
作者介绍
裴征峰,现就职于北京海天起点,二线专家成员,南京办事处负责人,OCP 10g、OCP 11g、OCM11g。超八年Oracle服务经验,擅长数据库故障诊断和性能调优。目前主要从事客户的现场维护、重大问题的解决、数据库性能分析、二线服务质量保证等工作。
某省份的电信业务系统由于业务量较大,按地市划分部署在4套配置相同的RAC上,相同主机版本,相同的CRS和数据库版本。该系统已正常运行3年多,其间也有重启主机等正常维护操作。从4月24日 开始,这个系统的4套RAC的节点,一个接一个地宕机重启,但每次都不是同一个节点。整理的宕机情况列表如下:
系统 宕机时间
-----------------
xx1db01 04-24
xx1db02
xx2db01 07-30
xx2db02 07-23
xx3db01 08-19
xx3db02 07-27
xx4db01
xx4db02
这4套RAC是3年前安装的,平时运行非常稳定,基本没有问题,从4月份开始有节点宕机,并且在7,8月份宕机频率非常高。但有点比较奇怪,每次宕机都是不同的节点,没有相同的节点发生宕机。由于配置了业务隔离,所以RAC宕一个节点,对业务影响不大,但是如此大规模的节点宕机,肯定有一些共性的问题。
每次宕机基本为ocssd.bin进程出错,直接重启节点。ocssd.bin报错的日志基本为:
这4套RAC的配置如下:
主机版本:HP-UX B.11.31 U ia64
数据库CRS版本为:10.2.0.5.0(未打PSU)
数据库版本为:10.2.0.5.8(PSU号:13923855)
安装了Veritas Storage Foundataion,使用VCS集群文件系统。
4月24日,xx1db01节点宕机,这是这套业务系统的第一次节点宕机。由于没有安装OSWatch工具,无法得知宕机时操作系统资源情况。
检查操作系统日志,没有发现报错信息。这可能是系统直接重启时,还没有来得及把内存中的信息刷到磁盘。检查数据库的alert日志,宕机重启时数据库实例没有异常信息。
检查ocssd.log,发现如下报错:
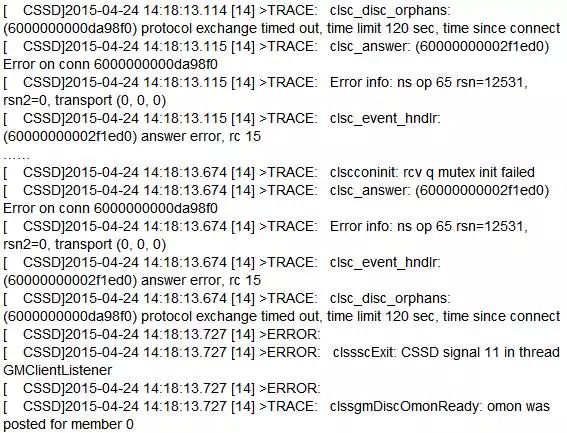
clssscExit:CSSD signal 11 in thread这个报错以前没有碰见过。
对这个报错的相关解释:当RAC GM client监听线程在处理"clsc_disc_orphans"时,CSSD.LOG中会出现"clsc_disc_orphans"的信息,该函数在处理clsc_disc尝试断开连接时,负责获得和持有线程信息。存在BUG(Bug 9132429: LNX64-10205-CRS:NODE CRASH AFTER 5 MINUTES OF HANG/RESUME OCSSD.BIN。)可能导致多个session形成死锁,最终导致节点HANG住或被驱逐宕机。
MOS上的这个Bug 9132429是在Linux平台上,当前主机是HP-UX。请网络组检查心跳交换机,没有发现闪断或者其它异常。由于没有检查到有用的信息,认为这可能是ocssd.bin进程的偶然报错现象,暂时没法解释这个问题。
07月23日,xx2db02发生宕机,检查结果和4月23日一样,其它全部没有信息,只有ocssd.log日志信息如下:
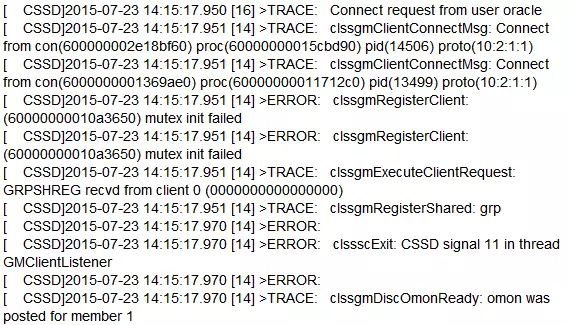
经过确认,主机重启是由于ocssd的GMClientListener问题导致。由于未在主机上安装系统资源监控工具,没有有效的主机资源使用情况。在MOS上了开SR,SR回复可能是主机资源使用存在问题,但没有OSW的信息,他们给不出解释。
7月27日,xx3db02宕机,Oracle Support认为在ocssd.log中存在Authentication OSD error信息,可能是认证失败导致GMClientListener发生问题,进而cssd.bin进程宕掉。相关日志信息如下:
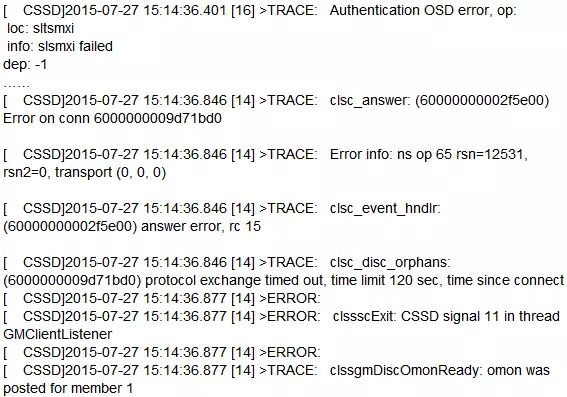
认证信息失败的原因,可能有以下几点:
1、节点间有防火墙 【没有配置】
2、节点间有authentication tools 【未配置】
3、$ORA_CRS_HOME/crs/css目录权限发生改变 【未发生】

4、/oracle文件系统满 【未满】
5、/tmp目录下的.oracle目录被删除 【未删除】
6、节点间认证信息网络包发生问题 【无证据】
而前两次宕机,没有Authentication OSD error的信息,所以没有直接证据表明Authentication OSD error造成了CSSD signal 11 in thread GMClientListener,Authentication OSD error错误信息也可能是结果,不是根本原因。
监控系统上主机资源使用情况如下,CPU使用率:
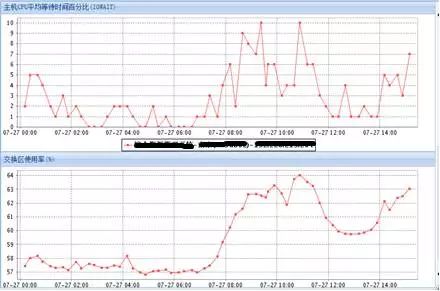
IO使用率:
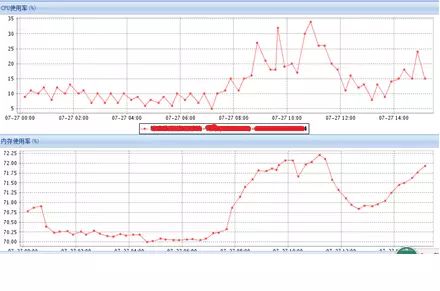
SR认为监控粒度太粗。给这4套RAC、8个节点全部安装了OSWatch,下次如果有其它节点宕机就有详细的操作系统资源使用信息。
7月30日,xx2db01宕机,日志信息如下:

发生“clsc_event_hndlr: (6000000000ae51b0) answer error, rc 15”,Oracle认为是操作系统发生了问题。
检查ulimit信息:
root@xx2db01:/#ulimit -a
time(seconds) unlimited
file(blocks) unlimited
data(kbytes) 4194300
stack(kbytes) 392192
memory(kbytes) unlimited
coredump(blocks) 4194303
nofiles(descriptors) 20480
root@xx2db01:/#su - oracle
oracle@xx2db01:/oracle#ulimit -a
time(seconds) unlimited
file(blocks) unlimited
data(kbytes) 4194300
stack(kbytes) 392192
memory(kbytes) unlimited
coredump(blocks) 4194303
nofiles(descriptors) 20480
检查file相关的内核参数:
oracle@xx2db01:/oracle#/usr/sbin/kctune |grep file
fcache_seqlimit_file 100 Default Immed
filecache_max 130470211584 Default Auto
filecache_min 13047017472 Default Auto
max_acct_file_size 2560000 Default Immed
maxfiles 20480 20480
maxfiles_lim 20480 20480 Immed
检查nproc内核参数:
oracle@xx2db01:/oracle#/usr/sbin/kctune |grep nproc
nproc 30000 30000 Immed
oracle@xx2db01:/oracle#/usr/sbin/kctune nfile
Tunable Value Expression Changes
nfile 0 Default Immed
SR认为这些参数都正常。上次故障时,在所有节点上都安装了OSW工具,这次有了相关主机资源信息。经过检查,vmstat中显示:从7月30号的08:42到宕机时的09:34,一直存在pi的情况,而空闲内存为11g左右。xx2db01主机是256G内存,sga_max_size=100g,pga_aggregate_target=40g。
宕机时vmstat信息如下,空闲内存为11g,有一些内存页交换。

而正常情况下xx2db01主机的空闲内存是100g,pi基本为0。
经过检查,内核参数filecache_max 130470211584 Default Auto这个参数表明主机允许文件缓存最大为130g左右,该参数设置较高,有可能占用大部分内存,但是OSWatch没有监控这个参数,所以宕机时无文件系统缓存的相关信息。当前使用了Veritas ODM,基本用不到操作系统缓存,建议把该参数调整到10g。
在宕机时的ps输出文件中存在大量的sendmail和rmail进程,但具体不清楚是什么作用。
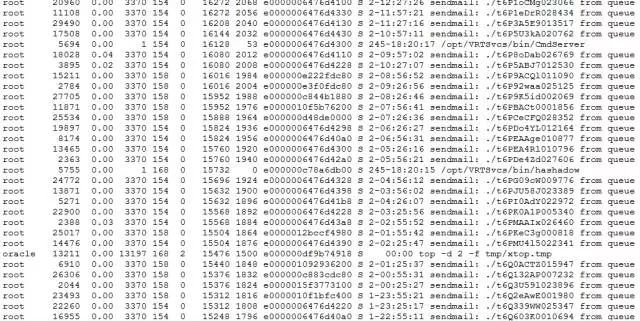
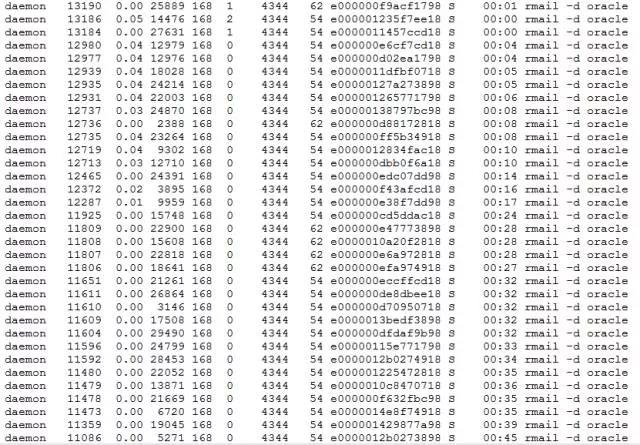
这次故障的原因,猜测是主机swap造成,但从vmstat中监控到主机空闲内存还有11g左右(主机内存是256g),不怎么确认一定是主机内存耗尽导致ocssd.bin出现故障。
暂时建议:
filecache_max调整到10g左右,减小文件系统占用内存导致宕机的概率。
调整CSSD的日志级别为4,让cssd出故障时,输出更多的日志信息。
crsctl debug log css CSSD:4
8月19日,xx3db01节点也是因为“CSSD signal 11 in thread GMClientListener”发生宕机重启。vmstat查看宕机时内存使用情况,发现宕机时空闲内存有将近80g,这又排除了内存紧张,主机swap导致的问题。
通过详细检查OSWatch日志,发现了宕机时ocssd.bin内存占用达到8g。

跟SR交流,SR建议以下ulimit设置为unlimited,如下:
data(kbytes) unlimited
stack(kbytes) unlimited
我检查了7月30日宕机时,ocssd.bin的大小,发现也是8g左右。

怀疑是不是进程所使用的内存达到限制导致,这时侯我咨询了主机工程师,是否有内核参数,限制一个进程能够使用的内存大小,查到如下参数:
root@xx3db01:/ # kctune | grep maxdsiz
maxdsiz 4294963200 4294963200 Immed
maxdsiz_64bit 8589934592 8589934592 Immed
这两个参数解释如下:
maxdsiz、maxdsiz_64bit,是指任何用户进程的数据段的最大大小(以字节为单位)。HP-UX 系统上的用户程序由五个不连续的虚拟内存段组成:文本(或代码)、数据、堆栈、共享的和 I/O。每个段都占用一段已设定大小上限的结构化定义的虚拟地址空间范围,但由于 maxtsiz、maxdsiz 和 maxssiz 可调参数的强制约束,文本、数据段和堆栈段的最大值可能会略小。此可调参数定义了 32 位和 64 位进程的静态数据存储段的最大大小。数据存储段包含了固定的数据存储,例如使用 sbrk() 和 malloc() 在main()、字符串和空间中分配的全局变量、数组变量、静态变量和局部变量。
检查其它HP-UX上的10g库,发现10.2.0.4的RAC,ocssd.bin内存占用正常,而所有10.2.0.5版本的ocssd.bin内存占用在缓慢增加。
检查未发生过宕机的xx4db02节点上ocssd.bin进程一段时间的内存使用情况,确认存在内存泄露问题。

猜想可能是内存泄露导致了ocssd.bin内存占用过高,达到操作系统限制,造成ocssd.bin出现问题,进而宕机重启。经过到MOS上检查,发现如下Bug:
Memory usage of crsd.bin and ocssd.bin keeps growing after upgrade to 10.2.0.5 (文档 ID 1633236.1)
Bug 11704113 - OVER TIME THE MEMORY USAGE OF THE CRSD.BIN PROCESS GROWS TO VERY LARGE VALUES
SR也确认是由于crsd.bin的nsdo()函数发生内存泄露,导致ocssd.bin受影响。当前情况与MOS文档上描述一致。
问题的根本原因是,由于存在如下Bug:
Memory usage of crsd.bin and ocssd.bin keeps growing after upgrade to 10.2.0.5 (文档 ID 1633236.1)
Bug 11704113 - OVER TIME THE MEMORY USAGE OF THE CRSD.BIN PROCESS GROWS TO VERY LARGE VALUES
导致ocssd.bin进程的内存使用率持续上升,达到了maxdsiz_64bit内核参数的限制,进而造成ocssd.bin进程故障,ocssd.log日志中的“clssscExit: CSSD signal 11 in thread GMClientListener”信息,signal 11代表内存申请失败。
解决办法有两个:
打CRS补丁11704113
由于内存泄露缓慢,可能要半年到一年左右,ocssd.bin的内存使用才能达到限制,并且只有在特定的版本和平台上存在这个问题,可以监控一下ocssd.bin进程的内存使用率,在快达到限制前,手工重启下CRS。
这个问题非常之隐蔽,会被很多因素遮盖掉,因为在1年时间之内,主机很可能因为维护、硬件故障等造成了主机重启,而重启主机后CRS的ocssd.bin进程的内存就释放了,又要经过长时间的内存泄露才会触发。如果没有多套RAC的长时间稳定运行,宕机后操作系统资源使用数据的相互交叉比对,很难诊断出根本原因。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721