
作者介绍
杨奇龙,前阿里数据库团队资深DBA,主要负责淘宝业务线,经历多次双十一,有海量业务访问DB架构设计经验。目前就职于有赞科技,负责数据库运维工作,熟悉MySQL性能优化、故障诊断、性能压测。
和团队内部的同事一起沟通,讨论了MySQL数据库系统数据安全性问题,主要针对MySQL丢数据 、主从不一致的场景 ,还有业务层面使用不得当导致主备库数据结构不一样的情况,本文是基于以上的讨论和总结做的思维导图。

BBU:数据库服务器要配置BBU,BBU在电源供应出现问题的时候,为RAID控制器缓存提供电源。当电源断电时,BBU电力可以使控制器内缓存中的数据可以保存一定时间(根据BBU的型号而决定)。用户只需要在BBU电力耗尽之前恢复正常供电,缓存中的数据即可被完整的写回RAID中,避免断电导致数据丢失
防止OS异常断电导致数据无法正常落盘
磁盘禁用cache,MySQL的 O_DIRECT 方式可以跳过pagecache写数据
(1)redo log

< 5.6.6: 每隔一秒将redo log buffer中的数据刷新到磁盘
>= 5.6.6:每隔innodb_flush_log_at_timeout秒将数据刷新到磁盘中去
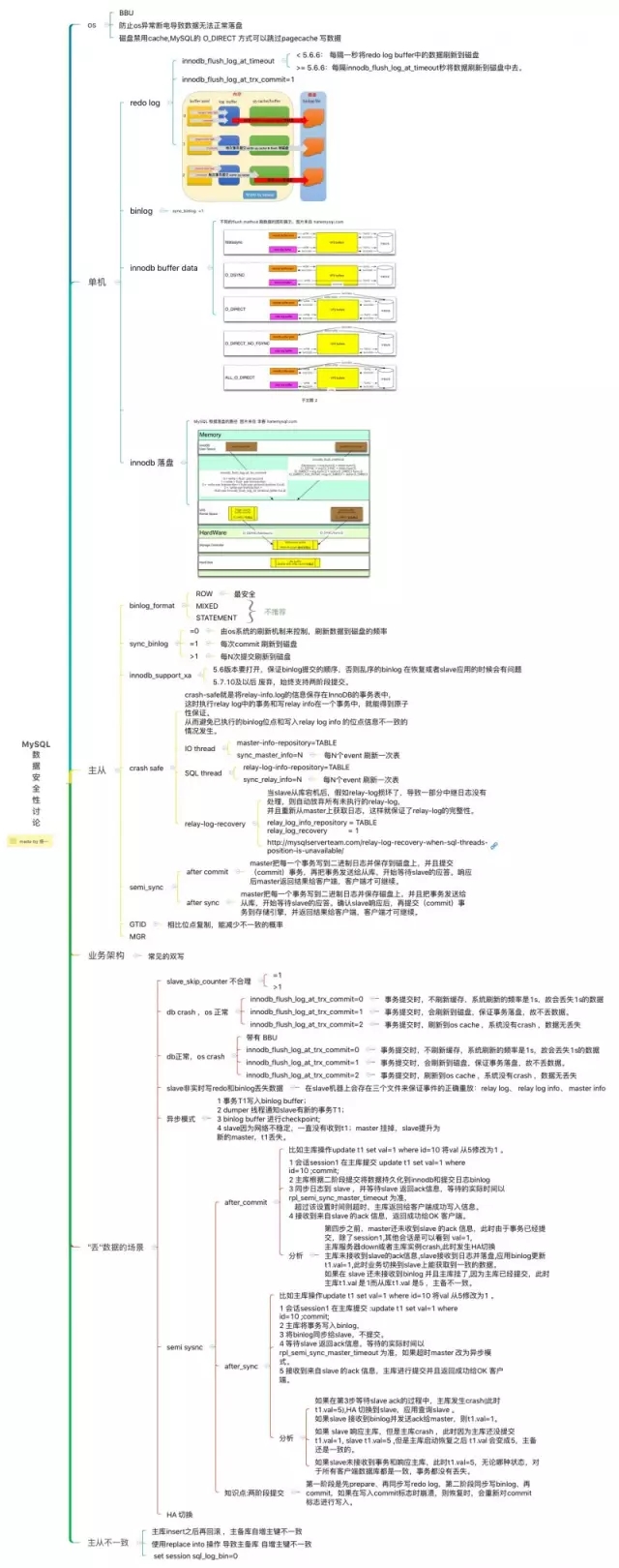
(2)binlog
sync_binlog =1
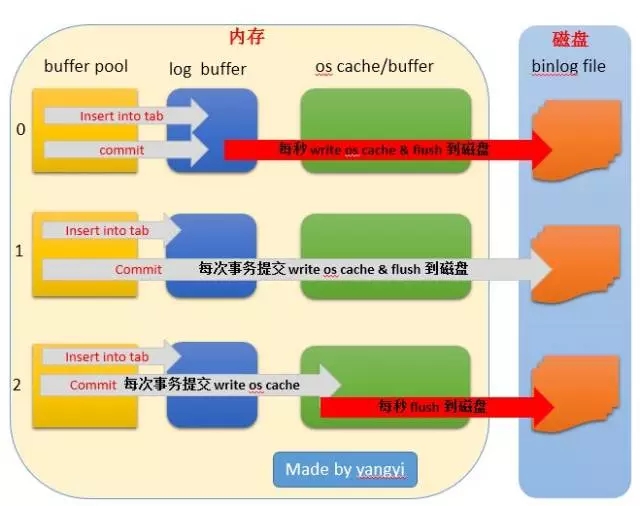
(3)innodb buffer data
不同的flush mathod刷数据的图形展示。图片来自hatemysql.com。
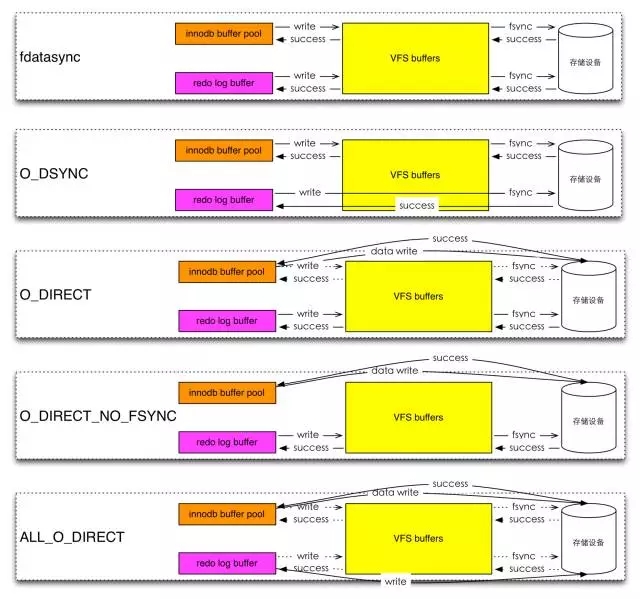
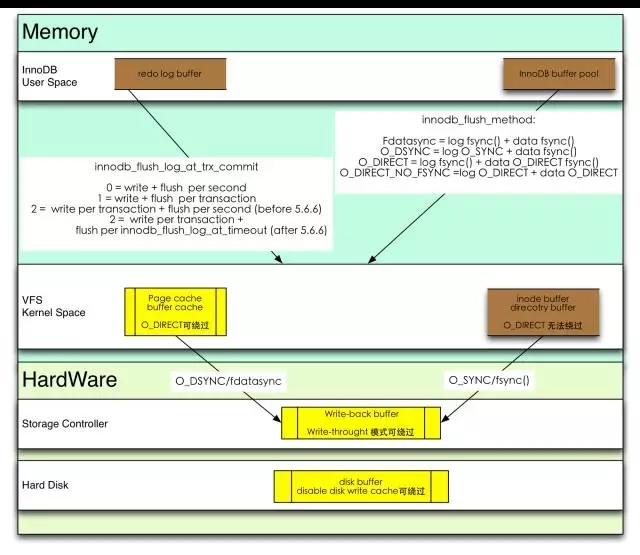
(4)InnoDB 落盘
MySQL数据落盘的路径,图片来自李春hatemysql.com。
主库insert之后再回滚 ,主备库自增主键不一致
使用replace into操作,导致主备库自增主键不一致
set session sql_log_bin=0
常见的双写
(1)slave_skip_counter 不合理
slave_skip_counter =1
slave_skip_counter >1
(2)DB Crash,OS正常
事务提交时,不刷新缓存,系统刷新的频率是1s,故会丢失1s的数据。
事务提交时,会刷新到磁盘,保证事务落盘,故不丢数据。
事务提交时,刷新到os cache,系统没有crash,数据无丢失。
(3)DB正常,OS Crash
事务提交时,不刷新缓存,系统刷新的频率是1s,故会丢失1s的数据。
事务提交时,会刷新到磁盘,保证事务落盘,故不丢数据。
事务提交时,刷新到os cache,系统没有crash,数据无丢失。
(4)slave非实时写redo和binlog丢失数据
在slave机器上会存在三个文件来保证事件的正确重放:relay log、 relay log info、 master info。
(5)异步模式
事务T1写入binlog buffer;
dumper线程通知slave有新的事务T1;
binlog buffer进行checkpoint;
slave因为网络不稳定,一直没有收到t1;master挂掉,slave提升为新的master,t1丢失。
(6)semi sysnc
比如主库操作update t1 set val=1 where id=10将val从5修改为1 。
会话session1在主库提交update t1 set val=1 where id=10 ;commit;
主库根据二阶段提交将数据持久化到innodb和提交日志binlog;
同步日志到slave ,并等待slave 返回ack信息,等待的实际时间以 rpl_semi_sync_master_timeout 为准,超过该设置时间则超时,主库返回给客户端成功写入信息。
接收到来自slave的ack信息,返回成功给OK客户端。
分析:
第四步之前,master还未收到slave的ack信息,此时由于事务已经提交,除了session1,其他会话是可以看到 val=1。
主库服务器down或者主库实例crash,此时发生HA切换。
主库未接收到slave的ack信息,slave接收到日志并落盘,应用binlog更新。t1.val=1,此时业务切换到slave上能获取到一致的数据。
如果在slave还未接收到binlog并且主库挂了,因为主库已经提交,此时主库t1.val是1而从库t1.val是5,主备不一致。
比如主库操作update t1 set val=1 where id=10将val从5修改为1 。
会话session1在主库提交 :update t1 set val=1 where id=10;commit;
主库将事务写入binlog。
将binlog同步给slave,不提交。
等待slave返回ack信息,等待的实际时间以rpl_semi_sync_master_timeout为准,如果超时master改为异步模式。
接收到来自slave的ack信息,主库进行提交并且返回成功给OK客户端。
分析:
如果在第3步等待slave ack的过程中,主库发生crash(此时t1.val=5),HA 切换到slave,应用查询slave 。如果slave接收到binlog并发送ack给master,则t1.val=1。
如果slave响应主库,但是主库crash ,此时因为主库还没提交t1.val=1, slave t1.val=5,但是主库启动恢复之后t1.val会变成5,主备还是一致的。
如果slave未接收到事务和响应主库,此时t1.val=5,无论哪种状态,对于所有客户端数据库都是一致,事务都没有丢失。
第一阶段是先prepare、再同步写redo log,第二阶段同步写binlog、再commit,如果在写入commit标志时崩溃,则恢复时,会重新对commit标志进行写入。
(6)主从
ROW(最安全)
MIXED(不推荐)
STATEMENT(不推荐)
=0:由os系统的刷新机制来控制,刷新数据到磁盘的频率
=1:每次commit刷新到磁盘
>1:每N次提交刷新到磁盘
版本要打开,保证binlog提交的顺序,否则乱序的binlog在恢复或者slave应用的时候会有问题,及以后废弃,始终支持两阶段提交。
crash-safe就是将relay-info.log的信息保存在InnoDB的事务表中,这时执行relay log中的事务和写relay info在一个事务中,就能得到原子性保证。从而避免已执行的binlog位点和写入relay log info的位点信息不一致的情况发生。
master-info-repository=TABLE
sync_master_info=N:每N个event刷新一次表
relay-log-info-repository=TABLE
sync_relay_info=N:每N个event刷新一次表
当slave从库宕机后,假如relay-log损坏了,导致一部分中继日志没有处理,则自动放弃所有未执行的relay-log,并且重新从master上获取日志,这样就保证了relay-log的完整性。
relay_log_info_repository = TABLE
relay_log_recovery = 1
http://mysqlserverteam.com/relay-log-recovery-when-sql-threads-position-is-unavailable/
after commit:master把每一个事务写到二进制日志并保存到磁盘上,并且提交(commit)事务,再把事务发送给从库,开始等待slave的应答。响应后master返回结果给客户端,客户端才可继续。
after sync:master把每一个事务写到二进制日志并保存磁盘上,并且把事务发送给从库,开始等待slave的应答。确认slave响应后,再提交(commit)事务到存储引擎,并返回结果给客户端,客户端才可继续。
相比位点复制,能减少不一致的概率
MySQL数据丢失讨论
细看InnoDB数据落盘
MySQL5.7 深度解析:Loss-Less半同步复制技术
MySQL 5.7 Replication相关新功能说明
登录云盘http://pan.baidu.com/s/1qYbOOyg,可下载高清版思维导图。
也欢迎大家提供自己的想法,一起来完善这张MySQL数据安全性思维导图,可直接在本文微信评论区留言或发送邮件至:editor@dbaplus.cn。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721