
张永翔,现任网易云RDS开发,持续关注MySQL及数据库运维领域,擅长MySQL运维,知乎ID:雁南归。
MySQL 8.0中一个重要的新特性是对Redo Log子系统的重构,通过引入两个新的数据结构recent_written和recent_closed,移除了之前的两个热点锁:log_sys_t::mutex和log_sys_t::flush_order_mutex。
这种无锁化的重构使得不同的线程在写入redo_log_buffer时得以并行写入,但因此带来了log_buffer不再按LSN增长的顺序写入的问题,以及flush_list中的脏页不再严格保证LSN的递增顺序问题。
本文将介绍MySQL 8.0中对log_buffer相关代码的重构,并介绍并发写log_buffer引入问题的解决办法。
一、MySQL Redo Log系统概述
Redo Log又被称为WAL ( Write Ahead Log),是InnoDB存储引擎实现事务持久性的关键。
在InnoDB存储引擎中,事务执行过程被分割成一个个MTR (Mini TRansaction),每个MTR在执行过程中对数据页的更改会产生对应的日志,这个日志就是Redo Log。事务在提交时,只要保证Redo Log被持久化,就可以保证事务的持久化。
由于Redo Log在持久化过程中顺序写文件的特性,使得持久化Redo Log的代价要远远小于持久化数据页,因此通常情况下,数据页的持久化要远落后于Redo Log。
每个Redo Log都有一个对应的序号LSN (Log Sequence Number),同时数据页上也会记录修改了该数据页的Redo Log的LSN,当数据页持久化到磁盘上时,就不再需要这个数据页记录的LSN之前的Redo日志,这个LSN被称作Checkpoint。
当做故障恢复的时候,只需要将Checkpoint之后的Redo Log重新应用一遍,便可得到实例Crash之前未持久化的全部数据页。
InnoDB存储引擎在内存中维护了一个全局的Redo Log Buffer用以缓存对Redo Log的修改,mtr在提交的时候,会将mtr执行过程中产生的本地日志copy到全局Redo Log Buffer中,并将mtr执行过程中修改的数据页(被称做脏页dirty page)加入到一个全局的队列中flush list。
InnoDB存储引擎会根据不同的策略将Redo Log Buffer中的日志落盘,或将flush list中的脏页刷盘并推进Checkpoint。
在脏页落盘以及Checkpoint推进的过程中,需要严格保证Redo日志先落盘再刷脏页的顺序,在MySQL 8之前,InnoDB存储引擎严格的保证MTR写入Redo Log Buffer的顺序是按照LSN递增的顺序,以及flush list中的脏页按LSN递增顺序排序。
在多线程并发写入Redo Log Buffer及flush list时,这一约束是通过两个全局锁log_sys_t::mutex和log_sys_t::flush_order_mutex实现的。
二、MySQL 5.7中MTR的提交过程
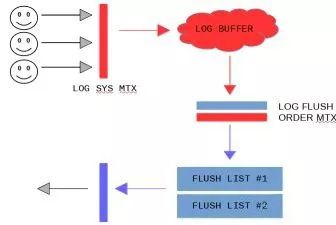
在MySQL 5.7中,Redo Log写入全局的Redo Log Buffer以及将脏页添加到flush list的操作均在mtr的提交阶段中完成,简化后的代码为:

MySQL官方博客中有一张图可以很好的展示了这个过程:
三、MySQL 8中的无锁化设计
从上面的代码中可以看到,在有多个MTR并发提交的时候,实际在这些MTR是串行的完成从本地日志Copy redo到全局Redo Log Buffer以及添加Dirty Page到Flush list的。这里的串行操作就是整个MTR 提交过程的瓶颈,如果这里可以改成并行,想必可以提高MTR的提交效率。
但是串行化的提交可以严格保证Redo Log的连续性以及flush list中Page修改LSN的递增,这两个约束使得将Redo Log和脏页刷入磁盘的行为很简单。只要按顺序将Redo Log Buffer中的内容写入文件,以及按flush list的顺序将脏页刷入表空间,并推进Checkpoint即可。
当MTR不再以串行的方式提交的时候,会导致以下问题需要解决:
MTR串行的copy本地日志到全局Redo Log Buffer可以保证每个MTR的日志在Redo Log Buffer中都是连续的不会分割。当并行copy日志的时候,需要有额外的手段保证mtr的日志copy到Redo Log Buffer后仍然连续。MySQL 8.0中使用一个全局的原子变量log_t::sn在copy数据前为MTR在Redo Log Buffer中预留好需要的位置,这样并行copy数据到Redo Log Buffer时就不会相互干扰。
由于多个MTR并行copy数据到Redo Log Buffer,那必然会有一些MTR copy的快一些,有些MTR copy的比较慢,这时候Redo Log Buffer中可能会有空洞,那么就需要一种方法来确定Redo Log Buffer中的哪些内容可以写入文件。MySQL 8.0中引入了新的数据结构Link_buf解决了这个问题。
并行的添加脏页到flush list会打破flush list中每个数据页对应LSN的单调性约束,如果仍然按flush list中的顺序将脏页落盘,那如何确定Checkpoint的位置?
下面本文将分别讨论以上三个问题:
1、MTR复制日志到Redo Log Buffer的无锁化
在MySQL 8.0中, MTR的提交部分可以用如下伪代码表示:

同5.7的代码相比,最明显的区别就是移除了log_sys->mutex锁和log_sys->flush_order_mutex锁,而实现Redo Log无锁化的关键在于 log_buffer_reserve(*log_sys, len) 这个函数, 其中关键的代码只有两句:
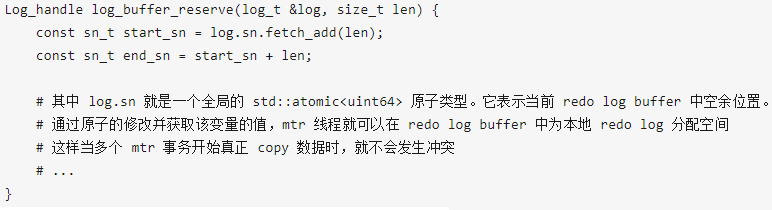
可以看到,这里是通过一个原子操作std::atomic<uint64>.fetch_add(log_len)实现在Copy Redo之前在全局Redo Log Buffer中预分配空间,实现并行写入而不冲突。
2、Log Buffer空洞问题
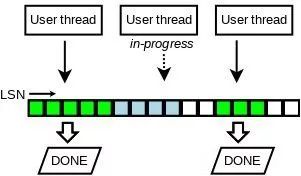
预分配的方式可以使多个MTR不冲突的copy数据到Redo Log Buffer,但由于有些线程快一些,有些线程慢一些,必然会造成Redo Log Buffer的空洞问题,这个使得Redo Log Buffer刷入到磁盘的行为变得复杂。
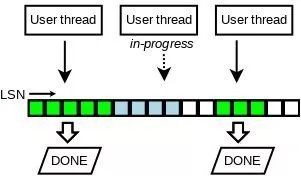
如上图所示,Redo Log Buffer中第一个和第三个线程已经完成了Redo Log的写入,第二个线程正在写入到Redo Log Buffer中,这个时候是不能将三个线程的Redo都落盘的。MySQL 8.0中引入了一个数据结构Link_buf解决这个问题。
Link_buf实际上是一个定长数组,并保证数组的每个元素的更新是原子性的,并以环形的方式复用已经释放的空间。
Link_buf用于辅助表示其他数据结构的使用情况,在Link_buf中,如果一个索引位置i对应的值为非0值n,则表示Link_buf辅助标记的那个数据结构,从i开始后面n个元素已被占用。同时Link_buf内部维护了一个变量M表示当前最大可达的LSN,Link_buf的结构示意图如下所示:
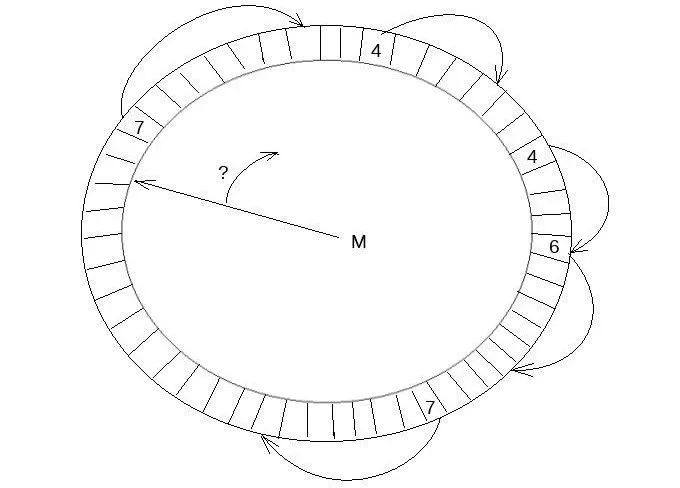
在接口层面,Link_buf实际上定义了3个有效的行为:

Redo Log Buffer内部维护了两个Link_buf类型的变量recent_written和recent_closed来维护Redo Log Buffer和flush list的修改信息。
对于redo log buffer,buffer的使用情况和recent_written的对应关系如下图所示:
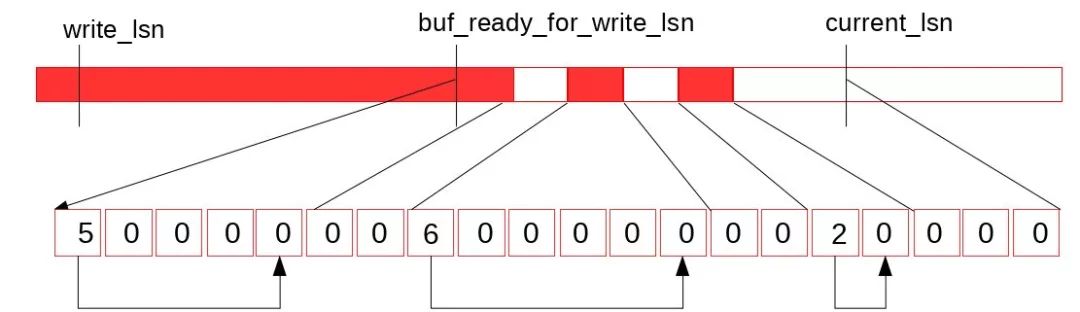
buf_ready_for_write_lsn这个变量维护的是可以保证无空洞的最大LSN值,也就是recent_written->tail()的结果,在这之前的Redo Log都是可以安全的持久化到磁盘上的。
当第一个空洞位置的数据被写入成功后,写入数据的mtr通过调用log.recent_written.add_link(start_lsn, end_lsn)将recent_written内部状态更新为如下图所示的样子:
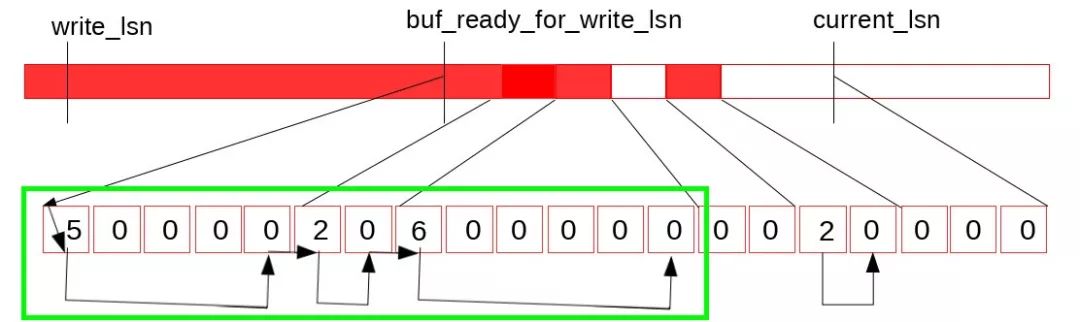
这部分代码在log0log.cc文件的log_buffer_write_completed方法中。
每次修改recent_written后,都会触发一个独立的线程log_writer向后扫描recent_written并更新buf_ready_for_write_lsn 值(调用recent_written->advance_tail()方法)。log_writer线程实际上就是执行日志写入到文件的线程。由log_writer线程扫描后的recent_written变量内部如下图所示:
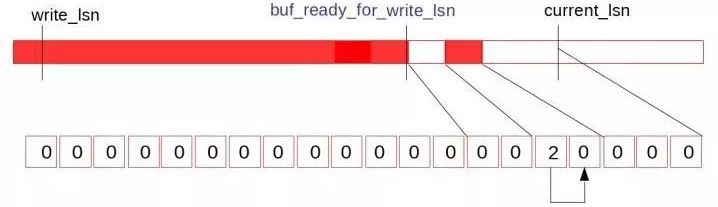
这样就很好的解决了MTR并发写入log_buffer造成的空洞问题。通过新引入的Link_buf类型的数据结构,可用很方便的知道哪一部分的Redo Log可以执行写入磁盘的操作。
关于更多落盘的细节
在MySQL 8中,Redo log的落盘过程交由两个独立的线程完成,分别 log_writer和log_flusher,前者负责将Redo Log Buffer中的数据写入到OS Cache中, 后者负责不停的执行fsync操作将OS Cache中的数据真正的写入到磁盘里。
两个线程通过一个全局的原子变量log_t::write_lsn同步,write_lsn表示当前已经写入到OS Cache的Redo log最大的LSN。
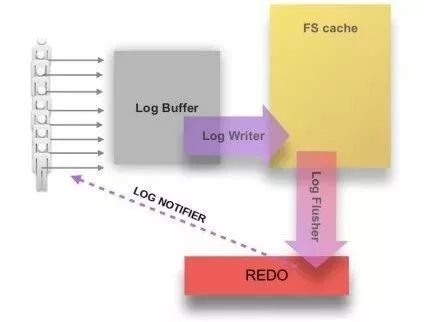
log buffer中的redo log的落盘不需要由用户线程关心,用户线程只需要在事务提交的时候,根据innodb_flush_log_at_trx_commit定义的不同行为,等待log_writer或log_flusher的通知即可。
log_writer线程会在监听到recent_written被修改后,log_buffer中大于log_t::write_lsn小于buf_ready_for_write_lsn的redo log刷入到 OS Cache 中,并更新log_t::write_lsn。
log_flusher线程则在监听到write_lsn更新后调用一次fsync()并更新flushed_to_disk_lsn,该变量保存的是最新fsync到文件的值。
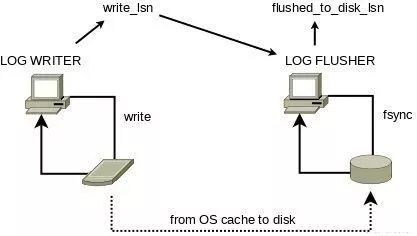
在这种设计模式下,用户线程只负责写日志到log_buffer中,日志的刷新和落盘是完全异步的,根据innodb_flush_log_at_trx_commit定义的不同行为,用户线程在事务提交时需要等待日志写入操作系统缓存或磁盘。
在8.0之前,是由用户线程触发fsync或者等先提交的线程执行fsync( Group Commit行为), 而在MySQL 8.0中,用户线程只需要等待flushed_to_disk_lsn足够大即可。
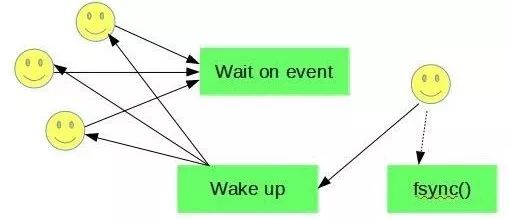
8.0中采用了一个分片的消息队列来通知用户线程,比如用户线程需要等待flushed_to_disk_lsn >= X那么就会加入到X所属的消息队列。分片可以有效降低消息同步损耗及一次需要通知的线程数。
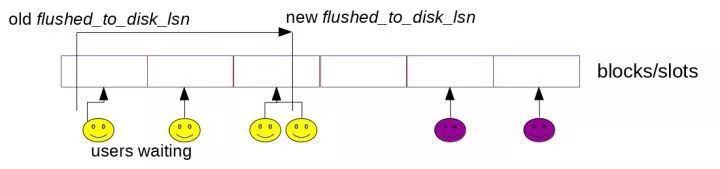
在8.0中,由后台线程log_flush_notifier通知等待的用户线程,用户线程、log_writer、log_flusher、log_flush_notifier四个线程之间的同步关系为。
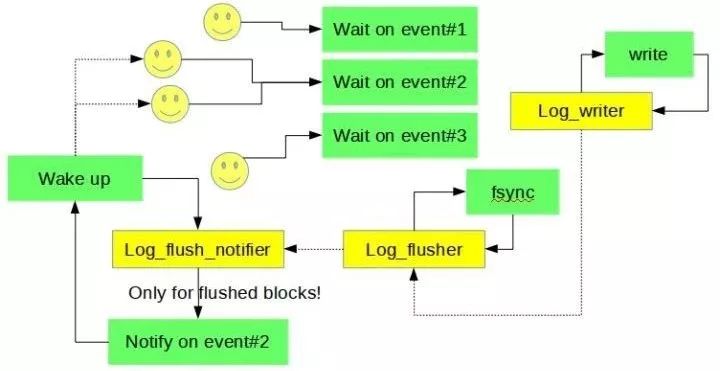
8.0中为了避免用户线程在陷入等待状态后立即被唤醒,用户线程会在等待前做自旋以检查等待条件。8.0中新增加了两个Dynamic Variable: innodb_log_spin_cpu_abs_lwm 和innodb_log_spin_cpu_pct_hwm控制执行自旋操作时CPU的水位,以免自旋操作占用了太多的CPU。
3、flush list 并发控制以及check point 推进
回到上面的MTR提交的代码,可以看到在将Redo Log写入全局的log buffer中以后,mtr立即开始了将脏页加入到flush list的步骤,其过程分为三个函数调用。
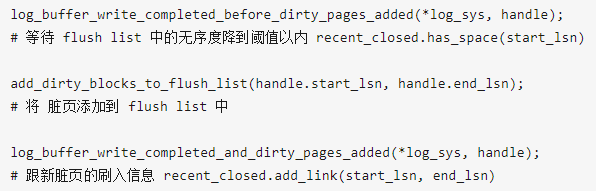
这里同样是通过一个Link_Buf类型的无锁结构recent_closed来跟踪处理flush list并发写入状态。
假设MTR在提交时产生的redo log的范围是[start_lsn, end_lsn],MTR在将这些redo对应的脏页加入到某个flush list后,立即将start_lsn到end_lsn这段标记在recent_closed结构中。recent_closed同样在内部维护了变量M,M对应着一个LSN,表示所有小于该LSN的脏页都加入到了flush list中。
而与redo log写入不同的是,MTR在写入flush list之前,需要等待M值与start_lsn相差不是太多才可以写入。这是为了将flush list上的空洞控制在一个范围之内,这个过程的示意图如下:
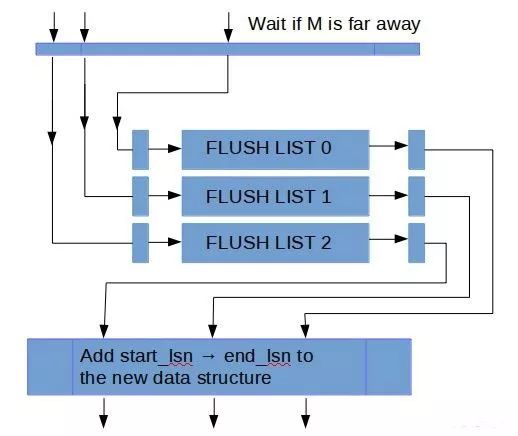
MTR在写入到flush list之前,需要等待M值与start_lsn的相差范围是一个常数L,这个常数度量了flush list中的无序度,它使得checkpoint的确定变得简单(实际代码中,L值就是recent_closed内部容量大小)。
从上面的代码可以看到,在8.0中实际上加入到flush list的行为并不是完全并发的,但也不是5.7中完全串行的,而是被控制到一个范围L之内的并行写入。
由于MTR需要等待条件start_lsn - M < L成立才能加入到flush list , 反过来说,对于flush list中的每个Page ,如果其对应的修改的LSN为Ln,那么可以断定Ln - L对应的Page一定已经加入到了flush list中,而且一定在当前Page之前(因为Page添加时的检查条件Ln-L < M,M之前是无空洞连续的LSN)。
也就是说,在延续原有的按flush list的顺序刷新脏页到磁盘的策略不变的情况下,只需要将Checkpoint的推进由原来的Page对应的LSN改成LSN-L即可。
MySQL 8.0中实际实现的时候,Checkpoint推进仍然是按照Page对应的LSN写入的,只不过Recover的时候从Checkpoint - L开始执行,这两张方式实际上是等效的。
不过在MySQL 8.0中,Recover阶段从Checkpoint - L的地方开始,可能会遇到Checkpoint -L是某个Redo的中间位置而不是开始位置的情况,所以要对一些边界情况做一些额外的工作才行。
四、总结
对于InnoDB存储引擎,Redo Log的处理是实现事务持久性的关键,在MySQL 5.7及以前,通过两个全局锁,实际上使MTR的提交过程串行化保证了RedoLog以及脏页处理的正确性,这使得MTR的提交过程因为锁竞争的缘故无法充分的发挥多核的优势。
8.0中通过引入的Link_buf 数据结构将整个模块变成了Lock_free的模式,必然会带来性能上的提升。
MySQL8.0: 重新设计的日志子系统
MySQL 8.0: New Lock free, scalable WAL design
https://mysqlserverteam.com/mysql-8-0-new-lock-free-scalable-wal-design/
MySQL Source Code Documentation/InnoDB Redo Log
https://dev.mysql.com/doc/dev/mysql-server/8.0.11/PAGE_INNODB_REDO_LOG.html
InnoDB的Redo Log分析
http://www.leviathan.vip/2018/12/15/InnoDB%E7%9A%84Redo-Log%E5%88%86%E6%9E%90/
MySQL · 引擎特性 · WAL那些事儿








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721