作者介绍
刘书浩,中国移动DBA,负责“移动云”业务系统的数据库运维、标准化等工作;擅长MySQL技术领域,熟悉MySQL复制结构、Cluster架构及运维优化;具有自动化运维经验,负责“移动云”数据库管理平台的搭建。
通常来说,性能监控类业务场景具有数据导入量大、表空间增长快的特点,为了避免磁盘空间被占满,并提高SQL执行效率,要定期对历史数据进行清理。根据数据采集频率和保留周期的不同,可在应用程序中植入不同的定时器用于删除历史数据。在业务上线初期,这种简单的定时清理机制是有效的,但随着业务增长,特别是当有数据激增的情况发生时,上述定时器有很大机率会失效,不仅无法清理数据,还会因事务长时间持有表锁,引起数据库阻塞和流控。
下面我就跟大家分享一个因清理机制失效引发数据库故障的案例,并且给出如何通过分区表和存储过程进行数据清理的工程方案。
今年年初我们生产环境曾短暂发生云监控系统故障。经排查故障是由OP应用程序定期在性能库删除数据引起的,具体原因是delete事务过大超出PXC集群同步复制写入集,该事务在本地逻辑提交后,无法在集群另外两个节点同步,最终在本地回滚。因持有表锁时间过长,阻塞大量线程触发System Lock,引起数据库流控,最终导致华北节点云监控数据更新缓慢。
下面介绍下故障排查的过程:
Zabbix发出告警通知:“华北节点OP性能库内存利用率超过80%”,时间为:2018/02/27 06:14:05。
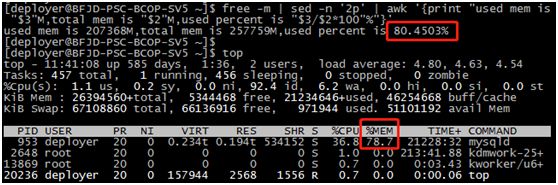
注:OP 是“移动云”门户系统简称;OP性能库用于存放用户订购云产品的性能数据,架构类型为3节点的PXC多主集群架构。
登录数据库查看,发现等待执行的线程数量激增,数据库已处于流控状态。引发数据库阻塞的SQL语句为:
DELETE FROM perf_biz_vm WHERE '2018-02-25 02:00:00'>CREATE_TIME
该语句由OP应用程序发起,用于删除perf_biz_vm表两天前的历史数据,故障发生时执行时间已超过4个小时,看执行计划预计删除2亿行数据。

最终该语句没有执行成功,并引发数据库流控。
这里我们结合Galera Cluster复制原理具体分析一下故障发生的机理。
首先,Galera集群节点间同步复制,主要基于广播write set和事务验证来实现多节点同时commit、冲突事务回滚等功能。
此外,事务在本地节点执行时采取乐观策略,成功广播到所有节点后再做冲突检测,当检测出冲突时,本地事务优先被回滚。如果没有检测到冲突,每个节点将独立、异步去执行队列中的write set。
最后,事务在本地节点执行成功返回客户端后,其他节点保证该事务一定会被执行,Galera复制的架构图如下:

根据Galera复制原理,删除事务在本地节点提交成功时,本地节点把事务通过write set复制到集群另外两个节点,之后各个节点独立异步地进行certification test,由于要删除的数据量非常大,该事务已超过同步复制写入集(生产环境中write set设定值为1G),因此,本地节点无法得到certification信息,事务并没有插入待执行队列进行物理提交,而是在本地优先被回滚。
错误日志如下:

因事务长时间持有perf_bix_vm表的X锁,导致本地节点云主机监控数据无法入库,随着等待线程的累积,本地节点执行队列会越积越长,触发了PXC集群Flow Control机制。
该机制用于保证集群所有节点执行事务的速度大于队列增长速度,从而避免慢节点丢失事务,实现原理是集群中同时只有一个节点可以广播消息,每个节点都会获得广播消息的机会,当慢节点的执行队列超过一定长度后,它会广播一个FC_PAUSE消息,其他节点收到消息后会暂缓广播消息,随着慢节点(本地节点)事务完成回滚,直到该慢节点的执行队列长度减少到一定程度后,Galera集群数据同步又开始恢复,流控解除。
OP性能库发生流控时,本地节点“DELETE FROM perf_biz_vm WHERE '2018-02-25 02:00:00'>CREATE_TIME”语句执行占满了Buffer Pool(即生产环境innodb_buffer_ pool_size=128G),加上数据库本身正常运行占用的内存,使系统内存占用率超过80%预警值,此时打开华北节点OP控制台,可以看到云监控数据更新缓慢:

截止到2月28日,历史数据清理机制失效,导致业务表单表数据量高达250G,数据库存储空间严重不足,急需扩容。为消除数据库安全隐患、释放磁盘空间,我们决定在数据库侧使用分区表+存储过程+事件的方案重建数据清理机制。

通过分析上述故障案例,我们决定基于分区表和存储过程建立一种安全、稳健、高效的数据库清理机制。
通过查看执行计划可以看到,用Delete语句删除数据,即使在命中索引的情况下,执行效率也是很低的,而且容易触发System lock。因此,根本解决大表数据清理问题要引入分区表,删除数据不再执行DML操作,而是直接drop掉早期分区表(DDL)。
因为执行Delete操作时write set记录每行信息,执行drop操作write set只是记录表物理存放位置、表结构以及所依赖的约束、触发器、索引和存储过程等,当表的数据量很大时,采用drop操作要快几个数量级。
分区表的另一个好处是对于应用程序来说不用修改代码,通过对后端数据库进行设置,以表的时间字段做分区字段,就可以轻松实现表的拆分,需要注意的是查询字段必须是分区键,否则会遍历所有的分区表,下面看一下具体的实施过程:
Step 1:首先,创建分区表。在这里我们就以perf_biz_vm表为例,创建相同表结构的新表,并把它命名为perf_biz_vm_new,利用create_time索引字段做分区字段,按天做分区并与主键一起创建联合索引,创建语句:
代码如下:
CREATE TABLE `perf_biz_vm_new` (
`CREATE_TIME` datetime NOT NULL COMMENT '性能采集时间',
`VM_ID` varchar(80) NOT NULL COMMENT '虚拟机ID',
`PROCESSOR_USED` varchar(100) DEFAULT NULL COMMENT 'CPU利用率(%)',
`MEM_USED` varchar(100) DEFAULT NULL COMMENT '内存的使用率(%)',
`MEM_UTILITY` varchar(100) DEFAULT NULL COMMENT '可用内存量(bytes)',
`BYTES_IN` varchar(100) DEFAULT NULL COMMENT '流入流量速率(Mbps)',
`BYTES_OUT` varchar(100) DEFAULT NULL COMMENT '流出流量速率(Mbps)',
`PROC_RUN` varchar(100) DEFAULT NULL COMMENT 'CPU运行队列中进程个数',
`WRITE_IO` varchar(100) DEFAULT NULL COMMENT '虚拟磁盘写入速率(Mb/s)',
`READ_IO` varchar(100) DEFAULT NULL COMMENT '虚拟磁盘读取速率(Mb/s)',
`PID` varchar(36) NOT NULL,
PRIMARY KEY (`PID`,`CREATE_TIME`),
KEY `mytable_categoryid` (`CREATE_TIME`) USING BTREE,
KEY `perf_biz_vm_vm_id_create_time` (`VM_ID`,`CREATE_TIME`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='虚拟机性能采集表'
/*!50500 PARTITION BY RANGE COLUMNS(CREATE_TIME)
(PARTITION p20180225 VALUES LESS THAN ('20180226') ENGINE = InnoDB,
PARTITION p20180226 VALUES LESS THAN ('20180227') ENGINE = InnoDB,
PARTITION p20180227 VALUES LESS THAN ('20180228') ENGINE = InnoDB,
PARTITION p20180228 VALUES LESS THAN ('20180229') ENGINE = InnoDB,
PARTITION p20180229 VALUES LESS THAN ('20180230') ENGINE = InnoDB) */
(上下拖动可见完整代码)
Step 2:用新的分区表替换原有旧表。这里需要注意的是,执行rename操作会对perf_biz_vm表的元数据进行修改,需提前检查有无对此表的Delete、Update、Insert事务与DDL操作,否则冲突会产生元数据锁(Metadata Lock)。
我们的做法是提前将业务侧的定时器停掉,并在业务低谷时执行如下语句,将旧表和新表通过rename的方式互换,让新表纳入使用。期间若有业务调用,则会短暂断开业务。
rename table perf_biz_vm to perf_biz_vm_old;
rename table perf_biz_vm_new to perf_biz_vm;
Step 3:查看到新表有数据写入,云监控页面数据显示正常,说明业务恢复。云主机监控数据的保存周期是两天,因此需要将旧表两天前的数据拷贝到新表,该步骤通过脚本来完成,可参考以下脚本:
代码如下:
#!/bin/bash
function insert(){
end_time="$1 $2"
start_time="$3 $4"
mysql -u'user' -p'passwd' << !
use monitor_alarm_openstack;
set innodb_flush_log_at_trx_commit=0;
start transaction;
insert into perf_biz_vm select * from perf_biz_vm_old where create_time < '$end_time' and create_time > '$start_time';
commit;
select TABLE_ROWS from information_schema.tables where TABLE_SCHEMA ="monitor_alarm" and TABLE_NAME="perf_biz_vm";
!
}
base_time="2018-02-27 2:00:00"
while true
do
#end_time=$(date -d "-1hour $base_time" +%Y-%m-%d" "%H:%M:%S)
end_time=$base_time
start_time=$(date -d "-1hour $end_time" +%Y-%m-%d" "%H:%M:%S)
#base_time=$end_time
base_time=$start_time
echo "Cur_time: $(date +%Y%m%d" "%H%M%S)" | tee -a 1.log
echo "Range: $end_time $start_time" | tee -a 1.log
insert ${end_time} ${start_time} | tee -a 1.log
sleep 2
done
(上下拖动可见完整代码)
Step 4:编写存储过程用于定期创建新的分区,并删除几天前旧的分区:
代码如下:
delimiter $$
CREATE PROCEDURE `clean_partiton`(SCHEMANAME VARCHAR(64), TABLENAME VARCHAR(64),reserve INT)
BEGIN
-- 注:该储存过程适用于分区字段类型为datetime,按天分区且命名为p20180301格式规范的分区表
-- 获取最旧一个分区,判断是否为reserve天前分区,是则进行删除,每次只删除一个分区
-- 提前创建14天分区,判断命名不重复则创建
-- 创建 history_partition 表,varchar(200)和datetime类型。记录执行成功的SQL语句
DECLARE PARTITION_NAMES VARCHAR(16);
DECLARE OLD_PARTITION_NAMES VARCHAR(16);
DECLARE LESS_THAN_TIMES varchar(16);
DECLARE CUR_TIME INT;
DECLARE RETROWS INT;
DECLARE DROP_PARTITION VARCHAR(16);
SET CUR_TIME = DATE_FORMAT(NOW(),'%Y%m%d');
BEGIN
SELECT PARTITION_NAME INTO DROP_PARTITION FROM information_schema.partitions WHERE table_schema = SCHEMANAME AND table_name = TABLENAME order by PARTITION_ORDINAL_POSITION asc limit 1 ;
IF SUBSTRING(DROP_PARTITION,2) < DATE_FORMAT(CUR_TIME - INTERVAL reserve DAY, '%Y%m%d') THEN
SET @sql = CONCAT( 'ALTER TABLE ', SCHEMANAME, '.', TABLENAME, ' drop PARTITION ', DROP_PARTITION, ';' );
PREPARE STMT FROM @sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
INSERT INTO history_partition VALUES (@sql, now());
END IF;
end;
SET @__interval = 1;
create_loop: LOOP
IF @__interval > 15 THEN
LEAVE create_loop;
END IF;
SET LESS_THAN_TIMES = DATE_FORMAT(CUR_TIME + INTERVAL @__interval DAY, '%Y%m%d');
SET PARTITION_NAMES = DATE_FORMAT(CUR_TIME + INTERVAL @__interval -1 DAY, 'p%Y%m%d');
IF(PARTITION_NAMES != OLD_PARTITION_NAMES) THEN
SELECT COUNT(1) INTO RETROWS FROM information_schema.partitions WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND LESS_THAN_TIMES <= substring(partition_description,2,8) ;
IF RETROWS = 0 THEN
SET @sql = CONCAT( 'ALTER TABLE ', SCHEMANAME, '.', TABLENAME, ' ADD PARTITION (PARTITION ', PARTITION_NAMES, ' VALUES LESS THAN ( "',LESS_THAN_TIMES, '" ));' );
PREPARE STMT FROM @sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
INSERT INTO history_partition VALUES (@sql, now());
END IF;
END IF;
SET @__interval=@__interval+1;
SET OLD_PARTITION_NAMES = PARTITION_NAMES;
END LOOP;
END
$$
delimiter ;
(上下拖动可见完整代码)
Step 5:创建名称为clean_perf_biz_vm的事件,并在每天凌晨00:30:00的时候调用clean_partition存储过程创建下一个新分区,并删除两天前的旧分区。
delimiter |
CREATE DEFINER=’root’@’localhost’ event clean_perf_biz_vm on schedule every 1 day starts DATE_ADD(DATE_ADD(CURDATE(),INTERVAL 1 DAY),INTERVAL 30 MINUTE)
ON COMPLETION PRESERVE
do
begin
call clean_partition(‘monitor_alarm’,’perf_biz_vm’,’2’);
end |
delimiter;
Step 6:处理perf_biz_vm_old旧表,在业务低谷期执行如下操作:drop table if exists perf_biz_vm_old,Drop掉整张旧表的时间约为3min,并释放了150G的磁盘空间。需要注意的是,虽然drop table的时间较短,仍会产生短暂的阻塞,因为drop table触发的是实例锁,因此需要在业务低谷期进行操作,并实时观察数据库情况。

从下图可以看到,实际drop过程中记录到的等待接收队列的长度瞬时值为169,最高达到202:
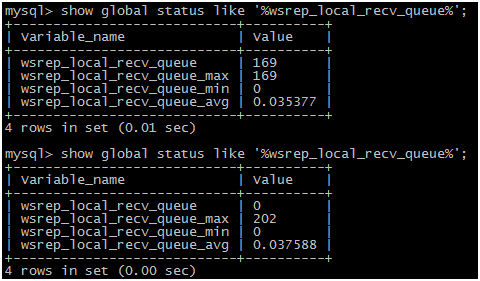
至此,改造全部完成,我们已在数据库侧建立起安全、稳健、高效的数据清理机制。
虽然本方案强调了存储过程的使用,但上述存储过程是基于简单的create和drop操作,并没有涉及复杂的逻辑和计算。MySQL是OLTP应用,最擅长的还是增、删、查、改这样简单的操作,对逻辑计算分析类的应用并不适合,所以尽量避免使用复杂的存储过程。
当然,也并不是所有场景都适合使用分区表,在很多DBA看来分区表在某些场景下是禁止使用的,一般会采用切表的形式进行拆分,本方案中使用时间做分区字段,应用程序中查询语句基本都能命中分区,对于Select、Insert等语句的执行性能是有所提升的。
以上是关于数据清理做的一些分享,更多内容请继续关注dbaplus社群后续文章!









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721