
本文结合一个实际故障案例出发,从小白的视角分析慢SQL是如何打垮数据库并引发故障的。
一、案发现场
上午9:49,应用报警:
4103.ERR_ATOM_CONNECTION_POOL_FULL,应用数据库连接池满。
上午9:49-10:08期间,陆续出现:4200.ERR_GROUP_NOT_AVALILABLE、4201.ERR_GROUP_NO_ATOM_AVAILABLE和4202.ERR_SQL_QUERY_TIMEOUT 等数据库异常报警。

由于数据库承载了销售核心的用户组织权限功能,故障期间,期间销售工作台无法打开,大量小二反馈咨询。
上午10:08,定位到有应用基础缓存包升级发布,上午9点40刚完成最后一批发布,时间点相吻合,尝试通过打开缓存开关,系统恢复。
二、现场结论
对此次升级缓存包应用发布内容分析,发现升级的某个二方包中,删除了本地缓存逻辑,直接请求DB,而本次升级没有对请求的SQL进行优化,如下代码所示,该SQL从Oracle迁移到MySQL,由于数据库性能的差异,最终造成慢查询,平均一次执行2S多,大量慢SQL最终打挂数据库。
SELECT CRM_USER_ID AS LOGIN_ID, CRM_ROLE_ID AS ROLE_NAME, CRM_ORG_ID AS ORG_ID, CONCAT(CRM_USER_ID, '#', CRM_ROLE_ID, '#', CRM_ORG_ID) AS URO, CONCAT(CRM_ORG_ID, '#', CRM_ROLE_ID) AS ORG_ID_ROLE_NAMEFROM CRM_USER_ROLE_ORGWHERE IS_DELETED = 'n'AND CONCAT(CRM_ORG_ID, '#', CRM_ROLE_ID) = '123#abc'ORDER BY ID DESC;
经过讨论排查分析,得出以下结论:
1、之前逻辑走本地内存,本次升级中由于涉及到的某个二方库代码变更删除了本地逻辑改查DB。
2、查询DB的SQL去O阶段没有进行优化,在MySQL下为慢SQL,大量慢SQL查询拖垮了数据库。
三、进一步的疑问
面对上述结论,作为数据库方面的小白,有以下几个疑问,感觉需要深入挖掘:
1、这条SQL为何是慢SQL;
2、发布的应用为非核心应用,只是与登录权限共用了一个数据库,当时发布应用的QPS只有0.几,为何可以把库打挂;
3、之前已经申请过一波连接池扩容,从10扩到了15,发布的应用线上有流量的机器不过7台,为何可以把数据库压垮;
4、事后复盘,发布前一天灰度时也有过慢SQL,为何当时没有压垮数据库。
四、深入分析原理
带着以上疑问,结合以下相关知识,一层层剥开深层次的原因。
CONCAT(CRM_ORG_ID, '#', CRM_ROLE_ID) = '123#abc' 该SQL由工具直接从Oracle翻译过来的
虽然两个拼接的字段各自都有索引,但是使用函数后,MySQL是不会使用索引的,退化为了普通查询。

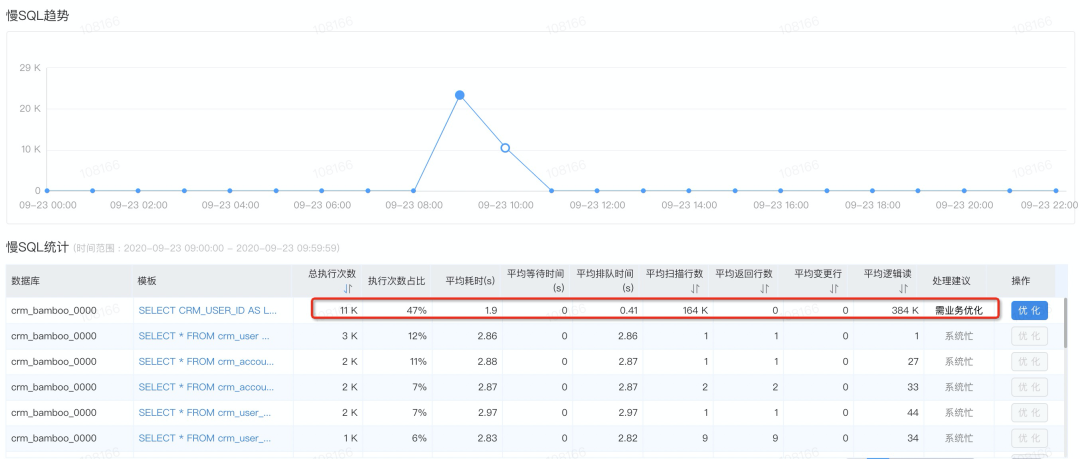
由于表数据量较大,全表40W+数据,导致扫描行数很多,平均扫描16W行、逻辑读38W行,执行2s左右。
故障后第二天,有个别销售反馈页面打开较慢,有好几秒,怀疑是止血时的操作是切到了tair而不是回滚到本地缓存逻辑导致,不过此时还是有疑问,为何一个页面会慢好几秒呢,听起来就像是一次请求大量循环调用缓存导致。
代理账号经定位,确实是如上假设,此处的业务代码逻辑为查找组织下的指定角色,会递归遍历所有子组织,最差情况下,一次页面请求,会有1000+次访问缓存/DB。
结合数据库当时慢SQL趋势,符合我们的猜测,虽然业务流量不大,但是每次请求会放大1000倍,最终导致问题SQL执行了1.5W+次,同时同下图可以看到,其他正常SQL由于系统忙被排队,响应也变慢,而这些基本都是基础用户组织权限相关,所以造成了业务系统不可用。
上文背景有提及,应用连接池配置的为15,切应用流量本身很小,那么是什么原因导致整个库都被拖垮呢?
这里要从一次SQL请求的链路说起,如下图所示:
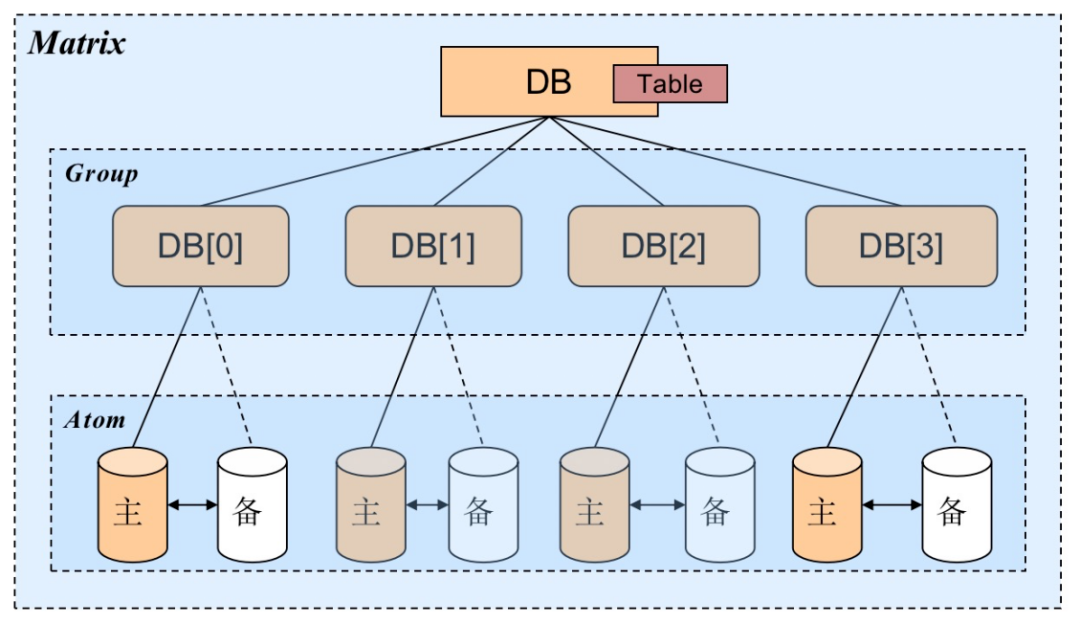
应用层通过tddl访问MySQL数据源,其中连接管理是在atom层,利用druid进行连接池的管理,我们平时所说的tddl线程池,指的就是druid连接池,这个配置维护在diamond中,一般有dba来设置。
对于我们的应用来说,单个应用7台机器,maxPoolSize配置为15,数据库是单库单表,则单个应用的最大连接数为1*15,所有应用连接数为7*1*15=105。
注意以上只是应用维度的连接数推导,正常工作下连接池也不会达到max的,如果达到了,TDDL会抛出4103.ERR_ATOM_CONNECTION_POOL_FULL,应用数据库连接池满错误,与第一节现象吻合。
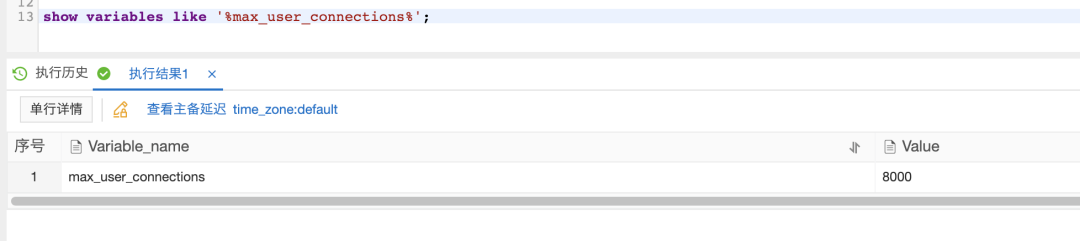
那么问题来了,这么几个连接,为何打垮整个数据库呢?看数据库的最大连接数可是有8000。
经与DBA同学咨询,了解到了数据库server端的内部处理线程池与druid没有任何关系,两者是两个层面的东西,所以需要研究下server端的处理逻辑。
同时这里提一点,由于我们很多应用都在连接数据库,所以需要评估下数据库的最大连接数是否可以满足这么多应用的机器的链接,即应用服务器总数 * 一个数据库实例上的分库数(atom) * maxPoolSize < max_user_connections。
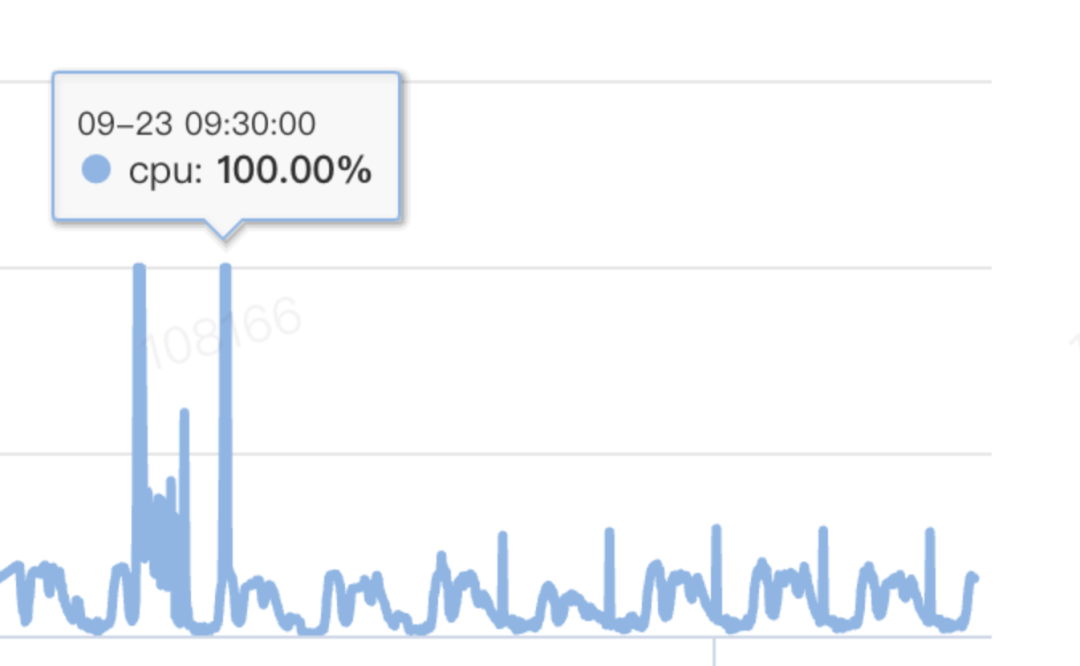
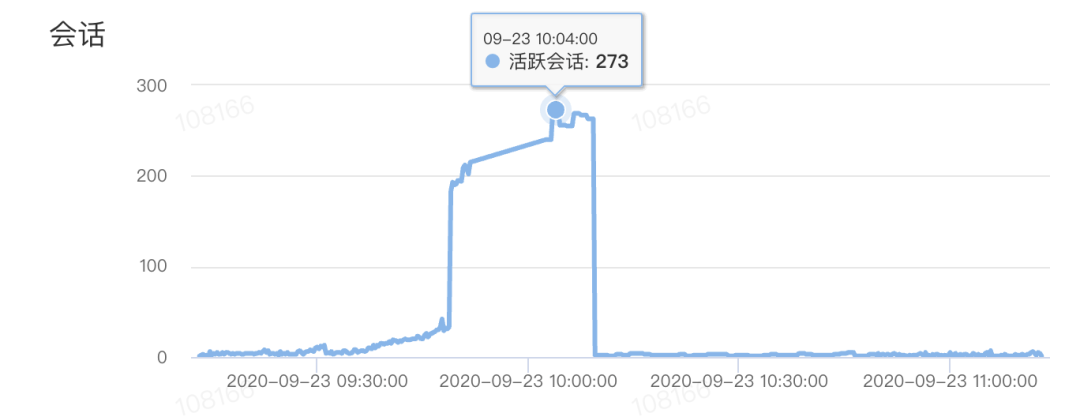
如上图所示,案发时,有一个明显的现象,数据库CPU被打满,同时活跃连接数增长、数据库rt增长:
活跃连接数,即当前数据库中有多少会话正在执行SQL,是衡量数据库繁忙程度的指标。
根据执行时间来判断,阈值一般很低,正常情况下一条SQL执行很快,活跃会话很低。
经过与DBA同学请教,结合慢SQL明细,确定问题就是慢SQL执行,大量逻辑读导致的。
server端的链路还原如下:
针对数据库实例,出于保护,引入了线程池,通过参数进行控制,默认300个左右;
正常情况下,由于SQL执行很快,活跃会话不会很高;
慢SQL情况下,由于每一条慢SQL都会逻辑读30W+行,执行2s+,导致线程变慢,线程池里的线程被用尽,也即活跃会话数上升,如上图所示,逼近280;
数据库CPU都在执行慢SQL的逻辑读和排序等操作、活跃会话数大幅增长,数据库rt飙升,导致其他应用请求无法与数据库建立新的会话,应用请求超时,TDDL层进入fast fail状态,抛出4201.ERR_GROUP_NO_ATOM_AVAILABLE异常。
上面分析中,有一个核心的细节,就是慢SQL逻辑读太多,最终导致CPU打满了,这里有个疑问,读写不是io操作吗,为什么会使CPU load高呢,研究了一下innodb的结构:
如下图所示,在innodb存储层,维护了一个缓存数据和索引信息到内存的存储区叫做buffer pool,他会将最近访问的数据缓存到缓冲区。
我们说的逻辑读,也就是SQL在同一时间内需要访问多少个缓冲区的内存页;而与之相对应的,物理读则是同一时间内需要从磁盘获取多少个数据块。
理想情况下,buffer pool size应该设置的尽可能大,这样就可以减少进程的额外分页,当buffer pool size设置的足够大的时候,整个数据库就相当于存储在内存当中,当读取一次数据到buffer pool size以后,后续的读操作就不用在进行磁盘读。

通过现场的cloud dba监控也可以发现,innoDB缓存命中率为100%,不存在物理读的情况,也即可以认为数据库的高频数据都已全量存在于内存中了。
通过查看数据库容量也可以佐证这个观点,数据+索引大小6G左右,未达到数据库实例配置的8G,所以实际情况是数据都存在于内存中了,并不会有多余的IO操作,CPU的性能全部都消耗在了大量的内存数据扫表(逻辑读)中——看现场平均扫描16w行数据。
这个结论让我不禁想到了一个类似的场景,在线上vi打开服务器中大文件导致load飙高,应用不可用的问题。vi在将文件原样加载到内存后,还会将其转换为内部结构(线条,单词等),使用内部脚本语言执行语法高亮显示等等,所有这些都会消耗内存和CPU时间。

虽然慢SQL模板只一个,QPS也不是特别高(现场峰值100左右,平均20左右),但是由于线程池机制,快速将活跃会话(线程池)占满。
由于业务QPS水位在3000左右,线程池打满后,后续即使是索引甚至是主键查询的正常SQL,也都在排队了,最终导致了雪崩效应。
在优化慢SQL的同时,考虑到数据库实例配置较低(8core 8G 100G),也尝试与DBA相关同学沟通升级配置,经过多次讨论,结论为升配无用,只能优化慢SQL或者加缓存,以下配置核心的三个维度进行说明:
CPU:目前实例配置为8核,但是MySQL集群的CPU隔离是放开的,最高可用到物理机的64核,所以无需升配。
内存:目前实例配置为8G,内存这块直接影响的就是上述介绍的buffer pool,如4.5小结分析,库总数据量都没有达到8G,所以无需进行内存升级。
磁盘:目前实例配置为100G,以目前业务发展速度也已够用。
五、总结
1、直接原因:应用升级二方库中本地缓存代码被删除;慢SQL没有优化;同时业务逻辑复杂,嵌套循环导致快速雪崩;
2、根本原因:慢SQL导致数据库CPU打满,活跃连接数突增,rt上升,后续SQL请求都在排队,高QPS场景下,最终导致雪崩效应,TDDL fast fail,抛出数据库不可用异常;
3、两个池的知识点:TDDL中的druid插件维护的是业务应用层与数据库连接的连接池;MySQL服务端 也会通过线程池技术,处理会话,默认300左右,一般情况下SQL执行非常快,所以活跃线程/活跃会话非常低;
4、快速定位数据库问题的思路 -- 熟练掌握cloud dba的性能分析工具:
判断数据库是否正常:RT - 响应时间是否变大了;活跃会话 ——数据库当前是否拥堵了;
QPS:是否有突发大流量;
检查执行的SQL:如果逻辑读、DML大幅增长,则基本可以锁定该SQL出了问题。
参考资料
《关于MySQL线程池,这也许是目前最全面的实用帖!》
http://dbaplus.cn/news-11-1989-1.html
《当我有16 GB RAM时,为什么Vim无法打开100 MB文本文件?》
http://qastack.cn/unix/139254/why-cant-vim-open-a-100-mb-text-file-when-i-have-16-gb-ram








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721