
一、前言
你是否在为系统的数据库来一波大流量就几乎打满CPU,日常CPU居高不下烦恼?你是否在各种NoSQL间纠结不定,到底该选用哪种最好?今天的你就是昨天的我,这也是写这篇文章的初衷。
这篇文章是我好几个月来一直想写的一篇文章,也是一直想学习的一个内容,作为互联网从业人员,我们要知道关系型数据库(MySQL、Oracle)无法满足我们对存储的所有要求,因此对底层存储的选型,对每种存储引擎的理解非常重要。同时也由于过去一段时间的工作经历,对这块有了一些更多的思考,想通过自己的总结把这块写出来分享给大家。
二、结构化数据、非结构化数据与半结构化数据
文章的开始,聊一下结构化数据、非结构化数据与半结构化数据,因为数据特点的不同,将在技术上直接影响存储引擎的选型。
首先是结构化数据,根据定义,结构化数据指的是由二维表结构来逻辑表达和实现的数据,严格遵循数据格式与长度规范,也称作为行数据,特点为:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。例如:

因此关系型数据库完美契合结构化数据的特点,关系型数据库也是关系型数据最主要的存储与管理引擎。
非结构化数据,指的是数据结构不规则或不完整,没有任何预定义的数据模型,不方便用二维逻辑表来表现的数据,例如办公文档(Word)、文本、图片、HTML、各类报表、视频音频等。
介于结构化与非结构化数据之间的数据就是半结构化数据了,它是结构化数据的一种形式,虽然不符合二维逻辑这种数据模型结构,但是包含相关标记,用来分割语义元素以及对记录和字段进行分层。常见的半结构化数据有XML和JSON,例如:
这种结构也被成为自描述的结构。
三、以关系型数据库的方式做存储的架构演进
首先,我们看一下使用关系型数据库的方式,企业一个系统发展的几个阶段的架构演进(由于本文写的是SQL与NoSQL,因此只以存储方式作为切入点,不会涉及类似MQ、ZK这些中间件内容):
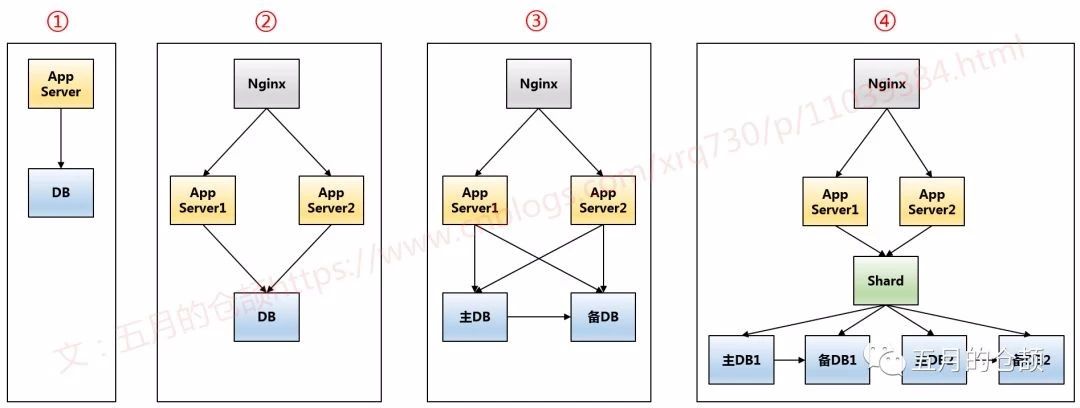
阶段一:企业刚发展的阶段,最简单,一个应用服务器配一个关系型数据库,每次读写数据库。
阶段二:无论是使用MySQL还是Oracle还是别的关系型数据库,数据库通常不会先成为性能瓶颈,通常随着企业规模的扩大,一台应用服务器扛不住上游过来的流量且一台应用服务器会产生单点故障的问题,因此加应用服务器并且在流量入口使用Nginx做一层负载均衡,保证把流量均匀打到应用服务器上。
阶段三:随着企业规模的继续扩大,此时由于读写都在同一个数据库上,数据库性能出现一定的瓶颈,此时简单地做一层读写分离,每次写主库,读备库,主备库之间通过binlog同步数据,就能很大程度上解决这个阶段的数据库性能问题.
阶段四:企业发展越来越好了,业务越来越大了,做了读写分离数据库压力还是越来越大,这时候怎么办呢,一台数据库扛不住,那我们就分几台吧,做分库分表,对表做垂直拆分,对库做水平拆分。以扩数据库为例,扩出两台数据库,以一定的单号(例如交易单号),以一定的规则(例如取模),交易单号对2取模为0的丢到数据库1去,交易单号对2取模为1的丢到数据库2去,通过这样的方式将写数据库的流量均分到两台数据库上。一般分库分表会使用Shard的方式,通过一个中间件,便于连接管理、数据监控且客户端无需感知数据库IP。
上面的方式,看似可以解决问题(实际上确实也能解决很多问题),正常对关系型数据库做一下读写分离 + 分库分表,支撑个1W+的读写QPS还是问题不大的。但是受限于关系型数据库本身,这套架构方案依然有着明显的不足,下面对利用关系型数据库方式做存储的方案的优点先进行一下分析,后一部分再分析一下缺点,对某个技术的优缺点的充分理解是技术选型的前提。
1)易理解
因为行 + 列的二维表逻辑是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型更加容易被理解。
2)操作方便
通用的SQL语言使得操作关系型数据库非常方便,支持join等复杂查询。
3)数据一致性
支持ACID特性,可以维护数据之间的一致性,这是使用数据库非常重要的一个理由之一,例如同银行转账,张三转给李四100元钱,张三扣100元,李四加100元,而且必须同时成功或者同时失败,否则就会造成用户的资损。
4)数据稳定
数据持久化到磁盘,没有丢失数据风险,支持海量数据存储。
5)服务稳定
最常用的关系型数据库产品MySQL、Oracle服务器性能卓越,服务稳定,通常很少出现宕机异常。
紧接着的,我们看一下关系型数据库的缺点,也是比较明显的。
1)高并发下IO压力大
数据按行存储,即使只针对其中某一列进行运算,也会将整行数据从存储设备中读入内存,导致IO较高。
2)为维护索引付出的代价大
为了提供丰富的查询能力,通常热点表都会有多个二级索引,一旦有了二级索引,数据的新增必然伴随着所有二级索引的新增,数据的更新也必然伴随着所有二级索引的更新,这不可避免地降低了关系型数据库的读写能力,且索引越多读写能力越差。有机会的话可以看一下自己公司的数据库,除了数据文件不可避免地占空间外,索引占的空间其实也并不少。
3)为维护数据一致性付出的代价大
数据一致性是关系型数据库的核心,但是同样为了维护数据一致性的代价也是非常大的。我们都知道SQL标准为事务定义了不同的隔离级别,从低到高依次是读未提交、读已提交、可重复度、串行化,事务隔离级别月底,可能出现的并发异常越多,但是通常而言能提供的并发能力越强。
那么为了保证事务一致性,数据库就需要提供并发控制与故障恢复两种技术,前者用于减少并发异常,后者可以在系统异常的时候保证事务与数据库状态不会被破坏。对于并发控制,其核心思想就是加锁,无论是乐观锁还是悲观锁,只要提供的隔离级别越高,那么读写性能必然越差。
4)水平扩展后带来的种种问题难处理
前文提过,随着企业规模扩大,一种方式是对数据库做分库,做了分库之后,数据迁移(1个库的数据按照一定规则打到2个库中)、跨库join(订单数据里有用户数据,两条数据不在同一个库中)、分布式事务处理都是需要考虑的问题,尤其是分布式事务处理,业界当前都没有特别好的解决方案。
5)表结构扩展不方便
由于数据库存储的是结构化数据,因此表结构Schema是固定的,扩展不方便,如果需要修改表结构,需要执行DDL(Data Definition Language)语句修改,修改期间会导致锁表,部分服务不可用。
6)全文搜索功能弱
例如like "%中国真伟大%",只能搜索到"2019年中国真伟大,爱祖国",无法搜索到"中国真是太伟大了"这样的文本,即不具备分词能力,且like查询在"%中国真伟大"这样的搜索条件下,无法命中索引,将会导致查询效率大大降低。
写了这么多,我的理解核心还是前三点,它反映了关系型数据库在高并发下的能力是有瓶颈的,尤其是写入/更新频繁的情况下,出现瓶颈的结果就是数据库CPU高、SQL执行慢、客户端报数据库连接池不够等错误,因此例如万人秒杀这种场景,我们绝对不可能通过数据库直接去扣减库存。
可能有朋友说,数据库在高并发下的能力有瓶颈,我公司有钱,加CPU、换固态硬盘、继续买服务器加数据库做分库不就好了。
问题是这是一种性价比非常低的方式,花1000万达到的效果,换其他方式可能100万就达到了,不考虑人员、服务器投入产出比的Leader就是个不合格的Leader,且关系型数据库的方式,受限于它本身的特点,可能花了钱都未必能达到想要的效果。
至于什么是花100万就能达到花1000万效果的方式呢?可以继续往下看,这就是我们要说的NoSQL。
四、结合NoSQL的方式做存储的架构演进
像上文分析的,数据库作为一种关系型数据的存储引擎,存储的是关系型数据,它有优点,同时也有明显的缺点,因此通常在企业规模不断扩大的情况下,不会一味指望通过增强数据库的能力来解决数据存储问题,而是会引入其他存储,也就是我们说的NoSQL。
NoSQL的全称为Not Only SQL,泛指非关系型数据库,是对关系型数据库的一种补充,特别注意补充这两个字,这意味着NoSQL与关系型数据库并不是对立关系,二者各有优劣,取长补短,在合适的场景下选择合适的存储引擎才是正确的做法。
比较简单的NoSQL就是缓存:
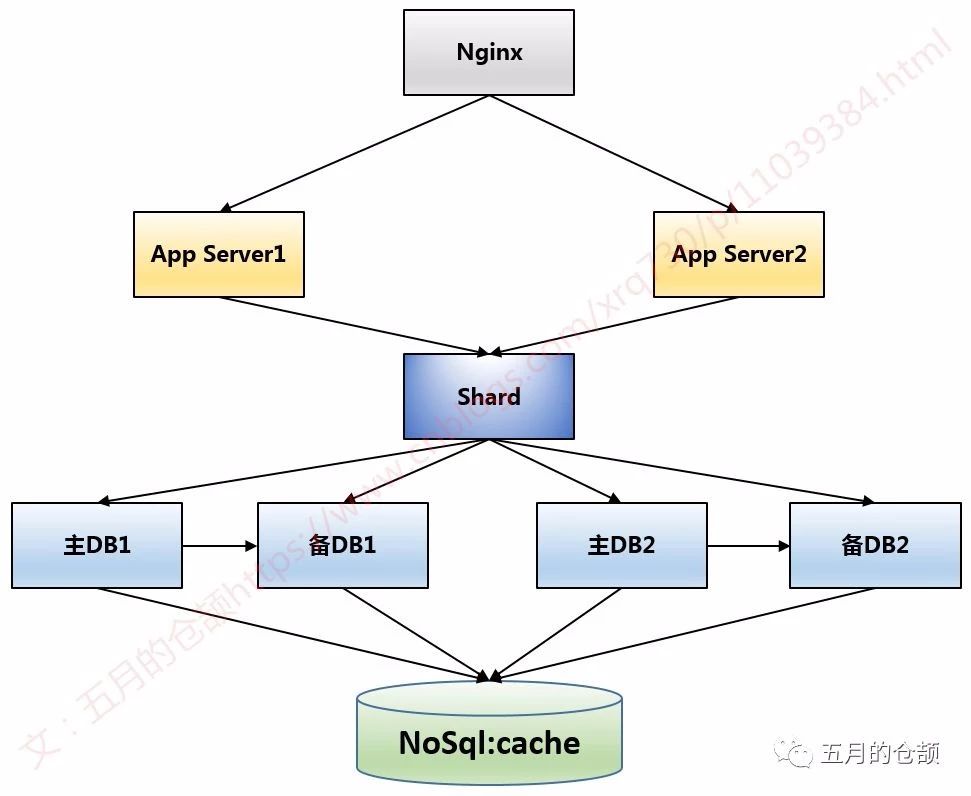
针对那些读远多于写的数据,引入一层缓存,每次读从缓存中读取,缓存中读取不到,再去数据库中取,取完之后再写入到缓存,对数据做好失效机制通常就没有大问题了。通常来说,缓存是性能优化的第一选择也是见效最明显的方案。
但是,缓存通常都是KV型存储且容量有限(基于内存),无法解决所有问题,于是再进一步的优化,我们继续引入其他NoSQL:

数据库、缓存与其他NoSQL并行工作,充分发挥每种NoSQL的特点。当然NoSQL在性能方面大大优于关系型数据库的同时,往往也伴随着一些特性的缺失,比较常见的就是事务功能的缺失。
下面看一下常用的NoSQL及他们的代表产品,并对每种NoSQL的优缺点和适用场景做一下分析,便于熟悉每种NoSQL的特点,方便技术选型。
代表:Redis。KV型NoSQL顾名思义就是以键值对形式存储的非关系型数据库,是最简单、最容易理解也是大家最熟悉的一种NoSQL,因此比较快地带过。Redis、MemCache是其中的代表,Redis又是KV型NoSQL中应用最广泛的NoSQL,KV型数据库以Redis为例,最大的优点我总结下来就两点:
只能根据K查V,无法根据V查K;
查询方式单一,只有KV的方式,不支持条件查询,多条件查询唯一的做法就是数据冗余,但这会极大的浪费存储空间;
内存是有限的,无法支持海量数据存储;
同样的,由于KV型NoSQL的存储是基于内存的,会有丢失数据的风险。
综上所述,KV型NoSQL最合适的场景就是缓存的场景:
文档ID;
在该文档中出现的位置情况。
可以举一反三,我们搜索"Betty Tom"这两个词语也是一样,搜索引擎将"Betty Tom"切分为"Tom"、"Betty"两个单词,根据开发者指定的满足率,比如满足率=50%,那么只要记录中出现了两个单词之一的记录都会被检索出来,再按照匹配度进行展示。
搜索型NoSQL以ElasticSearch为例,它的优点为:
性能全靠内存来顶,也是使用的时候最需要注意的点,非常吃硬件资源、吃内存,大数据量下64G + SSD基本是标配,算得上是数据库中的爱马仕了。为什么要专门提一下内存呢,因为内存这个东西是很值钱的,相同的配置多一倍内存,一个月差不多就要多花几百块钱;
至于ElasticSearch内存用在什么地方,大概有如下这些:
① Indexing Buffer----ElasticSearch基于Luence,Lucene的倒排索引是先在内存里生成,然后定期以Segment File的方式刷磁盘的,每个Segment File实际就是一个完整的倒排索引;
② Segment Memory----倒排索引前面说过是基于关键字的,Lucene在4.0后会将所有关键字以FST这种数据结构的方式将所有关键字在启动的时候全量加载到内存,加快查询速度,官方建议至少留系统一半内存给Lucene;
③各类缓存----Filter Cache、Field Cache、Indexing Cache等,用于提升查询分析性能,例如Filter Cache用于缓存使用过的Filter的结果集;
④ Cluter State Buffer----ElasticSearch被设计为每个Node都可以响应用户请求,因此每个Node的内存中都包含有一份集群状态的拷贝,一个规模很大的集群这个状态信息可能会非常大。
读写之间有延迟,写入的数据差不多1s样子会被读取到,这也正常,写入的时候自动加入这么多索引肯定影响性能;
数据结构灵活性不高,ElasticSearch这个东西,字段一旦建立就没法修改类型了,假如建立的数据表某个字段没有加全文索引,想加上,那么只能把整个表删了再重建。
因此,搜索型NoSQL最适用的场景就是有条件搜索尤其是全文搜索的场景,作为关系型数据库的一种替代方案。
另外,搜索型数据库还有一种特别重要的应用场景。我们可以想,一旦对数据库做了分库分表后,原来可以在单表中做的聚合操作、统计操作是否统统失效?例如我把订单表分16个库,1024张表,那么订单数据就散落在1024张表中,我想要统计昨天浙江省单笔成交金额最高的订单是哪笔如何做?我想要把昨天的所有订单按照时间排序分页展示如何做?这就是文档型NoSQL的另一大作用了,我们可以把分表之后的数据统一打在文档型NoSQL中,利用文档型NoSQL的搜索与聚合能力完成对全量数据的查询。
至于为什么把它放在KV型NoSQL后面作为第二个写呢,因为通常搜索型NoSQL也会作为一层前置缓存,来对关系型数据库进行保护。
代表:HBase。列式NoSQL,大数据时代最具代表性的技术之一了,以HBase为代表。
列式NoSQL是基于列式存储的,那么什么是列式存储呢,列式SQL和关系型数据库一样都有主键的概念,区别在于关系型数据库是按照行组织的数据:
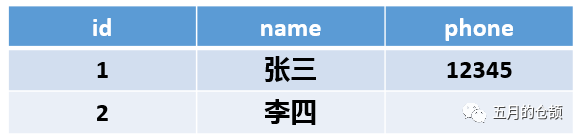
看到每行有name、phone、address三个字段,这是行式存储的方式,且可以观察id = 2的这条数据,即使phone字段没有,它也是占空间的。
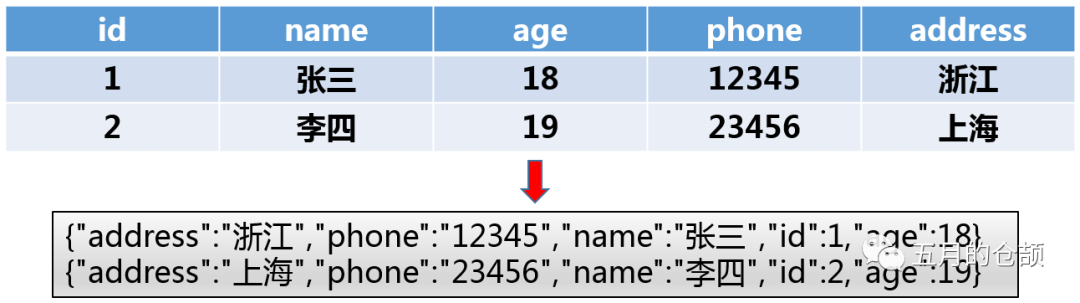
列式存储完全是另一种方式,它是按每一列进行组织的数据:


这么做有什么好处呢?大致有以下几点:
海量数据无限存储,PB级别数据随便存,底层基于HDFS(Hadoop文件系统),数据持久化;
读写性能好,只要没有滥用造成数据热点,读写基本随便玩;
横向扩展在关系型数据库及非关系型数据库中都是最方便的之一,只需要添加新机器就可以实现数据容量的线性增长,且可用在廉价服务器上,节省成本;
本身没有单点故障,可用性高;
可存储结构化或者半结构化的数据;
列数理论上无限,HBase本身只对列族数量有要求,建议1~3个。
说了这么多HBase的优点,又到了说HBase缺点的时候了:
看到,关系型数据库是按部就班地每个字段一列存,在MongDB里面就是一个JSON字符串存储。关系型数据可以为name、phone建立索引,MongoDB使用createIndex命令一样可以为列建立索引,建立索引之后可以大大提升查询效率。其他方面而言,就大的基本概念,二者之间基本也是类似的:
五、数据库与NoSQL及各种NoSQL间的对比
第二点,核心数据不走非关系型数据库,例如用户表、订单表,但是这有一个前提,就是这一类核心数据会有多种查询模式,例如用户表有ABCD四个字段,可能根据AB查,可能根据AC查,可能根据D查,假设核心数据,但是就是个KV形式,比如用户的聊天记录,那么HBase一存就完事了。
接着是第二个问题,如果我们使用非关系型数据库作为存储引擎,那么如何选型?其实上面的文章基本都写了,这里只是做一个总结(所有的缺点都不会体现事务这个点,因为这是所有NoSQL相比关系型数据库共有的一个问题):
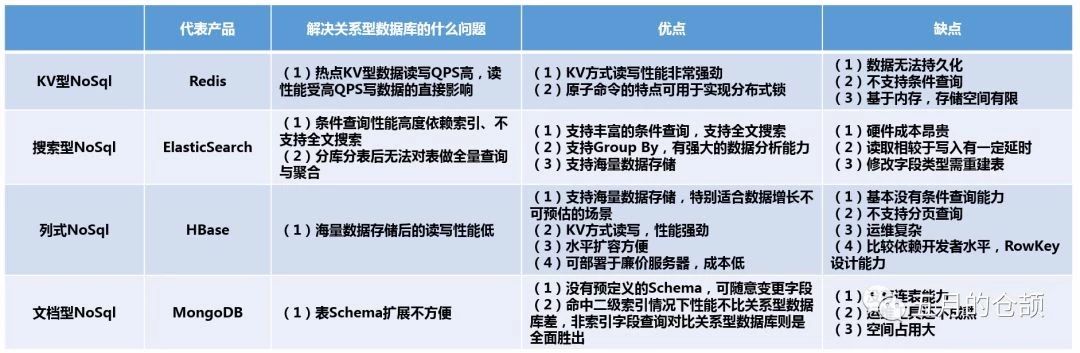
但是这里特别说明,选型一定要结合实际情况而不是照本宣科,比如:
企业发展之初,明明一个关系型数据库就能搞定且支撑一年的架构,搞一套大而全的技术方案出来;
有一些数据条件查询多,更适合使用ElasticSearch做存储降低关系型数据库压力,但是公司成本有限,这种情况下这类数据可以尝试继续使用关系型数据库做存储;
有一类数据格式简单,就是个KV类型且增长量大,但是公司没有HBase这方面的人才,运维上可能会有一定难度,出于实际情况考虑,可先用关系型数据库顶一阵子。
所以,如果不考虑实际情况,虽然合适有些存储引擎更加合适,但是强行使用反而适得其反,总而言之,适合自己的才是最好的。
作者:五月的仓颉
来源:五月的仓颉订阅号(ID:gh_6b7a3f664e7d)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721