
刘书浩,“移动云”DBA,负责“移动云”业务系统的数据库运维、标准化等工作;擅长MySQL技术领域,熟悉MySQL复制结构、Cluster架构及运维优化;具有自动化运维经验,负责“移动云”数据库管理平台的搭建。
前言
在云平台的日常运维工作中,有很多故障排查和数据核对的场景,为了给全线运维人员(含部分开发和运营分析人员)提供现网数据的实时查询,我们使用MySQL和开源工具otter搭建了一套数据查询和管理系统,可以查询平台各资源池现网当前的数据。并与现网保持准实时同步(秒级延时)。
查询模块的主要组件是MySQL,纳管线上业务系统的核心数据库,用户使用频次极高,此台MySQL中的部分核心数据还作为其他资源池的源数据,实时同步给异地机房。负责数据实时同步的otter管理节点与MySQL部署在同一物理机上,是云平台所有资源池中查询模块的中枢节点。
首先,介绍一下开源工具Otter(内容引自GitHub)
Otter是由阿里提供的基于数据库增量日志解析,准实时同步到本机房或异地机房MySQL数据库的一个分布式数据库同步系统,工作原理如下:
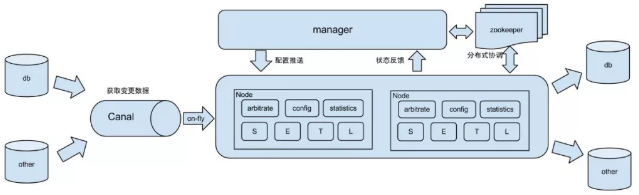
db:数据源以及需要同步到的库;
Canal:用户获取数据库增量日志;
manager:配置同步规则设置数据源同步源等;
zookeeper:协调node进行协调工作;
node:负责任务处理处理接受到的部分同步工作。
一、Otter的特性
1、纯JAVA开发,占时资源比较高
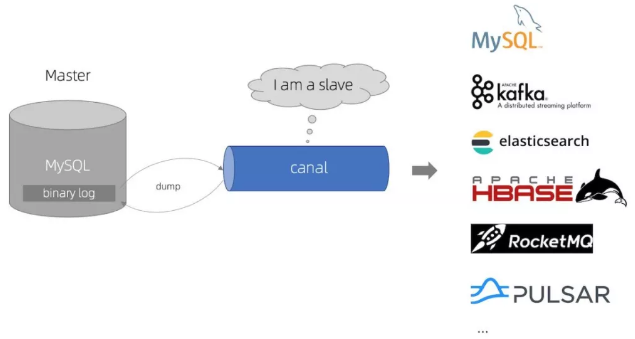
2、基于Canal获取数据库增量日志数据,Canal是阿里另一款开源产品
下面是Canal的原理图:
基于MySQL主备复制原理:
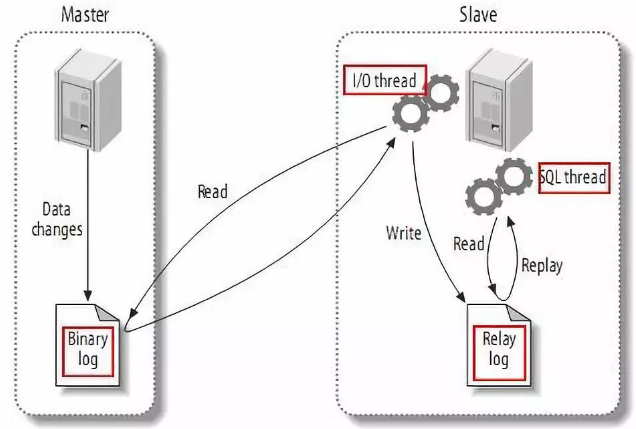
MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看);
MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log);
MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据。
Canal工作原理:
Canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议;
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal );
Canal 解析 binary log 对象(原始为 byte 流)。
3、典型管理系统架构,manager(web管理)+node(工作节点)
1)manager运行时推送同步配置到node节点,负责配置监控
2)node节点将同步状态反馈到manager上,负责处理任务
4、基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作
5、使用aria2多线程传输技术,对网络依赖带宽依赖较低
二、Otter能解决什么问题
1、异构库同步
MySQL -> MySQL/Oracle。(目前开源版本只支持MySQL增量,目标库可以是MySQL或者Oracle,取决于Canal的功能)
2、单机房同步 (数据库之间RTT < 1ms)
数据库版本升级;
数据表迁移;
异步二级索引。
3、异地机房同步(是Otter最大的亮点之一,可以解决国际化问题把数据从国内同步到国外提供用户使用,在国内场景可以做到数据多机房容灾)
机房容灾
4、双向同步(双向同步是在数据同步中最难搞的一种场景,Otter可以很好的应对这种场景,Otter有避免回环算法和数据一致性算法两种特性,保证双A机房模式下,数据保证最终一致性)
1)避免回环算法 (通用的解决方案,支持大部分关系型数据库)
2)数据一致性算法 (保证双A机房模式下,数据保证最终一致性,亮点)
5、文件同步
站点镜像 (进行数据复制的同时,复制关联的图片,比如复制产品数据,同时复制产品图片)
单机房复制示意图:

说明:
数据on-Fly,尽可能不落地,更快的进行数据同步. (开启node loadBalancer算法,如果Node节点S+ETL落在不同的Node上,数据会有个网络传输过程);
node节点可以有failover / loadBalancer。
异地机房复制示意图:
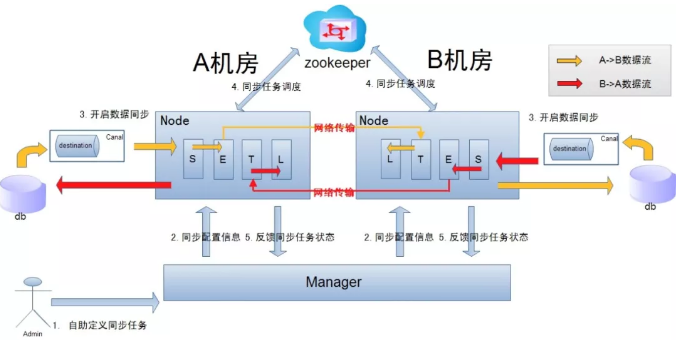
说明:
数据涉及网络传输,S/E/T/L几个阶段会分散在2个或者更多Node节点上,多个Node之间通过zookeeper进行协同工作 (一般是Select和Extract在一个机房的Node,Transform/Load落在另一个机房的Node);
node节点可以有failover / loadBalancer. (每个机房的Node节点,都可以是集群,一台或者多台机器)。
关于Otter的调度模型、数据入库算法、一致性、高可用性和扩展性等内容,可以登录GitHub了解。
「Otter」相关链接:https://github.com/alibaba/otter/wiki/Introduction
里面有详细的介绍,本文不再赘述,下面重点说明一下otter的安装和使用。
三、安装部署
移动云业务需要数据汇总,需将多个主数据库同步汇总到一个从数据库中,方便数据统计分析。Otter中间件则满足了此需求,相对比多源复制,更加灵活和可塑性。
前面简单介绍了Otter的基本信息,下面开始搭建一个Otter环境,因为一个Otter需要Manage+node+数据库还有很多的依赖,这里我们先来搭建Otter的管理服务器Manager。
1、环境准备
1)阿里软件
Otter(manager、node)软件:https://github.com/alibaba/otter/releases
Manager数据库初始化脚本:https://raw.githubusercontent.com/alibaba/otter/master/manager/deployer/src/main/resources/sql/otter-manager-schema.sql
2)集群
Zookeeper:http://download.csdn.net/download/jxplus/9451794
3)JAVA
JDK:测试环境使用yum安装1.6以上版本
4)数据库
Mysql5.7:http://dev.mysql.com/downloads/mysql/
5)操作系统
CentOS 7.1.1503 (Core):https://www.centos.org/download/
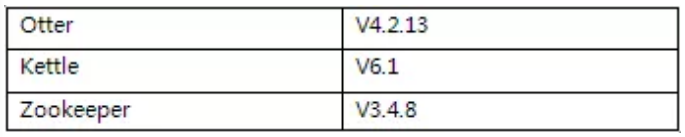
版本信息
2、软件安装
1)操作系统安装
2)java jdk1.6
安装完成操作系统后,使用yum安装jdk1.6以上版本(含1.6)
yum -y install java-1.6.0-openjdk.x86_64
3)安装MySQL数据库
4)安装集群软件ZooKeeper
下载安装包后解压即可,不需要编译安装。然后进行配置:
① 修改tickTime、clientPort、dataDir参数
vim /zookeeper-3.4.8/conf/zoo.cfg
tickTime :时长单位为毫秒,为zk使用的基本时间度量单位。例如,1 * tickTime是客户端与zk服务端的心跳时间,2 * tickTime是客户端会话的超时时间。
tickTime的默认值为2000毫秒,更低的tickTime值可以更快地发现超时问题,但也会导致更高的网络流量(心跳消息)和更高的CPU使用率(会话的跟踪处理)。
clientPort :zk服务进程监听的TCP端口,默认情况下,服务端会监听2181端口。
dataDir :无默认配置,必须配置,用于配置存储快照文件的目录。
② 执行下面命令启动server
cd /zookeeper-3.4.8/bin/
./zkServer.sh start
③ 查看是否启动成功
ps -ef |grep zookeeper
5)安装阿里otter(manager、node)
① 初始化manager的otter数据库
连接安装好的mysql数据库,在数据库软件中创建otter数据库,在操作系统命令行执行:
mysql -uroot -pxxxx otter <otter-manager-schema.sql
② 解压manager安装包到指定目录,并做如下修改
vim /otter/conf/otter.properties
otter.domainName=本机IP
otter.port = web访问端口
otter.zookeeper.cluster.default=zookeeper server ip
③ cd /otter/bin执行shstartup.sh,查看 vim /otter/logs/manager.log,出现以下信息说明manager启动成功

④ 访问本机ip+port,可以看到manager管理平台,使用匿名用户只能查看,使用admin用户可以操作配置
⑤ 安装node,在manager页面为node定义配置信息,并生一个唯一id,首先访问manager页面的机器管理页面,点击添加机器按钮并配置node的一些参数
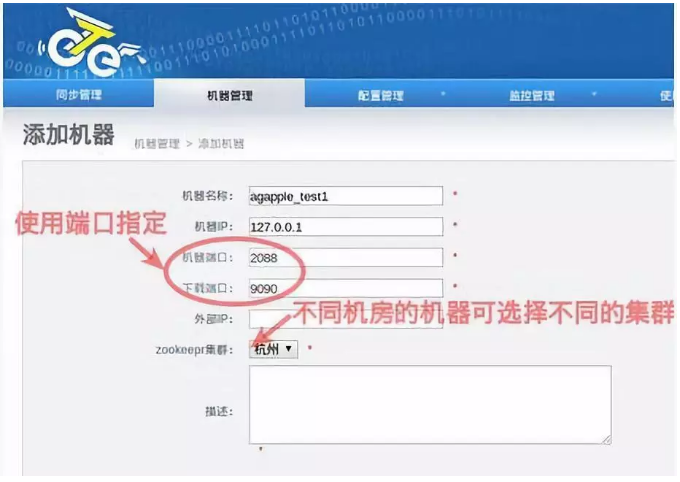
机器名称:自定义,方便记忆即可
机器IP :对应node节点将要部署的机器ip,如果有多ip时,可选择其中一个ip进行暴露(此ip是整个集群通讯的入口,实际情况千万别使用127.0.0.1,否则多个机器的node节点会无法识别)
机器端口:node数据通信端口,建议默认2088
下载端口:node数据下载端口,建议默认9090
外部地址:node部署的物理机外网IP,存在一个外部ip允许通讯的时候走公网处理,没有可以不写。
Zookeeper集群:zookeper server ip
⑥ 机器添加完成后,跳转到机器列表页面,获取对应的机器序号nid
⑦ 解压node安装包到指定目录,将第五步生成的nid写入conf目录下的nid文件
echo nid> /node/conf/nid
⑧ 修改 /node/conf/otter.properties文件
otter.manager.address = manager 安装部署机器的IP+PORT
例如:
otter.manager.address = 192.168.165.200:1099
⑨ 启动node
cd /node/bin
sh startup.sh
⑩ 验证node
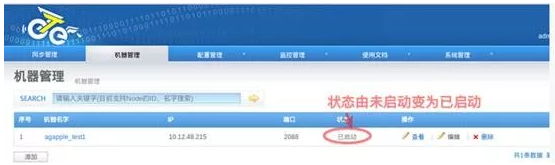
访问 http://managerip:port/node_list.htm,查看对应节点状态,如果变为已启动,说明node已经正常启动。
3、同步配置
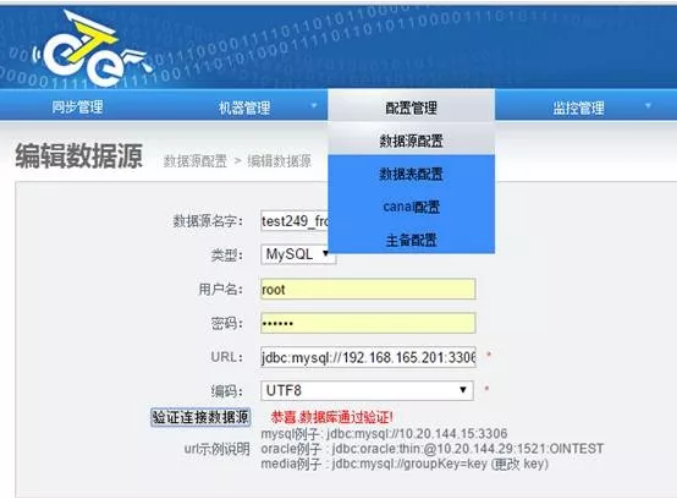
1)添加数据源-数据来源端
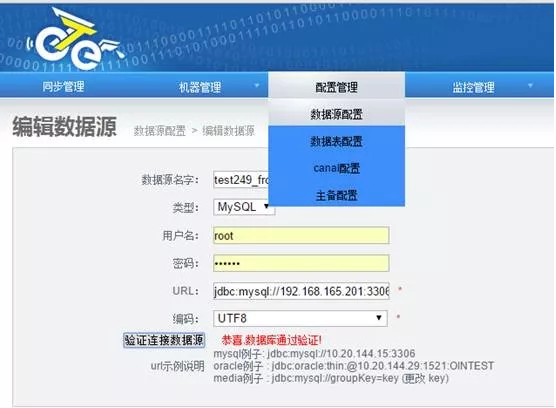
2)添加数据源-数据落地端
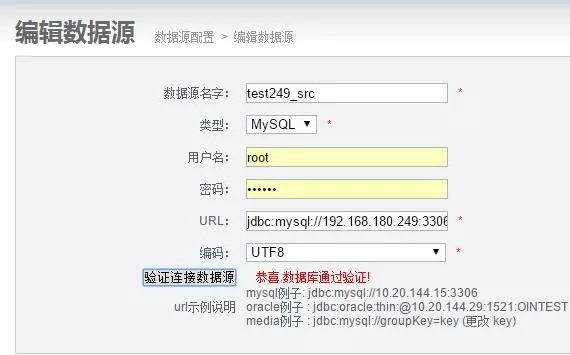
3)添加需要同步的数据表-数据来源端

4)添加需要同步的数据表-数据落地端

5)添加canal
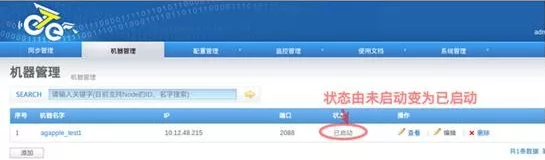
6)添加channel

7)添加Pipeline
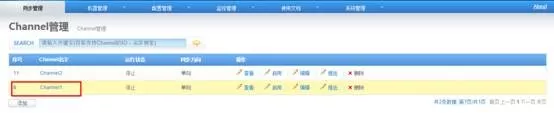
点击上一步添加的channel1,添加pipeline。
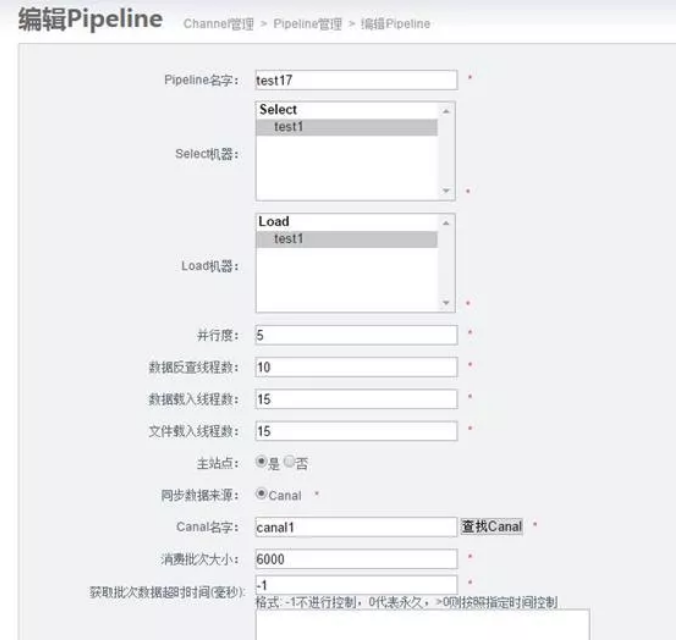
8)添加表映射关系

点击上一步添加的pipeline test17,添加表映射关系。
9)启动channel
添加完成表映射关系后,回到channel页面,启动刚刚添加channel1。
10)测试同步
11)构建kerberos安全域
由于查询涉及到现网数据的异地传输,数据安全保障工作十分重要,因此构建了Kerberos安全域。域内的组件互通,以及外部客户端访问域内组件,均需要经过kerberos的认证。
通过上述操作otter环境基本配置好了,并且搭建了zookeeper+manager环境,成功运行了otter-manager管理界面,并完成了数据同步测试。这样我们初步完成了数据同步和查询平台的搭建。
四、数据查询平台的使用
推荐使用Navicat等工具,IP、端口、账号、密码等和原魔数台相同。
可以将访问频次比较高的数据保存为视图。
不建议使用select * 或没有任何条件的全表查询,查询数据前先查找对象表的主键,并使用主键过滤。
查询模块的逻辑架可以设计为星型结构,MySQL除作为核心数据主节点,将核心数据分发到各资源池之外,其他资源池的数据不互通。
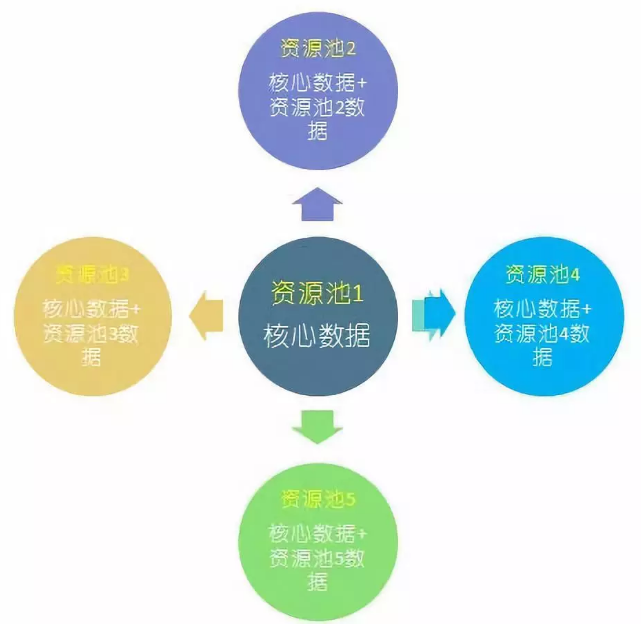
为兼容数据表外键(外键关联的表数据变更不能被同步),保证数据一致性,对出现不一致的表数据,采用点对点trigger触发变更的方式,逐个建立关联触发器。

总结
通过以上方式,我们就初步搭建了一套生产环境数据同步和查询系统,可以满足日常运维中大多数故障排查和数据核对的场景,为运维人员提供一种安全、实时和有效的数据查询平台。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721