
随着系统的运行,数据量变得越来越大,单纯的将数据存储在MySQL中,已然不能满足查询要求了,此时我们引入Redis作为查询的缓存层,将业务中的热数据保存到Redis,扩展传统关系型数据库的服务能力,用户通过应用直接从Redis中快速获取常用数据,或者在交互式应用中使用Redis保存活跃用户的会话,都可以极大地降低后端关系型数据库的负载,提升用户体验。
使用传统的Redis Client命令在大数据量的导入场景下存在如下缺陷:
由于Redis是单线程模型,虽然避免了多线程下线程切换所耗费的时间,单一顺序的执行命令也很快,但是在大批量数据导入的场景下,发送命令所花费的时间和接收服务器响应结果耗费的时间就会被放大。
假如需要导入100万条数据,那光是命令执行时间,就需要花费100万*(t1 + t2)。

除了逐条命令发送,当然Redis设计肯定也会考虑这个问题,所以出现了pipelining管道模式。
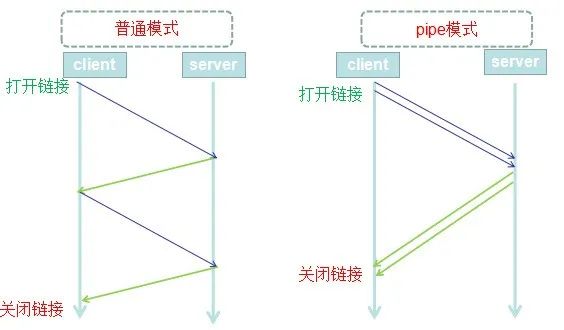
但是pipelining在命令行中是没有的,使得我们又需要编写新的处理代码,来接收批量的响应。但是只有很少很少的客户端代码支持,比如php-redis的扩展就不支持异步。
pipelining管道模式,其实就是减少了TCP连接的交互时间,当一批命令执行完毕后,一次性发送结果。
其实现原理是采用FIFO(先进先出)的队列来保证数据的顺序性。
只有一小部分客户端支持非阻塞I/O,并不是所有的客户端都能够以一种有效的方式解析应答,以最大化吞吐量。
由于这些原因,将庞大数据导入到Redis的首选方法是生成一个包含Redis协议数据格式,批量的发送过去。
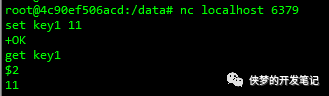
采用nc命令导入数据
nc是netcat的简写,nc的作用有:
1)实现任意TCP/UDP端口的侦听,增加-l参数后,nc可以作为server以TCP或UDP方式侦听指定端口。
2)端口的扫描,nc可以作为client发起TCP或UDP连接。
3)机器之间传输文件。
4)机器之间网络测速。
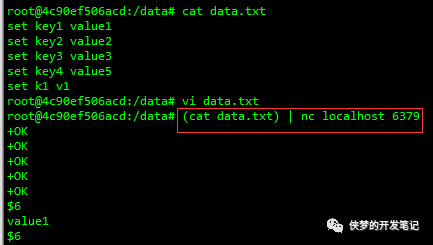
采用pipe模式导入数据
然而,使用nc监听并不是一个非常可靠的方式来执行大规模的数据导入,因为netcat并不真正知道何时传输了所有数据,也无法检查错误。在2.6或更高版本的Redis中,Redis -cli脚本支持一种称为pipe管道模式的新模式,这种模式是为了执行大规模插入而设计的。使用管道模式的命令运行如下:
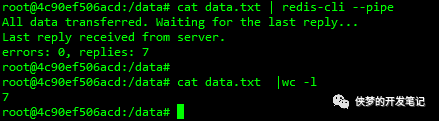
由上图,可以看到pipe命令的返回结果,txt文件中有多少行命令,返回的replies数就是多少, errors表示其中执行错误的命令条数。
协议的格式为:
*<参数数量> \r\n
$<参数 1 的字节数量> \r\n
<参数 1 的数据> \r\n
...
$<参数 N 的字节数量> \r\n
<参数 N 的数据> \r\n
比如:插入一条hash类型的数据。
HSET id book1 book_description1
根据Redis协议,总共有4个部分,所以开头为*4,其余内容解释如下:
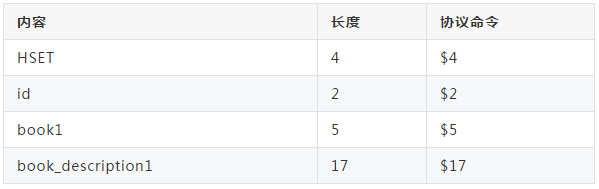
注意一下:HSET命令本身也作为协议的其中一个参数来发送。
构造出来的协议数据结构:
*4\r\n$4\r\nHSET\r\n$2\r\nid\r\n$5\r\nbook1\r\n$17\r\nbook_description1\r\n
格式化一下:
*4\r\n
$4\r\n
HSET\r\n
$2\r\n
idvvvv\r\n
$5\r\n
book1\r\n
$17\r\n
book_description1\r\n
Redis客户机使用一种称为RESP(Redis序列化协议)的协议与Redis服务器通信。
redis-cli pipe模式需要和nc命令一样快,并且解决了nc命令不知道何时命令结束的问题。
在发送数据的同时,它同样会去读取响应,尝试去解析。
一旦输入流中没有读取到更多的数据之后,它就会发送一个特殊的20比特的echo命令,标识最后一个命令已经发送完毕 如果在响应结果中匹配到这个相同数据后,说明本次批量发送是成功的。
使用这个技巧,我们不需要解析发送给服务器的协议来了解我们发送了多少命令,只需要解析应答即可。
在解析应答时,Redis会对解析的应答进行一个计数,在最后能够告诉用户大量插入会话向服务器传输的命令的数量。也就是上面我们使用pipe模式实际操作的响应结果。
将输入数据源换成MySQL
上面的例子中,我们以一个txt文本为输入数据源,使用了pipe模式导入数据。
基于上述协议的学习和理解,我们只需要将MySQL中的数据按照既定的协议通过pipe模式导入Redis即可。
首先造数据
由于环境限制,所以这里没有用真实数据来实现导入,那么我们就先使用一个存储过程来造一百万条数据吧。使用存储过程如下:
DELIMITER $$
USE `cb_mon`$$
DROP PROCEDURE IF EXISTS `test_insert`$$
CREATE DEFINER=`root`@`%` PROCEDURE `test_insert`()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i<= 1000000
DO
INSERT INTO t_book(id,number,NAME,descrition)
VALUES (i, CONCAT("00000",i) , CONCAT('book',i)
, CONCAT('book_description',i));
SET i=i+1;
END WHILE ;
COMMIT;
END$$
DELIMITER ;
调用存储过程:
CALL test_insert();
查看表数据:
按协议构造查询语句。
按照上述Redis协议,我们使用如下SQL来构造协议数据:
SELECT
CONCAT(
"*4\r\n",
"$",
LENGTH(redis_cmd),
"\r\n",
redis_cmd,
"\r\n",
"$",
LENGTH(redis_key),
"\r\n",
redis_key,
"\r\n",
"$",
LENGTH(hkey),
"\r\n",
hkey,
"\r\n",
"$",
LENGTH(hval),
"\r\n",
hval,
"\r"
)
FROM
(SELECT
"HSET" AS redis_cmd,
id AS redis_key,
NAME AS hkey,
descrition AS hval
FROM
cb_mon.t_book
) AS t limit 1000000
并将内容保存至redis.sql 文件中。
编写脚本使用pipe模式导入Redis
编写shell脚本。由于我在主机上是通过docker安装的Redis和MySQL,以下脚本供参考:

#!/bin/bash
starttime=`date +'%Y-%m-%d %H:%M:%S'`
docker exec -i 899fe01d4dbc mysql --default-character-set=utf8
--skip-column-names --raw < ./redis.sql
| docker exec -i 4c90ef506acd redis-cli --pipe
endtime=`date +'%Y-%m-%d %H:%M:%S'`
start_seconds=$(date --date="$starttime" +%s);
end_seconds=$(date --date="$endtime" +%s);
echo "脚本执行耗时:"$((end_seconds-start_seconds))"s"
执行截图:

可以看到百万级的数据导入Redis,只花费了7秒,效率非常高。
注意事项
如果MySQL表特别大,可以考虑分批导入,或者将表拆分,否则在导入过程中可能会发生:
lost connection to mysql server during query
由于max_allowed_packed和超时时间限制,查询数据的过程中,可能会造成连接断开,所以在数据表的数据量特别大的时候,需要分页或者将表拆分导入。
本篇文章主要探讨了,MySQL百万级数据量级下,如何高效的迁移到Redis中去,逐步实现目标的过程中,总结了如下几点:
1、Redis单线程执行命令,避免了线程切换所消耗的时间,但是在超大数据量级下,其发送、响应接收的时延不可忽视。
2、网络nc命令的应用场景,及在数据导入时存在的缺点。
3、Redis RESP协议的理解和应用。
4、百万量级MySQL数据的Redis快速导入案例。
活动推荐
2020年5月29日,北京,Gdevops全球敏捷运维峰会将开启年度首站!重点围绕数据库、智慧运维、Fintech金融科技领域,携手阿里、腾讯、蚂蚁金服、中国银行、平安银行、中邮消费金融、建设银行、工商银行、农业银行、民生银行、58到家、中国联通大数据、浙江移动、新炬网络等技术代表,展望云时代下数据库发展趋势、破解运维转型困局。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721