
知其然而不知所以然,学习技术不能停留在表面,而是要进一步去深入挖掘其中的原理,这样才能不断进步和成长。回到这个问题:为什么单表数据量不能超过两千万,其中的依据是什么?
事情是这样的:
小王最近参加了腾讯的技术面试,面试官向他提了一个经典的面试问题:聊聊你日常项目里的分库分表实践?
于是小王以过往项目里的某个 case 为例做了回答:
我负责的项目里涉及到存储用户操作记录的功能,因为每天的数据量比较大,差不多超过 5000 万条,所以我另外又做了分库分表的操作。系统会自动定时生成 3 张表,数据分别存储其中,防止都放在一个表里面导致查询性能降低。
面试官又问:这里为什么要做一个分库分表的操作呢?如果放在同一张表里面,为什么会导致查询性能降低?
小王内心 OS:为什么1+1=2?但他还是语气平常地回答说:
MySQL 单表不要超过 2000 万行基本上是一个行业共识,只有当单表行数超过 500 万行或者单表容量超过 2GB,我们一般才推荐进行分库分表。
面试官点了点头表示认可,却也没有在这个问题上继续深究,继而问起了别的问题,不久后就结束了面试。小王回过神来以后复盘这次面试过程,觉得自己在 MySQL 分库分表问题上没有回答得特别到位,于是他开始进一步地深究起来这个“1+1=2”的问题。
一、自增主键角度
我们先来看看单表数据量理论上最大值是多少?
假设我们建表,ID 是自增主键,也就是说主键的大小可以限制表的上限。如果主键声明为 int 类型,那么 int 类型最大为2的32次方 – 1 ,也就是21亿左右;
如果主键声明为 bigint 类型,那么 bigint 类型最大为2的64次方 – 1,这个数字实在太大了,一般还没到这个限制,磁盘就撑不住了;
如果主键声明为tinyint类型,那么 tinyint 类型最大为2的8次方 – 1,也就是255,所以如果我插入一条 ID=256 的数据,就会报错;
上面是从自增主键的角度来讲述单表最大数据量理论上能达到多少,那么接下来从另一个角度“数据页”来阐述一下,单表数据量最大能达到多少,依据是什么?
二、数据页角度
假设我们有一张 user 表,其中 ID 是自增主键,那么该表在硬盘文件上是 user.ibd(innodb 数据文件,又叫表空间文件)。这个数据文件被划分成很多的数据页,每个数据页大小是16K。
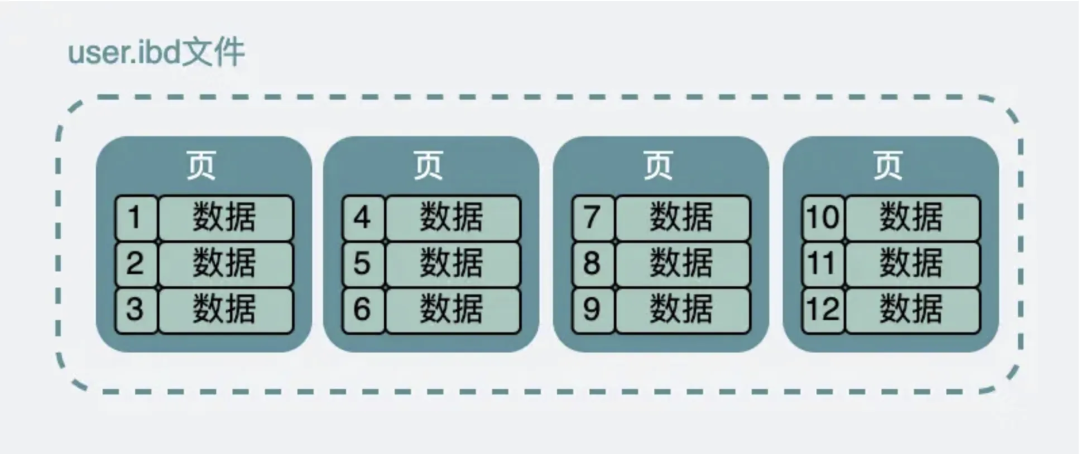
一个数据页16K,表的数据量很多,一个数据页可能放不下那么多数据,所以数据被分成好多份,存放在不同的数据页,为了标识具体是哪一个数据页,所以需要有页号来标识;
同时为了把这些存放数据的数据页关联起来,又引入了前后指针,用于指向前后的页;
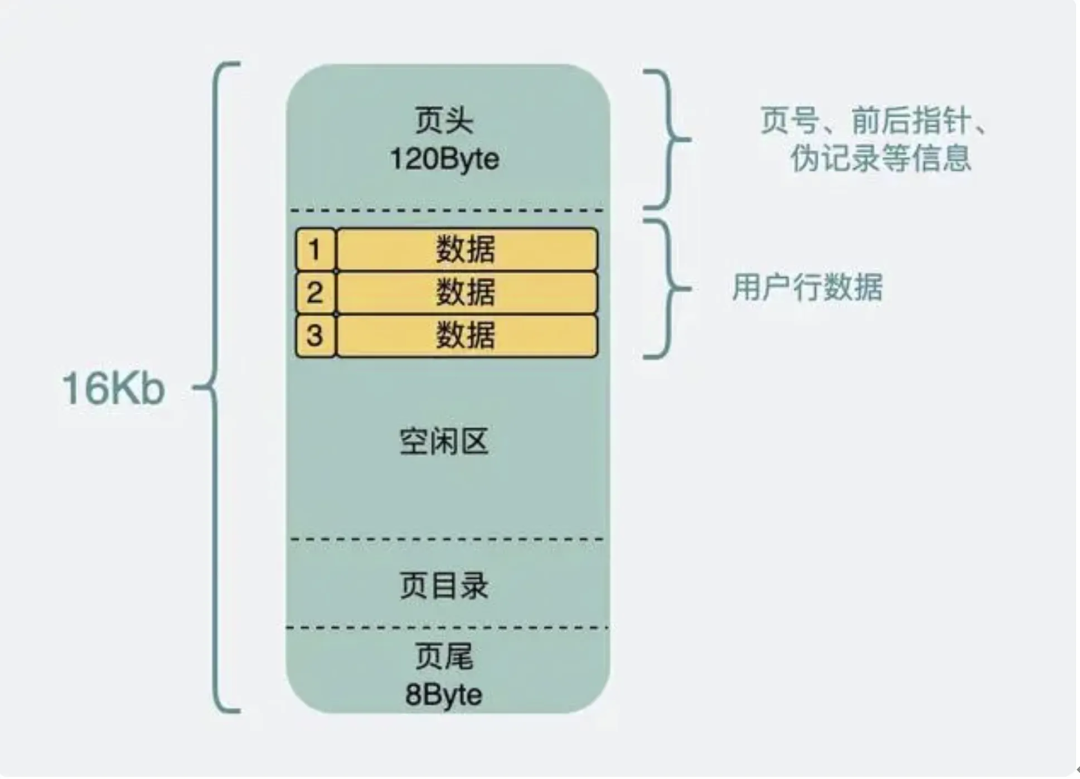
数据页需要读写,写入到一半的过程中可能会发生了意外断电等情况,所以为了保证数据页的准确性,还引入了校验码;
同时为了在数据页搜索数据提高效率,数据页内部还生成了页目录;
除了上述所说的,数据页内剩下的空间就用来存放实际的数据;
即数据页的结构如下:
数据是以数据页的形式进行存储,数据页和数据页之间是以B+树的形式进行关联,例如:
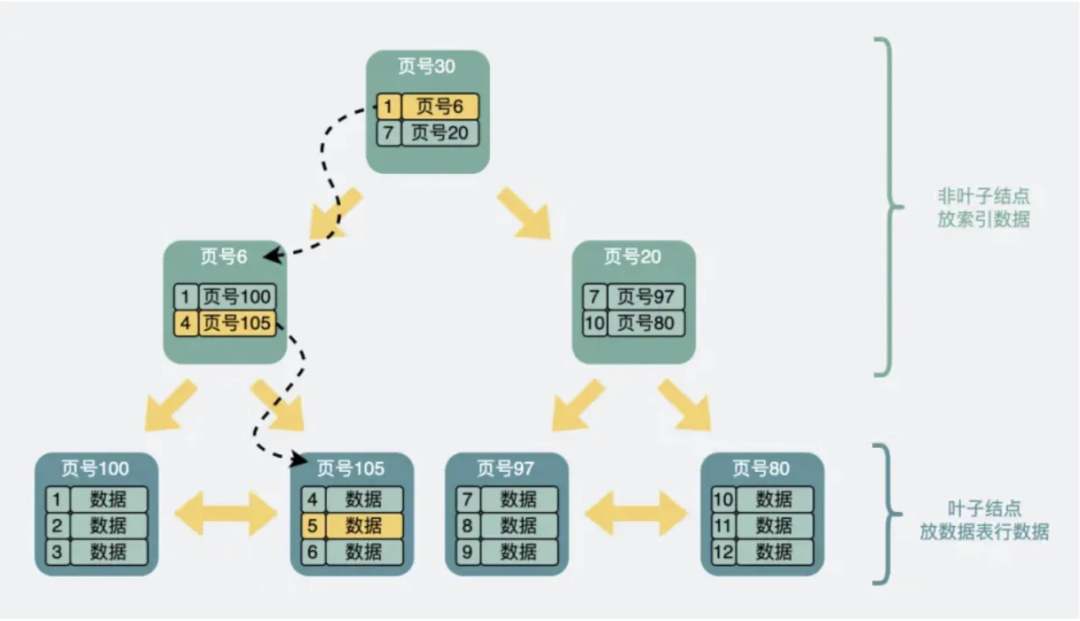
其中,叶子节点的数据页存放的是实际存储的数据,非叶子节点存放的是索引内容。B+树的每一层代表一次磁盘 IO。
举个例子,如果我要寻找 ID=5 的记录,从顶部非叶子节点开始查找,由于 ID=5 大于1并且小于7,故应该往左边寻找,来到页号为6的数据页,由于5大于4,故应该往右边寻找,来到页号为105的数据页,找到 ID=5 的记录,完成查询。
这个过程中查询了三个数据页,如果这三个数据页都没有加载到内存,那么就需要经历三次磁盘 IO 查询。
了解完 B+树是如何存储数据的,我们就可以开始进行数据的估算。
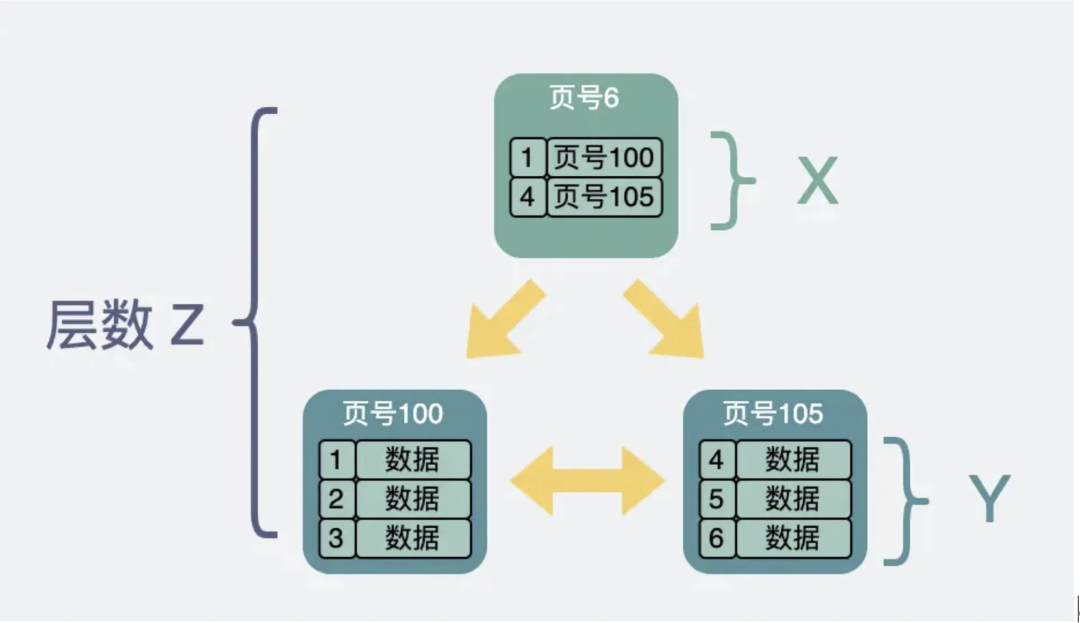
假设:非叶子节点内指向其他数据页的指针数量为 X(即非叶子节点的最大子节点数为 X);每个叶子节点可以存储的行记录数为 Y;B+树的高度为 N(即 B+树的层数);
对于一个高度为 N 的 B+树,顶层(根节点)有一个非叶子节点,那么第二层就有X个节点,第三层就有 X 的2次方个节点,第四层就有 X 的三次方个节点,以此类推,第 N 层(即叶子节点所在的第 N 层)就有 X 的 N-1 次方个节点;
在 B+ 树中,所有的记录都存储在叶子节点中,假设每个叶子节点都可以存储的行记录数为 Y;
那么 B+ 树可以存储的数据总量为叶子节点总数乘以每个叶子节点存储的记录数,即:M=(X 的 N-1 次方)乘以 Y;
代入计算:
一个数据页大小16K,扣除页号、前后指针、页目录,校验码等信息,实际可以存储数据的大约为15K,假设主键ID为bigint型,那么主键 ID 占用8个 byte,页号占用4个 byte,则 X=15*1024/(8 + 4) 等于1280;
一个数据页实际可以存储数据的空间大小,大约为15K,假设一条行记录占用的空间大小为1K,那么一个数据页就可以存储15条行记录,即 Y=15;
假设 B+树是两层的:则 N=2,即 M=1280的(2-1)次方 * 15 ≈ 2w ;
假设 B+树是三层的:则 N=3,即 M=1280的2次方 * 15 ≈ 2.5 kw;
假设 B+树是四层的:则 N=4,即 M=1280的3次方 * 15 ≈ 300亿 ;
综上所述,我们建议单表数据量大小在两千万。当然这个数据是根据每条行记录的大小为 1K 的时候估算而来的,而实际情况中可能并不是这个值,所以这个建议值两千万只是一个建议,而非一个标准。
三、思考
最后考一个问题:一个4层的 B+树,主键是 bigint 型,一条记录平均长度是1K,不考虑碎片,能存放多少条记录?
答案:
根据 B+树存储数据的计算公式:M = X 的 N-1 次方 * Y:
一个数据页大小16K,扣除页号、前后指针、页目录,校验码等信息,实际可以存储数据的大约为15K,假设主键 ID 为 bigint 型,那么主键 ID 占用8个 byte,页号占用4个byte,则X=15*1024/(8 + 4) 等于1280;
每条记录1K大小,一个数据页有15K是用来存储数据的,那么一个数据页就能存储15条记录;
所有叶子节点数量为 X 的 N-1 次方,即1280*1280*1280;存储的记录数总数为:叶子节点数量 * 每个叶子节点存储的记录数,所以 M = 1280*1280*1280*15。
你,学会了吗?








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721