
这次带大家盘一个觉得有点意思的东西,之前研究分页的时候,遇到一个神奇的现象,但是当时忙着搞定这个主线任务,就没有去深究这个支线任务。
现在我们一起把这个支线任务盘一下。
一、啥支线任务?
之前不是写分页嘛,分页肯定就要说到 limit 关键字嘛。
然后我啪地一下扔了一个链接出来:
https://dev.mysql.com/doc/refman/8.0/en/limit-optimization.html

这个链接就是 MySQL 官方文档,这一章节叫做“对 Limit 查询的优化”,针对 limit 和 order by 组合的场景进行了较为详细的说明。
链接里面有这样的一个示例。
首先,针对一张叫做 ratings 的表给了一个不带 limit 的查询结果:
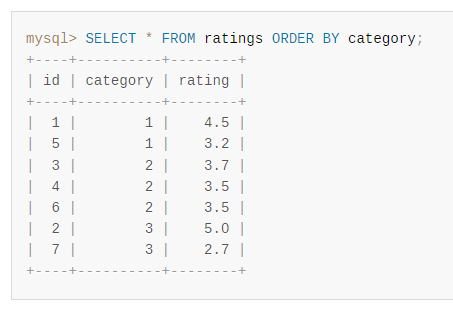
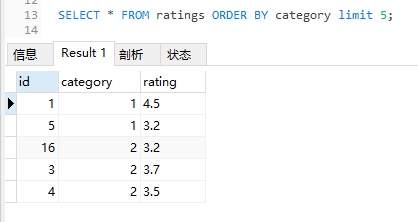
可以看到,一共有 7 条数据,确实按照 category 字段进行了排序。
但是当我们带着 limit 的时候,官方文档上给出的查询结果是这样的:
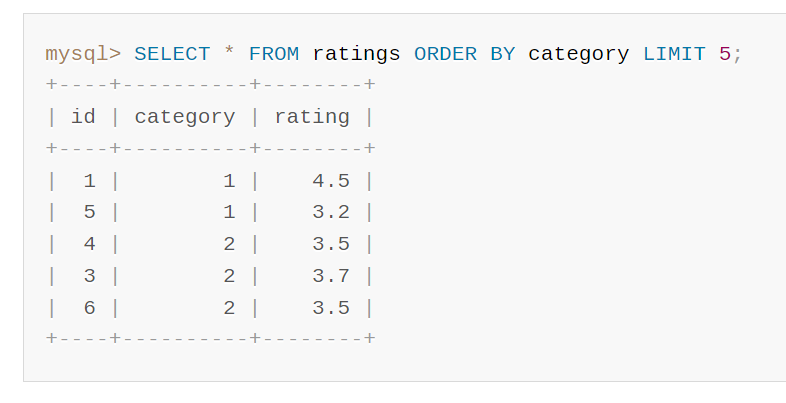
为了让你更加直观地看出差异,我把两个结果给你放在一起:
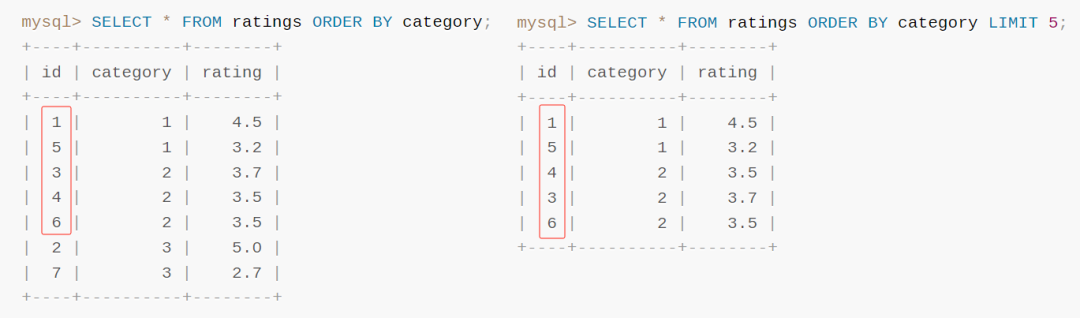
没排序之前,前五条对应的 ID 是 1,5,3,4,6。
排序之后,前五条对应的 ID 是 1,5,4,3,6。
这就是官方的案例,非常直观地体现了 order by 和 limit 一起使用时带来的 nondeterministic。
我一向是比较严谨的,所以我想着在本地复现一下官网的这个案例。
我本地的 MySQL 版本是 8.0.22,以下 SQL 均是基于这个版本执行的。
首先,按照官网上的字段,先“咔”的一下整出表结构:
CREATE TABLE `ratings` (`id` int NOT NULL AUTO_INCREMENT,`category` int DEFAULT NULL,`rating` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB;
然后“唰”地一下插入 7 条数据:
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (1, 1, '4.5');INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (2, 3, '5.0');INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (3, 2, '3.7');INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (4, 2, '3.5');INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (5, 1, '3.2');INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (6, 2, '3.5');INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (7, 3, '2.7');
接着“啪”地一声执行一下不带 limit 的 SQL,发现运行结果和官网一致:
SELECT * FROM ratings ORDER BY category;
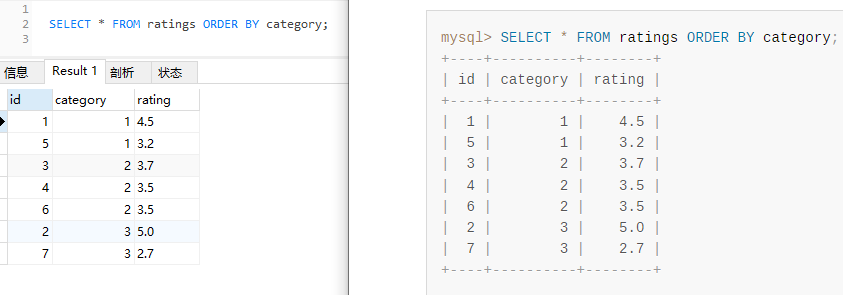
然后“咻”地声执行一下带 limit 的 SQL:
SELECT * FROM ratings ORDER BY category LIMIT 5;
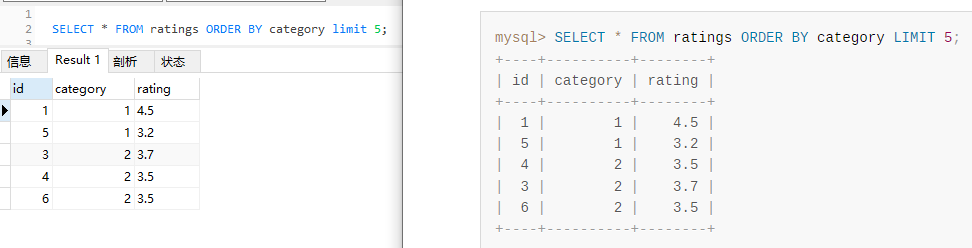
等等,运行结果不一样了?
你把表结构拿过去,然后分别执行对应的 SQL,大概率你也会发现:怎么和官网上的运行结果不一样呢?
为什么运行结果不一样了呢?
这就是我当时遇到的支线任务。
二、大力出奇迹
当我遇到这个问题的时候,其实我非常自信。
我自信的知道,肯定是我错了,官方文档不可能有问题,只是它在展示这个案例的时候,隐去了一些信息而已。
巧了,我也恰好知道怎么去触发 order by 和 limit 组合在一起时的“数据紊乱”的情况:当 order by 的字段重复率特别高的时候,带着 limit 查询,就会出现官网中的现象。
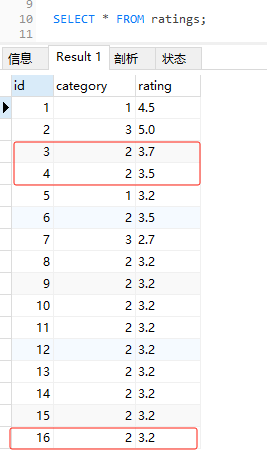
我直接先插入了 20 条这样的数据:
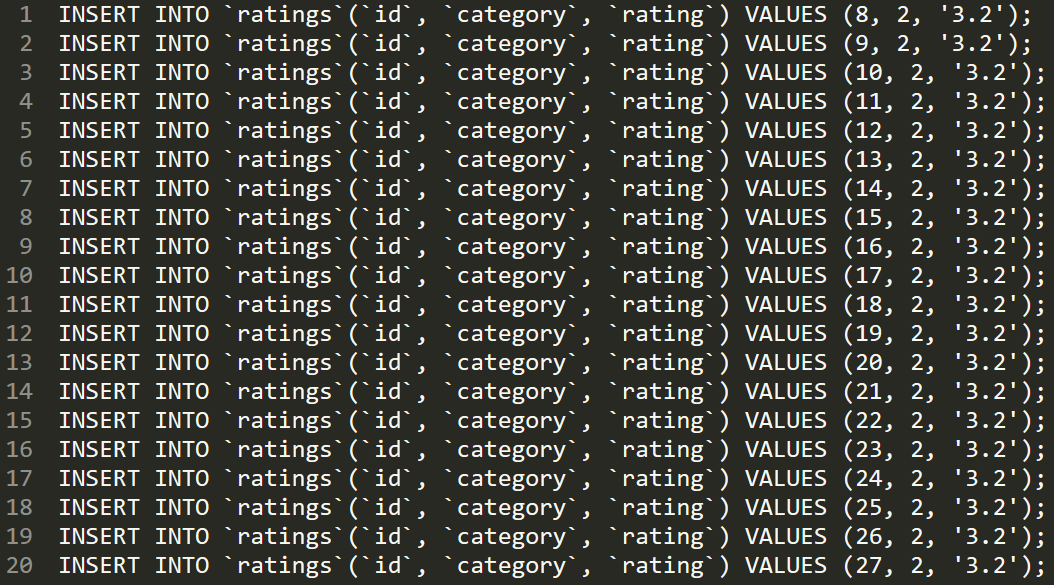
(实际上我第一次运行的时候,插入了 100 条这样的数据,所以,这一小结的名字叫做:大力出奇迹。)
这样在表中就有大量的 category 为 2 的数据。
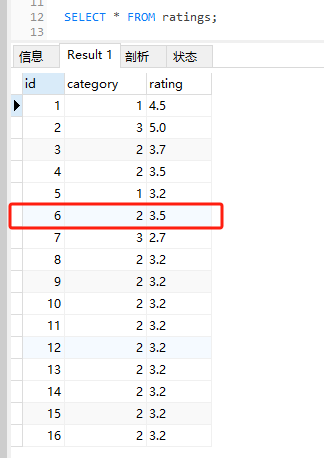
同样的 SQL,运行结果就变成了这样:
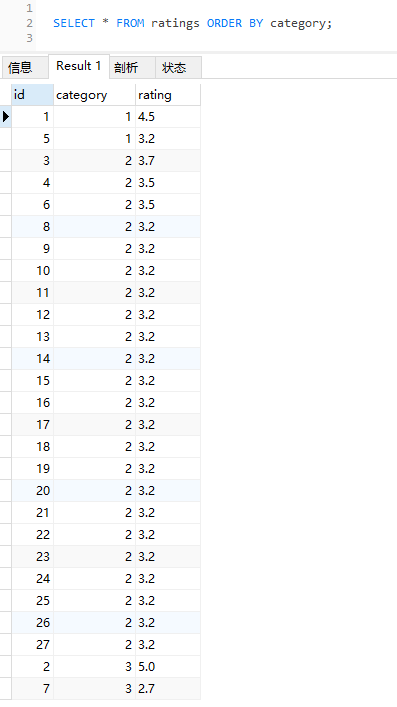
可以看到前五条数据的 ID 还是 1,5,3,4,6。
但是,当我运行这个 SQL 的时候,情况就不一样了:
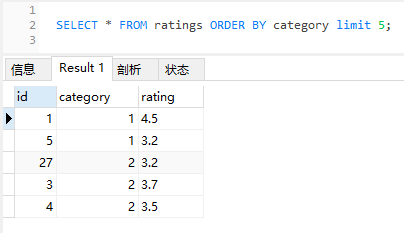
确实出现了官网中类似的情况,ID 为 27 的数据突然冲到了前面。
好,现在算是一定程度上复现了官网上的案例。
你知道当我复现这个案例之后,随之而来的另一个问题是什么吗?
那就是如果我开始的不插入 20 条 category 为 2 的数据,只是插入 10 条呢,或者是 5 条呢?
就是有没有一个临界值的存在,让两个 SQL 运行结果不一样呢?
你猜怎么着?
我以二分查找大法为抓手,为运行结果赋能,沉淀出了一套寻找临界值的打发,最终通过精准下钻,找到了临界值,就是 ID 为 16 的这条数据。
你先把这一批数据插入到表中:
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (8, 2, '3.2');INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (9, 2, '3.2');INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (10, 2, '3.2');INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (11, 2, '3.2');INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (12, 2, '3.2');INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (13, 2, '3.2');INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (14, 2, '3.2');INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (15, 2, '3.2');
然后分别执行这两个 SQL,运行结果是符合预期的:
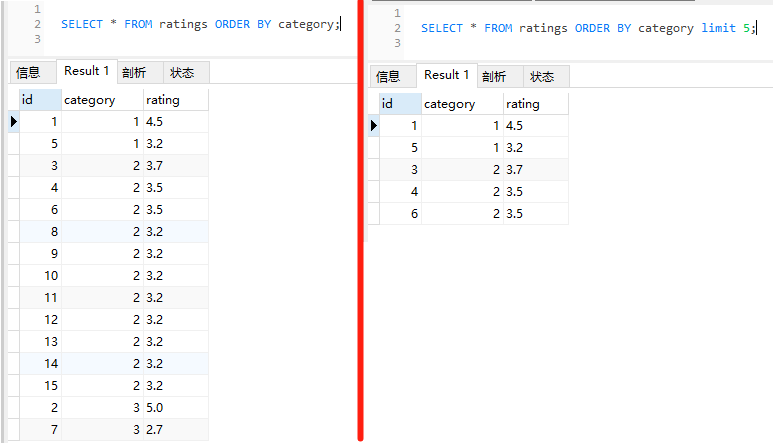
但是,一旦再插入这样的一条数据:
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (16, 2, '3.2');
情况就不一样了:
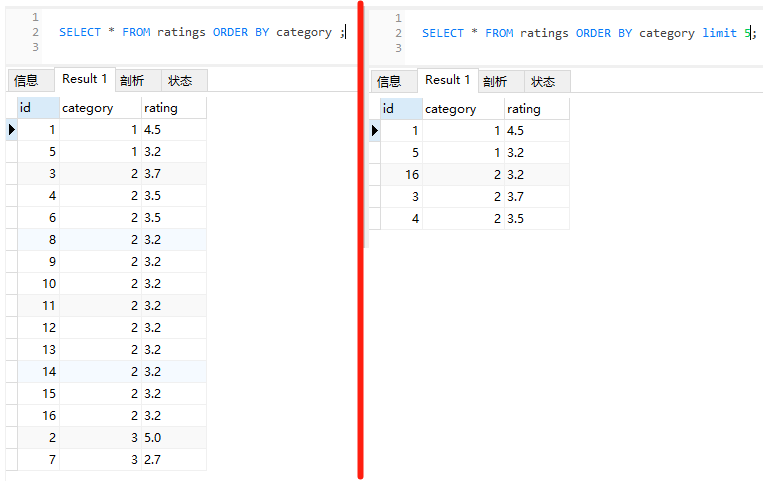
limit 语句查询出来的 id 就是 1,5,16,3,4 了。
16 就冒出来了。
很好,越来越有意思了。
为什么当表里面有 15 条数据的运行结果和 16 条数据时不一样呢?
我也不知道,所以我试图从执行计划中寻找答案。
但是,这两种情况对应的执行计划一模一样:
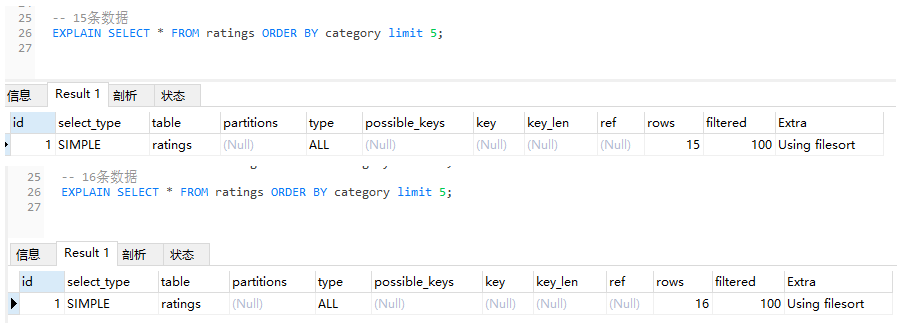
为什么会这样呢?
因为官网上还有这样一句话:

使用 EXPLAIN 不会区分优化器是否在内存中执行文件排序。
但是在优化器的 optimizer trace 的输出中的 filesort_priority_queue_optimization 字段,可以看到内存中文件排序的相关情况。
所以,这个时候得掏出另外一个武器了:optimizer_trace。
使用 optimizer_trace 可以跟踪 SQL 语句的解析优化执行的全过程。
这两张情况的执行结果不一样,那么它们的 optimizer_trace 结果也必然是不一样的。
于是我分别在 15 条数据和 16 条数据的情况下执行了这样的语句:
SET optimizer_trace='enabled=on';SELECT * from ratings order by category limit 5;SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`;SET optimizer_trace='enabled=off';
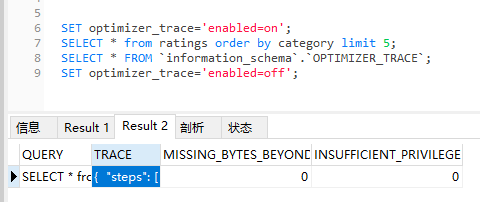
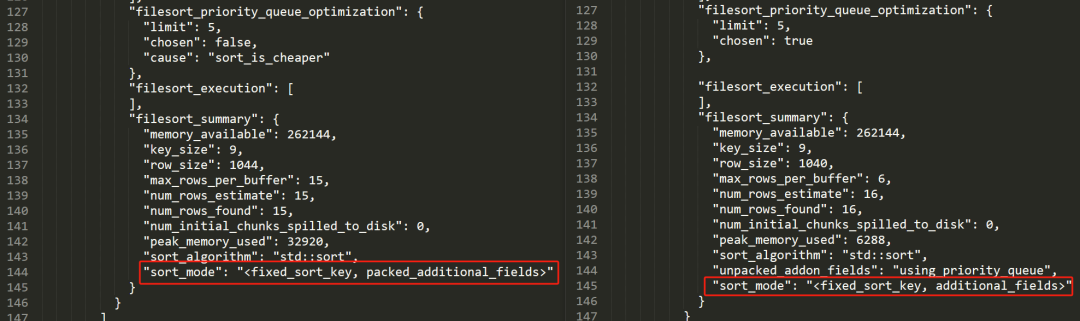
然后取出 optimizer_trace 结果中的 TRACE 数据,左边是 15 条数据的情况,右边是 16 条数据的情况:
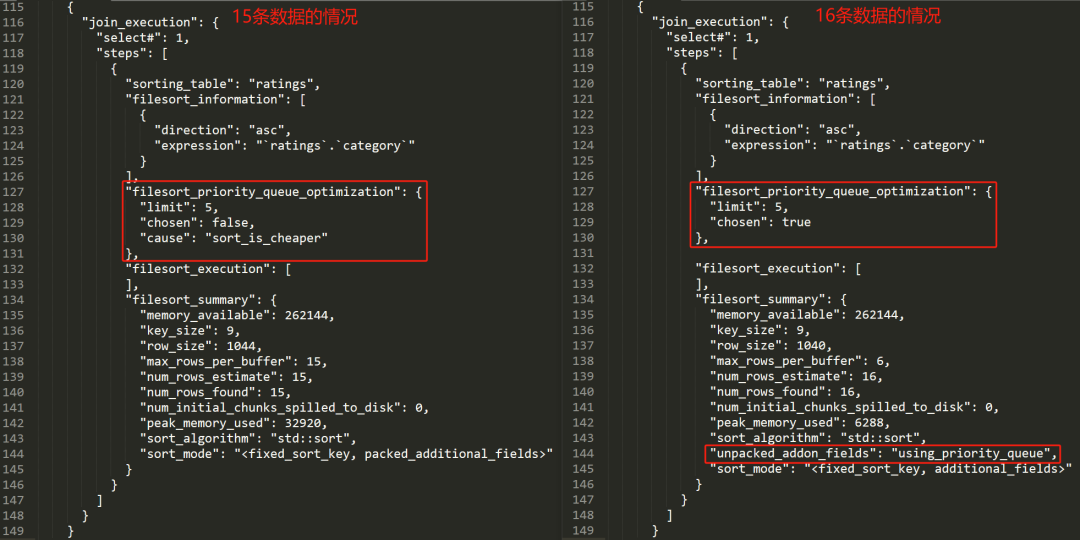
主要关注我框起来的部分,也就是前面提到的 filesort_priority_queue_optimization 字段。
这个字段主要是表明这个 SQL 是否使用优先级队列的方式进行排序。
在只有 15 条数据的情况下,它的 chosen 是 false,即不使用优先级队列。
"filesort_priority_queue_optimization": {"limit": 5,"chosen": false,"cause": "sort_is_cheaper"},
同时它也给了不使用的原因:sort_is_cheaper。
它认为直接进行排序的成本更低。
而我们也知道,大部分正常情况下 MySQL 就两种排序方式。如果 sort_buffer_size 够用,那么就在内存中使用快速排序完成排序。
如果 sort_buffer_size 不够用,那就借助临时文件进行归并排序。
但是你要注意,我前面说的是“大部分正常情况下”。
当我们程序中这种案例,order by + limit 的情况,MySQL 就掏出了优先级队列。
这个逻辑其实很简单嘛,limit 语句,不就是找 TOP N 吗?
那你说说,提到 TOP N 你是不是就能立马联想到优先级队列,想到堆排序?
翻出八股文一看:哦,原来堆排序不是稳定的排序算法。
那么不稳定会带来什么问题呢?
我们先按下不表,插个旗子在这里,等会儿回收。
继续回到 15 条数据和 16 条数据的情况,当时我找到这个临界值之后,我就在想:为什么临界值在这个地方呢?
一定是有原因的,我想知道答案。
答案在哪里?
我先在网上搜了一圈,发现可能是我冲浪的姿势不对,一直没找到能说服我的答案。
直到我有一天我干饭的时候,脑海里面突然蹦出了一句话:朋友,源码之下无秘密。
于是我桌子一掀,就起来了。
三、找源码
找源码这步,我就遭老罪了。
因为 MySQL 这玩意主要是用 C++ 写的:
虽然我经常也在说语言是相通的,但是我也确实很久没写 C++ 了。
一路坎坎坷坷终于找到了这个地方:
https://github.com/mysql/mysql-server/blob/trunk/sql/filesort.cc
这个里面有前面出现过的 sort_is_cheaper:
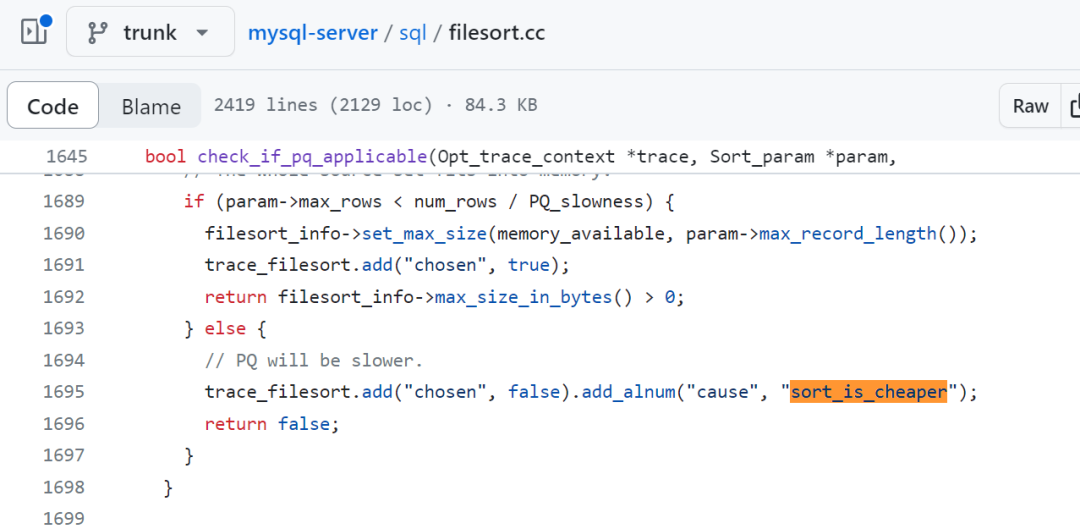
找到这里,就算是找到突破口了,就开始无限的接近真相了。
在 filesort.cc 这个文件里面,有一个方法叫做 check_if_pq_applicable:
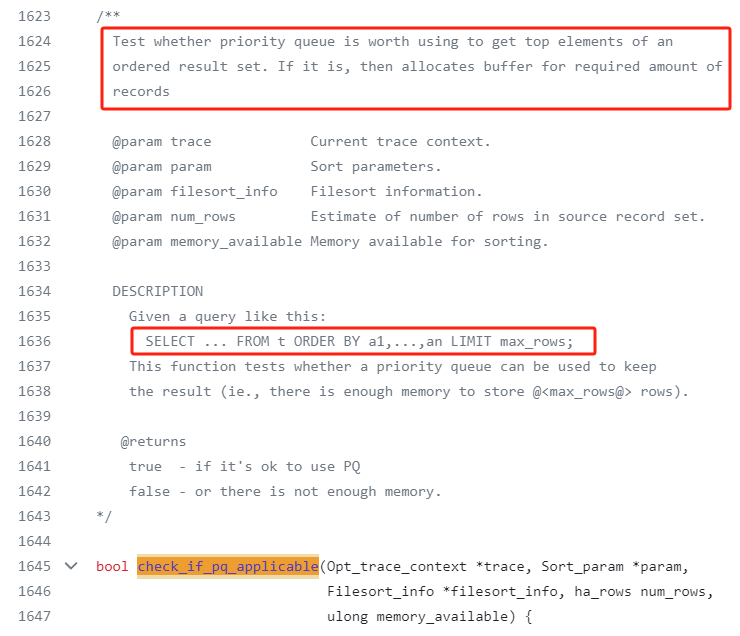
先关注一下这个方法上的描述:
Test whether priority queue is worth using to get top elements of an ordered result set.
翻译过来大概是说,看看是否值得使用优先级队列去获取有序结果级中的 Top 元素。
也就是这个方法主要就是评判“是否值得”这件事的。
如果值得呢?
If it is, then allocates buffer for required amount of records
如果值得,就为所需数量的记录分配对应的缓存区。
同时在描述部分还给出了一个对应的 SQL:
SELECT ... FROM t ORDER BY a1,...,an LIMIT max_rows;
这 SQL 样例不就是对应我们前面研究的 SQL 吗。
所以这里面一定能解决我的问题:
为什么临界值在 16 条数据这个地方呢?
瞟一眼源码,可以发现它大概是分为了 6 大部分判断:
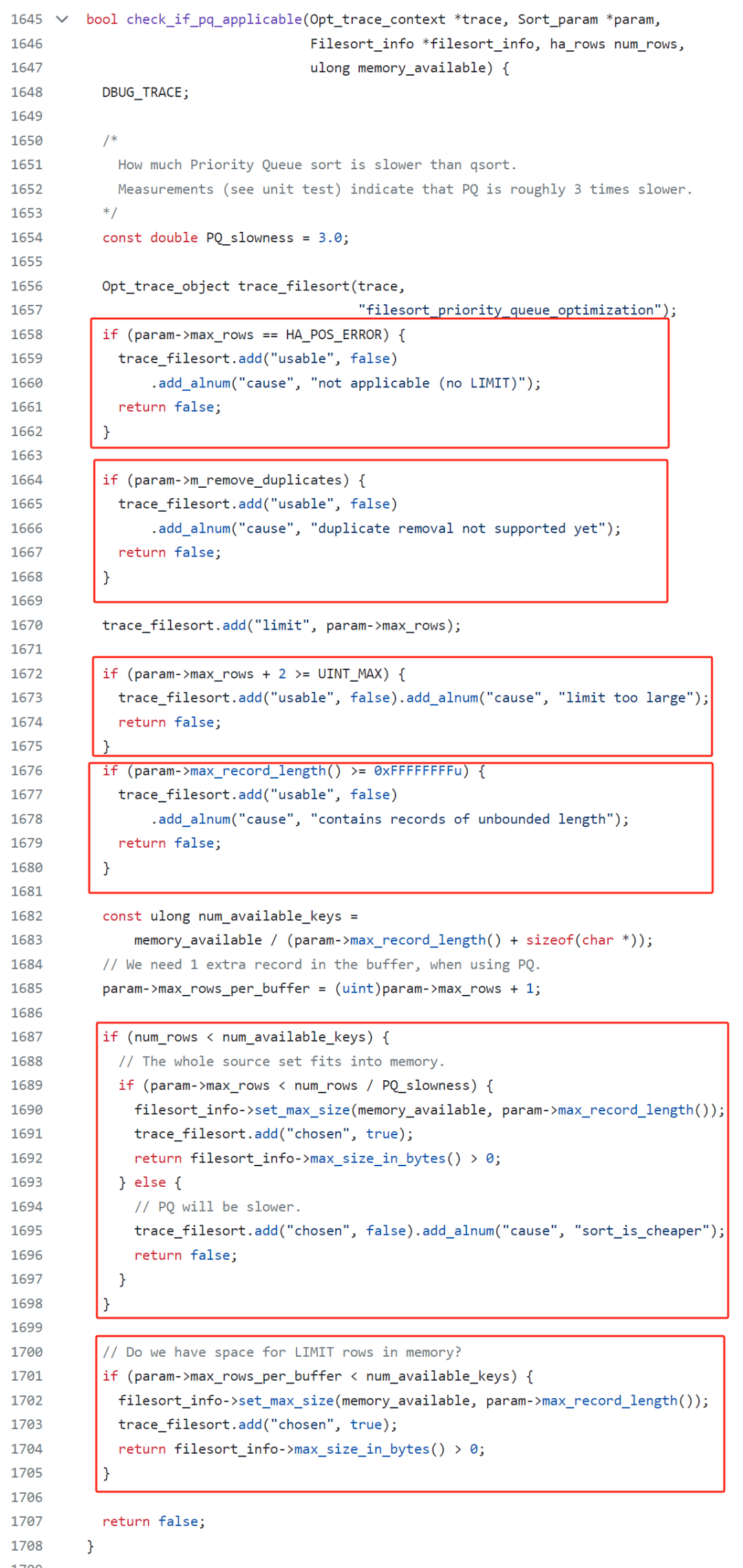
首先第一部分:

很明显,判断了 SQL 中是否有 limit 关键词。
如果 limit 都没有,那肯定不能用优先级队列了。
这一点,我们也可以通过 optimizer_trace 中的结果来验证:
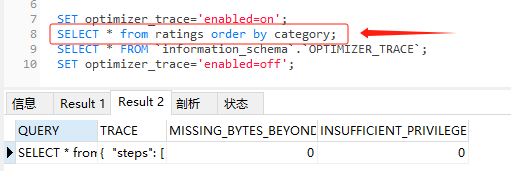
这个 SQL 对应的结果是这样的:
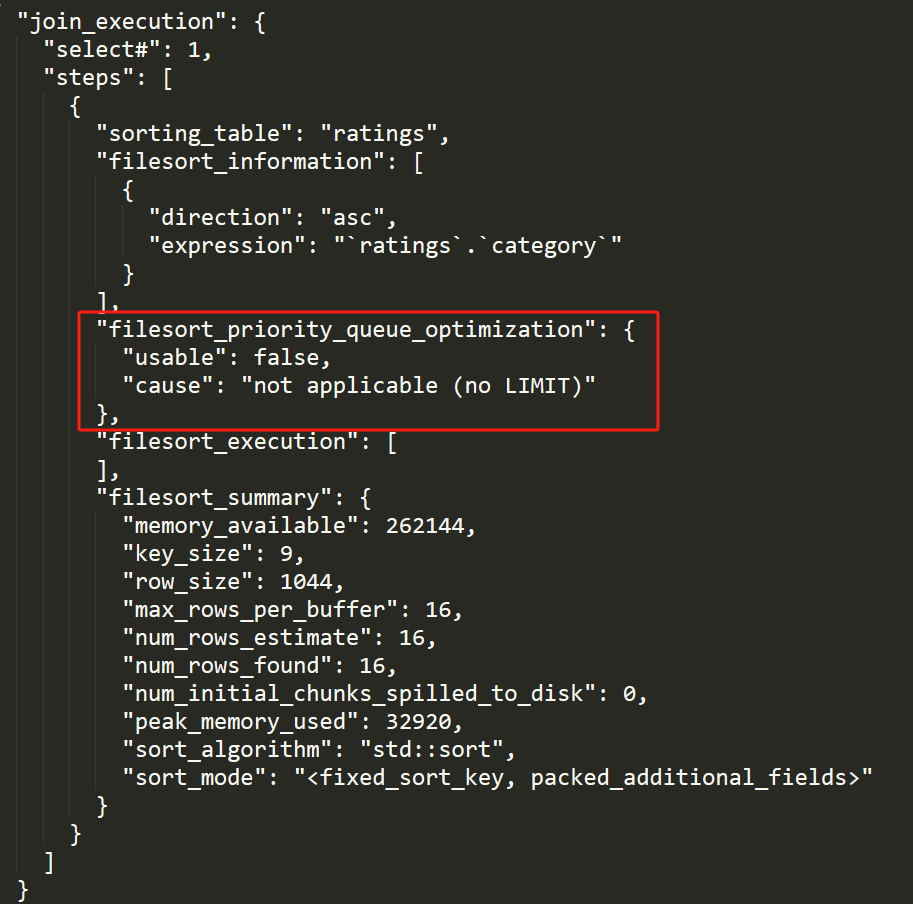
这不就和源码中的 “not applicable (no LIMIT)” 呼应上了吗?
然后看第二部分 if 判断:

如果 SQL 里面有去重的操作,则不支持。
第三部分和第四部分:

UINT_MAX - 2 指的是 priority queue 的最大容量。
然后我们先看最后一部分 if 判断:

也很好理解,要看看针对 limit 这部分的数据,内存够不够,放不放得下。放得下才能使用优先级队列。
主要看这部分:
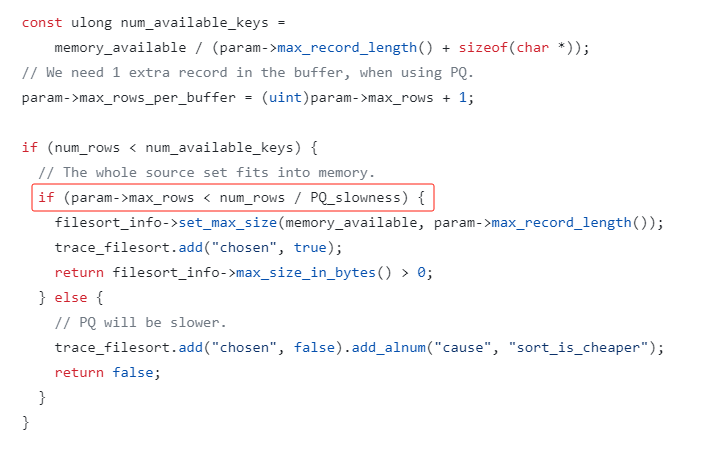
看这个判断条件:
if (param->max_rows < num_rows / PQ_slowness)
如果满足,就使用优先级队列。
如果不满足,就 “sort_is_cheaper”。
其中 max_rows 就是 limit 的条数,num_rows 就是数据库里面符合条件的总条数。
PQ_slowness 是什么玩意?
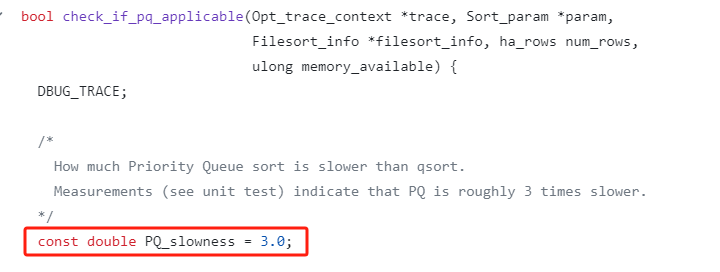
PQ_slowness 是一个常量,值为 3。
从这个值的描述上看,MySQL 官方认为快速排序的速度是堆排序的 3 倍,这个值也不是拍脑袋拍出来,是通过测试跑出来。
知道了每个字段的含义,那么这个表达式什么时候为 true 就很清晰了。
if (param->max_rows < num_rows / PQ_slowness)
已知,PQ_slowness=3,max_rows=5。
那么当 num_rows <=15 时,表达式为 false。num_rows>16 时,表达式为 true。
为 true ,则使用优先级队列进行排序。
临界值就是这样来的。
所以,那句话是怎么说的来着?
源码之下,无秘密。
四、再回首
前面盘完了 optimizer_trace 中的 filesort_priority_queue_optimization 字段。
接着再回首,看看结果文件中的这个 sort_mode 玩意。
关于 sort_mode 官网上也有专门的介绍:
https://dev.mysql.com/doc/refman/8.0/en/order-by-optimization.html

sort_mode 一共有三种模式。
第一种,<sort_key, rowid> 模式:
This indicates that sort buffer tuples are pairs that contain the sort key value and row ID of the original table row. Tuples are sorted by sort key value and the row ID is used to read the row from the table.
这种模式的工作逻辑就是把需要排序的字段按照 order by 在 sort buff 里面排好序。
sort buff 里面放的是排序字段和这个字段对应的 ID。排序字段和 ID 是以键值对的形式存在的。
如果 sort buff 不够放,那就让临时文件帮帮忙。
反正最后把所有数据都过一遍,完成排序任务。接着再拿着 ID 进行回表操作,取出完整的数据,写进结果文件。
第二种,<sort_key, additional_fields> 模式:
This indicates that sort buffer tuples contain the sort key value and columns referenced by the query. Tuples are sorted by sort key value and column values are read directly from the tuple.
这种模式和回表不一样,就是直接一梭子把整个用户需要查询的字段放在存入 sort buffer 中。
当然,还是会先按照排序的字段 order by ,在 sort buff 里面排好序。
这样全部数据读取完毕之后,就不需要回表了,可以直接往结果文件里面写。
其实我理解,第一种和第二种就是是否回表的区别。第二种模式应该是第一种模式的迭代优化。
因为不管怎么样,用第一种模式都能完成排序并获取数据任务。
至于怎么决策使用哪种方案,MySQL 内部肯定也是有一套自己的逻辑。
第三种模式是 <sort_key, packed_additional_fields>:
Like the previous variant, but the additional columns are packed tightly together instead of using a fixed-length encoding.
这种模式是第二种模式的优化。描述中说用 packed tightly together 代替了 fixed-length encoding。
啥意思呢?
比如我们的表结构中 rating 字段的类型是 varchar(255):
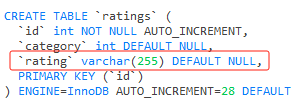
如果我只是在里面存储一个 why,那么它的实际长度应该是 “why” 这 3 个字符的内存空间,加 2 个字节的字段长度,而不是真正的 255 这么长。
这就是 “packed tightly together”,字段紧密的排列在一起,不浪费空间。
sort buffer 就这么点大,肯定不能太浪费了。
我之前确实不知道这个东西,所以趁这次查漏补缺了一下,属于又拿捏了一个小细节。
五、堆排序
哦,对了,前面还插了一个旗子,我回收一下。
既然都提到堆排序了,那我们就按照堆排序的逻辑盘一盘数据库里面的数据。
目前数据库里面全部的数据是这样的:
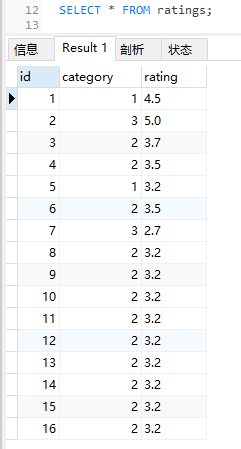
因为是 limit 5,所以先把前五条拿出来:
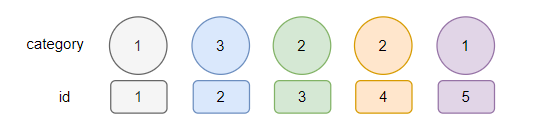
我们先按照 category 构建小顶堆,只是用不同的颜色来表示不同的 ID。
那么前五条数据构建出来的小顶堆是这样的:
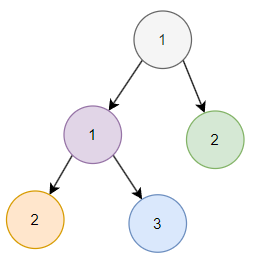
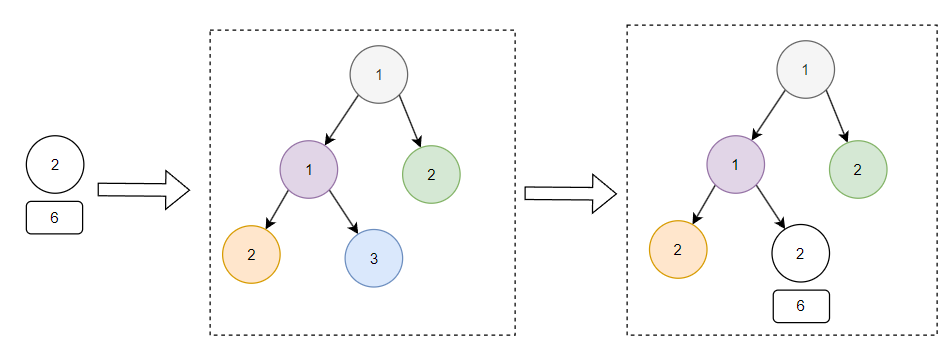
接着,下一条数据是 id 为 6,category 为 2 的数据:
把这条数据放到小顶堆之后变成了这样:
再下一条数据为 id 为 7,category 为 3 的数据。
由于 3 大于 2,所以不满足放入小顶堆的条件。
再下一条数据为 id 为 8,category 为 2 的数据,所以会把小顶堆变成这样:
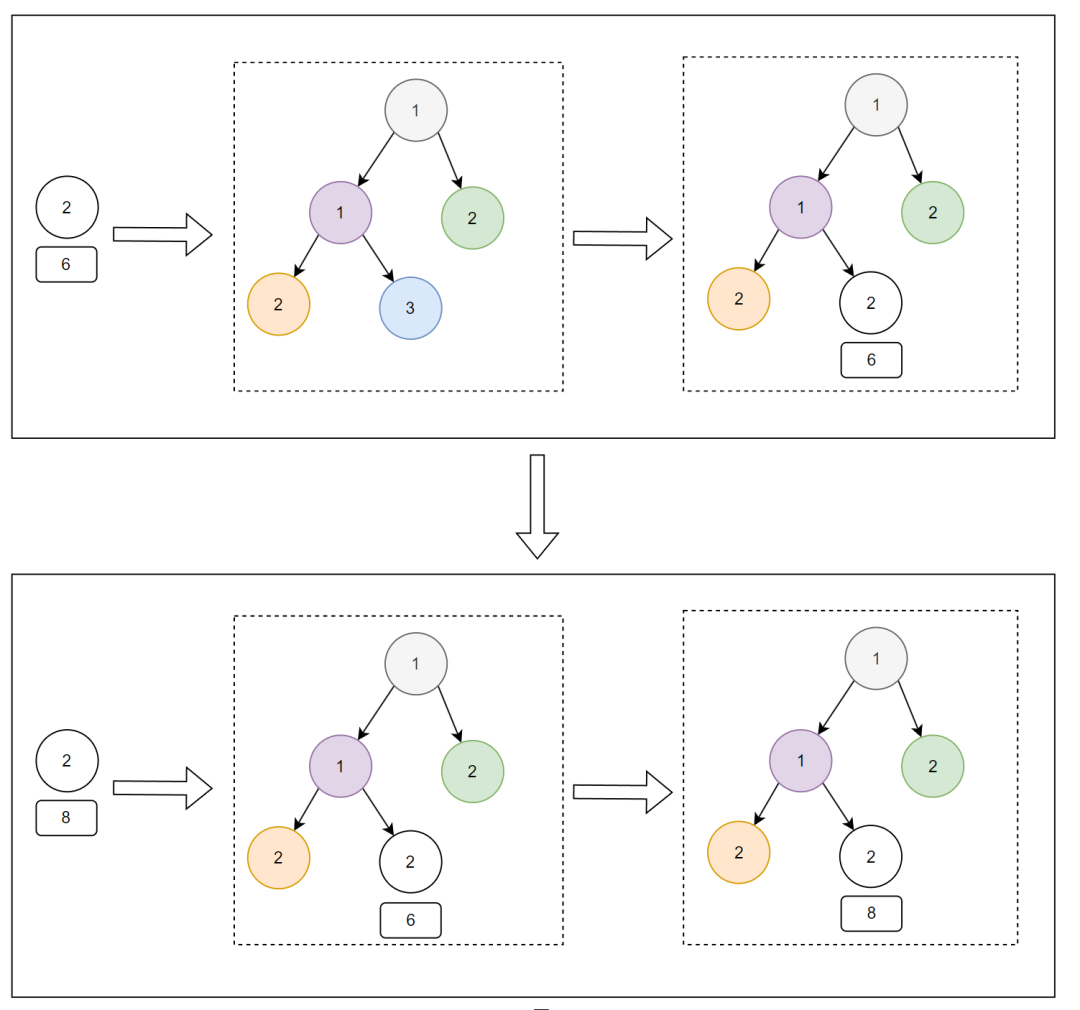
再来 id 为 9,category 为 2 的数据,小顶堆会变成这样:
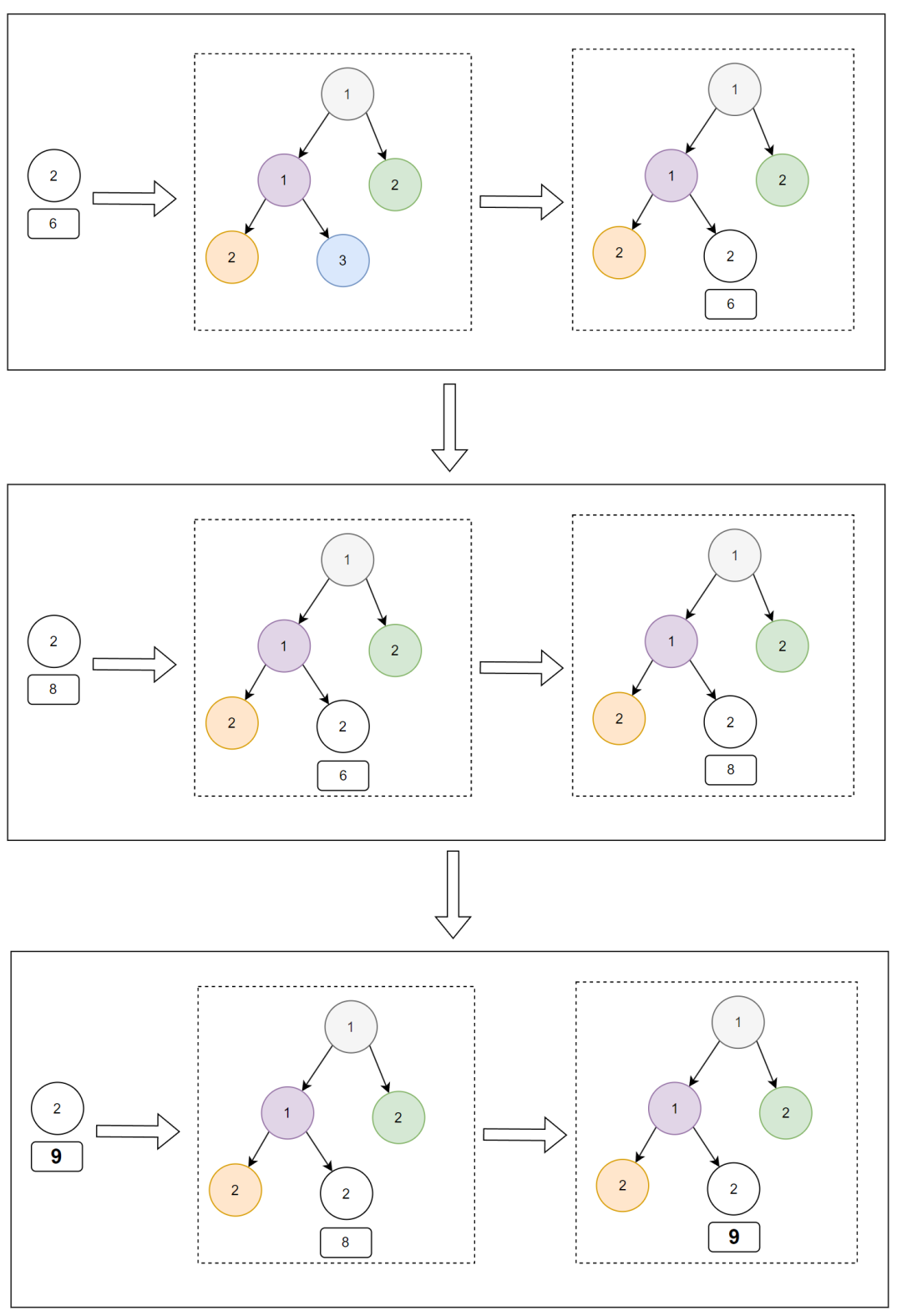
以此类推,最后一条处理完成之后,小顶堆里面的数据是这样的:
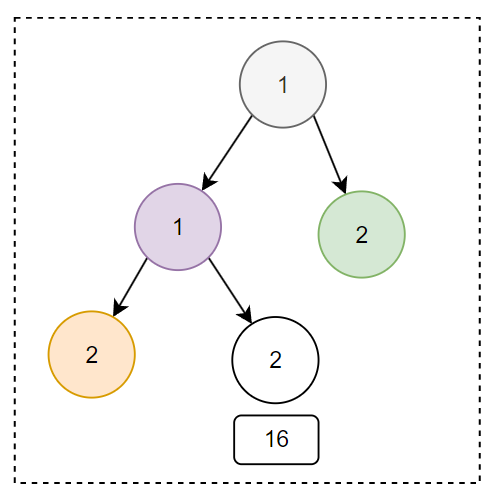
然后,我们将上述小顶堆,进行出堆操作。
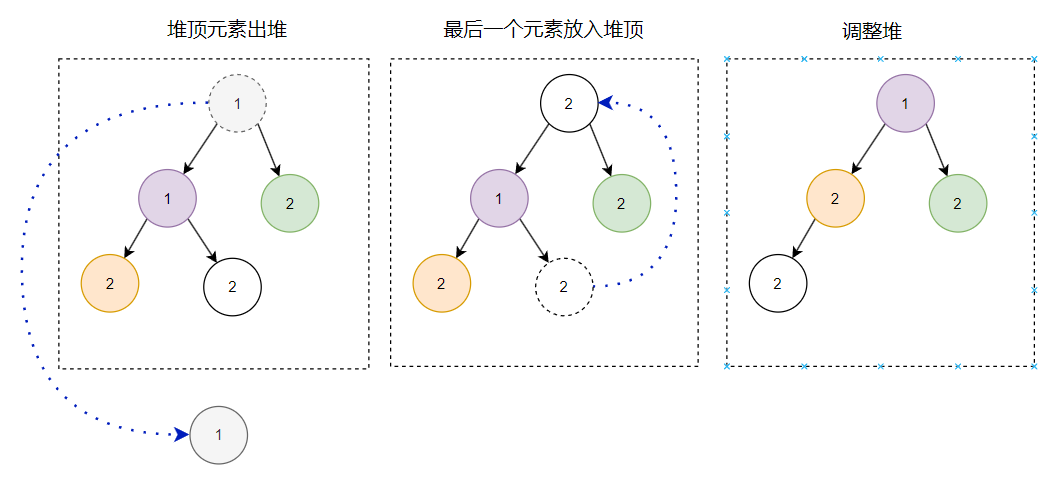
翻开八股文一看,哦,原来出堆无外乎就三个动作:
堆顶元素出堆
最后一个元素放入堆顶
调整堆
所以第一个出堆的节点是这样:
第二个出堆的节点是这样的:
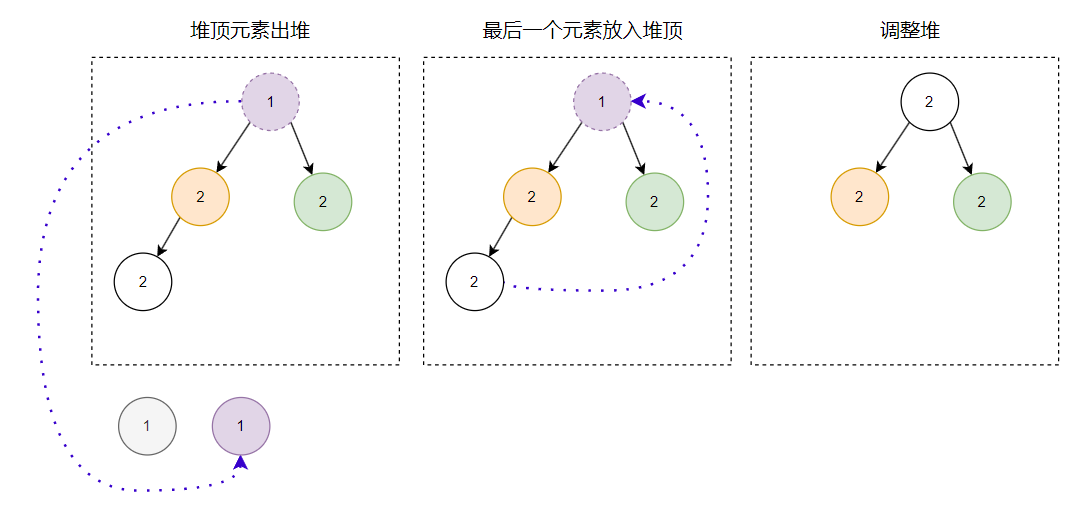
第三个出堆的节点是这样的:
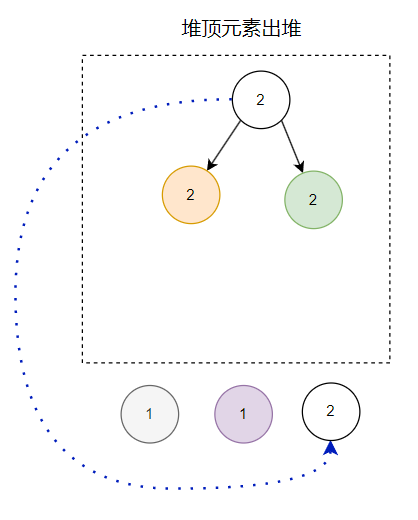
那么最终的出堆顺序就是这样的:

接下来,别忘了,我们的颜色是有含义的,代表的是 ID,我们在看看最开始的五条数据:
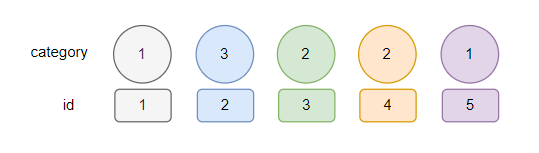
所以,我们按照颜色把出堆顺序补上 ID:
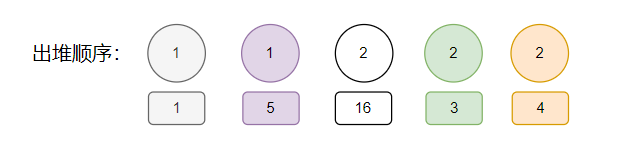
1,5,16,3,4。
朋友们,这串数字是否有点眼熟?
是否在午夜梦回的时候梦到过一段?
再给你看一个神奇的东西:
你看看这个 limit 5 取出来的 id 是什么?
1,5,16,3,4。
这玩意就这样呼应上了,掌声可以响起来了,今晚高低得用这串数字搞个彩票。
然后,再提醒一下,我们都知道堆排序是一个不稳定的排序算法。
它的不稳定体现在哪里?
翻开八股文一看,哦,原来是“位置变了”。
就拿我们的这个例子来说,排序之前,3 和 4 这两条数据在 16 之前:
排完序之后,16 这条数据跑到 3 前面去了。
虽然他们对应的 category 值都是 2,但是相对位置发生了变化,这就是不稳定的表现。
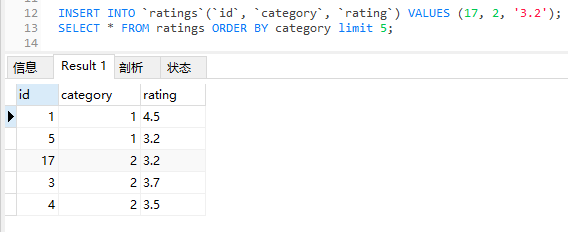
好了,现在我再问你一个问题,当我再插入一条数据:
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (17, 2, '3.2');
你说取前五条,运行结果是什么?
肯定是 1,5,17,3,4。
哪怕我插入个 10000,运行结果我也猜得出来,肯定是 1,5,10000,3,4。
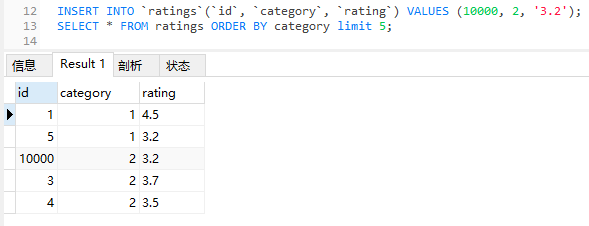
但是你说,我要是再插入个 10w 条 category=2 的数据呢?
这玩意我就没实验了,但是我猜,可能不会启用优先级队列,也就是不会走这一套逻辑。
为什么,你问为什么?
要不你再想想使用优先级队列的那几坨 if 判断?
最后
好了,写到这里文章也就进入尾声了,到了我拿手的上价值环节了。
你现在回过头想想,其实这篇文章真的没有教会你什么特别有价值的东西。如果让我来总结这篇文章,我只会取走文章开头的这个链接:
https://dev.mysql.com/doc/refman/8.0/en/limit-optimization.html
这是官方文档,当你打开这个链接之后,我不相信你不会被侧边栏中的 Optimization 这个单词给吸引住,然后仔细一看,这一章节下有这么多的 xxx Optimization,我不信你没有点开看一眼的欲望:
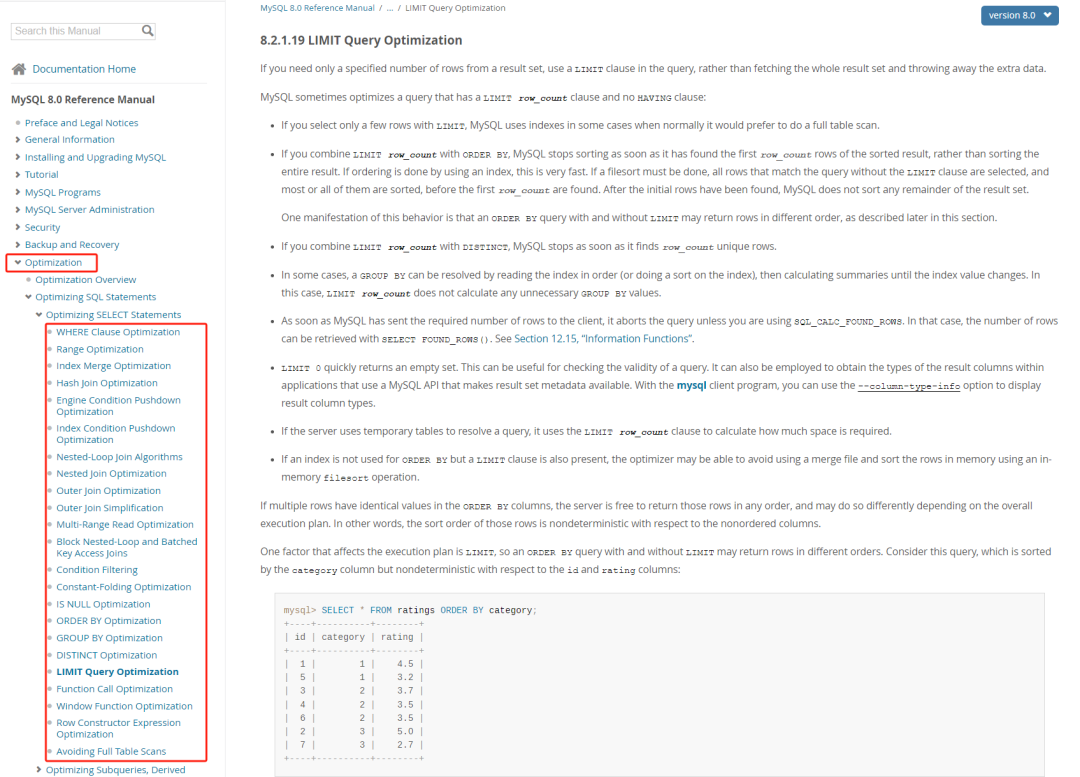
如果你没有这一眼欲望,你抵抗的一定不是技术,因为如果你抵抗技术,你根本就不会打开这个链接。
如果你没有这一眼欲望,说明你抵抗的是纯英文。但是我的朋友,要克服好吗。一点点啃,这才是一手资料的地方,而我不过是一个拙劣的倒卖一手资料的二手贩子而已。
你在看的过程中,除了英文的问题外,肯定有很多其他的问题。这个时候你带着问题去搜索答案,收获将会是巨大的。
这就是我们常常说的:从官方文档开始学。
我这篇文章的起点,就是官方文档,然后从文档发散,我看了很多其他的文章。
如果有一天你看官方文档的时候,看到 limit optimization 这一章节的时候,有看不懂的地方,然后带着问题在网上搜到了我这篇文章。
朋友,这是你的收获,是我的荣幸。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721