
作者介绍
田冬雪,美团点评数据库架构师,7年数据库自动化运维经验。目前负责美团点评基础技术研究、数据库高可用架构优化、数据库运维自动化推进,美团点评工具平台融合等。
作为综合性多业务的“互联网+生活服务”平台,美团点评对数据库的稳定运行有较高的要求,小概率的性能抖动(包括慢SQL)都会造成一定的可用性损失。本文将从过去几年遇到的一些性能问题中,挑选了一个较为棘手的案例,探究端到端数据库性能问题的解决思路,为DBA同学在解决类似问题时提供一种参考。
在一段时间内不断有开发同学反馈,线上应用程序获取数据超时,通过CAT监控系统发现这些应用的SQL 99line都比较高,这在一定程度上影响了对应业务的QoS,比如达不到99.99%的业务可用性(超时被定义为不可用)。这些问题出现在很多业务场景中,是一个普遍性问题。
通过CAT监控系统、SQL样本、慢查询系统等进一步了解,发现这类SQL有如下特征:
基本上都是以主键或唯一键为条件的简单查询,查询后的结果集及扫描的行数都比较小;
查询的表的数据总量也很小,最小的表甚至只有几千行;
时间达到了几百ms,甚至1s;
数据库的slow log里没有记录这类SQL。
下图为CAT相关监控数据的样本,以xxx-service这个service为例:
99line的监控数据,有很多SQL的返回时间超过100ms以上。
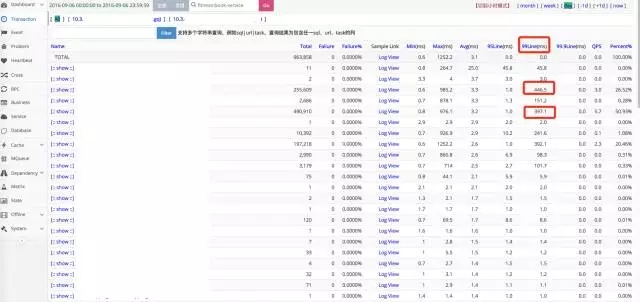
SQL的绝对数量在2016年9月6日当天为 :3788。
具体到某个SQL,甚至达到了929ms。

FB_Coach的表结构如下:
可看到最多641条记录,还有联合索引。

要想定位到原因,必须通过排除法找到该SQL到底慢在哪个阶段,这样才能缩小范围。接下来我们来分析慢SQL的花费时间组成。从下图可看出,时间主要由3部分组成:
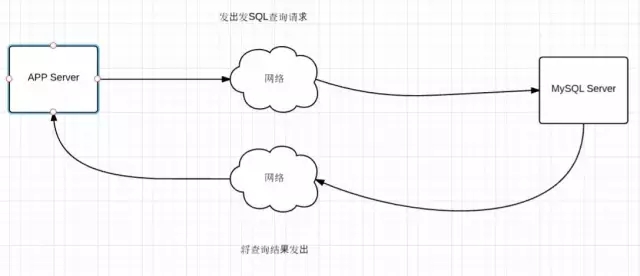
App Server:发出SQL请求的时间,接收返回结果的时间
网络:SQL请求包及查询结果在网络上花费的时间
MySQL Server:发出SQL到查询结果整个过程花费的时间
我们可以通过抓包工具获取每个阶段花费的时间,从而定位到底慢在哪个阶段。
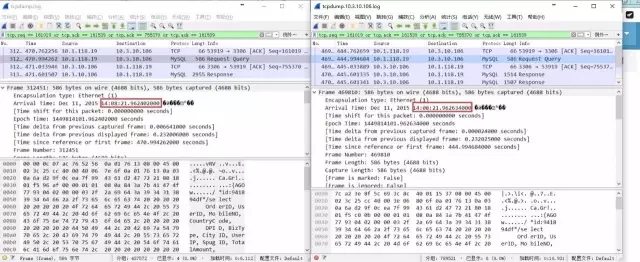
思路1:确认哪个过程花费的时间最多
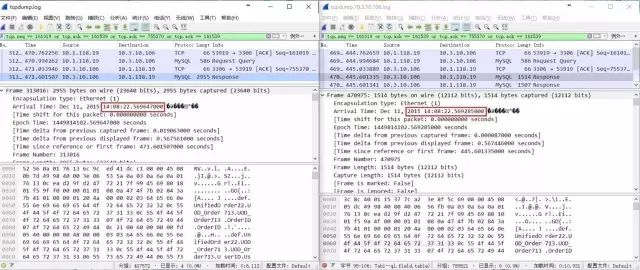
方法:分别在APP Server与MySQL Server部署TcpDump抓包工具,得到数据包在4个监测点的“到达时间”。为了方便,把如下4个Wireshark分析结果(对TcpDump抓取日志分析)按4个方位标注:
APP Server 发出SQL(左上)
MySQL Server 收到SQL(右上)
MySQL Server 将查询发出(右下)
APP Server 收到查询结果(左下)
从数据可以准确的看出时间主要花费在MySQL内部,具体时间为22.569285000-21.962634000=0.6066509999999994(秒),约为606ms。
抓包结果:慢在MySQL Server端。
方法:将MySQL内部对SQL查询的流程进行梳理,采用排除法定位问题。要把经典图拿出来说事了,以下基础知识主要来自于《高性能MySQL》,“拿来主义”一下。

首先可以看到,MySQL主要有三个组件:连接/线程处理、MySQL Server层、存储引擎层。
最上层主要进行连接处理、授权认证、安全等;
第二层包括查询解析、分析、优化(这三个是解决问题最关心的)、缓存管理、所有内置函数、存储过程、触发器、视图,似乎扯得有点远;
第三层包含了主要的存储引擎层,MySQL Server层(第二层)通过“存储引擎API”向存储引擎层存储和提取数据,此层主要是数据存储相关。
接下来通过一个客户端请求查询数据,看看MySQL主要做哪些工作吧。
每个客户端(可能理解为App负责连接数据库的组件,我们叫DAL)连接到MySQL服务器进程后会拥有一个线程,这个连接的所有查询都会在该线程中去执行,同时服务器会缓存线程,以减少创建或销毁线程的开销和频繁的上下文切换。
当客户连接到MySQL服务器时,服务器会分配一个线程,之后进行权限认证,认证通过后,MySQL就开始解析该SQL查询,并创建内部数据数据结构(解析树),然后对其各种优化,最后调用存储引擎API获取或存储需要的数据,最后将查询结果返回给客户端。
通过以上“背书”,我们大概了解了一个SQL请求的执行过程,那到底慢在哪个阶段呢?
通过“慢SQL特点”的第4条知道,“数据库的slow log里没有记录这类SQL”,那慢SQL发生的阶段就可以排除了。
MySQL slow log是记录SQL执行过程花费的时间,记录的时间从“SQL解析”到“存储引擎”返回数据整个过程,所以可以排除该SQL是慢在第二层和第三层,那么只能是把时间花费在第一层了?和线程相关?
结果:很可能慢在MySQL线程管理上。
思路3:是创建线程慢?thread cache不够用,需要频繁的创建线程?
方法:查看当时数据库的状态值
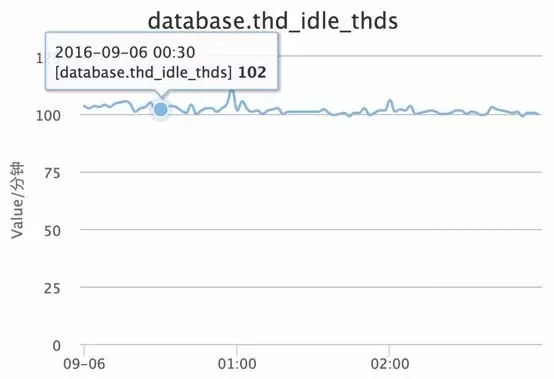
可以看到,当时空闲的thread很多,监控图也没有抖动,所以并没有频繁地创建线程。慢SQL产生的时间点,空闲的thread很多,并没有进行大量的线程创建。
那问题到底出现在和线程相关的哪个环节呢? 先把所有和thread相关的参数列出来。
|
thread_cache_size |
一眼看过去,大部分是和Thread-Pool相关。同时意识到这些问题是随着升级到MySQL 5.6产生的,5.6引入了Thread-Pool功能。
结果:看来MySQL5.6的Thread-Pool有很大嫌疑了。
思路4:关闭MySQL 5.6的Thread-Pool,确认一下问题
方法:调整MySQL参数 thread_handling = pool-of-threads---- → thread_handling = One-Connection-Per-Thread。
结论:关闭Thread-Pool功能后,减少78%的慢SQL,侧面证明是Thread-Pool的问题。
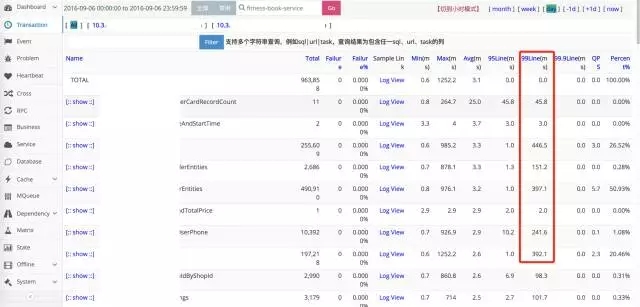
以下是具体的证据,以xxx-service这个service为例:打开Thread-Pool功能(2016年9月6日当天数据)。
99line占比:有好多超过100ms的SQL。
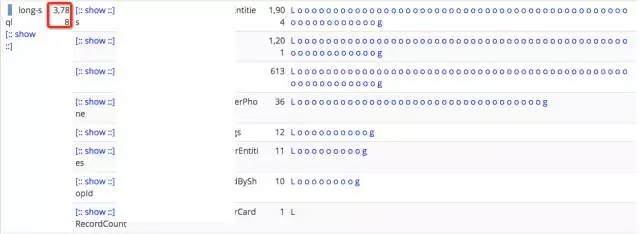
慢SQL数量:3788
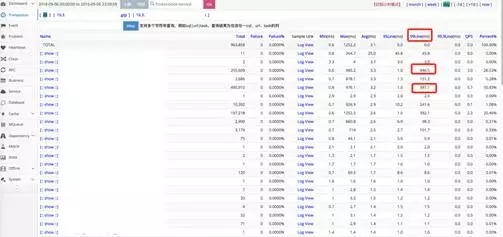
关闭Thread-Pool功能后(2016年9月13日当天数据)。
99line占比:已经看不到超过100ms的sql了,都在10ms以内。
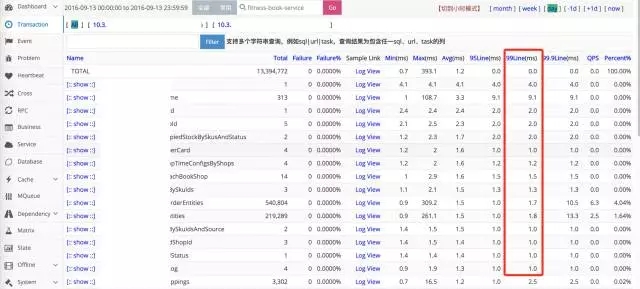
慢SQL数量:818
那么关闭Thread-Pool ?答案很显然,不能!Thread-Pool是MySQL5.6重要的功能,能够保证MySQL数据库高并发下的性能稳定。
思路5:调优Thread-Pool相关参数
方法:深入了解Thread-Pool的工作原理,查找可能产生慢SQL的参数。
结果:找到了相关参数(thread_pool_stall_limit),并且效果明显,慢SQL数量从最初的3788减少到63,几乎全部消灭掉。
以xxx-service这个service为例,调整后的效果,2016年9月20日当天的数据:
99line占比:
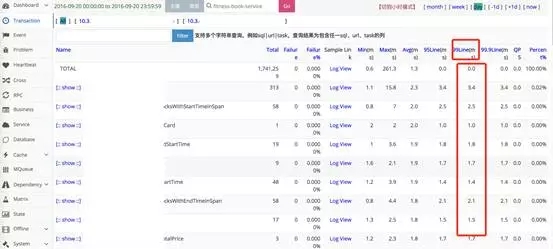
慢SQL数量:63

ok,效果有了,总结一下。
1、基本原理
没有引入Thread-Pool前,MySQL使用的是one thread per connection,一旦connection增加到一定程度,MySQL的性能将急剧下降甚至被压跨。引入Thread-Pool后将会解决上述问题,同时会减少MySQL内部的线程数(节省内存)及频繁创建线程的开销(节省CPU)。
2、Thread-Pool是如何工作的?
在MySQL内部有一个专用的thread用来监听数据库连接请求,当一个新的请求过来,如果采用以前的模型(one-thread-per-connection),main listener(这是主线程中的listener,为了避免与thread group 中的listener混淆,我们称之为“Main listener”)将从thread cache中取出1个thread或创建1个新的thead立即处理该连接请求,由该thread完成该连接的整个生命周期;
而如果采用Thread-Pool模型,这个连接请求将会被随机放到一个thread group(thread pool由多个thread group 组成)的队列中,之后该thread group中worker thread从队列中取出并建立连接,一旦连接建立,该连接对应的socket句柄将与该thread group中的listener关联起来,之后该连接将在该thread group中完成它的生命周期。
接下来我们来说说Thread Group 。Thread Group是Thread-Pool的核心组件,所有的操作都是发生在thread group。Thread-Pool由多个(数量由参数thread_pool_size来决定,默认等于cpu个数)thrad group组成。一个连接请求被随机地绑定到一个thread group,每个thread group独立工作,并且占用一个核的CPU。所以thread group都会最大限度地保持一个thread处于ACTIVE状态,并且最好只有一个,因为太多就有可能压跨数据库。
Thread Group中的thread一般有4个状态:
TP_STATE_LISTENER
TP_STATE_IDLE
TP_STATE_ACTIVE
TP_STATE_WAITING
当一个线程作为listener运行时就处于“TP_STATE_LISTENER”,它通过epoll的方式监听联接到该Thread Group的所有连接,当一个socket就绪后,listener将决定是否唤醒一个thread或自己处理该socket。此时如果Thread Group的队列为空,它将自己处理该socket并将状态更改为“ACTIVE”,之后该thread 在MySQL Server内部处理“工作”,当该线程遇到锁或异步IO(比如将数据页读入到buffer pool)这些wait时,该thread将通过回调函数的方式告诉thread pool,让其把自己标记为“WAITING”状态。
此时,假设队列中有了新的socket准备就绪,是立即创建新的线程还是等待刚才的线程执行结束呢?
由于Thread-Pool最初设计的目标是保持一定数量的线程处于“ACTIVE”状态,具体的实现方式就是控制thread group的数量和thread group内部处于"ACTIVE"状态的thread的数量。控制thread group内部的ACTIVE状态的数量,方法就是最大限度地保证处于ACTIVE状态的线程个数是1。很显然,当前thread group中有一个处于WAITING状态的thread了,如果再启用一个新的线程并且处于ACTIVE状态,刚才的线程由WAITING变为ACTIVE状态时,此时将会有2个“ACTIVE”状态的线程,和最初的目标似乎相背,但显然也不能让后续就绪的socket一直等待下去,那应该怎么处理?
那么此时需要一个权衡了,提供了这样的一个方法:对正在ACTIVE或WAITING状态的线程启用一个计数器,超过计数器后将该thread标记为stalled,然后thread group创建新的thread或唤醒sleep的thread处理新的sokcet,这样将是一个很好的权衡。超时时间该参数thread_pool_stall_limit来决定,默认是500ms。
如果一个线程无事可做,它将保持空闲状态(TP_STATE_WAITING)一定时间(thread_pool_idle_timeout参数决定,默认是60秒)后“自杀”。
3、和我们遇到的具体问题相关的点
假设上文提到的由“ACTIVE”转化为“WAITING”状态的线程(标记为“线程A”)所执行的“SQL"可能是一个标准的慢SQL(命名为SQLA,执行时间较长),那么后续有连接请求分配到了同一个thread group,那么新连接的SQL(命名SQLB)需要等待线程A结束;如果SQLA执行时间超过500ms,该thread group创建新的worker线程来处理SQLB。
不管哪种情况,SQLB都会在线程等待上花费很多时间,此时SQLB就是CAT监控系统上看到的慢SQL。又因为SQLA不一定都是慢SQL,所以SQLB也不是每次在线程等待上花费较多的时间,这就吻合我们看到的现象“一定比例的慢SQL”。
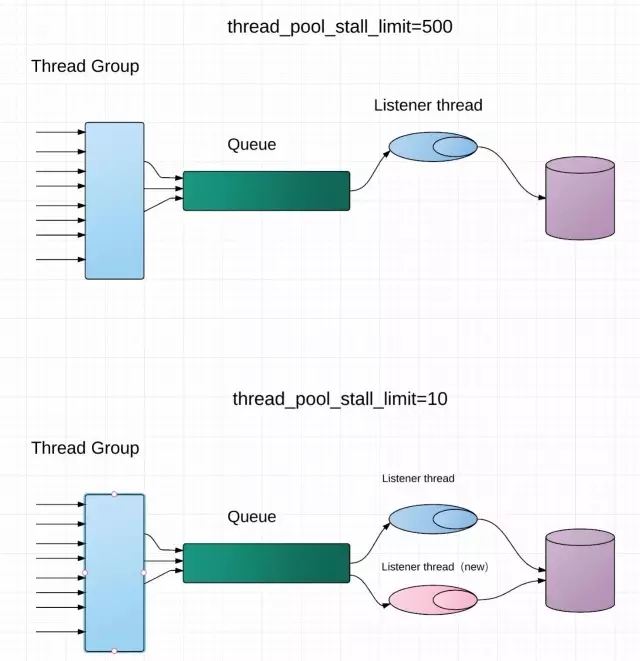
找到问题了,那么解决办法就简单了。调整thread_pool_stall_limit=10,这样就强迫被SQLA更快被标记为stalled,然后创建新的线程来处理SQLB。
带来的价值
以xxx-service为例,减少了98.3%的慢SQL,效果很明显;
该问题的解决让百个产品线从中受益,业务可用性超过了99.99%。
|
状态 |
慢SQL数量 |
备注 |
|
|
优化前 |
3788 |
||
|
优化操作:关闭thread pool |
818 |
||
|
优化操作:调整参数thread_pool_stall_limit=10 |
63 |
首先我们分析了慢SQL的特点及该SQL花费的时间组成,通过“时间花费在哪”这一通用方法,不断把问题范围缩小,最终通过排除法将问题锁定在MySQL内部线程。
对于MySQL内部线程,我们通过对参数“全量扫描”,发现了与MySQL 5.6新开启的参数有关,粗略确定了Thread-Pool是导致慢SQL问题的。
之后通过关闭Thread-Pool进一步确认是开启该功能引起的。之后我们不断调整参数和阅读大量相关的资料,最终将问题解决。
通过以上问题的解决,我们可以学到一些端到端的性能问题解决思路:
定位问题
划分问题的边界
每个问题总有它的边界。当我们无法一眼看出来问题的边界在哪里时,就需要不断的通过排除法缩小边界,在特定的边界内就用特定的专业知识来定位问题。
搜集关键数据得出靠谱结论
比如生产环境中会有各种数据,包含监控数据、临时部署工具获取的数据,充分利用这些数据支撑我们的结论。
对问题产生的时间或影响范围进行上下文联想
很多问题是随着一些改变产生的,就像软件的生命周期一样,受到各种环境的变化影响。通过问题产生的上下去寻找问题的原因,可以发现大部分问题的产生原因。
解决问题
不断尝试
有很多人认为,知道问题的原因了,解决问题是比较容易的。其实我认为这个是反的。因为只有清楚知道问题解决了,才能证明问题的原因是对的。在找到问题的原因之前,其实我们已经通过不断的调整和测试把问题解决了。所以解决问题很关键,貌似是废话。
合理的理论推断问题产生的原因
问题解决了,原因也找到了,最后一步还要“自圆其说”,这就需要深究技术原理,找到切入点,复现问题了。
解决问题的方法有千万种,这里列举了其中一种,希望能够帮助到大家。
参考文献:
-END-
当AI遇上大数据,会擦出什么样的火花?
微服务实践都有哪些坑?
9月9日 ArchData技术峰会
由DBAplus社群&中生代技术联合主办的技术盛典
等你一起讨论!
▼

点这里开始报名,一起约会~
https://m.grouplus.com/dUwrtN?awsd_qwerty=1503026632890&source=&fx_code=







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721