
前言
目前,出于对数据库产品高安全和高可用的要求,银行业在现有核心业务系统中选用的一般为国际大型厂商的成熟产品,如IBM的DB2、甲骨文的Oracle、微软的SQL Server等。但随着业务的不断发展,银行业对数据库产品的需求已经逐渐多样化:一方面要能满足业务系统的基本需求,另一方面对于数据安全、自主掌控的要求也越来越高。鉴于此,不少银行业已经开始了自己的转型尝试,并取得了一定的成果。
MySQL作为当前最热门的开源数据库,已被互联网公司广泛应用。基于对数据库安全可控的考虑,银行业也正在进行较大规模的推广,用于替代传统数据库产品。
我行在替换和使用、改造的过程中遇到了不少问题,下面总结了最常被开发、运维问到的问题,我们做了最精简的解答,希望对大家能有所帮助。
一、为什么首选MySQL数据库作为替换Oracle的数据库产品?
近年来MySQL的蓬勃发展及其在互联网行业的丰富实践,使得其替换商业数据库成为了可能,尤其是阿里等行业巨头已成功地使用MySQL替换Oracle并支撑了庞大的业务。MySQL作为世界上最流行的数据库还具备如下优势:
丰富的文档资料,大量的从业人员和蓬勃的生态都使MySQL成为首选;
支持行锁和事务的Innodb存储引擎在官方的强力支持下越来越强大,对于高并发下OLTP优势明显;
灵活的逻辑复制搭建主从可以在架构设计上有更多的空间。组复制(MGR)技术可以保证数据的强一致,打通了最后一道技术壁垒,满足了金融等领域对数据强一致性的要求;
当单机成为性能瓶颈的时候,丰富的开源中间件搭配MySQL做数据拆分实现了分布式数据库改造方案,可以提供更高的业务需求。
二、MySQL对比Oracle有哪些语法、数据类型、对象类型兼容性问题?
MySQL支持 Oracle 绝大部分的基本 SQL 语法及数据类型、对象类型。部分不支持的如下:
数据类型方面MySQL不支持序列、自定义类型、XML数据类型及伪列;
MySQL不支持对象包括物化视图、包管理及同义词;
索引方面MySQL不支持位图索引、位图连接索引、函数索引、在线重建索引;
触发器方面MySQL不支持DDL事件触发器、系统事件触发器、时间触发器;
高级功能方面MySQL不支持外部数据库链接、面向对象、闪回查询等;
函数方面MySQL不支持COSH(x)、CHR(n1)、LAG()、RANK()等函数。
三、采用中间件+MySQL开发和直连MySQL开发有哪些限制?
在应用连接池配置部分与直连MySQL相同,对应用而言引入中间件屏蔽了后端拆分细节,可理解为中间件即数据库,采用中间件方式的具体限制如下:
存在部分语法限制,包括DDL、DML及管理语句,如不⽀持create table ... like ...、INSERT... SELECT...等语法;
性能方面,需要基于相同分片规则的分片键进行查询与关联查询;
不支持外键关联、临时表、触发器、分布式级别存储过程和自定义函数等。
四、如何将数据从Oracle迁移到MySQL?
从Oracle迁移到MySQL属于异构迁移,需要依赖第三方开源工具或者商业工具进行迁移。数据量大小和业务停机时间决定了迁移的方式。
当数据量很小,停机时间完全可以操作完成的时候,可以采用直接文本导出导入操作,这种方式简单并且高效。
当停机时间要求特别短,此时我们将采用OGG(Oracle Golden Gate)或者类似工具进行全量+增量保持Oracle到MySQL实时同步。等到业务停止准备切换时,停掉Oracle到MySQL同步。验证数据无误后,业务代码对接到MySQL数据库完成数据迁移过程。
五、为什么MySQL不建议建立存储过程、触发器、自定义函数等对象?
对于数据库的使用,我们强烈建议只参与数据存取,不参与业务逻辑。具体原因如下:
将业务逻辑的实现完全置于代码中,易于集中维护和调试;
触发器的嵌套,如果再涉及多个存储过程、事务控制等时,很容易出现死锁;
基于中间件实现的分布式数据库对存储过程、触发器、自定义函数支持有限;
对DB保护,减少数据库的压力;
对于异构数据库可移植性较差,增加开发成本。
六、什么情况下使用分库分表?数据库拆分方式有哪些?如何选择拆分方式?
对于MySQL而言,当数据量过大、QPS或TPS过高,或者单机的硬件资源(CPU、磁盘、内存、IO等)出现性能瓶颈,通过单方面增加硬件资源已经无法满足要求时需要考虑做分库分表。一般情况下单表大小超过2000万,数据库大小超过100G需要考虑,具体根据实际应用场景而定。
数据库拆分方式分为水平拆分和垂直拆分。
垂直拆分是指按照功能模块、关系密切度拆分到不同的表或者库,垂直拆分相对简单,不同的业务访问自己的库和表就可以实现。
水平拆分是指把表的数据按照某种规则进行划分,存储到结构相同的不同表中,水平拆分相对复杂一些,需要把一张表的数据做物理拆分,拆分的时候要根据数据的增长预测拆分的粒度,并且也要尽可能的保证数据和负载的平均。
在选择拆分方式的时候,要评估出现瓶颈的原因,如果是因为数据库表过多导致数据量过大,并且数据库中业务逻辑清晰,那么就选择垂直拆分。如果是单表的数据量比较大,就应该选择水平拆分。
七、有哪些MySQL管理工具?
常用的MySQL管理工具有:Navicat for MySQL、SQLyog、PhpMyAdmin、MySQLWorkBench等。
开源工具推荐采用MySQLWorkBench,付费推荐采用:SQLyog。
八、修改MySQL大表的风险和性能如何?
MySQL大表修改会产生死锁,所以一般情况下会采用以下两种方式进行修改:
在业务低峰期停止服务后直接ALTER修改。此方式的安全性较高,但是每次修改都需要停止业务,对于某些核心业务系统是不可接受的。而且对于比较大的表,停止业务时间也较长,成本会较高;
采用第三方工具pt-online-schema-change。该工具可以直接进行修改,其操作原理是:首先对表加锁(表此时只读),然后复制原表物理结构创建一个中间表,接下来修改中间表的物理结构,随后把原表数据导入中间表中,数据同步完后,锁定中间表,并删除原表,接下来rename中间表为原表,最后刷新数据字典并释放锁。该工具修改过程中所修改的表必须有主键,且不能是联合主键。同时也存在一定的风险,该工具在做change修改的时候不会提示错误,但是结果会发现数据会有部分丢失。在性能方面也有一定的瓶颈:如在并发比较高的情况下会对业务的访问速度有一定影响。
基于分布式数据库中间件产品,暂不支持pt-osc、gh-ost第三方工具,建议使用MySQL5.7以上版本,依靠原生Online DDL进行表结构变更。
九、MySQL分区表使用原则是什么?
MySQL实现分区表的方式是对底层表的封装,意味着索引也是按照分区的子表定义的,没有全局索引。这和Oracle不同,在Oracle中可以更加灵活地定义索引和表是否进行分区。
MySQL分区表在使用的时候常规的CRUD操作以及返回结果和普通表没有任何区别。MySQL的分区表的类型主要包括RANGE、LIST、HASH、KEY四种,不支持自建分区。
某些特定场景下可以考虑采用分区表,如历史数据有明确的分区范围、访问不跨分区、极少的变更操作、查询语句逻辑简单、无性能瓶颈等。
对于Oracle这些商业数据库,由于商业授权导致横向扩展成本较高,且分区表功能稳定,因此可通过硬件扩展和分区来承担大数据量带来的负载。而对于MySQL开源数据库,企业有资源有能力将很多需求迁移到数据库外通过代码逻辑或者其它替代方式来实现,因此更追求MySQL使用过程中的简单、稳定和可靠,且通过增加服务器以及分库分表更能处理由于数据量爆炸式增长所带来的性能问题。因此不建议大量使用MySQL分区表,尤其是在重要的业务上。
十、如何做MySQL架构选型?
可以参考如下表格:
|
系统级别高 |
系统级别中 |
系统级别低 |
|
|
数据量小 |
集中式+三中心架构 |
集中式+两中心架构 |
集中式+单中心架构 |
|
数据量大 |
分布式+三中心架构 |
分布式+两中心架构 |
分布式+单中心架构 |
数据量大小依据:以单表2000万以内,单库100G以内划分,具体可以根据实际情况而定。
集中式:即直连MySQL单机数据库。
分布式:通过中间件+MySQL做数据拆分。
三中心架构:同城双中心+异地中心。
两中心架构:本地单中心+异地中心。
单中心架构:本地单中心。
十一、MySQL如何保障数据一致性?
单机:通过双1参数设置,强制日志写入磁盘后提交事务。
复制:
主从:主从通过增强半同步实现:主库提交事务,从库需要接收到主库的日志并写入relay log,返回给主库ack消息后,主库才可以提交。基于这个原理可以最大限度的保障从库数据不丢失,主从数据的一致性,但在极端情况下会出现丢失的情况。
MGR:MySQL组复制由若干个成员共同组成一个复制组。一个事务的提交,必须经过组内大多数成员(N / 2 + 1)确认收到消息后,才能进行决议并提交。对比传统的主从复制,增加了一致性协议层和冲突认证,这是保证数据一致性和多主复制的关键所在。组复制解决了主从复制极端情况下出现数据丢失、不一致的问题,保障了数据的强一致。
十二、如何降低MySQL主从延迟?
主从延迟直接决定了RTO的时间,因此低延迟对于数据库切换、恢复时间非常重要。具体实现方法如下:
适当提高从库配置,要大于等于主库的配置;
使用更高的数据库版本,MySQL5.7开启并行复制;
表结构设计时,一定要有主键,而且主键要短小;
使用新型硬件:PCI-E & SSD类设备;
应用端适当地使用缓存,减少数据库的压力;
尽量避免大事务,建议在业务低峰期进行批量DML操作,并且小批量多次执行操作。
十三、Oracle和MySQL如何实现相互抽数?
1.双向抽数都可以通过程序实现,通过JDBC分别建立到Oracle和MySQL数据库的连接,在源数据库上执行查询返回ResultSet对象,然后通过ResultSet.next()方法逐条获取数据后,使用到目标数据库连接将数据逐条插入或批量缓存N行后插入,针对Oracle数据库查询的内存消耗为单行或N行数据大小,针对MySQL数据库查询的内存消耗为结果集大小,因此建议分页查询处理。
2.MySQL to Oracle:通过工具或select* from table_name into outfile ‘文件路径的方式将MySQL的数据导出为符合MySQL语法的SQL文件、CSV格式文件、数据文本文件,在通过Oracle的sqlldr或其他工具进行导入。
3.Oracle to MySQL:可以采用开源的工具sqluldr2,它能够将oracle中的数据导出成为符合MySQL语法的SQL文本,然后灌入到MySQL数据库中。
4.另外可以采用第三方ETL工具或OGG软件实现,具体实现原理本文不做赘述。
十四、单体MySQL、中间件+MySQL与Oracle性能对比如何?
下面以我行某业务场景单表9千万数据数据量为例(共三张不同的业务表)。
其中单表为某一张表,两表为某两张表。
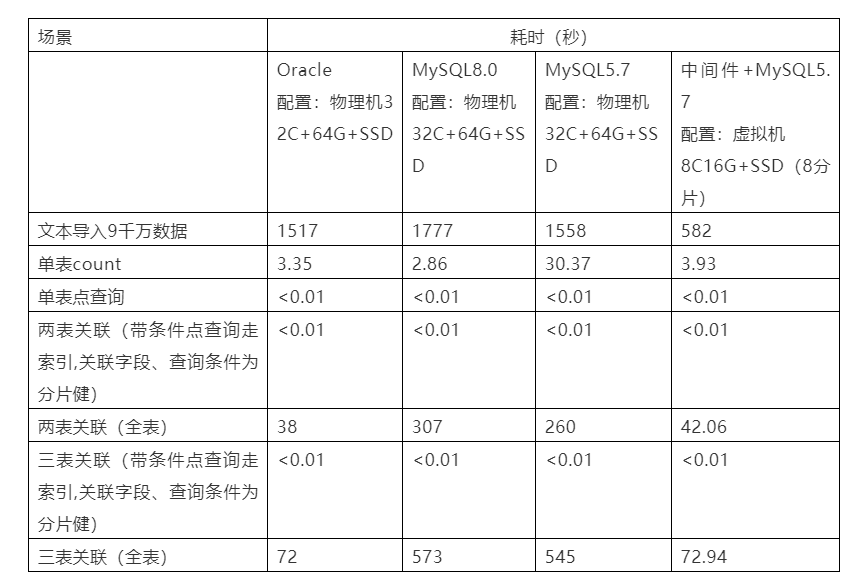
1.文本导入由于中间件+MySQL做了拆分,性能要明显好于其他单机数据。
2.单表count MySQL8.0做了优化,性能比Oracle还要好,但多表关联略差于5.7。
3.单机的MySQL无论5.7,还是8.0在关联查询上性能还是远差于Oracle的。虽然8.0支持了hash join,但也有一定的限制要求,比如关联字段不能建立索引,必须有等值条件。
4.带条件的关联查询性能表现一样,需要说明这里关联字段必须是分片健,查询条件也是分片健,中间件+MySQL的优势才可以体现出来。
5.中间件+MySQL8分片采用虚拟机(8c16G)和单库Oracle物理机(32C64G)性能上基本持平,但对语句有比较严格的要求,必须要结合分片健做关联过滤条件。
十五、如何申请MySQL主机资源,MySQL主从数量?
资源申请:
采用单机数据库、中间件配置不低于16C32G,采用分片数据单节点不低于8C16G,具体根据实际情况而定。
主从数量:
单中心部署:1主2从。
双中心部署:1主3从。
三中心部署:1主4从。
总结
以上即为我行在使用过程中最常见的15个问题,其中部分解决方案及参数选择和设置与我行的实际应用情况相关,未必适合大家各自的场景。但他山之石可以攻玉,希望我们的解决方案能够拓展大家的思路,让我们一起在数据库转型之路上共同进步!








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721