

一、初识Vitess
MySQL作为关系型数据库的佼佼者,伴随着互联网技术的发展,已风靡全球十余年;但是MySQL单机存储能力有限。性能或者容量达到瓶颈后,就需要我们来进行改造。
当MySQL出现性能和存储瓶颈后,目前有2个大的解决方向。一个是利用程序或者数据库中间件(底层仍是MySQL)来实现分库分表,。这种中间件方案,我相信每个DBA或者相关研发人员,或多或少的都了解过或测试过。
另一个方向,就是使用分布式数据库直接解决,比如业内比较火的tidb,cockroachdb等。对于后者,我想没有人去否定它,它一定是关系型数据库的将来;因此一些大公司纷纷都在招募人马,积极发展自己的分布式关系型数据库,但是目前此类数据库还有一些问题亟待解决,因此传统的分库分表中间件还是有它成长和发展空间的。
我今天将向大家介绍一个集部署、扩展、管理大型MySQL实例集群的数据库解决方案:Vitess。
Vitess最初的名字是Voltron, Voltron是动画片里的人物形象,可以把多个部件汇总在一起组成超级机器人(隐喻Vitess是分布式系统),选择开源对外发布的时候,合伙人给这个产品起名为vitesse,法语中“速度”的意思,但这哥们由于拼写经常糊里糊涂的,漏写了一个e,后来也就这样了。(玩笑)
Vitess的里程碑:
2010年出生,2011年上线应用
2012年开源,2015年为云而生
2018年2月加入CNCF
2019年10月从CNCF毕业
CNCF有三个不同层次的项目:沙箱、孵化和毕业。目前只有8个项目毕业,这意味着它们符合最高水平的质量标准。有了CNCF的毕业认证背书,说明Vitess是质量可靠、社区完善、创新新颖的数据库中间件软件。
下面是一些客观数据,也说明Vitess是非常被业界认可的。
Github:9,000+ stars、17,000+ commits、190+ contributors、1200+ forks、1000+ Slack members
谁在使用:Youtube、Slack、Square、Pinterest、Github、BetterCloud等
使用环境:k8s/non k8s, AWS / GKE / EKS / Azure
1)扩展性
Vitess集MySQL数据库的很多重要特性和NoSQL数据库的可扩展性于一体。
其内建拆分分片功能使用户的MySQL数据库集群可以实现无限水平扩展,同时无需为应用添加分片逻辑。
2)性能
Vitess避免了MySQL连接的高内存开销。Vitess服务器轻松地一次处理数千个连接。
Vitess自动重写对数据库性能有损害的查询。它还使用缓存机制来调解查询,并防止重复查询同时到达后端的数据库。
3)运维
Vitess可以支持自动处理主故障转移和备份等功能。
它使用分布式元数据服务来跟踪和管理服务器,使您的应用程序无需关心数据库拓扑变化。
4)Cloud-native
容器化(Containerized):每个部分(应用程序,进程等)都封装在自己的容器中。这有助于重复性,透明度和资源隔离。
动态编排(Dynamically orchestrated):动态的调度和管理容器以优化资源利用。
面向微服务(Microservices oriented):应用程序基于微服务架构,显著提高架构演进的灵活性和可维护性。
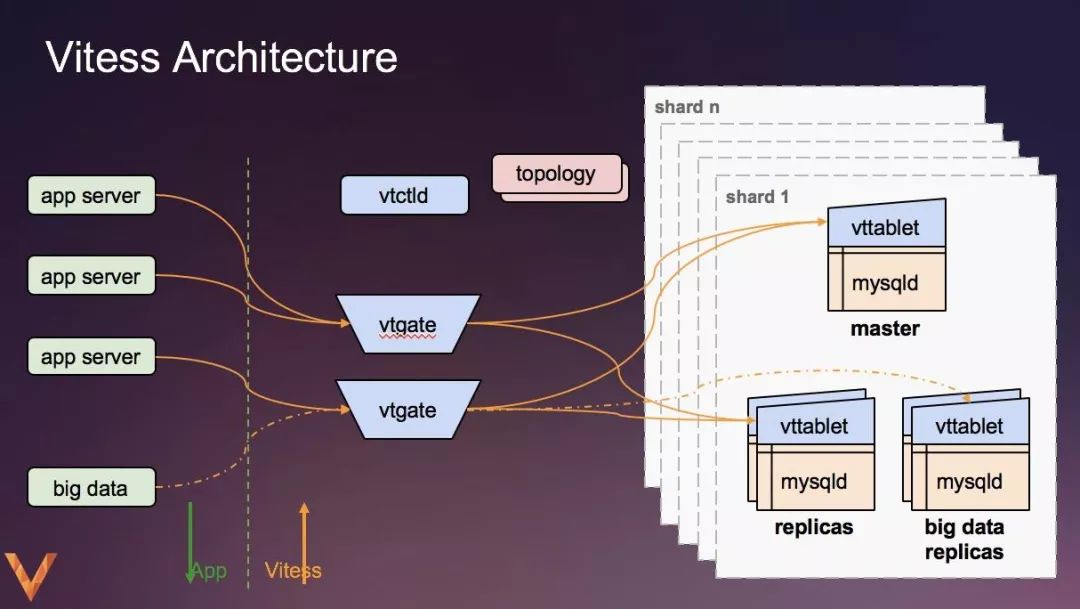
其中各个角色用途如下:
1)Vttablets部署在某个单独的MySQL实例之前,接管所有与该MySQL实例的通信和维护主、从架构。
2)Vitess需要一个拓扑服务器来存储其元数据。可以是etcd、zk、consul等。
3)Vtgate是无状态的proxy,可以动态的扩容。(由于proxy是带数据库连接状态的,缩容是需要注意的)
4)应用服务器可以连接到任何vtgate,甚至在请求之间。
5)vtctld是用于查看系统元数据,启动工作流,具备相关维护操作的web服务。
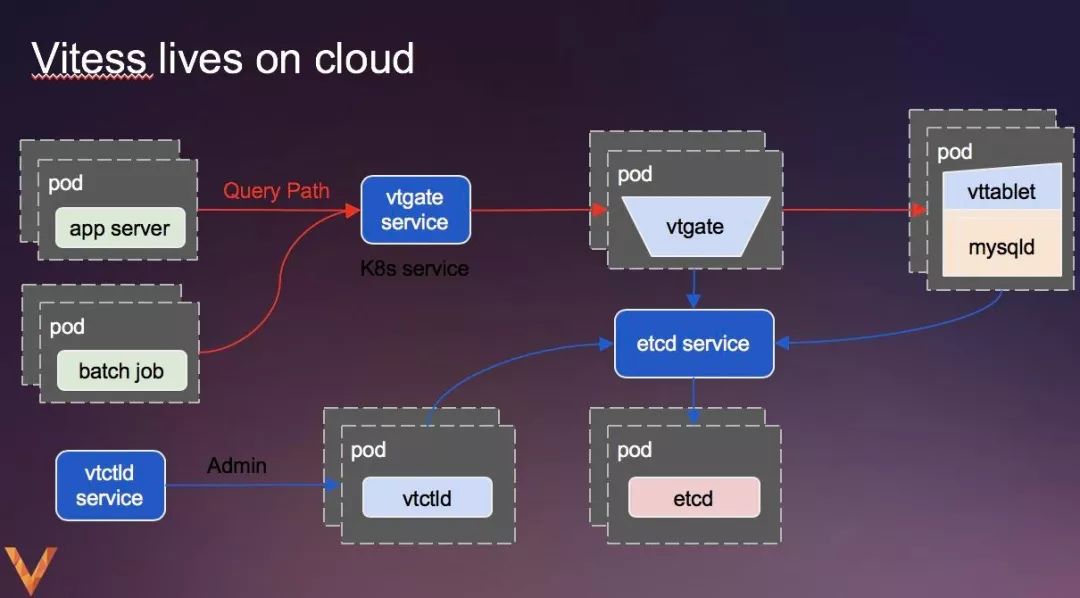
前面我们提到,Vitess为云而生,Vitess是如何做到的?
Vitess出生于youtube,part of google,vitess早于k8s,但已为k8s准备就绪,因为它在google内部服务于borg系统,而k8s的前身正是borg。云中的数据库是k8的最后一个领域,而Vites填补了这一空白。目前大规模使用k8s部署生产集群的公司有,JD 、Needlework Lab,Hub 。
下面的图中,我们可以看到,Vitess的每个角色,都利用k8s部署到了云环境中。
下面我们介绍一些Vitess重要概念,通过这些概念,我们可以指定Vitess是如何维护数据库集群的。
1)Cell
一个Cell是指一个网络资源区域,在这个区域里,放置一组服务器或网络基础设施。它通常对应物理部署中的数据中心,亦可称为可用区域。Cell的主要作用是网络隔离。Vitess可以优雅的处置Cell级别的网络故障,如果有其他的Cell故障并不会影响到当前Cell。
示例:
整个数据中心
数据中心的一个子集,可用区域
一个Kubernetes集群
2)Keyspace
逻辑 数据库概念
未拆分场景下, keyspace => 单个 MySQL 集群
拆分场景下, keyspace => 多个 MySQL 集群 (相同配置)
无论哪种情况,从应用程序的角度来看,对外表现都是一个数据库集群
3)Keyspace ID
Keyspace 由keyspace ID 范围区间组成
每一行都能映射到一个keyspace ID
相当于一行数据的街道门牌号码,是决定一行数据存在于哪个Shard的标识
Vitess内部实现,应用程序不需要知道任何关于它的信息。
通过计算而得,并未存储
4)Shard
Keyspace ID 范围 (Begin, End)
如果 Begin < KeyspaceID <= End, 那么计算而得到KeyspaceID的这行数据属于这个shard
一主多从
位于一个或多个Cell中

5)Vindex
对表中数据计算得到Keyspace ID 的方法
表的Vindex 由下列两种参数定义:
拆分列
分片函数
KeySpaceIDForRow = ShardingFunction(ColumnValueForRow)
举个栗子:
表名: customer, 拆分列名: id,分片函数: hash
For a row where id is 123, KeySpaceId = hash(123)
6)Sharding functions
下面是vitess已经提供的Sharding functions,当然我们也可以自定义。
二、Reshard
经过前面的基本概念的介绍,下面我们看一些vitess实现的reshard的过程。2片->4片的过程,需要说明的是,整个拆分过程,业务代码不用任何修改,只是在最后的切流量环节,会有几秒钟的可用率下跌:
1)首先是一个正常的2个分片的keyspace,分片的名字分别是00-80,80-FF,正常对外提供服务,首先每个分片上选择一个从库,如图中所示:
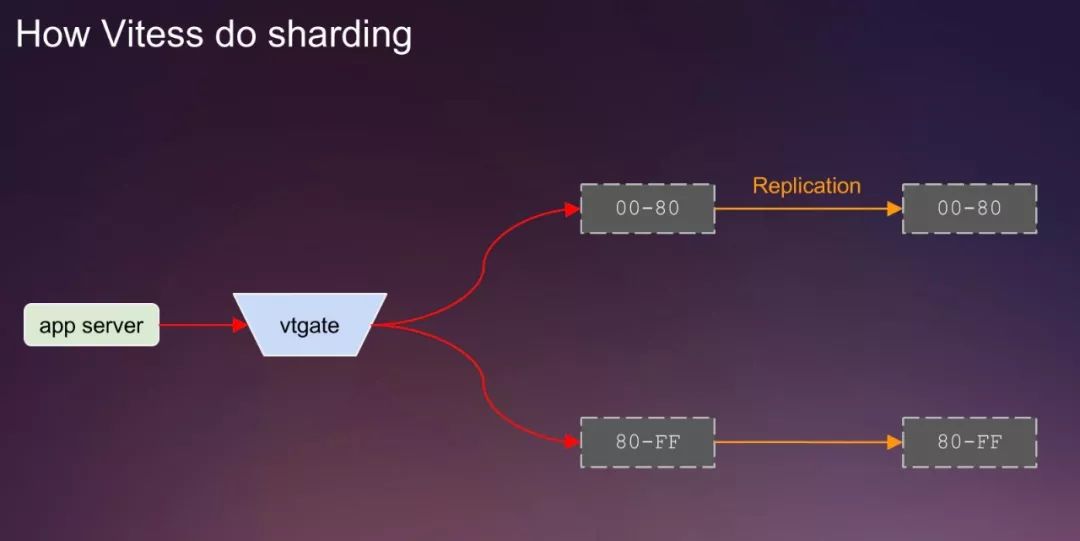
2)接下来呢,申请新的分片需要的资源同时将老分片的从库停止复制,为下一步操作做好准备。

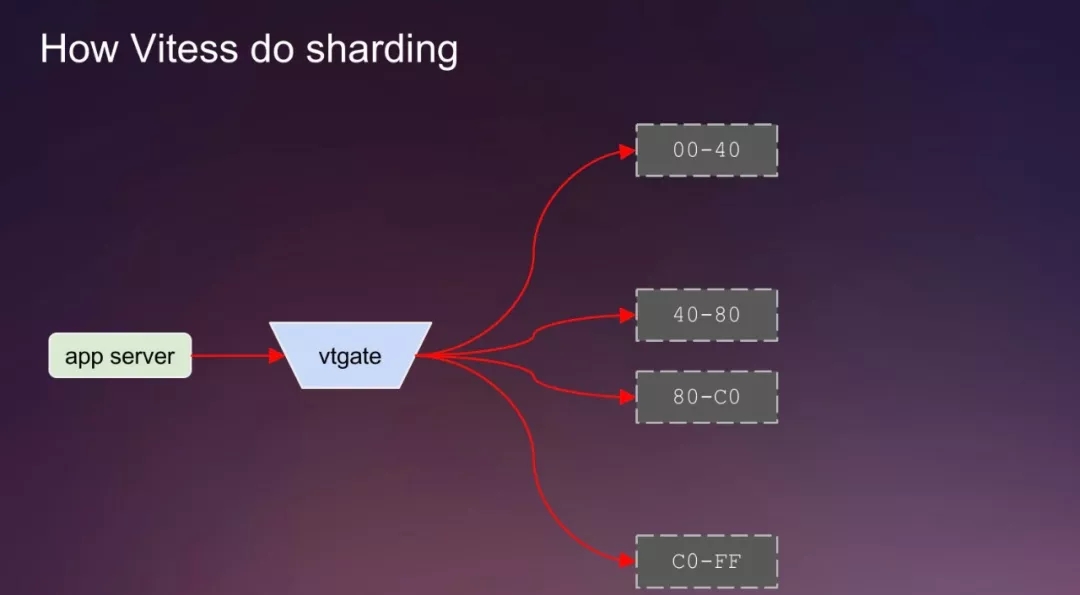
3)根据路由信息,将老分片的静态数据拷贝到新的分片上去。
其中要根据具体数据的keyspace id来路由数据。
00-80的数据只能路由到00-40或者40-80分片上。
80-FF的数据只能路由到80-C0或者C0-FF分片上。
4)根据前面拷贝静态数据的binlog结束的位置点开始做过滤复制,核心点也是根据具体数据行的keyspace id路由到正确的地方。

5)下一步操作就是切量流量。切换过程中,Vitess做了如下操作:数据校验、切流量(先切从、再切主)。
6)下一步操作就是清理老的资源,建议观察几天后,再做此步骤。清理完老的分配资源后的效果如下:
三、落地Vitess
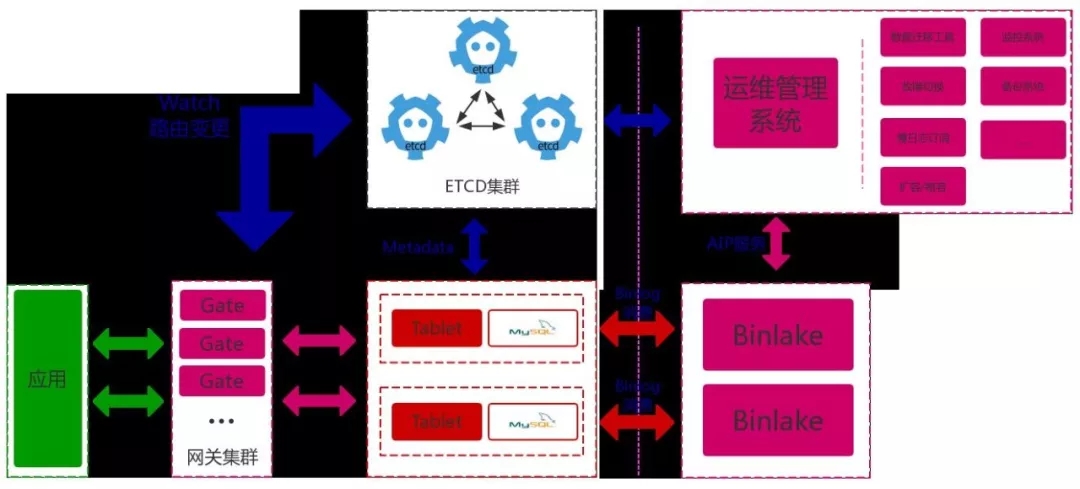
上面的架构图是我们使用Vitess的架构图,其中需要重点说明的如下几点:
管理工具需要可以同时操作Vitess及K8s。
迁移工具:从普通库迁移到Vitess集群的工具,同时配套相应数据校验工具。
Binlake:对外的一个提供类似canal抽数服务,对接kafka消息队列,业务无需知道集群内发生的任何事情,这意味着binlake具备采集自愈功能,能够保证业务消费到的binlog一定是新鲜无误的。
1)具备连接状态的网关升级问题
修改rc的镜像为最新的。
修改老的pod的标签,使service的标签选择器无法找到当前pod,同时rc会根据新的镜像,拉起新的pod。
循环以上步骤。
2)复杂sql的支持:join、load、Prepare等支持。
3)App的需求:业务隔离性、大数据部抽数、超核心系统的敏感性。
基于业务分级,物理隔离敏感系统及高i/o,高吞吐的项目
核心系统的使用独立网关
抽数使用独立网关,使用流式抽数
4)Etcd问题:修复一些bug造成Etcd OOM; app过多时,Vschema大value问题。
大value独立存储。
Vschma的操作由Cell级别拆成keyspace级别。
Vitess作为一个核心产品,周边的生态仍然相对欠缺,各位如果有想把Vitess大规模用于生产,一定要对如下几点做好调研:
监控:监控要覆盖每个角色的每个pod。
拆分:一定要熟悉拆分过程,能够定位bug、修改bug,便于解决拆分中遇到的问题。
可靠的调度系统:一定要用好K8S本身强大的功能;或者Nomad也可以考虑。
最重要的一点,实际动手操作,走出第一步,迁一个业务试试!
直播回放
https://m.qlchat.com/topic/details?topicId=2000007160506168
活动推荐
2020年4月17日,北京,Gdevops全球敏捷运维峰会将开启年度首站!重点围绕数据库、智慧运维、Fintech金融科技领域,携手阿里、腾讯、蚂蚁金服、中国银行、平安银行、中邮消费金融、中国农业银行、中国民生银行、中国联通大数据、浙江移动、新炬网络等技术代表,展望云时代下数据库发展趋势、破解运维转型困局。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721