
注:文章涉及的程序名、用户名、表名、索引名、序列名均作了脱敏处理。
某客户核心系统数据库工作日生产时间发现会话积压,存在大量异常等待事件,部分节点所有联机日志组全部处于Active状态,无法完成数据库检查点,数据库实例处于Hang住的状态。
第二周几乎相同时间发生同样的问题,但由于第一次已经提出预案,所以问题影响得到控制,同时采集到更多分析信息,最终彻底解决了该问题。
环境介绍:
IBM Power8 E880
AIX 7.1
Oracle 4-nodes RAC(11.2.0.3.15)
第一次故障发生后,提出以下预案并在第二次故障发生时,提前发现问题,介入诊断,业务无影响。
部署短信告警,监控Active日志组个数,当大于四组时告警,以提前发现问题。
第一时间介入后抓取现场,添加可用日志组以延缓故障发生时间,给现场诊断留出时间。
紧急停止Hang住的节点,因数据库集群使用RAC架构,能够实现高可用,避免单点故障,对实际业务无影响。
为确保能够对故障进行事后分析,彻底定位和解决问题,对生产库做hanganalyze分析和进行采集system dump,但该系统非常繁忙,采集system dump时间需60-90分钟,因此为控制业务影响范围,在做10分钟左右dump之后,紧急停止dump,并优先停止节点2,以恢复数据库,至11点48分,数据库完全恢复,正常提供对外服务。
鉴于本次故障比较复杂,我们用思维导图的形式将故障诊断分析过程简化,方便你的理解。如果你有更好的分析思路,欢迎文末评论!
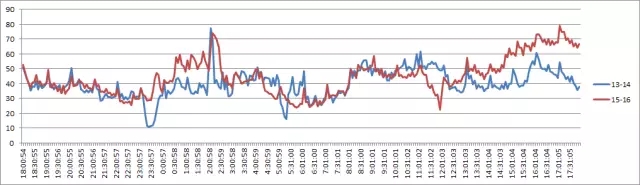
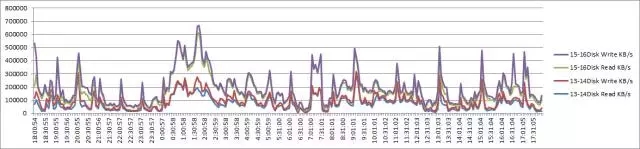
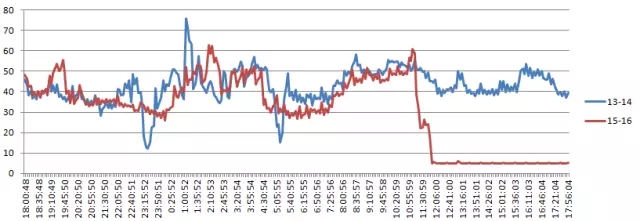
通过对比,我们可以发现,周五的数据库负载基本与平时相差不多,整体均在正常状态。
节点1 CPU使用情况分析:
节点1 IO读写情况分析:
节点2 CPU使用情况分析:
节点2 IO读写情况分析:
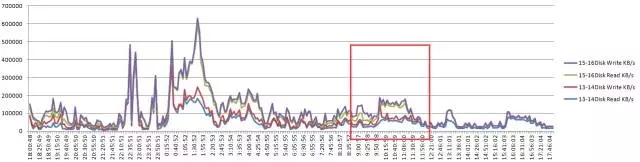
节点3 CPU使用情况分析:
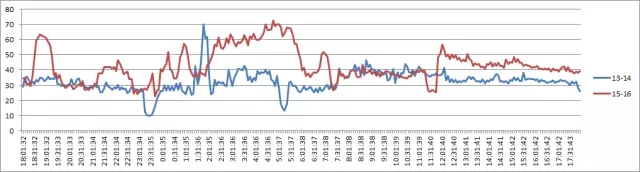
节点3 IO读写情况分析:

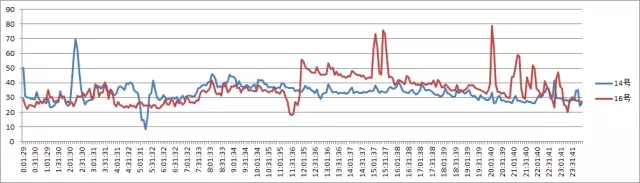
节点4 CPU使用情况分析:
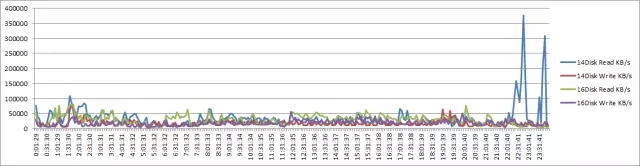
节点4 IO读写情况分析:
1、检查点未完成导致数据库Hang的可能原因:
首先怀疑归档目录出现问题导致无法写入归档日志,采取以下措施进行排查:
归档目录空间足够,不存在空间问题。
对归档目录进行dd操作,对目录进行touch文件的操作,不存在无法读写问题。
赛门铁克反馈近期SF集群日志正常,多路径日志也未发现异常报错。
常规排查未发现问题的情况下,只能从当时抓取dump中进行分析,以找到问题根源。
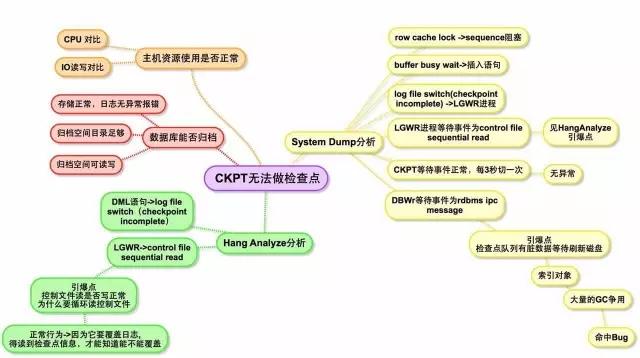
2、System Dump分析:
从System Dump输出日志文件中发现4个阻塞源头:

从中可以看到总共有四个阻塞源头,然后一一查找源头。
两个Sequence阻塞
Rcache object=700000b7e8ecf08, SEQ_LNCH_XXXX_TRIGID
Rcache object=700000bbffdedc0, SEQ_LNCH_XXXX_TRIGLOGID

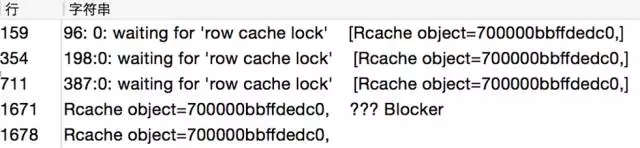
可以看到前面两个Object都在等待row cache lock,这是一种数据字典的并发争用引起的锁。
Dump输出日志中的sequence如下,Cache size为0。建议与应用沟通为何设置为0,如无特殊场景,RAC环境中设置cache size为1000。

Insert语句 Blocker,等待获得SEQ
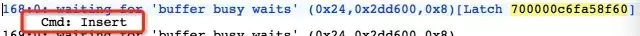
insert into QTKB_XXXX_PLANRAL(RSRV_STR2,……) values (:1,:2,:3,:4,:5,:6,:7,:8,:9,:10,:1 1,:12,:13,:14,:15,:16,:17,:1
这个Blocker是一个客户端发起的的会话。可以看到它当时的信息如下:
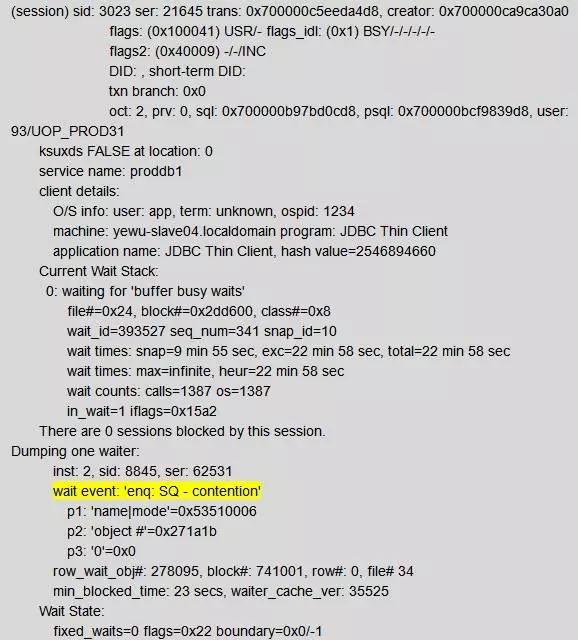
非系统级别的Sequence阻塞,会导致相关业务性能急剧下降。
Update在等待获得日志切换完成
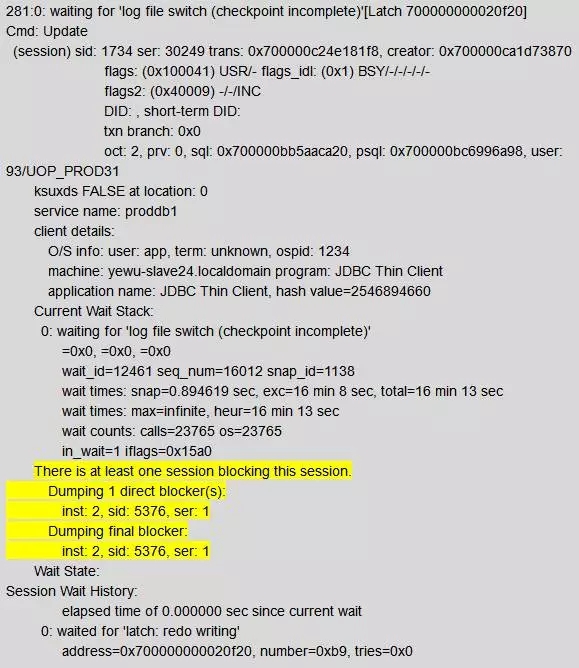


可以看到这个会话被inst: 2, sid: 5376阻塞。5376就是节点2的LGWR进程,他一直在等待log file switch(checkpoint incomplete)完成。
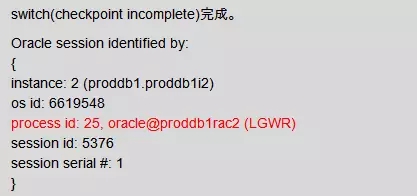
3、全局Hanganalyze分析
在12月16日故障发生过程中,已对数据库2节点做全局HangAnalyze分析。发现有两个Blocker分别阻塞5817个会话和3694个会话,接下来依次分析。
LGWR进程阻塞了5817个会话,等待日志切换完成
对Hang Analyze结果分析发现,节点2的LGWR阻塞5817个会话。
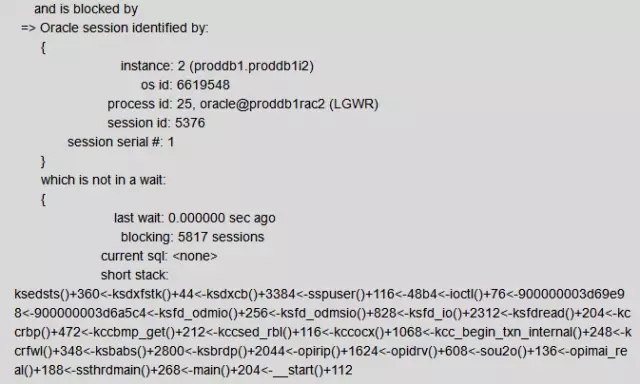

从等待事件上来看,LGWR一直在等待control file sequential read。那么LGWR为什么要读控制文件呢?
参考文档Master Note: Overview of Database ControlFiles (文档 ID 1493674.1),在日志切换的时候,LGWR需要去获取CF队列,获取这个队列之后,就要读取控制文件。

Update语句阻塞了3600个会话,等待日志切换完成
DML语句:Update,然后它们的阻塞会话在等待log file switch(checkpoint incomplete)。
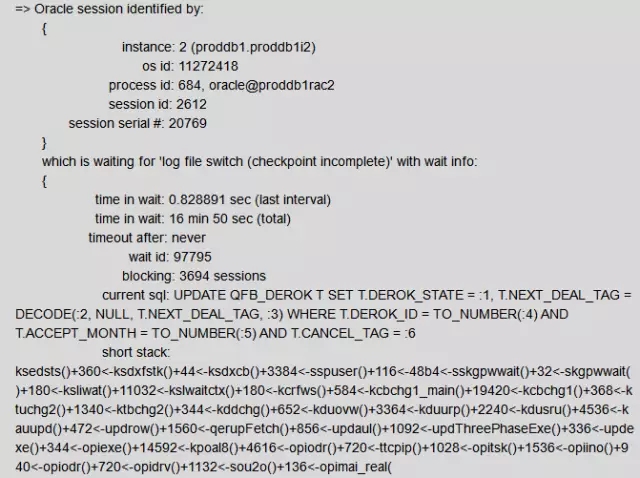

日志切换之后,有一个“日志切换检查点”操作,这个操作由CKPT发起,让DBWR进程把缓冲区的脏数据写入磁盘,之后才会把redo logfile的状态从ACTIVE变成INACTIVE。
以下是log switch checkpoint的描述:

通过对Hanganalyze的分析,可以得出一个初步结论,由于DBWR无法把跟ACTIVE redo logfile相关的脏数据写入磁盘,导致redo logfile状态一直是ACTIVE。
4、深入分析日志切换检查点
日志检查点没有完成
前面提到过,日志切换检查点会更新系统状态信息(background checkpoints started和background checkpoints completed),从DBA_his_sysstat历史表中得到了下列信息,节点2后台检查点完成信息从10点开始到11点一直没有更新,而其他节点的检查点进程完成更新很及时。
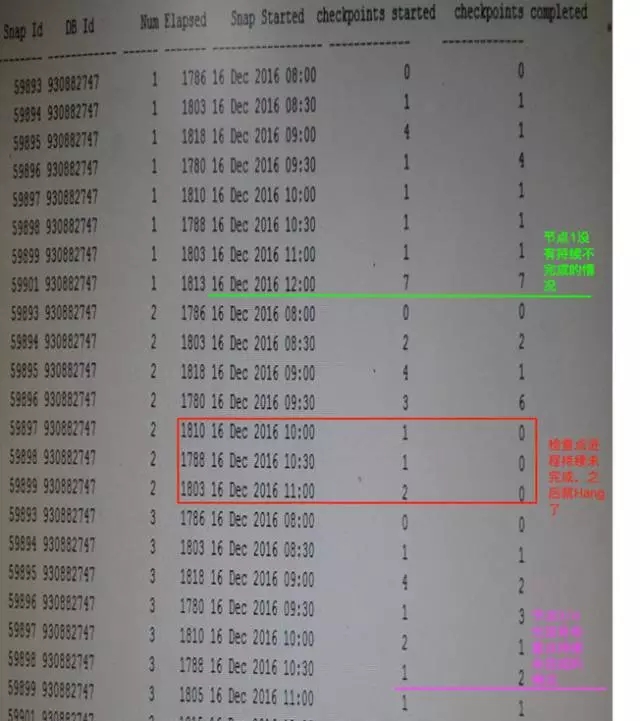
正常情况下(12月26日),检查点完成信息如下:
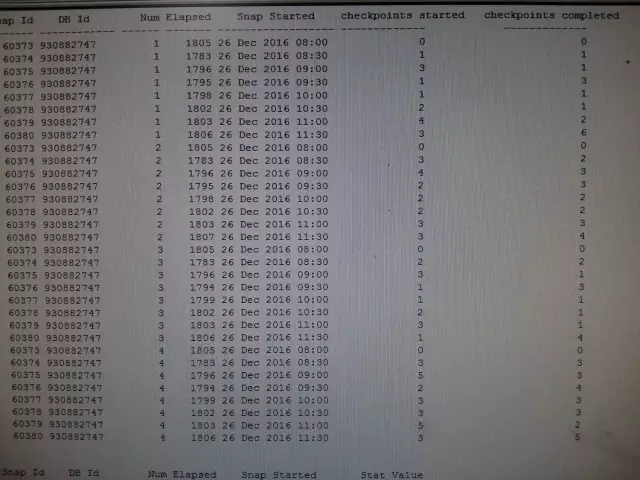
所有数据库实例检查点进程没有持续未完成的情况发生。
异常脏数据,使得CKPT进程异常
分析发现,DBW0~DBW6共7个数据库写进程状态正常:

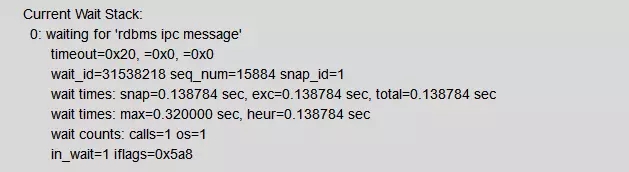
可以看到DBWR当时的等待事件是'rdbms ipc message',也就是空闲等待。
这说明系统认为当前已经没有脏数据了,它一直在等待其他进程唤醒它工作。这个状态是正常的。
事实上,从System Dump输出,我们看到数据库缓冲区中是有存在脏数据队列:
ckptq: [NULL] fileq: [0x7000009cf6f61d0,0x7000004cfa39a60] objq: [0x7000003ffa24818,0x7000006d77eeda8] objaq: [0x70000043f871938,0x7000006d77eedb8]

obj:1341208 objn:141351
这个脏块上的对象是一个Index,对应的对象名称为IDX_HQMHLCD_RZ_1 (对应的表为: UDP_PROD31.QFCHL_XXXXACTION_LOG)。
脏数据块上索引对应的语句
进一步从日志分析发现,索引IDX_HQMHLCD_RZ_1相关的业务SQL在数据库故障发生前存在gc cr multiblock request等待事件和gc current request等待事件:
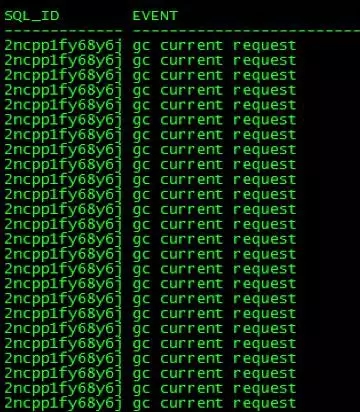
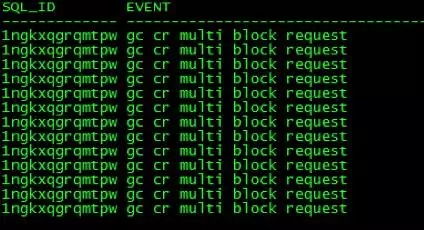
对应的SQL文本如下:

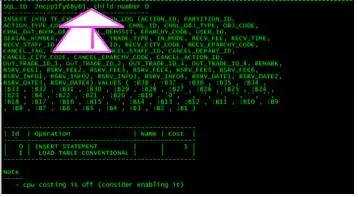
我们可以看到,Select语句里显性的指定了使用这个索引IDX_HQMHLCD_RZ_1,而每个Insert语句都会对索引进行更新。
从而推导,是否是IDX_HQMHLCD_RZ_1及相关语句触发了bug,导致的CKPT进程异常呢?
进一步从MOS去查证,bug 16344544与此极为相符。
跨节点业务访问导致的bug
通过以上分析,我们推断,表UDP_PROD31.QFCHL_HQMHLCD_LOGRZ对应的insert语句和select语句跨节点访问触发bug 16344544,导致CheckPoint检查点进程无法让DBWR进程将脏数据写入磁盘,造成了日志组状态持续为ACTIVE,无法变成INACTIVE正常状态。
该bug证实影响的数据库版本为11.2.0.3/11.2.0.4,官方文档显示12.1以下版本都可能遭遇。详情访问MOS文章:Bug 16344544 Deadlock and hang possible in RAC env between 'gc current request' and 'gc cr multi block request'。
但据官方文档记载该bug暂无补丁,只有一个workround规避问题:修改隐含参数"_gc_bypass_readers"为FALSE。
更多IDX_XXXXHUOD_RZ_1索引信息

(1)该索引为本地分区索引,从2013年系统上线以来,一直没有做过重组,大小已经很大,存在大量碎片。
(2)该索引同时被节点3和节点4上的应用程序访问
节点3上dump的信息显示索引IDX_HQMHLCD_RZ_1(object_id:1341208)被访问过:

节点4上dump的信息显示索引IDX_HQMHLCD_RZ_1(object_id:1341208)被访问过:
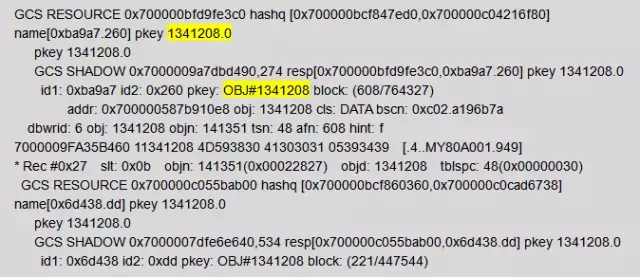
至此,我们基本判定触发bug。要规避这样的问题,就要消除上面两个因素。
5、解决方案:
该问题的解决方案有3个:
重建索引IDX_HQMHLCD_RZ_1,减少碎片,提升索引访问效率,降低GC等待。
渠道业务相关应用,应做好应用隔离,避免跨库访问业务,避免GC等待出现
将隐含参数"_gc_bypass_readers"设置为FALSE(需要应用侧充分测试后,方可在生产上实施)
考虑到方案的可实施性,先进行索引重建,然后逐步完成应用访问隔离。
在应用侧配合完成索引重建及应用隔离后,问题彻底解决。
此问题诊断分析、处理及跟踪长达3周时间,其间各类Oracle服务公司纷沓而至,问题指向千奇百怪,靠着新炬专家团队通力合作,深入、细致、理性的分析,最终推导,并完美解决!
最终的问题分析会上,客户领导评论:“所有厂商的人应该学习新炬专家这种抽丝剥茧的故障问题分析方法!”
保证数据的安全、数据库的稳定高效运行是DBA团队的天职。年前大检查你做好了么!
最后做个小广告,我们研发的DPM数据库性能管理平台已经完美支持这些bug预警。如果你想试用,请加老杨微信详细了解:boypoo。







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721