
作者介绍
陶政,游族网络平台部MySQL DBA负责人。曾任同程旅游系统架构组DBA,现负责游族网络数据库整体的运维规划和设计。熟悉各类业务的数据库设计、缓存设计、离线数据分析等解决方案。
2017 年初,公司用户中心体系面临迭代和重构,当时数据库有数亿多的核心数据通过 HashKey 分为了 1024 张表在 64 个数据库中来存储,使用自研的代码框架来进行对应 HashKey 的 seek 操作。
这时,非 HashKey 的查询、DDL 变更等业务需求、分表分库逻辑代码框架的局限让研发和运维都面临较高的数据库使用成本,数据库不能灵活高效的支撑业务需求。

图1:分库分表方案架构图
为了解决上述问题,我们的技术团队急需一套同时满足如下的条件的数据库分布式集群:
能够提供实时的 OLTP 的一致性数据存储服务;
弹性的分布式架构;
配套的监控备份方案;
稳定的高可用性;
较低的迁移重构成本。
最开始先考察了几个方案,但都有相对来说的不足:
将整个分表分库逻辑剥离到开源分表分库中间件上:
基于 2PC 的 XA 弱事务的一致性保证不尽如人意
高可用架构更加复杂,单分片的局部不可用会对全局产生影响
备份恢复的复杂度高
这些方案引入了新的 sharding key 和 join key 的设计问题,整体的迁移难度不降反升
官方的 MySQL Cluster 集群:
NDB 引擎不同于 InnoDB,需要修改表引擎,且实际使用效果未知
NDB的高可用有脑裂风险
监控备份的方案需要另作整理
国内生产用例不多、资料缺乏,非企业版运维流程复杂
机缘巧合下,我们发现NewSQL特性可以提供很好的支持,于是受 Google Spanner 的论文启发设计而来的开源分布式 NewSQL 数据库 TiDB 进入了我们的视线,它具备如下 NewSQL 特性:
SQL支持 (TiDB 是 MySQL 兼容的)
水平线性弹性扩展
分布式事务
跨数据中心数据强一致性保证
故障自恢复的高可用
海量数据高并发写入及实时查询(HTAP 混合负载)
所以说,上述的特点非常契合目前我们在数据库应用设计上碰到的问题。经过评估,我们开始着手安排部署和测试,在备份、监控、故障恢复和扩展几个方面有以下的一些心得:
官方提供了一套基于 mydumper 和 myloader 的工具套件,是基于逻辑备份的方式,对于迁移来说是很便捷的;
监控用的是应用内置上报 Prometheus 的方案,可以写脚本与自有的监控系统对接;
有状态的KV层采用的是 Raft 协议来保证高可用,Leader 的选举机制满足了故障自恢复的需求;
无状态的 TiDB-Server 查询层可以在前段搭建LVS 或HAProxy来保证故障的切换;
KV 层的 Region 分裂保证了集群无感知的扩展。
测试之后发现数据库运维中比较重要的几项都已经闭环的解决了,但有得有失,实测结论是:
TiDB 是分布式结构,有网络以及多副本开销,导致 Sysbench OLTP 测试中 单 server 的读性能不如 MySQL,但在大数据量下性能相较于MySQL不会产生明显下滑,且弹性扩展能力评估后可以满足业务的峰值需求;
TiDB 的 OLAP 能力在大数据量下优于 MySQL,且能看到持续的大幅提升;
由于 TiDB-Server 是无状态的,后续可以添加 Load Balance 来扩展 Server 层的支撑。
在性能和需求满足的前提下,我们开始着手业务层的接入和改造,因为兼容MySQL 协议,所以迁移成本大大降低,同时 TiDB 官方也提供的工具 Syncer ,部分迁移在业务层就是一次 MySQL 的主从切换。
于是用户积分系统的扩展便不再采用分表分库的方案,分表逻辑回归到多个独立的单表,数亿的数据在 OLTP 的业务场景下表现十分出色,没有 sharding key 的约束后,整个使用逻辑在上层看来和 MySQL 单表没有不同,更加灵活的索引也提供了一部分低开销的 OLAP 的查询能力,总体来说,整体的迁移改造流程比较顺利,业务契合度也很高。
随着上述系统的成功应用后,后面符合场景的 OLTP 项目也开始逐渐使用,当然在和业务结合的过程中也需要一些定制和改造,主要涉及登录态系统、补包码系统、用户轨迹项目和存储层。
登录态系统:原先是在 MySQL 采用 Replace 保留最后一条数据,而迁移到NewSQL 的模式后,由于表的伸缩能力获得了很大的提升,故将 Replace 改为了 Insert 保留了所有的登录情况,单表数据量十亿以上,业务上支持了更多维度的记录,没有碰到性能和扩展性问题。
礼包码系统:礼包码的主流程为复杂度 O(1) 的 hash seek OLTP业务,经过改造后,将原来的 100 个表的分表模式集中成单表归档式管理,单表数据预计会达到 20 亿+。
用户轨迹项目:数据库弹性能力增长后的新需求,一些重要的用户行为数据的记录。
在KV存储层没有瓶颈时,采用复用了集群的KV 层的策略,在无状态的 Server 层做了业务隔离,间接的提升了整个集群的使用率,类似一个 DBaaS 的服务。如下图所示:
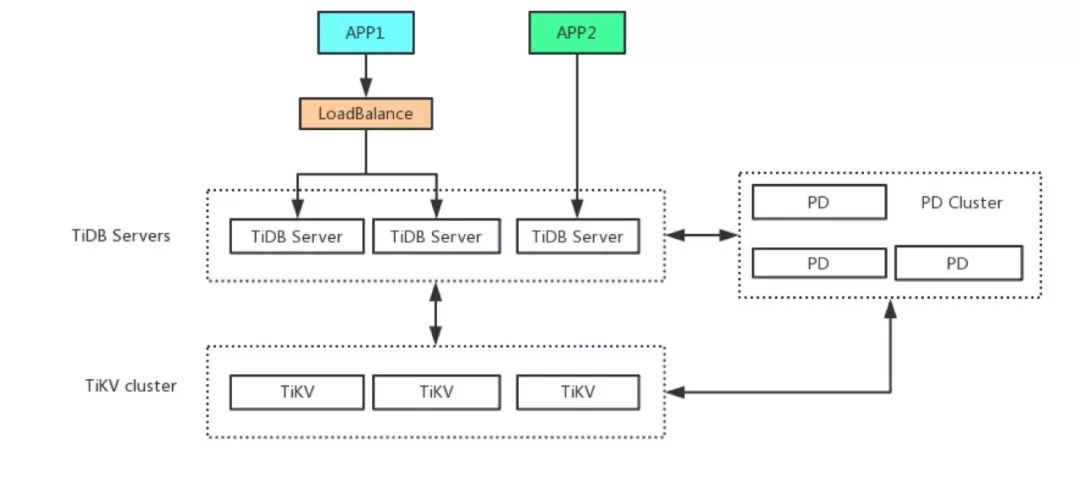
图2:多套业务系统 TiDB 部署图
从 RC2.2 版本到 GA1.0,游族平台部的生产环境已经有 3 套 TiDB 集群在运行,共计支撑了 6 个 OLTP 业务的稳定运行快一年的时间。 期间在集群部署策略、BUG 响应和修复、升级方案协助、迁移工具方面,厂商和开源社区都可以给予全面的支持。在后期对于分析型的需求上,我们也会尝试使用重 OLAP 需求的 TiSpark 计算层。
NewSQL给了大库大表业务一个全新的选择方向,相信以后能在更多的业务选型和设计方案上给出新的思路和方向。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721