
作者介绍
杨建荣,DBAplus社群联合发起人。现就职于搜狐畅游,Oracle ACE-A、YEP成员,超7年数据库开发和运维经验,擅长电信数据业务、数据库迁移和性能调优。持Oracle 10G OCP,OCM,MySQL OCP认证,《Oracle DBA工作笔记》作者。
MySQL的数据字典经历了几个阶段的演进,MySQL4.1 提供了information_schema 数据字典,一些基础元数据可以通过SQL来查询得到。
MySQL5.5 提供了performance_schema 性能引擎,可以通过参数performance_schema来开启/关闭,说实话,看起来是有些难度。
MySQL5.7 提供了 sys Schema,这个新特性包含了一系列的存储过程、自定义函数以及视图来帮助我们快速的了解系统的元数据信息,当然自MySQL 5.7.7推出以来,让很多MySQL DBA不大适应,而我看到这个sys库的时候,第一感觉是越发和Oracle像了,不是里面的内容像,而是很多设计的方式越来相似。所以按照这种方式,我感觉离AWR这样的工具推出也不远了。
对于实时全面的抓取性能信息,MySQL依旧还在不断进步的路上。因为开源,所以有很多非常不错的工具,产品推出。myawr算是其中的一个,现在看来当初的设计方式和现在sys库很有相似之处,感兴趣的可以自行搜索查看。
对于sys Schema,我觉得对DBA来说,有几个地方值得借鉴。
原本需要结合information_schema,performance_schema查询的方式,现在有了视图的方式,把一些优化和诊断信息信息通过视图的方式汇总起来,显示更加直观
sys Schema的有些功能在早期版本可能无从查起,或者很难查询,现在这些因为新版本的功能提炼都做出来了
如果想好好掌握这些视图的内涵,可以随时查看表的关联关系,对于理解MySQL的运行原理和问题的分析大有帮助,当然这个地方只能点到为止。
按照这种情况,没准以后会直接把sys完全独立出来,替代information_schema,performance_schema,没准以后还会出更丰富的功能,类似Oracle中的免费的statspack,还有闭源的AWR,实时的性能数据抓取,自动性能分析和诊断,自动优化任务等,当然只是我的猜想,根据我的认知,Oracle里也是这么走过来的。
对于sys Schema的学习,我是基于5.7.13-6这个版本,是用Oracle的眼光来学习的,准备好了吗,老司机开车了。
sys下的对象分布其实信息量很大,除了我们关心的视图和表以外,还有函数,存储过程和触发器。这些信息可以通过sys下的视图schema_object_overview来查看。
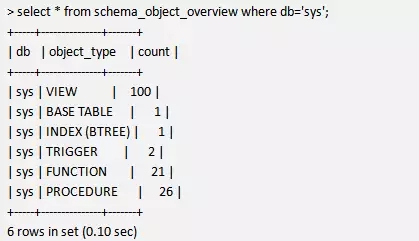
如果你观察仔细其实会发现里面的table只有一个,那就是sys_config,使用命令show tables显示出来的除了这个表都是视图。
这个视图有什么特别之处呢。

可以看到里面是一个基础参数的设置,比如一些范围,基数的设置。而且值得一提的是这个表里设置了几个触发器,对这个表的DML操作都会触发里面的数据级联变化。
sys_config的作用其实和Oracle AWR里面的设置非常相似,Oracle中是使用dba_hist_wr_control来得到。

然后我们继续查看,还是使用show tables来看,会看到整个sys下的表/视图有101个,其中x$开头的对象有48个,所以简单换算一下,里面的表/视图有53个。
x$的视图是什么意思,通过Oracle的角度来看,就很容易理解,意思是相通的。在Oracle中,数据字典分为两种类型,一类是数据字典表,像dba_tables这样的,基表都是tab$这种的表,数据是存放在系统表空间system下的,这些信息在MySQL中就有些类似information_schema下的数据字典,而另外一类数据字典是动态性能视图,Oracle是以v$开头的,比如v$session,它的基表是x$开头的“内存表”,在MySQL sys中也是类似的意思,只是这些信息MySQL都毫无保留的开放出来了。按照官方的说法,x$的信息是没有经过格式化的,比如下面的两个视图对比。

x$的视图的定义如下:

可以看到数据类型也有一些差别。如果是时间字段,在x$视图中可能精度是picosecond(皮秒,万亿分之一秒),而在普通视图中,就会格式化为秒。
我们抽取一个视图来看,就session吧,输出和show processlist命令如出一辙,我们来看看它的实现。使用show create view session可以看到引用的基表为`sys`.`processlist`,我们继续查看sys.processlist,可以发现它的基表是performance_schema下的`events_waits_current`,`events_stages_current`,`events_statements_current`,`events_transactions_current`,`session_connect_attrs`和sys下的基表`x$memory_by_thread_by_current_bytes` ,通过引用的这些视图其实可以看到也分了很多的层面。
而在Oracle中,因为主要是多进程多线程的实现方式(windows平台是单进程多线程),所以会有独立的v$session和v$process两个视图,两者通过内存地址的方式映射,所以在专用服务器模式下,就可以通过进程找到会话,或者通过会话找到进程,对于排查性能问题大有裨益。
sys下的视图分了哪些层面呢。我简单来总结一下,大体分为一下几个层面:
host_summary,这个是服务器层面的,比如里面的视图host_summary_by_file_io
user_summary,这个是用户层级的,比如里面的视图user_summary_by_file_io
InnoDB,这个是InnoDB层面的,比如innodb_buffer_stats_by_schema
IO,这个是I/O层的统计,比如视图 io_global_by_file_by_bytes
memory,关于内存的使用情况,比如视图memory_by_host_by_current_bytes
schema,关于schema级别的统计信息,比如schema_table_lock_waits
session,关于会话级别的,这个视图少一些,就两个,session和session_ssl_status
statement,关于语句级别的,比如statements_with_errors_or_warnings
wait,关于等待的,这个还是处于起步阶段,等待模型有待完善,目前只有基于io/file, lock/table, io/table这三个方面,提升空间还很大。
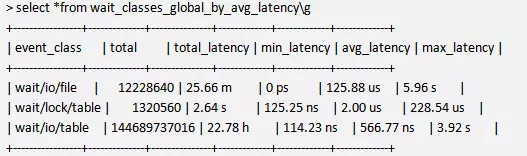
等待模型在Oracle中有一种流行的诊断方法论OWI,也就是Oracle Wait Interface。
OWI的信息会让调优变得更理性,更符合应用的场景。关于等待事件,Oracle的不同版本中也有着很显著的变化。
最初Oracle 7.0中有104个等待事件,8.0中有140多个等待事件,Oracle 8i中有220多个等待事件,9i中有400多个等待事件,10g中有800多个等待事件,11g有1 100多个。随着等待事件的逐步完善,也能够反映出对于问题的诊断粒度越来越细化。
当然sys的使用其实还是比较灵活的,在5.6及以上版本都可以,是完全独立的。和Oracle里面的statspack,AWR非常相似。
里面InnoDB,schema,statement这三部分是格外需要关注的,我重点来说一下。
比如InnoDB部分的视图innodb_lock_waits。
我们做个小测试来说明一下。我们开启两个会话。
会话1: start transaction; update test set id=100;
会话2: update test set id=102;
这个时候如果在没有sys的情况下,我们需要查看information_schema.innodb_locks和innodb_trx,有的时候还会查看show engine innodb status来得到一些信息佐证。
查看Innodb_locks

查看innodb_trx

面对这些情况,该怎么处理,比如要杀掉会话,可能还会有些模棱两可。
我们来看看使用innodb_lock_waits的结果。这个过程语句都给你提供好了,只有1行信息,就是告诉你产生了阻塞,现在可以使用kill的方式终止会话,kill语句都给你提供好了。
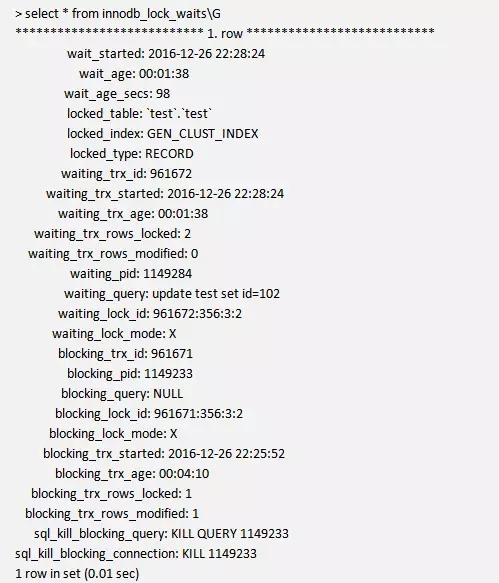
当然默认事务还是有一个超时的设置,可以看到确实是update test set id=102阻塞了。已经因为超时取消。
> update test set id=102;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
InnoDB相关的视图不多,只有3个,不过都蛮实用的。
我们继续看看schema层面的视图,这部分内容就很实用了。
schema_auto_increment_columns
schema_index_statistics
schema_object_overview
schema_redundant_indexes
schema_table_lock_waits
schema_table_statistics
schema_table_statistics_with_buffer
schema_tables_with_full_table_scans
schema_unused_indexes
如果要查看一个列值溢出的情况,比如是否列的自增值会超出数据类型的限制,这个问题对很多MySQL DBA一直以来都是一个挑战,视图schema_auto_increment_columns就给你包装好了,直接用即可。以下输出略微做了调整。
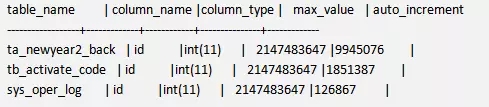
如果一个表的索引没有使用到,以前pt工具也可以做一些分析,现在查个视图就搞定了。当然索引的部分,一方面和采样率也有关系,不是一个绝对的结果。查看schema_unused_indexes的结果如下:

如果要查看那些表走了全表扫描,性能情况,可以查看schema_tables_with_full_table_scans,查询结果如下,如果数据量本身很大,这个结果就会被放大,值得关注。
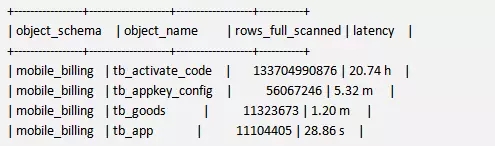
如果查看一些冗余的索引,可以参考 schema_redundant_indexes,删除的SQL语句都给你提供好了。

接下来是statement层面的视图,大体有下面的一些:
statement_analysis
statements_with_errors_or_warnings
statements_with_full_table_scans
statements_with_runtimes_in_95th_percentile
statements_with_sorting
statements_with_temp_tables
这部分内容对于分析语句的性能还是尤其有用的。
比如查看语句的排序情况,资源使用情况,延时等都会提供出来。
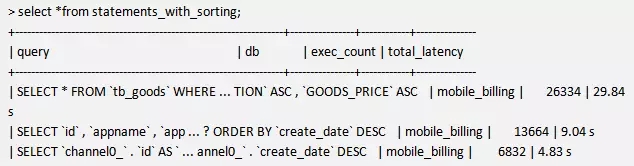
在这里SQL语句做了删减,不过大体能看出语句的信息,执行次数和 延时等都可以看到。
对于SQL语句中生成的临时表可以查看statements_with_temp_tables ,比如某一个语句生成的临时表情况,都做了统计。

最后来说说sys的备份和重建工作,如果查看sys的版本,可以使用视图version来得到。可见是把它当做一个独立的组件一样来维护的。
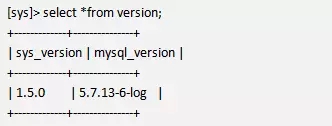
如果要导出,可以使用 mysqlpump sys > sys_dump.sql 或者mysqldump --databases --routines sys > sys_dump.sql来得到sys的创建语句,如果需要重建则更简单 mysql<sys_dump.sql 即可。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721