方面:

找几个场景做下示例:
1、隐患发现之OSPF重传
发现系统中潜在的问题隐患,这些问题通常是被常规监控系统忽略的,例如下图:

这台设备从5月20开始产生大量的OSPF重传并且一直持续,这就是一种网络的潜在隐患并且是通过日志系统感知到的,而常规监控上来看这台设备是完全正常的。
2、趋势管理中发现之异常主备切换
在搜索框搜索Master,发现系统中发生117次主备切换事件:
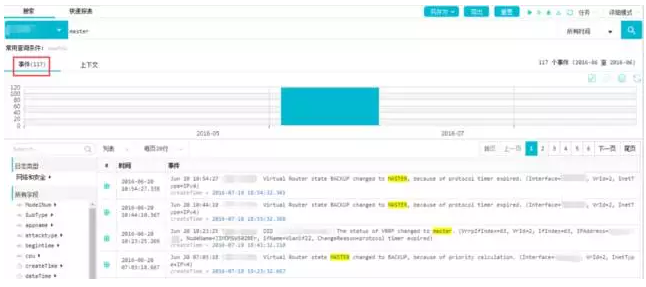
通过原IP统计,发现84%的切换与某IP设备有关,需进行重点隐患排查:

3、隐患发现之网络攻击
通过对网络设备日志相关类型分析,并且以直观的统计图表进行展现,协助识别网络攻击和异常隐患,提醒用户这些设备出现威胁网络安全的隐患,需要评估对网络造成的影响,提前做好防范措施。
某数通设备从某天开始每天出现20万条攻击记录,需进行相应防范:
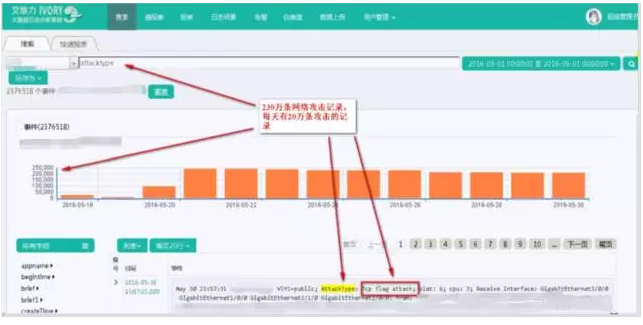
防火墙设备通过对IP和端口的拒绝访问趋势图,侦测潜在问题并进行重点关注:
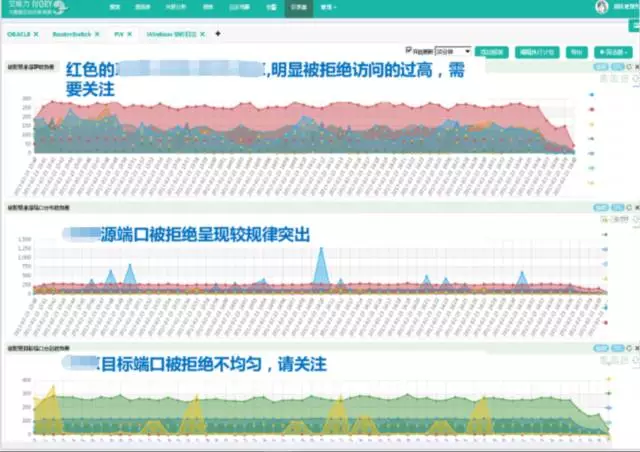
4、登录审计
可监控内部人员是否遵循了相应操作规范,对违规行为提前进行预警,出现故障后进行实时问题排查,例如对远程登录进行监控审计:
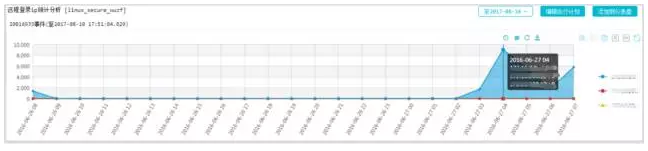
同时通过日志监测失败登录的情况,例如如果存在大量失败登录则表示可能存在通过软件模拟的暴力登录行为,如示例所示:
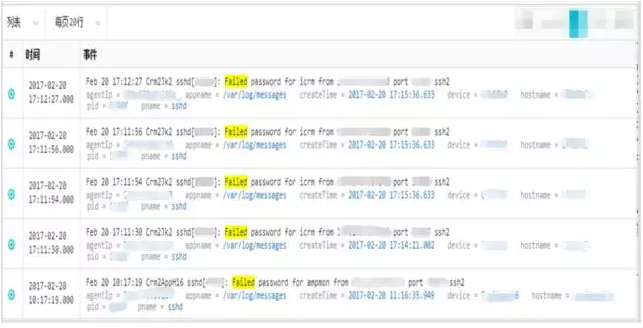
大部分失败均来自某IP节点,需重点进行关注:
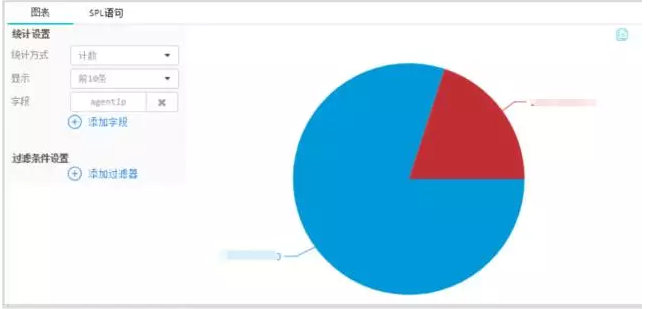
5、业务操作审计
发现安全隐患,根据交易数量、类型、频次、占例、来源地等分析操作的构成,发现异常的操作,对操作和业务的合规性进行审计。
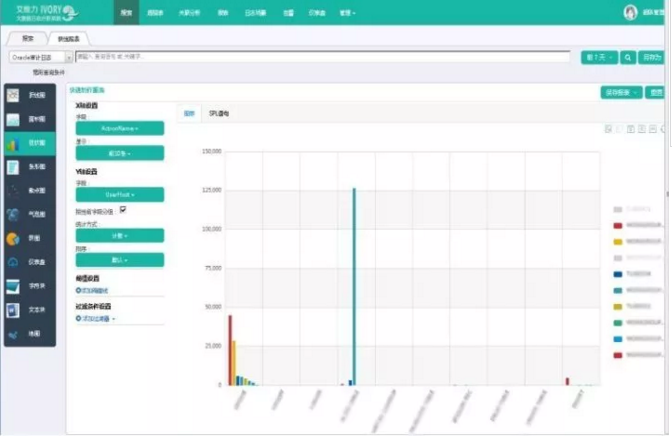
例如这个例子进行Oracle数据库操作审计,发现某主机存在大量修改表操作,正常来说应避免大量DDL操作以免影响稳定。
6、大屏展示
这个理论上不算是场景,是一种酷炫的可视化展现方式,通过对性能数据、配置数据、运维数据、运营数据等的离散与聚合,在大屏上进行个性化定制的展示。
实现业务和平台指标的聚合展现,用户可随时随地全景可视化了解大数据分析的所有情况。
最后做个总结,提升运维效率,协助管理决策,是IVORY所追求的最终价值。而建设大数据日志分析平台,不仅可以协助运维部门更加高效稳定的管理IT系统,同时可以让运维部门从IT成本中心更多地向IT服务中心、价值输出中心、利润输出中心进行转变。
今天的分享就到这里,谢谢大家!
Q1:现在系统环境千奇百怪,数量又多,要部署大量的日志收集的代理很是麻烦,有没有更便捷的方式做部署?
A1:可以参考使用自动化部署方案,在配置日志收集代理时,我们会找到相关的配置和部署规则,从规则中找出可以适合实现自动化部署和安装的那一部分,用自动化脚本加上可灵活自定义配置的方法来实现,如我们正在用自动化工具Ansible配合日志的收集。
Q2:现在日志的种类非常多种,怎么才能快速将非结构化的数据进行结构化,方便后续进行分析呢?
A2:日志种类确实是非常多样的,究其本质还是离不开日志的关键属性,如时间、来源、事件、日志级别、操作代码、内部错误码、提示信息等;我们将这些属性的信息进行相关维度的组合与匹配,便形成了结构化的数据,结合维度报表和关键字筛查与搜索可以直接有效地查询和分析,将这些分析结果进行聚类统计,并且用深度机器学习方法加以训练可以得出符合场景的精准分析。
Q3:运维人如何转变、如何修炼,才能游刃有余地处理AIops大数据日志?
A3:顶尖的运维人才是很多企业高薪追逐的对象,作为运维的老兵,是需要不断积累处理问题的方法和思路,持续不断地更新自身的知识,新技术的出现要有一定的敏锐视角,对线上业务怀有足够的敬畏之心,对新技术有强烈好奇的追求;现今我们讨论的技术焦点很有可能会被未来新的技术所淘汰,IT技术知识更新迭代非常迅速,只有不断学习、求新求变,才能在智慧运维的道路上拥有自己的一席之地,才能游刃有余地处理AIOPS。
Q4:这么多的代理节点,怎么去确保数据的可靠性,监控这块要怎么设计?
A4:数据的可靠性一直是线上系统需要关注的,作为数据的载体,我们的产品一直在注重数据的机密性、完整性和可靠性,这是信息安全CIA中三个重要性质。我们前端Flume数据采集的分布式、多代理、多副本、高可用,就是避免了不可靠传输,Agent,Collector和Storage,多Agent和数据源Source的关联,多节点的Master,各节点的Source和Sink,数据的水平扩展和横向扩展,都是在保证数据的完整性和可靠性;再配合Kafka的多个消费者场景,用Elasticsearch的实时、分布式、自动发现、索引自动分片和索引副本机制满足多数据源,自动搜索负载等进行可靠性保障。
Q5:日志分析一直被客户评价为:只能“诊断”,不能”治病“的工具,也就是说你可以查出哪里可能存在问题,但是解决不了那个可能存在的问题,日志分析的发展能否可以实现诊断+治病?
A5:日志分析是运维和开发人员诊断的依据,出现问题了,第一时间我们都是会被告知“日志有没有报错?”,规范运营系统对日志问题的梳理都有错误提示码,我们可以从相关FAQ列表中找出线索,定位并排查问题,最终解决问题;故障的自愈体系是我们日志未来研发的方向,我们的产品IVORY已经形成相关雏形,如依照错误码自动关联相关处理机制,如Oracle的ORA-错误码我们可以根据相关代码对应规则“对症下药”给出提示,诊断加治病随着版本的迭代,未来是可期的。
Q6:ES目前的分析能力比较有限,怎么去提高ES的计算能力呢?
A6:Elasticsearch 是一个基于 Lucene 的搜索服务,它提供了一个分布式多用户能力的全文搜索引擎,并提供了 Restful 接口,在我们的项目中,用Elasticsearch +Spark Streaming 使得读性能得到了提升,这个架构可以在亿级别数据表中,在十余秒内查询到所有满足查询条件的数据,由于Elasticsearch添加索引的同时SparkStreaming预先锁定资源,使得计算能力得到非常快的提升。但做这个事情是有前提条件的,就是我们的硬件计算需要资源非常充裕。
https://m.qlchat.com/topic/details?topicId=1910000016384979&isGuide=Y
密码:233








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721