
本文根据dbaplus社群第167期线上分享整理而成

2018年,数据库圈子发生了一件趣事:微软在SQL Server 2019预览版中提供了Spark及Hadoop的支持。
参考链接:
https://cloudblogs.microsoft.com/sqlserver/2018/09/24/sql-server-2019-preview-combines-sql-server-and-apache-spark-to-create-a-unified-data-platform/
我们知道SQL Server是一款技术上和商业上都很成功的产品,这一次微软选择拥抱Spark大数据生态,着实令人有些惊讶。国内的几款产品也丝毫不落后,阿里云的DRDS、腾讯云TDSQL也都各自推出了与Spark相融合的产品。
今天我们就来谈一谈,如何在数据库这个老生常谈的话题下,借力Spark给数据库带来新的价值。
一、传统数据库的不足
不用多说,MySQL是互联网企业中使用最广泛的数据库。但是MySQL专注于OLTP能力,对复杂的分析型查询并不在行。为什么这么说呢?
这是由MySQL的整个系统设计决定的,MySQL从最初就被设计为每个请求由单线程来处理。之所以这么设计,是因为OLTP查询大多很简单,SELECT多以点查居多,让一个线程来处理已经足够了。
在后来的改进中,MySQL增加了线程池、高低优先级等等,但是仍未改变其本质:一个线程对应一个查询请求。

对于这样的架构,即使增加机器配置,对提升OLAP查询性能也没什么显著帮助,因为无法利用多核并行的能力。
MySQL之上有很多支持水平拆分的分布式方案,能让数据均匀分摊到多个节点上,从而获得Scale Out的能力。以阿里云DRDS(分布式关系型数据库)为例,DRDS支持分布式事务、平滑扩容、读写分离、权限管理等特性,架构如下图所示:
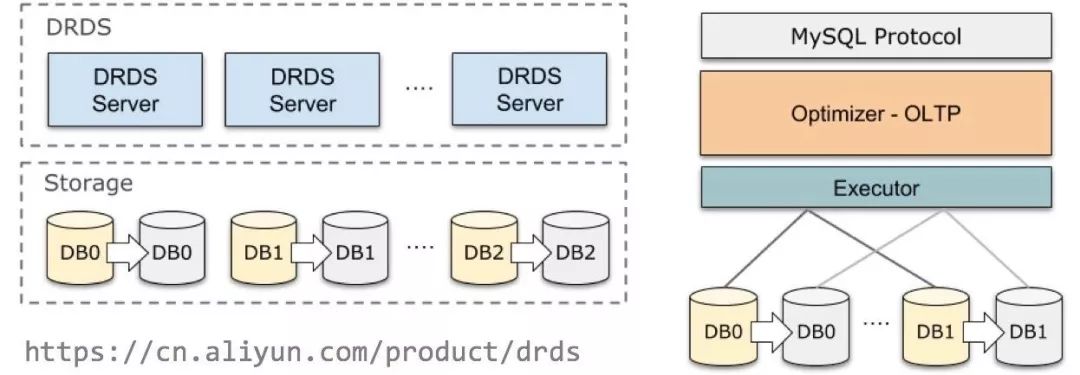
通过合理选择Sharding方式,我们可以在这种架构上比较好地处理一些聚合Join等查询。但是,如果数据量较大,例如遇到难以索引的ad-hoc查询,这一架构同样力不从心。
二、解决OLAP难题
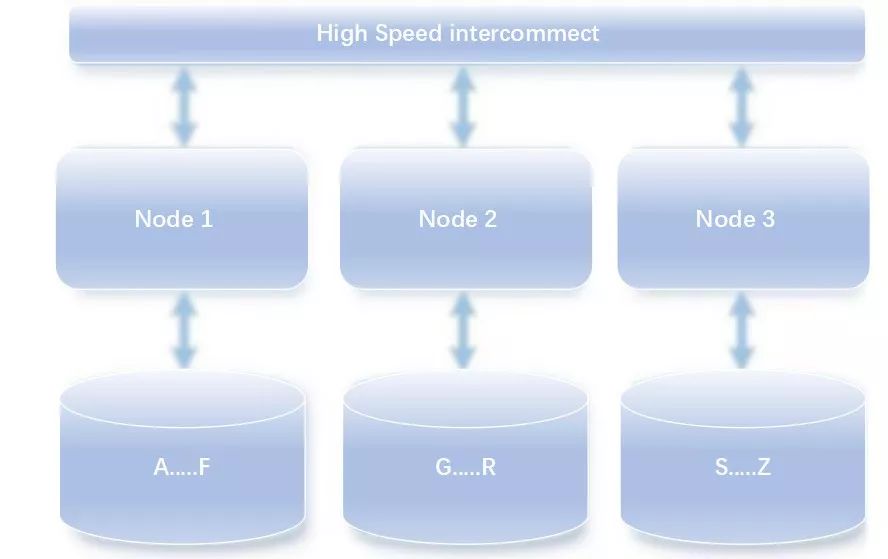
一般解决OLAP有两种思路。最常见的思路是,在业务库之外再拷贝一份数据,搭建数据仓库。大多数数仓都采用分布式MPP架构,MPP全称是Massively Parallel Processing,即大规模并行处理,顾名思义是用多节点并行计算的方式来加速复杂查询计算;另一方面,数仓大多使用share-nothing架构,数据被分片存储到各个节点上:
上面的思路有时也被称为ROLAP,与此相对的,另一种方案是跳出查询本身:MOLAP通过对数据进行预建模来加速查询。例如,我们通常选择时间维度、加上若干个业务维度,对它们的各种组合方式预先做好聚合。
下图就是一个例子:

从(year, item, city)三个维度枚举出8种组合方式,我们对这8种方式的聚合都进行预先计算,这有时也被形象地称为Data Cube。
如果用户查询与预建模匹配,只需要在之前聚合结果的基础上再做计算就行了,显然,查询代价大大减少。MOLAP的典型代表是Apache Kylin。
但很显然,MOLAP所能计算的查询严格受建模方式限制,这让它的门槛大大提高。所以综合来看,使用的不如ROLAP广泛。
三、Spark与Spark SQL
Spark是当下最流行的大数据框架,支持编程接口和声明式(SQL)接口,支持批处理任务和流计算任务。它使用Scala编写,支持Java、Scala、Python等语言的编程接口。
虽然我们常常把Spark归入Hadoop生态系统中,但事实上Spark并不依赖Hadoop,只是因为Spark本身不包含存储,通常和HDFS一起部署搭配使用。
Spark的设计比MapReduce更先进。为什么这么说?
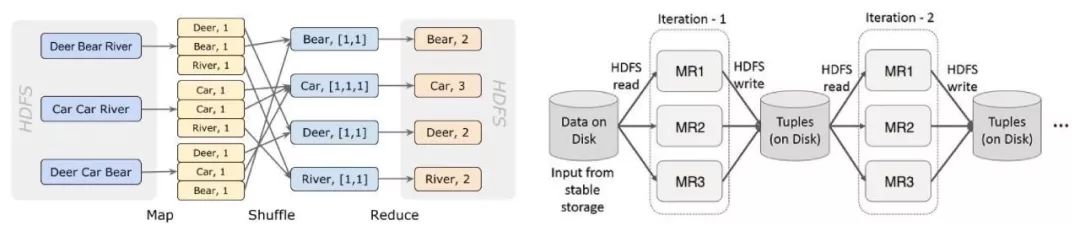
我们回顾一下MapReduce模型:MapReduce处理复杂任务需要分成多个MR Stage,每个Stage都要写入中间结果到HDFS,之后再被下个Stage读出。之所以要持久化中间结果,目的是要达到Worker级的失败容忍,但是这个代价过于大了点。
Spark RDD模型中,则采用另一套失败容忍方案。
Spark假设所有计算都是确定性的,因而也就可以通过重算恢复丢失的分区,避免写HDFS、把数据尽量放在内存,性能得以大大提告。
RDD全称是“弹性分布式数据集”,“分布式”意为每个RDD都包含多个分区、分布在多个节点上;“弹性”意为每个分区都可以容易的被恢复——只要它的依赖方还在,就可以重算来恢复。

Spark的查询计划包中,像filter、map这些算子是可以在分区内部以pipeline的方式执行的;但另一些算子,例如Join,通常需要在Join之前对左右两边的数据都按Join Key做Shuffle,这就导致想要执行Join之前必须等待左右所有数据都完成才能继续。这个点被称为Pipeline-breaker。执行计划中,不可避免地会出现几个Pipeline-breaker,所以就也产生了多个Stage,这和MR有些相似。
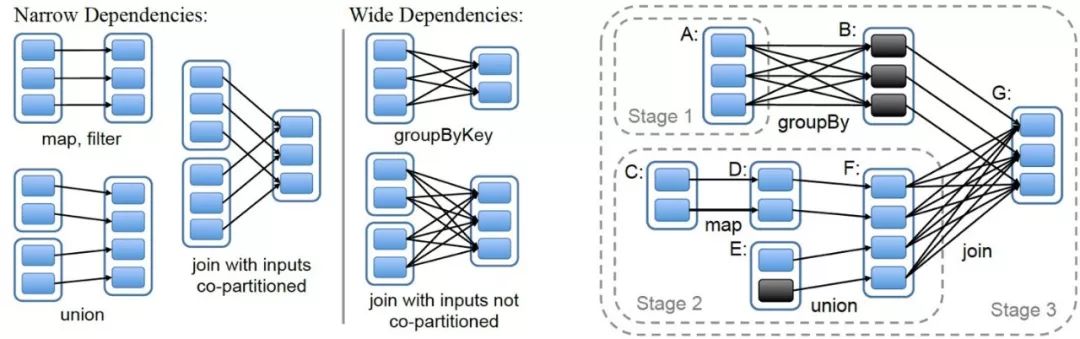
查询执行的时候,我们沿着Stage的依赖关系从左往右计算即可,例如对于上图,先执行Stage 1、Stage 2(二者可以并行),再执行Stage 3。Stage内部则以pipeline方式执行。
Spark SQL则是在Spark RDD API上的二次封装,下图是一段Native API的例子:
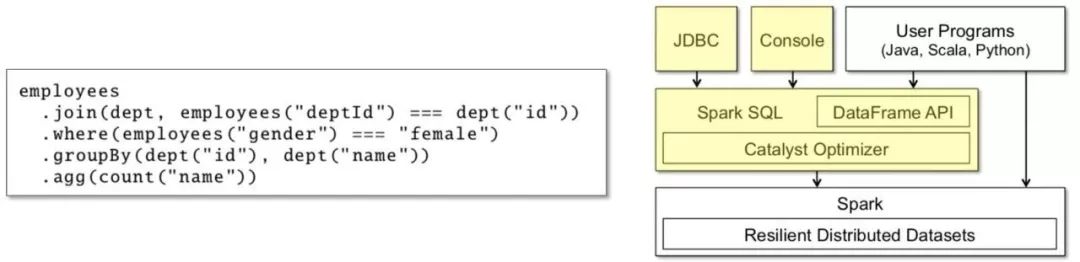
此外也可以直接输入SQL,二者无非是是否经过Parser的区别。
四、为什么用Spark?
之前说到,MySQL那样的架构不足以满足我们对复杂查询的需求。本着透过现象看本质的精神,让我们重新审视一下各种DBMS以及大数据的执行方式,无非是以下几种:
单机执行:以MySQL为代表,这显然不够;
单机并行(SMP):以PostgreSQL为代表,不具备Scale Out能力,也可以排除;
分布式并行(MPP):以数据仓库和各种大数据框架为代表。
其中,MPP又可以根据能否做到Worker级的失败容忍,进一步细分成两种:分布式并行和批处理。这二者之间的性能差异已经很小了,更多的是看其他方面,例如:业务中是否需要做小时级的查询、生态是否完善等。
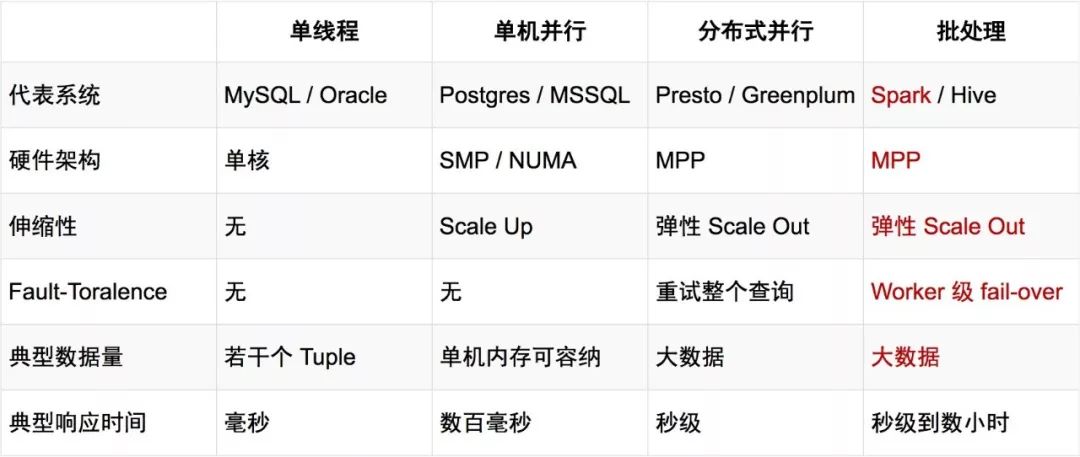
从上表可以看出,Spark SQL足以胜任我们的需求。之所以没有选择Hive等,还有其他一些技术性、非技术性的考虑,不一定是绝对的,在这里也就不引战了。
五、DRDS HTAP的实践
阿里云DRDS只读实例中引入了Fireworks引擎,它是我们基于Apache Spark定制的分布式MPP引擎。
从接口上看,计算方式是对用户透明的,执行引擎自动根据用户输入的SQL来决定是否要进行分布式执行,如果需要分布式执行,则将执行计划下发给Fireworks集群,只需等待计算完成即可。
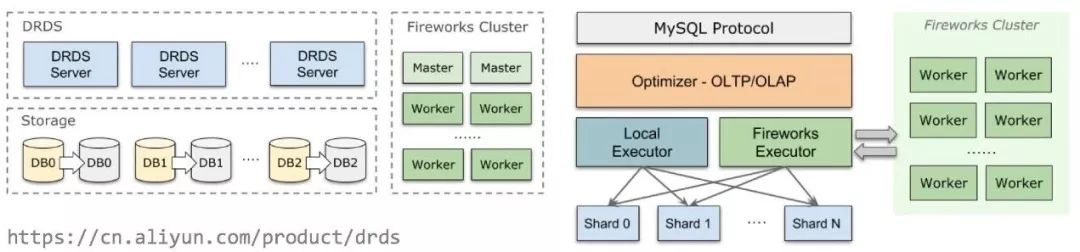
DRDS HTAP并没有引入新的存储,而是利用了数据库本身的备库。不同于ETL等数据Pipeline,数据库主备之间的binlog同步速度非常快,通常在毫秒级别,足以满足绝大部分查询的实时性要求。从备库拉取数据,也是为了保障主库不会增加额外负担、对业务造成影响。
Q:Optimizer这层如果收到复杂查询需要转到Spark计算的话是解析成Spark的logicplan吗?那如何跟Spark对接?
A:我们目前是直接使用的Spark SQL接口,因为不需要侵入到内部。这样可能造成的后果是Spark的优化器会再优化一次。不过我们的执行计划已经很具体了,通常Spark优化后依然和预期一样。
https://m.qlchat.com/topic/details-listening?topicId=2000002309168191&tracePage=liveCenter








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721