
本文根据DBAplus社群〖2018年1月6日北京开源与架构技术沙龙〗现场演讲内容整理而成。点击文末【链接】还能下载PPT哦~
分享大纲:
1.MySQL性能管理需求与现状
2.MySQL性能分析建设
1、数据库管理的现实需求
MySQL性能管理的现实需求很直观,我们现在大部分的客户都是在传统企业,而传统企业这几年向MySQL转型也是非常迅猛的。
所以用传统的商用数据库建设MySQL时就会发生一些很头疼的问题,比如:如何让少量的DBA管理大量的数据库?如何通过简单的方式改善和优化数据库性能问题?如何持续保障数据库的连续性和稳定性?...

一个极大的风险点在于MySQL的性能数据难铺展开回溯。MySQL性能数据的特点是比较依赖实时分析或执行分析,事后能得到的信息较少,也很难下钻下去。当少量DBA管理大量数据库时,出现问题只能通过高可用手段快速处理保障可用。但缺乏充足信息的回溯手段,往往只能在执行时间,锁定时间等少数几个维度分析问题SQL的影响程度,其覆盖面难以包括大部分SQL语句的影响层面,这在很多运维环境上看来,缺乏事后分析手段,都是存在极大风险的。
在这个方面我们需要基于MySQL目前已有的分析手段去做改进,让MySQL具备它原本不具备的性能信息增量记录的能力,并在这个基础上实现关联与下钻分析,便于快速定位到数据库性能问题。
2、传统MySQL性能管理手段的限制
从传统上来说,MySQL性能分析的特点是实时执行、分析手段多样,事后分析主要依赖Slow日志。
人工做问题分析,一般需要借助PT工具(Percona Toolkit)生成时段内慢语句报告,它能得到一些时段内的慢语句情况。但这并不能把PT工具生成报告跟原本在某一时段内的数据库性能的整体状态做一个关联。
假设出现了一个性能问题引起的数据库宕机故障,因为存储在数据库内的状态信息P_S信息在重启后都丢失了,那我们可以借助的手段只有日志分析和监控平台的状态指标分析。事实上这是一个比较头痛的过程,因为这些分析难以关联、精确定位到造成问题的原因。
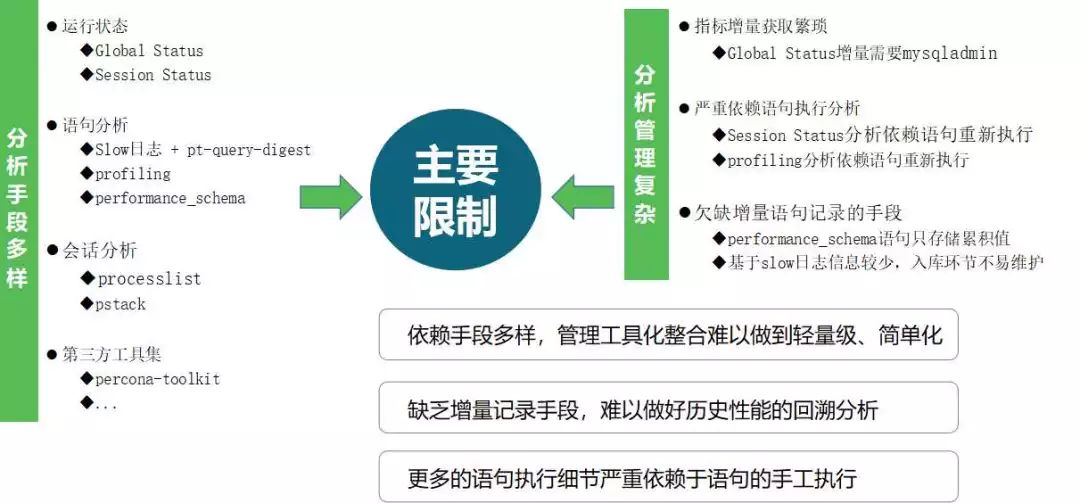
另一方面,如果要将这些多样化的分析手段都产品化,那对我们来说一定是一个稳定性、可用性非常差的选择。
因此,从简单即运维这个观点出发,站在产品化的角度面对不同的用户时,要尽量减少现场为了适应产品接入而进行的变更,同时还要能够提供最关键的关联与下钻分析功能。上述提到的这些点都是我们做设计的过程中一致考虑的问题。
3、优化MySQL性能管理的思考
谁都希望实现的工具是轻量化的,不需要做太多改造就可以接入。性能管理的需求分析起来可归结为三点:
第一是轻量化采集,即接入数据库并拿到数据库性能信息。常规的分析手段都是用一种形式,但其实用非侵入手段会更好。什么叫非侵入手段?就是直接给工具提供一个账号和相应的权限,然后工具就能通过接入数据库采集响应的信息来避免Agent,这样就能尽量避免自动化采集过程中对目标端的性能影响和风险。

第二是增量化记录:状态增标、语句信息实现增量化记录,使性能管理具备丰富的时段展示手段和历史回溯手段。
第三是经验沉淀:沉淀MySQL性能分析经验的重点在于沉淀指标关联,下钻到问题语句分析过程。整个分析过程很简单,重点在于提供给用户在使用层面中哪些指标是需要关联的、哪些指标是可以帮助我们进一步下钻的,这样就可以把分析的逻辑清晰化,也可以解决很多问题。
下图是在MySQL做性能分析里要去关联下钻的总体思路。从图中可以看出,展示层就是性能入口。我们应该选取少量小而简单的性能指标来作为它的问题点上浮。

后面是通过性能上浮的指标来提供一系列对比的手段进行分解,同时还能做到指标间的对比、指标和语句的关联。最后根据突出的性能指标下钻到语句,并确认语句的执行形态是否造成了性能的风险。
能做到这层指标关联与下钻,主要在于数据库中对语句执行性能信息的丰富程度远远大于日志记录的信息,再将语句执行记录的信息与数据库相关的状态信息进行关联,这样就更容易分析到语句执行对性能的影响了。
1、性能入口
(1)选取适当的上浮核心指标
如何选取上浮的核心指标,其实质是怎样去评估一套数据库的总体性能,这里主要包括两个内容:一是数据库负载如何、效率怎么样,二则是这里面有性能问题的程度到底如何。
传统上大部分DBA喜欢选择QPS作为这样的指标,在我们分析其意义,可以发现QPS并不能完全代表数据库的性能状态。QPS是纯粹的每秒查询数、执行数,能直观看到每秒钟有多少操作量,简单计算便能知道哪个数据库会更繁忙一些。
但如果把它放在衡量性能状态的层面,每一个操作会有操作的响应时间,需要同时关注操作数与响应时间才能反映真实的性能压力,而操作系统的对应负载就应该是操作数与操作时间的总数。
这里不难得到一个时段负载的公式,为“Load=QPS * avg_Latency(平均响应时间) * time(时间)”。但计算后会发现它的值与操作系统的Load对应不上,往往响应时间越大,系统压力会越大,负载值就越高。

在这种情况下,我们可以确认它其实有很多慢响应的时间,但在我们每一分钟采集一次的过程中,在采集点的前后有一些语句并没有被执行完成,而等到执行完以后,这些语句才会被计算QPS。所以如果在你采集的过程中有大量的慢语句,那这部分没有执行完成的语句就被遗漏了,若仍然使用上面的负载公式计算,那么慢语句越多,时段负载与OS统计的负载值就相差越大。
这时我们可以引入一个概念:AS/PS,它表示平均每秒执行语句的总负载。它引入了执行中语句时间增长统计,修正了单纯计算短查询负载的误差,通过验证,明确了通过在数据库层面的AS/PS总繁忙度计算,能够与主机层面统计的系统负载构成关联。有了数据库与系统的这一层的联系,再进行主机资源与数据库指标的关联分析,就变得有意思起来了。
当系统负载升高时,我们能很清晰地分解出到底是哪个数据库实例推高了负载,可以进一步得知是短查询暴增还是出现慢语句而影响了负载,再进一步得知到底是被谁触发了或者到底是哪个语句造成的,这些我们都能够根据这个思路一一查出。引入这个指标,还可以在这个维度上解决数据库上浮的问题。
另外一个思路是直观地根据响应时间评分上浮来明确最应该关注哪个节点。MySQL官方推出的Enterprise Monitor工具提出的QRTi,其实就是面向这一思路。
它实际是用一种评分的标准,我们可以设置一个可接受和不可接受的慢查询时限,其中默认设置为100-400毫秒之间,小于100毫秒查询记为1分,100-400毫秒之间的查询在可接受范围之内的为0.5分,大于400毫秒不在接受的范围之内为0分,根据执行次数计算平均值,再乘以百分比,得到了QRTi的结果值。那么显而易见,百分比越高就说明这里面的响应层级越好,而百分比下降就说明这里面有更多慢响应。
通过这两个维度,一是它对系统造成的负载压力大小,二是它实际上有多少个慢响应,就可以很快评估出这个数据库里哪些是值得你关注的。根据经验所能得到的很多情况是,最值得关注的不是QPS最高的数据库,反而是繁忙度升高、响应度变差的数据库,而且一般繁忙度升高往往伴随响应度降低,QPS也会随之降低。
(2)指标特点对比
下图列出了QPS、AS/PS、和QRTi的指标特点和优劣势的对比。

一般而言,当选择做整个性能评估或性能入口的点时,DBA会比较认可传统段的QPS,并通过其来接触数据库或者评估它的操作总量。从劣势来看,QPS不能直观横向比较数据库性能问题。
而AS/PS的劣势在于并不直接与数据库状态指标等同,而优势是与数据库的运行性能关联度高,能作为关联与下钻过程的关键指标。而QRTi仅能衡量慢查询程度,并不直观反映性能情况,但根据它能直接下钻问题SQL。
2、关联分析:提供多种场景的分析通路
有了入口指标后,它就可以为我们提供多种场景的分析通路,如指标分解、指标语句关联、指标对比和时段执行回溯。
(1)指标分解
分解获取性能指标的构成详情
场景举例:分解AS/PS,发现opening table占比较多

上图是我对AS/PS做的分解,其中红色部分是大量的短查询语句,根据绝对值来说这是一个繁忙度能达到400%的相当繁忙的数据库,很多短查询语句都是在时段内完成的,但仍然有一些语句属于慢等待。这就证明这里面其实有很多语句的响应时限在我们的采集范围间隔之外了,也就是说,如果我现在采集的间隔是1分钟一次,那很多语句的响应时限间隔是大于5秒、10秒甚至1分钟的,那我们很自然地就会关注这一部分还有没有执行耗时很高的情况。
(2)指标语句关联
提供性能指标关联到语句的分析通路
场景举例:
通过临时表创建率高定位到创建临时表的语句
发现时段内bytes较高,关联到rows_sent高的语句
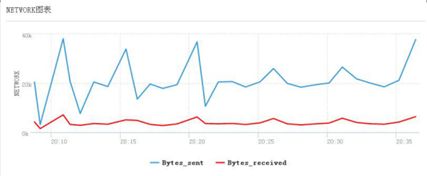
上图中展示的是Bytes_sents系统状态指标,这里可以与采集到的语句Rows Snet相关联,能够直观地关联到具体哪些语句的返回量过高,推高了整个数据库网络发送。
(3)指标对比
选取不同性能指标按维度进行对比
对比方式:
同库不同指标间对比:对比Com_delete与Innodb_rows_deletedu
异同库相关指标对比:对比不同库的innodb buffer pool命中率
同库不同时段指标对比:对于语句优化后临时表创建改善情况
在分析过程中也会普遍存在指标对比的需求。
第一个场景发生在同一个数据库内。假如我希望知道这套数据库里有没有一些大批量的删除操作和以及这些操作的比例,那只需要拿Com_delete与Innodb_row_delete关联在一起,确认一个删除操作到底对应多少行的删除。如果这个数非常大,那其实也会存在一些风险。
第二个场景发生在不同库之间。比如你知道很多库都有性能问题,但到底哪些库的受性能指标影响更深呢?那就可以把对应的指标拿出来作对比。
第三个场景是时段的对比。我们会在很多时候发起一些专门优化的周期,而优化周期前后是性能对比,所以可能调整过的语句、前面语句和后面的语句不能一一对应,这时我们也可以做一些对比,很明确的是,此时这个数据库的性能已经得到了优化。
需要指出,指标和语句的关联其实是这里面整个下钻过程中的核心,传统的分析手段里只能分别得到指标、语句,没有办法把它们关联起来。在传统情况下,如果一个数据库出了问题,我们可以根据慢日志看到其中很多查询时间长的语句是什么、最早产生的语句是什么,认为这部分就是对它性能影响最大的语句,这其实是靠经验推测的一个处理方法。
但如果做到状态指标跟语句的关联,我们通过问题指标的上浮,可以马上下钻到相关的风险语句,就可以节省分析时间,还可以通过造成的系统负载来判断不同语句对系统造成的问题的影响度。
(4)时段执行回溯
提供历史时段内的指标和语句回溯
场景举例:回顾过去故障时段的语句执行情况
状态指标差值计算比较简单,比如按采集周期在30秒或1分钟间取值再计算差值,这样的采集方式很多工具都支持。比较麻烦的是,语句的差值计算可能会存在一些特别的情况,很多语句是周期性执行的,可能这一分钟有查询,下一分钟没有,再下一分钟又有,这时你如果只是简单地做两个时间周期的差值是不合适的,需要特别处理采集间隔过大的情况。
还有一种情况就是数据库做了一些重启的操作,其中部分存储的信息可能遗失了,你在第一次获取时就会得到一个负的差值,这些值也需要特别处理。
我们设计时做了一个语句索引表,因为里面的ID是唯一的,即便是同一条语句在不同的库里也无妨,只要记录了它曾经出现、最近出现的两次数据,这样的设计能较快定位到语句,也比较省存储空间。
3、 问题点定位:提供更丰富的语句信息
最后讲讲我们到底可以做多少针对语句的性能下钻分析场景。
语句执行性能的采集来源是基于Performance_schema,下面的列表中体现了这一系列的语句执行信息包括的维度,这些维度都能关联数据库状态指标进行分析。

但比较不好的一点在于它是以语句的模板形式进行存储的,无论where条件变量是等于1、2、还是3,它仍然是一个模板,需要去专门获取语句的样例。有了语句的样子,特别是特定时段的样例,就能很好地针对性分析语句执行计划等执行信息。
4、围绕性能管理的其它拓展
这样的性能管理其实还有很多扩展,尤其是我刚提到的SQL样例。针对语句的样例,我们可以对语句做一些语法上的分析,把对SQL规范语法审核引入,又能在上线环节很好地做好应用变更的管控,即审核应该调整那些不合规的应用新增语句,才允许上线。
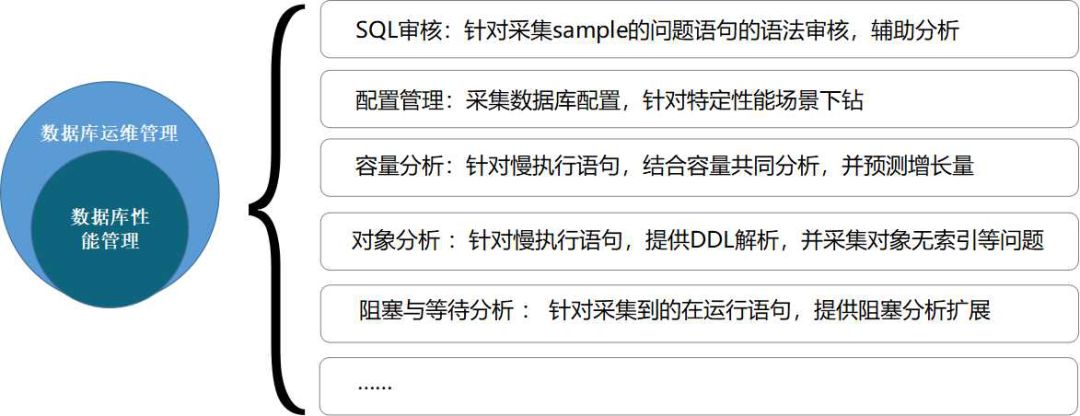
往往我们还会发现,很多造成数据库性能问题的点不仅仅是由于慢语句本身造成的,而是比如由配置不合理等产生,也有可能涉及到表对象本身的容量、碎片过多或者是由于对象存在外键、无索引、甚至无主键等情况,这些因素的监控也可以一并考虑。
这种基于性能本身的管理可以围绕起来做很多事情,希望能从性能管理的点最终扩展到数据库管理、数据库运维的整个面上来。
问题分析的过程,包括本文所关注的性能分析过程,往往是一个通过工具,结合经验的沉淀过程。分析问题的手段多种多样,而沉淀的经验是可以复制,可以被固化的。在这里,分享我们沉淀在产品中的分析经验与方法论,同样是希望与大家探讨一个把MySQL中的原理与使用实践相结合的思路。
将问题分析的过程自动化甚至智能化,在数据库运维中这是极具挑战的一环。而在数据库运维经验沉淀的产品化道路上,我们一直在不断探索。我们在努力锻造的正是这样一款支持主流Oracle、MySQL、SQL Server和DB2各版本数据库,具备数据库的专业监控、运维、性能管理,SQL审核等场景的专业数据库运维管理平台。
最后,容许我打个小广告,简单展示一下:








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721