
陈臣,甲骨文MySQL首席解决方案工程师,公众号《MySQL实战》作者,有大规模的MySQL,Redis,MongoDB,ES的管理和维护经验,擅长MySQL数据库的性能优化及日常操作的原理剖析。
归档,在MySQL中,是一个相对高频的操作。
它通常涉及以下两个动作:
迁移:将数据从业务实例迁移到归档实例。
删除:从业务实例中删除已迁移的数据。
在处理类似需求时,都是开发童鞋提单给DBA,由DBA来处理。
于是,很多开发童鞋就好奇,DBA都是怎么执行归档操作的?归档条件没有索引会锁表吗?安全吗,会不会数据删了,却又没归档成功?
针对这些疑问,下面介绍MySQL中的数据归档神器——pt-archiver。
一、什么是 pt-archiver
pt-archiver是Percona Toolkit中的一个工具。
Percona Toolkit是Percona公司提供的一个MySQL工具包。
工具包里提供了很多实用的MySQL管理工具。
譬如,我们常用的表结构变更工具pt-online-schema-change,主从数据一致性校验工具pt-table-checksum。
毫不夸张地说,熟练使用Percona Toolkit是MySQL DBA必备的技能之一。
二、安装
Percona Toolkit下载地址:https://www.percona.com/downloads/percona-toolkit/LATEST/
官方针对多个系统提供了现成的软件包。
我常用的是Linux - Generic二进制包。
下面以Linux - Generic版本为例,看看它的安装方法。
cd /usr/local/wget https://downloads.percona.com/downloads/percona-toolkit/3.3.1/binary/tarball/percona-toolkit-3.3.1_x86_64.tar.gz --no-check-certificatetar xvf percona-toolkit-3.3.1_x86_64.tar.gzcd percona-toolkit-3.3.1yum install perl-ExtUtils-MakeMaker perl-DBD-MySQL perl-Digest-MD5perl Makefile.PLmakemake install
三、简单入门
首先,我们看一个简单的归档Demo。
测试数据
mysql> show create table employees.departments\G*************************** 1. row ***************************Table: departmentsCreate Table: CREATE TABLE `departments` (`dept_no` char(4) NOT NULL,`dept_name` varchar(40) NOT NULL,PRIMARY KEY (`dept_no`),UNIQUE KEY `dept_name` (`dept_name`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci1 row in set (0.00 sec)mysql> select * from employees.departments;+---------+--------------------+| dept_no | dept_name |+---------+--------------------+| d009 | Customer Service || d005 | Development || d002 | Finance || d003 | Human Resources || d001 | Marketing || d004 | Production || d006 | Quality Management || d008 | Research || d007 | Sales |+---------+--------------------+9 rows in set (0.00 sec)
下面,我们将employees.departments表的数据从192.168.244.10归档到192.168.244.128。
具体命令如下:
pt-archiver --source h=192.168.244.10,P=3306,u=pt_user,p=pt_pass,D=employees,t=departments --dest h=192.168.244.128,P=3306,u=pt_user,p=pt_pass,D=employees,t=departments --where "1=1"
命令行中指定了三个参数。
--source:源库(业务实例)的DSN。
DSN在Percona Toolkit中比较常见,可理解为目标实例相关信息的缩写。
支持的缩写及含义如下:

--dest:目标库(归档实例)的DSN。
--where:归档条件。"1=1"代表归档全表。
四、实现原理
下面结合General log的输出看看pt-archiver的实现原理。
源库日志
2022-03-06T10:58:20.612857+08:00 10 Query SELECT /*!40001 SQL_NO_CACHE */ `dept_no`,`dept_name` FROM `employees`.`departments` FORCE INDEX(`PRIMARY`) WHERE (1=1) ORDER BY `dept_no` LIMIT 12022-03-06T10:58:20.613451+08:00 10 Query DELETE FROM `employees`.`departments` WHERE (`dept_no` = 'd001')2022-03-06T10:58:20.620327+08:00 10 Query commit2022-03-06T10:58:20.628409+08:00 10 Query SELECT /*!40001 SQL_NO_CACHE */ `dept_no`,`dept_name` FROM `employees`.`departments` FORCE INDEX(`PRIMARY`) WHERE (1=1) AND ((`dept_no` >= 'd001')) ORDER BY `dept_no` LIMIT 12022-03-06T10:58:20.629279+08:00 10 Query DELETE FROM `employees`.`departments` WHERE (`dept_no` = 'd002')2022-03-06T10:58:20.636154+08:00 10 Query commit...
目标库日志
2022-03-06T10:58:20.613144+08:00 18 Query INSERT INTO `employees`.`departments`(`dept_no`,`dept_name`) VALUES ('d001','Marketing')2022-03-06T10:58:20.613813+08:00 18 Query commit2022-03-06T10:58:20.628843+08:00 18 Query INSERT INTO `employees`.`departments`(`dept_no`,`dept_name`) VALUES ('d002','Finance')2022-03-06T10:58:20.629784+08:00 18 Query commit...
结合源库和目标库的日志,可以看到:
1)pt-archiver首先会从源库查询一条记录,然后再将该记录插入到目标库中。
目标库插入成功,才会从源库中删除这条记录。
这样就能确保数据在删除之前,一定是归档成功的。
2)仔细观察这几个操作的执行时间,其先后顺序如下。
源库查询记录。
目标库插入记录。
源库删除记录。
目标库COMMIT。
源库COMMIT。
这种实现借鉴了分布式事务中的两阶段提交算法。
3)--where参数中的 "1=1" 会传递到SELECT操作中。
"1=1" 代表归档全表,也可指定其它条件,如我们常用的时间。
4)每次查询都是使用主键索引,这样即使归档条件中没有索引,也不会产生全表扫描。
5)每次删除都是基于主键,这样可避免归档条件没有索引导致全表被锁的风险。
五、批量归档
如果使用Demo中的参数进行归档,在数据量比较大的情况下,效率会非常低,毕竟COMMIT是一个昂贵的操作。
所以在线上,我们通常都会进行批量操作。
具体命令如下:
pt-archiver --source h=192.168.244.10,P=3306,u=pt_user,p=pt_pass,D=employees,t=departments --dest h=192.168.244.128,P=3306,u=pt_user,p=pt_pass,D=employees,t=departments --where "1=1" --bulk-delete --limit 1000 --commit-each --bulk-insert
相对于之前的归档命令,这条命令额外指定了四个参数,其中,
--bulk-delete:批量删除。
--limit:每批归档的记录数。
--commit-each:对于每一批记录,只会 COMMIT 一次。
--bulk-insert:归档数据以 LOAD DATA INFILE 的方式导入到归档库中。
看看上述命令对应的General log。
源库
2022-03-06T12:13:56.117984+08:00 53 Query SELECT /*!40001 SQL_NO_CACHE */ `dept_no`,`dept_name` FROM `employees`.`departments` FORCE INDEX(`PRIMARY`) WHERE (1=1) ORDER BY `dept_no` LIMIT 1000...2022-03-06T12:13:56.125129+08:00 53 Query DELETE FROM `employees`.`departments` WHERE (((`dept_no` >= 'd001'))) AND (((`dept_no` <= 'd009'))) AND (1=1) LIMIT 10002022-03-06T12:13:56.130055+08:00 53 Query commit
目标库
2022-03-06T12:13:56.124596+08:00 51 Query LOAD DATA LOCAL INFILE '/tmp/hitKctpQTipt-archiver' INTO TABLE `employees`.`departments`(`dept_no`,`dept_name`)2022-03-06T12:13:56.125616+08:00 51 Query commit:
注意:
1)如果要执行LOAD DATA LOCAL INFILE操作,需将目标库的local_infile参数设置为ON。
2)如果不指定--bulk-insert且没指定--commit-each,则目标库的插入还是会像Demo中显示的那样,逐行提交。
3)如果不指定--commit-each,即使表中的9条记录是通过一条DELETE命令删除的,但因为涉及了9条记录,pt-archiver会执行COMMIT操作9次。目标库同样如此。
4)在使用--bulk-insert归档时要注意,如果导入的过程中出现问题,譬如主键冲突,pt-archiver是不会提示任何错误的。
六、不同归档参数之间的速度对比
下表是归档20w数据,不同参数之间的执行时间对比。
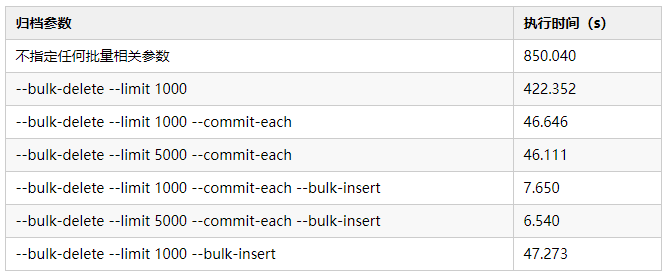
通过表格中的数据,我们可以得出以下几点:
1)第一种方式是最慢的。
这种情况下,无论是源库还是归档库,都是逐行操作并提交的。
2)只指定--bulk-delete --limit 1000依然很慢。
这种情况下,源库是批量删除,但COMMIT次数并没有减少。
归档库依然是逐行插入并提交的。
3)--bulk-delete --limit 1000 --commit-each
相当于第二种归档方式,源库和目标库都是批量提交的。
4)--limit 1000 和 --limit 5000归档性能相差不大。
5)--bulk-delete --limit 1000 --bulk-insert与--bulk-delete --limit 1000 --commit-each --bulk-insert相比,没有设置--commit-each。
虽然都是批量操作,但前者会执行COMMIT操作1000次。
由此来看,空事务并不是没有代价的。
七、其它常见用法
删除数据是pt-archiver另外一个常见的使用场景。
具体命令如下:
pt-archiver --source h=192.168.244.10,P=3306,u=pt_user,p=pt_pass,D=employees,t=departments --where "1=1" --bulk-delete --limit 1000 --commit-each --purge --primary-key-only
命令行中的 --purge 代表只删除,不归档。
指定了 --primary-key-only ,这样,在执行 SELECT 操作时,就只会查询主键,不会查询所有列。
接下来,我们看看删除命令相关的General log。
为了直观地展示pt-archiver删除数据的实现逻辑,实际测试时将--limit设置为了 3。
# 开启事务set autocommit=0;# 查看表结构,获取主键SHOW CREATE TABLE `employees`.`departments`;# 开始删除第一批数据# 通过 FORCE INDEX(`PRIMARY`) 强制使用主键# 指定了 --primary-key-only,所以只会查询主键# 这里其实无需获取所有满足条件的主键值,只取一个最小值和最大值即可。SELECT /*!40001 SQL_NO_CACHE */ `dept_no` FROM `employees`.`departments` FORCE INDEX(`PRIMARY`) WHERE (1=1) ORDER BY `dept_no` LIMIT 3;# 基于主键进行删除,删除的时候同时带上了 --where 指定的删除条件,以避免误删DELETE FROM `employees`.`departments` WHERE (((`dept_no` >= 'd001'))) AND (((`dept_no` <= 'd003'))) AND (1=1) LIMIT 3;# 提交commit;# 删除第二批数据SELECT /*!40001 SQL_NO_CACHE */ `dept_no` FROM `employees`.`departments` FORCE INDEX(`PRIMARY`) WHERE (1=1) AND ((`dept_no` >= 'd003')) ORDER BY `dept_no` LIMIT 3;DELETE FROM `employees`.`departments` WHERE (((`dept_no` >= 'd004'))) AND (((`dept_no` <= 'd006'))) AND (1=1); LIMIT 3commit;# 删除第三批数据SELECT /*!40001 SQL_NO_CACHE */ `dept_no` FROM `employees`.`departments` FORCE INDEX(`PRIMARY`) WHERE (1=1) AND ((`dept_no` >= 'd006')) ORDER BY `dept_no` LIMIT 3;DELETE FROM `employees`.`departments` WHERE (((`dept_no` >= 'd007'))) AND (((`dept_no` <= 'd009'))) AND (1=1) LIMIT 3;commit;# 删除最后一批数据SELECT /*!40001 SQL_NO_CACHE */ `dept_no` FROM `employees`.`departments` FORCE INDEX(`PRIMARY`) WHERE (1=1) AND ((`dept_no` >= 'd009')) ORDER BY `dept_no` LIMIT 3;commit;
在业务代码中,如果我们有类似的删除需求,不妨借鉴下pt-archiver的实现方式。
数据除了能归档到数据库,也可归档到文件中。
具体命令如下:
pt-archiver --source h=192.168.244.10,P=3306,u=pt_user,p=pt_pass,D=employees,t=departments --where "1=1" --bulk-delete --limit 1000 --file '/tmp/%Y-%m-%d-%D.%t'
指定的是--file ,而不是--dest。
文件名使用了日期格式化符号,支持的符号及含义如下:
d Day of the month, numeric (01..31)H Hour (00..23)i Minutes, numeric (00..59)m Month, numeric (01..12)s Seconds (00..59)Y Year, numeric, four digitsD Database namet Table name
生成的文件是CSV格式,后续可通过LOAD DATA INFILE命令加载到数据库中。
八、如何避免主从延迟
无论是数据归档还是删除,对于源库,都需要执行DELETE操作。
很多人担心,如果删除的记录数太多,会造成主从延迟。
事实上,pt-archiver本身就具备了基于主从延迟来自动调节归档(删除)操作的能力。
如果从库的延迟超过1s(由 --max-lag 指定)或复制状态不正常,则会暂停归档(删除)操作,直到从库恢复。
默认情况下,pt-archiver不会检查从库的延迟情况。
如果要检查,需通过--check-slave-lag显式设置从库的地址,譬如,
pt-archiver --source h=192.168.244.10,P=3306,u=pt_user,p=pt_pass,D=employees,t=departments --where "1=1" --bulk-delete --limit 1000 --commit-each --primary-key-only --purge --check-slave-lag h=192.168.244.20,P=3306,u=pt_user,p=pt_pass
这里只会检查192.168.244.20的延迟情况。
如果有多个从库需要检查,需将--check-slave-lag指定多次,每次对应一个从库。
九、常用参数
--analyze
在执行完归档操作后,执行ANALYZE TABLE操作。
后面可接任意字符串,如果字符串中含有 s ,则会在源库执行 ANALYZE 操作。
如果字符串中含有 d ,则会在目标库执行ANALYZE操作。
如果同时带有 d 和 s ,则源库和目标库都会执行ANALYZE操作。如,
--analyze ds
--optimize
在执行完归档操作后,执行OPTIMIZE TABLE操作。
用法同 --analyze 类似。
--charset
指定连接(Connection)字符集。
在 MySQL 8.0之前,默认是latin1。
在 MySQL 8.0中,默认是utf8mb4 。
注意,这里的默认值与MySQL服务端字符集character_set_server无关。
若显式设置了该值,pt-archiver在建立连接后,会首先执行SET NAMES 'charset_name'操作。
--[no]check-charset
检查源库(目标库)连接(Connection)字符集和表的字符集是否一致。
如果不一致,会提示以下错误:
Character set mismatch: --source DSN uses latin1, table uses gbk. You can disable this check by specifying --no-check-charset.
这个时候,切记不要按照提示指定 --no-check-charset 忽略检查,否则很容易导致乱码。
针对上述报错,可将--charset指定为表的字符集。
注意,该选项并不是比较源库和目标库的字符集是否一致。
--[no]check-columns
检查源表和目标表列名是否一致。
注意,只会检查列名,不会检查列的顺序、列的数据类型是否一致。
--columns
归档指定列。
在有自增列的情况下,如果源表和目标表的自增列存在交集,可不归档自增列,这个时候,就需要使用--columns显式指定归档列。
--dry-run
只打印待执行的SQL,不实际执行。
常用于实际操作之前,校验待执行的SQL是否符合自己的预期。
--ignore
使用INSERT IGNORE归档数据。
--no-delete
不删除源库的数据。
--replace
使用REPLACE操作归档数据。
--[no]safe-auto-increment
在归档有自增主键的表时,默认不会删除自增主键最大的那一行。
这样做,主要是为了规避MySQL 8.0之前自增主键不能持久化的问题。
在对全表进行归档时,这一点需要注意。
如果需要删除,需指定--no-safe-auto-increment。
--source
给出源端实例的信息。
除了常用的选项,其还支持如下选项:
a:指定连接的默认数据库。
b:设置 SQL_LOG_BIN=0 。
如果是在源库指定,则DELETE操作不会写入到Binlog中。
如果是在目标库指定,则INSERT操作不会写入到Binlog中。
i:设置归档操作使用的索引,默认是主键。
--progress
显示进度信息,单位行数。
如 --progress 10000,则每归档(删除)10000行,就打印一次进度信息。
TIME ELAPSED COUNT2022-03-06T18:24:19 0 02022-03-06T18:24:20 0 100002022-03-06T18:24:21 1 20000
第一列是当前时间,第二列是已经消耗的时间,第三列是已归档(删除)的行数。
十、总结
前面,我们对比了归档操作中不同参数的执行时间。
其中,--bulk-delete --limit 1000 --commit-each --bulk-insert是最快的。不指定任何批量操作参数是最慢的。
但在使用--bulk-insert时要注意 ,如果导入的过程中出现问题,pt-archiver是不会提示任何错误的。
常见的错误有主键冲突,数据和目标列的数据类型不一致。
如果不使用--bulk-insert,而是通过默认的INSERT操作来归档,大部分错误是可以识别出来的。
譬如,主键冲突,会提示以下错误。
DBD::mysql::st execute failed: Duplicate entry 'd001' for key 'PRIMARY' [for Statement "INSERT INTO `employees`.`departments`(`dept_no`,`dept_name`) VALUES (?,?)" with ParamValues: 0='d001', 1='Marketing'] at /usr/local/bin/pt-archiver line 6772.
导入的数据和目标列的数据类型不一致,会提示以下错误。
DBD::mysql::st execute failed: Incorrect integer value: 'Marketing' for column 'dept_name' at row 1 [for Statement "INSERT INTO `employees`.`departments`(`dept_no`,`dept_name`) VALUES (?,?)" with ParamValues: 0='d001', 1='Marketing'] at /usr/local/bin/pt-archiver line 6772.
当然,数据和类型不一致,能被识别出来的前提是归档实例的SQL_MODE为严格模式。
如果待归档的实例中有MySQL 5.6,我们其实很难将归档实例的SQL_MODE开启为严格模式。
因为MySQL 5.6的SQL_MODE默认为非严格模式,所以难免会产生很多无效数据,譬如时间字段中的0000-00-00 00:00:00 。
这种无效数据,如果插入到开启了严格模式的归档实例中,会直接报错。
从数据安全的角度出发,最推荐的归档方式是:
1)先归档,但不删除源库的数据。
2)比对源库和归档库的数据是否一致。
3)如果比对结果一致,再删除源库的归档数据。
其中,第一步和第三步可通过pt-archiver搞定,第二步可通过pt-table-sync搞定。
相对于边归档边删除的这种方式,虽然麻烦不少,但相对来说,更安全。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721