
一、感谢GitHub兄弟趟坑
2012年9月,GitHub官网发生用户私有数据泄露事故。
事故的原因是MySQL集群的数据库主节点写压力过大,导致心跳检查失败,这时某个未完全同步的从节点被自动提升为主节点。
在当时的数据设计中,开发人员使用了auto_increment自增计数器作为表的自增主键。新的主节点的计数器落后于原主节点(主从复制使用了异步方式,两者并非完全同步),它重新使用了某些已经被原主节点分配出去的主键。
然而,不幸的是,这些主键恰好已经被外部的redis系统引用了,结果出现了MySQL与Redis之间的数据不一致,最终某些私有数据被错误地泄露给了其它用户。
二、对自增主键的朴素期待
啥是自增主键?以下是MySQL的一个例子:
create table ‘test’ (‘id’ int(16) NOT NULL AUTO_INCREMENT,‘name’ char(10) DEFAULT NULL,PRIMARY KEY(‘id’)) ENGINE = InnoDB;
自增主键给开发人员提供了很大的便利。由于MySQL存储引擎的特性,主键唯一且自增是普遍的设计要求。如果数据库没有内置这个特性,应用开发人员就必须自己设计一套主键生成逻辑,而数据库原生提供的自增主键免去了这些工作量,这是非常好的事情。
而且,自增主键似乎还能满足开发人员更多的期待,比如:
唯一性:必要特性,否则就没法做主键了。
单调递增:后插入记录的自增主键值一定比先插入记录的值要大。
连续递增:自增主键每次加1 。
大家之所以有这些期待,是因为这些特征非常符合原子计数器的人设(对比java中的AtomicInteger,golang听atomic包),同时原子计数器非常高效,因此看起来也非常适合完成这个任务。然而,现实总想着时不时的给我们上一课:
首先是单调递增:从auto_increment计数器取到值,到写入到redo日志,这个过程中间没有原子性保证,并且是多线程操作。因此,即使取的过程中是单调递增的,落盘之后也不见得是。
其次是连续递增:自增主键每次加1本来也没啥,但是数据库事务是有可能失败的,你不能指望一个事务回滚的时候还把自增主键也回滚吧?
因此,这样盘算下来,只有唯一性是可以保证的,其它两点都只是一厢情愿的幻觉。
既然是幻觉,也就没什么好坚持的了。
三、如何避免主从切换时丢失数据?
在刚刚GitHub的事故分析中,之所以主从切换时会丢失数据,是因为集群把一个未能与主节点完全同步的从节点选举出来作为新的主节点。这真是一件遗憾的事情。为了避免同样的问题,我们需要至少有一个时刻与主节点保持数据同步的从节点,为了达到这个目标,通常会将集群配置成半同步复制模式:集群的所有从节点中,有一个从节点是同步复制模式,其它的从节点是异步复制模式。
不应该将所有的从节点都配置成同步复制模式,否则MySQL每次写数据必须等待所有从节点确认后才能返回,这会极大影响整个集群的响应时间。同时,如果其中某个从节点crash掉了,还会导致整个集群不可用。
相比之下,Kafka的ISR机制要可靠的多:如果从节点迅速确认返回了,应该保持同步;如果从节点超时未返回,就将它踢出ISR变成异步。
这样就能保证万无一失了嘛?等等,有坑:MySQL的REPLACE操作会导致主从节点的AUTO_INCREMENT值不一致,这个bug直到MySQL 8.0才修复。以我司到目前还在广泛使用MySQL 5.6现状来看,万一主从切换了,这是分分钟又掉入到GitHub坑里的节奏。要避免这个,就得禁止使用replace语句。
等等,这可不是唯一的坑:一些复杂的SQL语句,会在insert自带select,如果配置了binlog_format=statement,同样的SQL语句在主节点与从节点上选择的索引可能是不一样的,这可能会导致主从数据插入的顺序不一样。要避免这个,就得配置binlog_format=row。
你不能指望所有的业务研发和运维都配合你,对吧?
四、分布式id生成算法是一个更好选择吗?
市面上有很多分布式id生成算法,比如twitter的snowflake算法,变种的sonyflake算法等。它们通过将int64进行分段拆分,把时间戳和机器id揉和进一个int64中,从而做到集群中的不同机器在相互无感知的前提下生成(大概率)全局唯一的id。
以snowflake算法为例:

这个算法生成的 ID 是一个 64 位的长整型,由四个部分构成:
第一部分是 1 位的符号位,并没有实际用处,主要为了兼容长整型的格式。
第二部分是 41 位的时间戳用来记录本地的毫秒时间。
第三部分是机器 ID,这里说的机器就是生成 ID 的节点,用 10 位长度给机器做编码,那意味着最大规模可以达到 1024 个节点(2^10)。
最后是 12 位序列,序列的长度直接决定了一个节点 1 毫秒能够产生的 ID 数量,12 位就是 4096(2^12)。
这样,根据数据结构推算,snowflake算法支持的 TPS 可以达到 419 万左右(2^22*1000),相信对于绝大多数系统来说足够了。
但实现snowflake算法时,有个小问题往往被忽略,那就是要注意时钟回拨带来的影响。机器时钟如果出现回拨,产生的 ID 就有可能重复,这需要在算法中特殊处理一下。
又见时钟漂移,真是阴魂不散,NPC相关问题更多细节可参考《13.看似忠良的分布式锁》
MongoDB的ObjectID实现机制与snowflake算法类似,它占用12个字节:
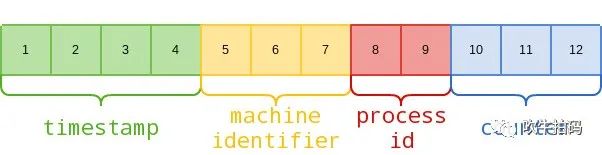
如果当年GitHub使用分布式id作为MySQL主键,在发生主从切换后,新主节点与原主节点生成的id几乎不可能相同,也就不会发生用户私有数据泄露事故了。
那万一极小概率下(自增段用完+时钟加拨+机器id相同),产生重复id呢?是否会导致数据库主键重复呢?答案是不会,数据库主键具体唯一性,如果人工插入重复的主键,根据编程语言不同,代码会抛出异常或返回error。处理数据库操作异常,是所有数据库操作代码的基操之一。
这样看起来,分布式id生成算法在分布式集群中还真有可能是一个更好的选择。
五、动手之前
如果你像我一样只是一个普通程序员,那么auto_increment是一个可用的选择;如果你想做一个靠谱的架构师,了解一下分布式id之类的东西还是有必要的。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721