
本文根据DBAplus社群第79期线上分享整理而成
唐波
中科院高级工程师
资深EBS套件DBA
DBAplus社群联合发起人,Oracle 10g/11g OCM、RHCI,中国东南甲骨文用户组secoug主席,ACOUG&SHOUG核心成员。
中科院最佳技术顾问、知名WDP讲师,福建省第一批Oracle ERP实施顾问。
大家好,我是来自中科院的唐波,今天我将跟大家分享如何使用保障前台业务0暂停的方式,从Oracle 11gR2 MAA升级到Oracle12c MAA。
本次分享将包括以下4个方面:
1. 环境概览
2. 通过两次Dataguard切换,升级所有GI
3. 通过Transient Logical Standby转换,升级所有DB
4.总结
一、环境概览
1、升级前环境概览
将要升级一套11.2.0.4的MAA系统到12.1.0.2。系统是x8664架构,MAA架构中 station11和station12运行两节点RAC主库,station13和station14运行Data Guard物理备库。
station11:
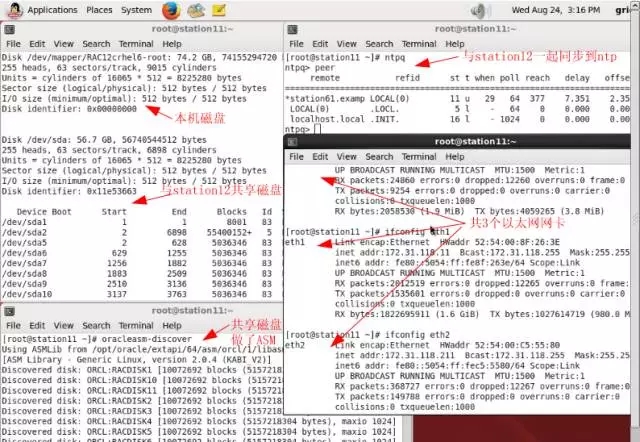
1-1-station11.png
Station12:
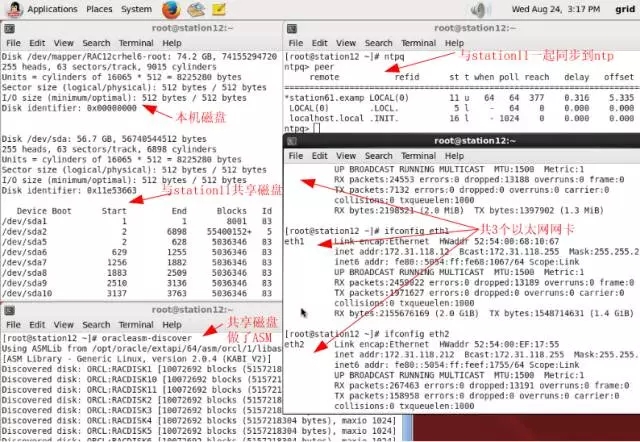
1-1-station12.png
Station13:
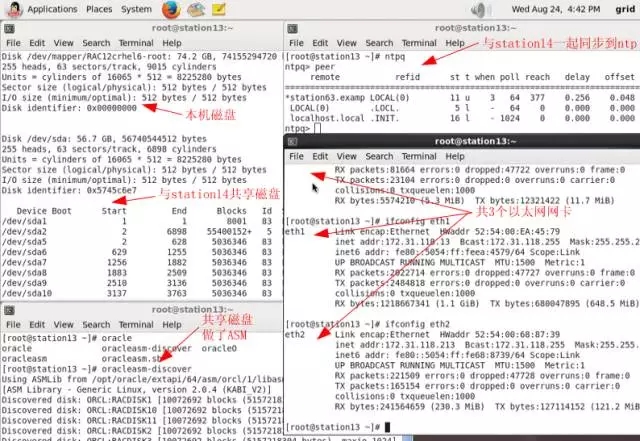
1-1-station13.png
station14:
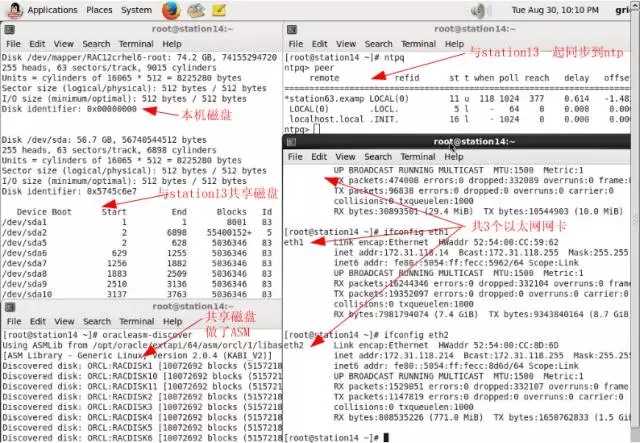
1-1-station14.png



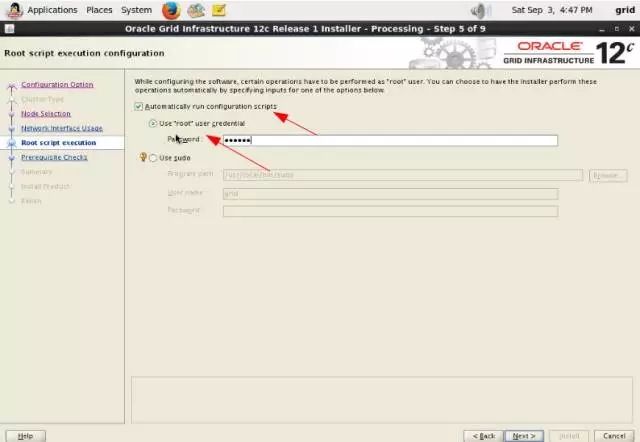
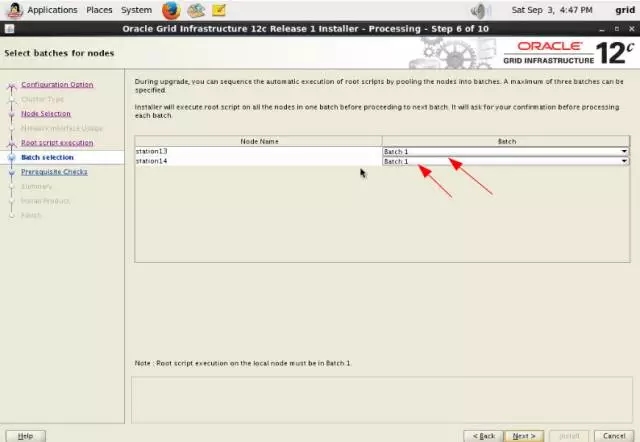
下面将要使用Oracle Grid Infrastructure Configuration Utility在以上两套网格基础架构的各个节点上进行升级。为了尽量不影响主库,我们先升级备库两个节点(升级之前这两个节点,可能要通过添加共享磁盘扩大+DATA和+FRA盘组的大小,保证 +DATA可用空间不小于8G)。station11、station12、station13和station14都以grid用户预先采用“software-only installation”选项在/u01/app/12.1.0/grid目录下安装了12.1.0.2.0版本的Grid Infrastructure软件。
1-2-station13.png
2-1-station13.png
2-2-station13.png
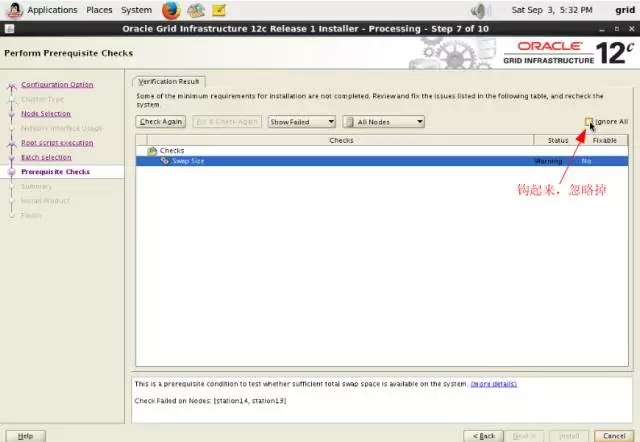
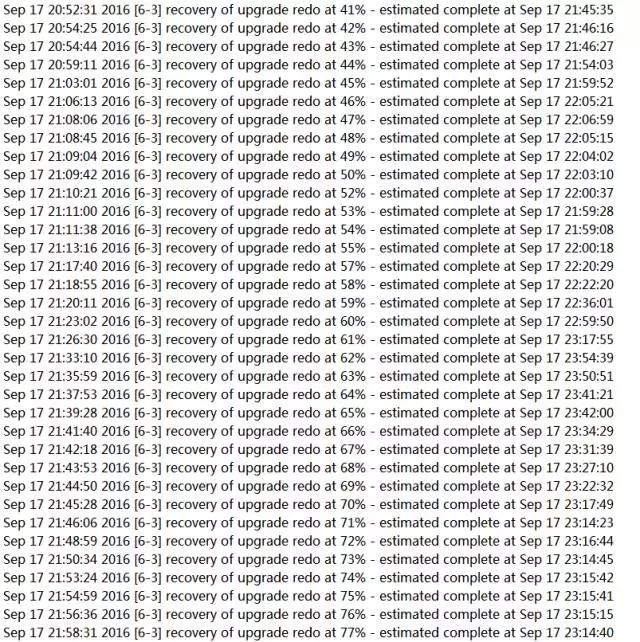
在station11的/u01/app/oraInventory/logs目录下面看日志,在我的环境中执行了46分钟:
2-3-station13.png
2-4-station13.png
2-5-station13.png
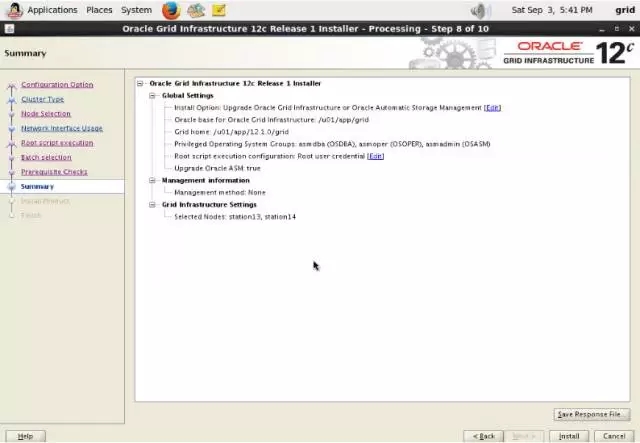
2-6-station13.png
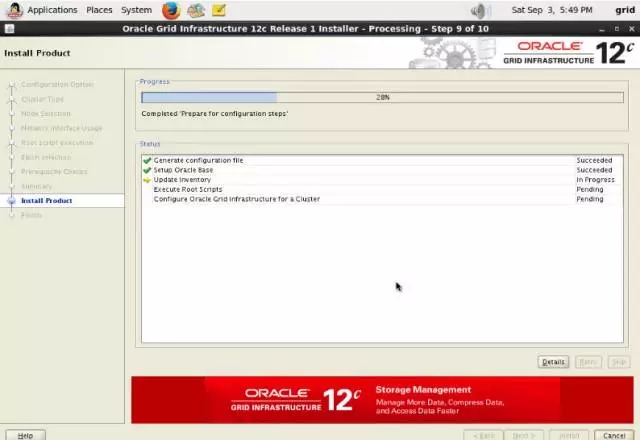
2-7-station13.png
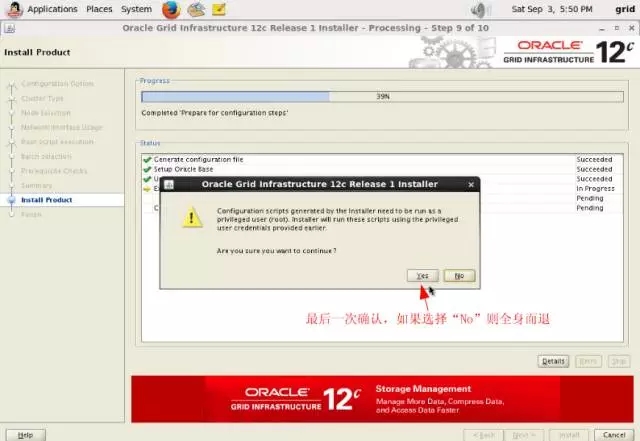
2-8-station13.png
在station11的/u01/app/oraInventory/logs目录下面看日志,在我的环境中执行了46分钟:
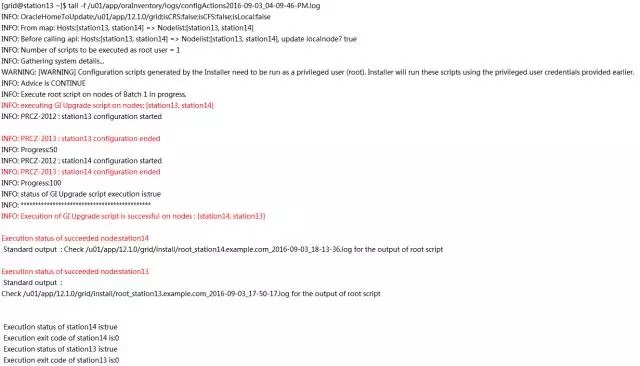
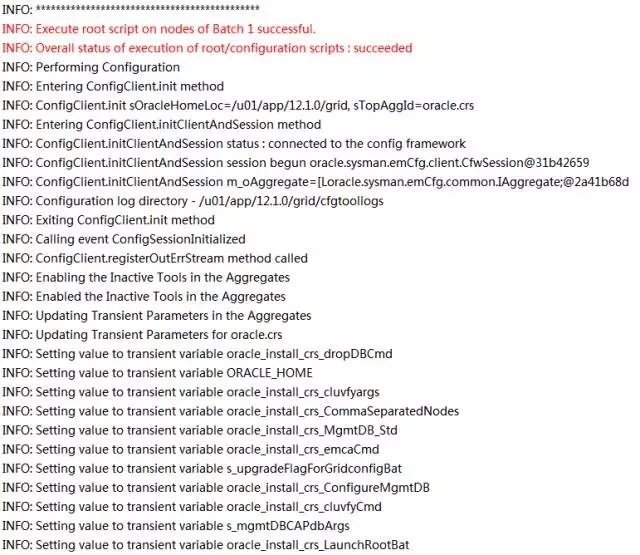








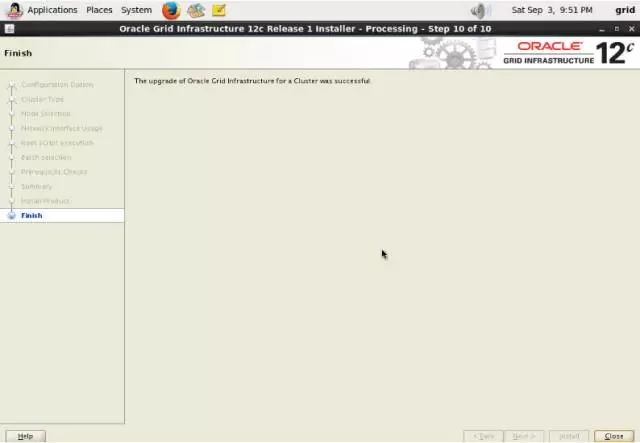
2-10-station13.png
2、 备库升级后环境概览

二、通过两次Dataguard切换,升级所有GI
1、主库Dataguard切换

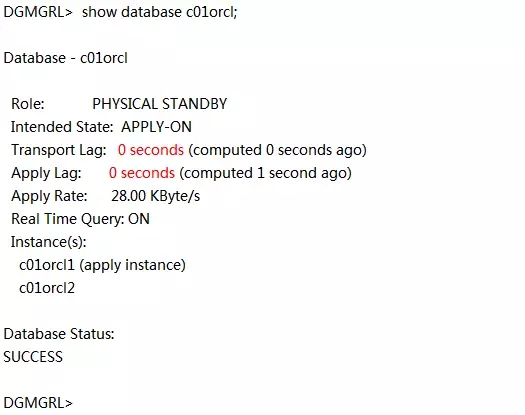
并且确保备库接收日志没有延迟,应用日志也没有延迟。



确保新备库接收日志没有延迟,应用日志也没有延迟。
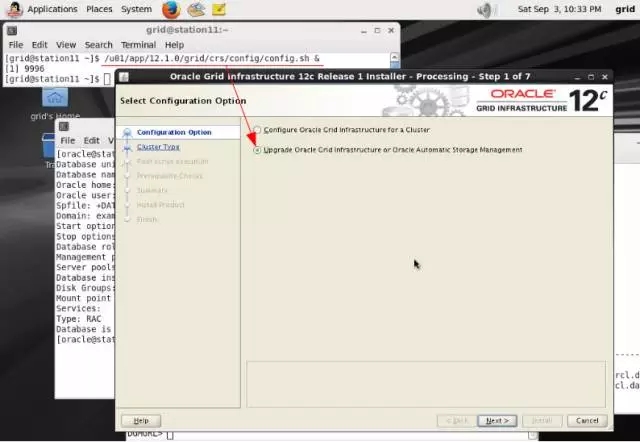
下面将要使用Oracle Grid Infrastructure Configuration Utility在station11上升级网格基础架构。
3-1-station11.png
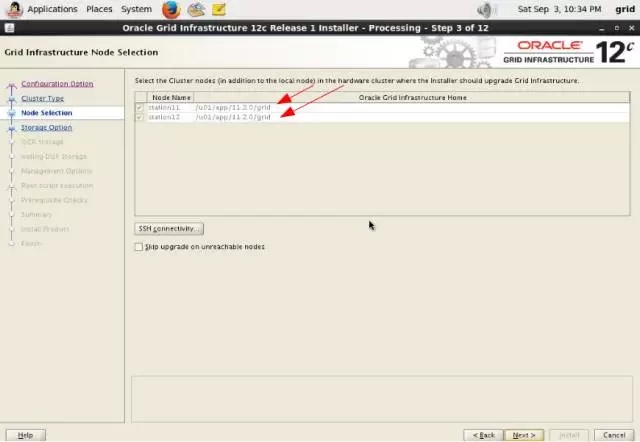
3-2-station11.png
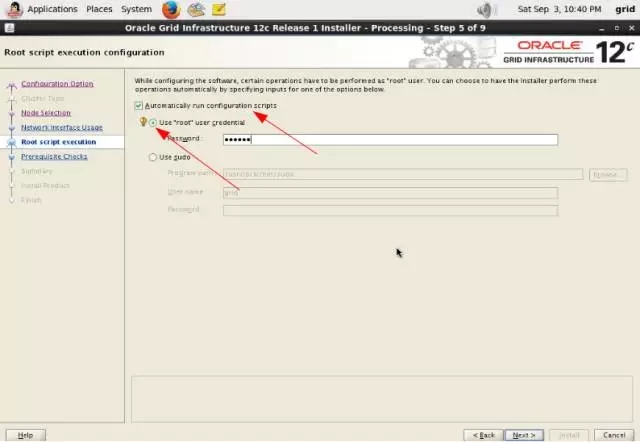
3-3-station11.png
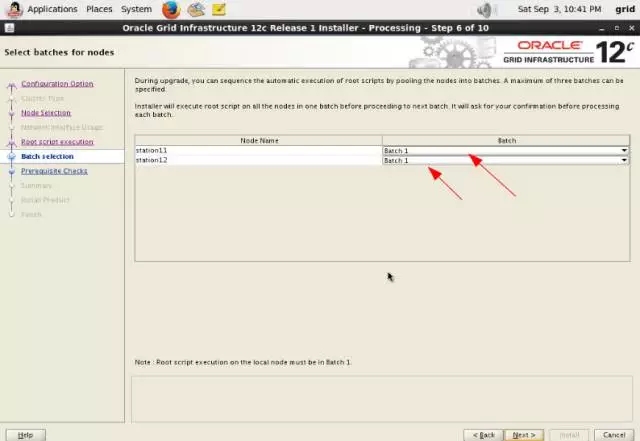
3-4-station11.png
3-5-station11.png
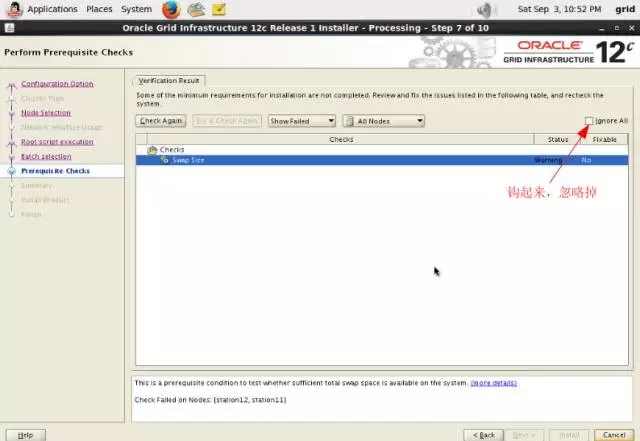
3-6-station11.png
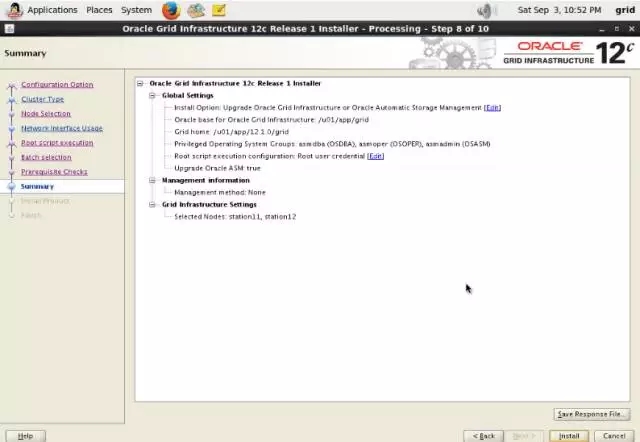
3-7-station11.png
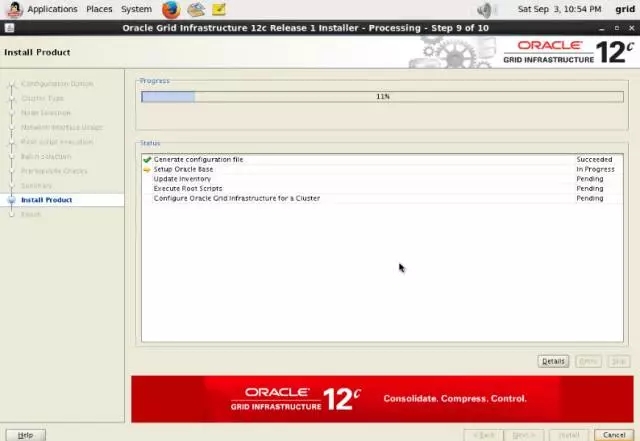
3-8-station11.png
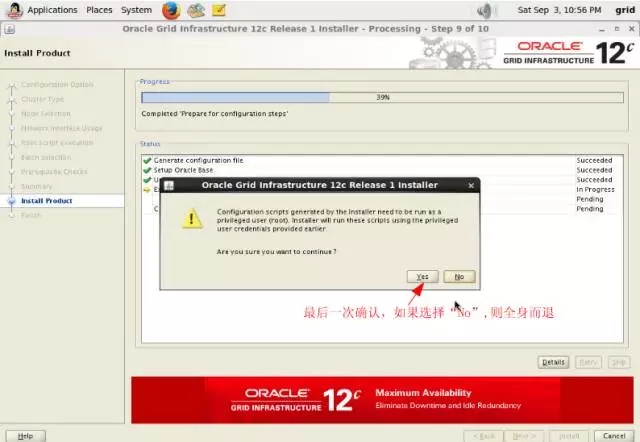
3-9-station11.png
如果进度条在44%时报错,点“retry”就是。



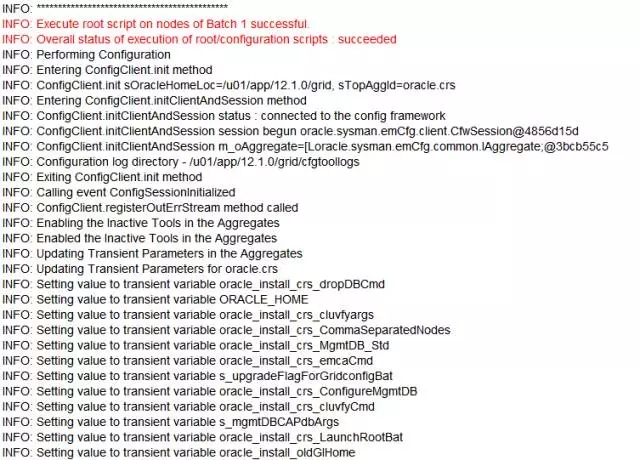

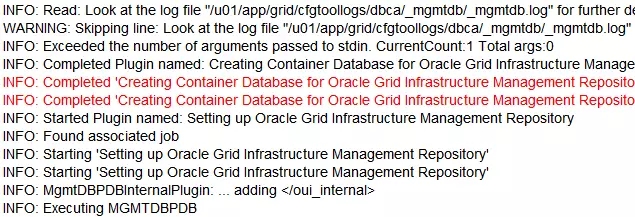






3-10-station11.png
2、原主库(新备库)升级后环境概览

3、主库Dataguard切换,原主库(新备库)重新成为主库

并且确保备库接收日志没有延迟,应用日志也没有延迟。
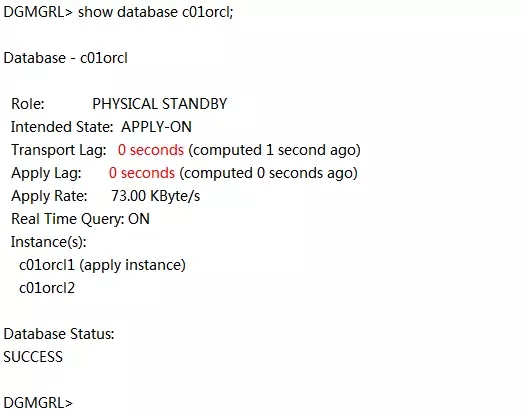


确保新备库接收日志没有延迟,应用日志也没有延迟。
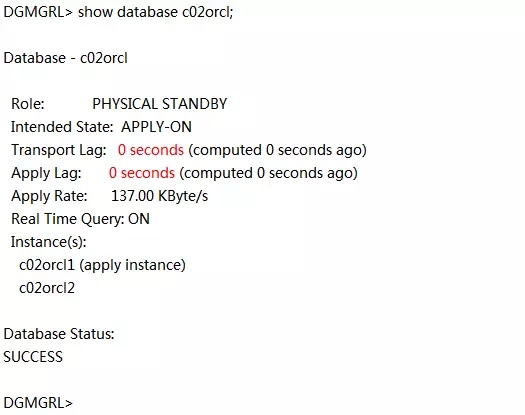
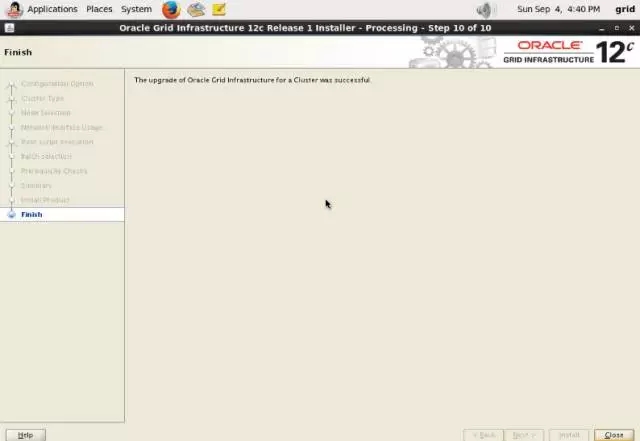
到此四台主机上的GI都成功升级完成,请把station11和station13上/home/grid/.bash_profile文件以grid用户都改成:

改后都要以grid用户使其生效:

请把station12和station14上/home/grid/.bash_profile文件以grid用户都改成:

改后都要以grid用户使其生效:

三、通过Transient Logical Standby转换,升级所有DB
1、My Oracle Support Bulletin 949322.1综述
到此,我们已经升级了所有的GI。下一步我们要准备升级MAA中的两个数据库,并且要在升级过程中使用Rolling Patch技术以期达到对前台业务的0影响。我们注意到早在2015年2月5日已经发布的My Oracle Support Bulletin 949322.1专注于在Linux/UNIX上实现这一工作并提供一个叫做“physru.sh”的Bash Shell脚本来具体实施。但是949322.1标注的适用范围是11.1.0.6(含RAC)到11.2.0.4(含RAC)。
于是需要仔细评估一下这个由大量SQL操作和验证语句写成的“physru.sh”脚本在我们这套MAA数据库从11.2.0.4升级到12.1.0.2的场景里的适用性,最后需要进行严格实验测试。
My Oracle Support Bulletin 949322.1中提到的 “Transient Logical Standby” 应该指的是为了执行升级目的而临时由物理Standby数据库转换成的逻辑Standby数据库;通过在转换前设定保障闪回还原点可以在升级后再转换回物理Standby架构。 “Transient Logical Standby”的概念最早出现在11.1,见Oracle官网解释。利用转换“Transient Logical Standby”过程,可以在升级或打冷补丁时实现前台业务0暂停。因为GI升级完成后接下来升级数据库软件,这下难题出现了:如果我们先升级物理备库到12.1.0.2,那么备库(12.1.0.2)和主库(11.2.0.4)的版本就会不一样。
大家都知道的基本常识是:物理备库和主库数据库软件版本必需完全一样(这两个库的数据文件都是能互替!)。如果数据库软件版本不一样,基于物理Standby的MAA架构就不复存在了,进而就根本不可能Switchover,再进而就完全不可能进行Rolling Patch。但是又要保障前台业务0暂停,所以我们就不能在升级数据库软件过程中破坏的Dataguard架构。大家知道:Oracle只有两种Dataguard:A. 物理Standby和B. 逻辑Standby。因此经过以上解释,所有人都会自然得出结论:为了保障前台业务0暂停,在升级数据库前,应该先把原先基于物理Standby的MAA架构转成基于逻辑Standby的。这个过程有以下几个优点:
逻辑Standby的SQL Apply是允许主库版本低于备库版本的。
利用已经存在的物理Standby转换成 Transient Logical Standby,不需要额外的存储,不需要部署另外一套逻辑Standby。
整个过程中只要升级Transient Logical Standby 数据库的数据字典到12c。通过对升级过程中的日志进行挖掘,进而再进行SQL Apply,剩下的一个库会“隐式”升级成12c。
2、升级前的准备工作
实验到此为止,我们已经完成了升级MAA的所有两个GI的工作。下面要对MAA中主库和备库做准备工作,以期望能够顺利完成剩下的DB Rolling Patch。
(1)停用Datagurad Broker
在station11上执行:

在station11上执行:

在station13上执行:

(2)确保主库和备库闪回区都存在,并都设置了正确的大小
在station11上执行:

在station11上执行:

在station13上执行:

在station13上执行:

(3)主库和备库都配置闪回数据库
在station11上执行:

在station13上执行:

(4)确保升级前,备库进行着健康的Recover Managed Standby Database
在station13上执行:

3、第一次执行physru.sh
数据库滚动升级过程包含许多步骤和多次数据库角色切换并且需要严格按照顺序进行。为了简化这个过程,也为了减少出错可能性,My Oracle Support Bulletin 949322.1提供了由SQL语句和验证过程编写而成的Bash Sell脚本:physru.sh。脚本会探测每一步的执行状态,有些步骤需要同时开另一Terminal进行手工操作。需要手工操作时会给出指引(RAC环境需要手工操作的地方还是比较多的)。
physru.sh允许出错重试,重试时会提示是否要从上次执行位置开始或者干脆从头再来。physru.sh被设计成至少要在第一次调用处(带着相同的6个参数)重复执行三次,才会成功完成整个Rolling Patch过程。本人下载了该脚本,并且将其存放在station11的/home/oracle/目录下。然后用dos2unix工具将其转成UNIX格式后再加上可执行位并执行。(在本文附录stage2中加密了该脚本,它是MOS的财产,请读者自行去MOS下载)。
在station11上不带任何参数执行输出如下(执行会报错,但是会看到physru.sh的自我介绍):

应该特别注意:以上输出中提到在“RAC配置中需要提供只连接到某个特定实例(一般是第一个实例)的TNS串” 。也就是说这个TNS串不能包含任何Load Balancing或Failover配置。同时可以得出推论:physru.sh可以使用这个TNS串实现远程打开数据库。因此在运行physru.sh前应该分别在station11和station13的 /u01/app/12.1.0/grid/network/admin/目录下配置相应的listener.ora文件。使服务名c01orcl.example.com在station11的监听器上做静态注册;使服务名c02orcl.example.com在station13的监听器上做静态注册。
还应该特别注意:在使用physru.sh进行Rolling Upgrade过程中, Transient Logical Standby数据库可能会周期性地无法接收到来自主库的更新。如果此时万一主库发生故障,就没有备库应急,甚至会发生数据丢失。 因此在特别重要的生产环境中,要考虑到这种风险并采取相应手段比如准备备用的Logical Standby以应对。
在station11上执行(在出现提示“Please enter the sysdba password:”时输入“oracle_4U”):

报错可能是由于physru.sh遇到未公开发布的Bug12753750、Bug14174798和Bug12694192中的一个或多个所致。不做任何处理再次运行physru.sh:
在station11上执行(在出现提示“Please enter the sysdba password:”时输入“oracle_4U”):
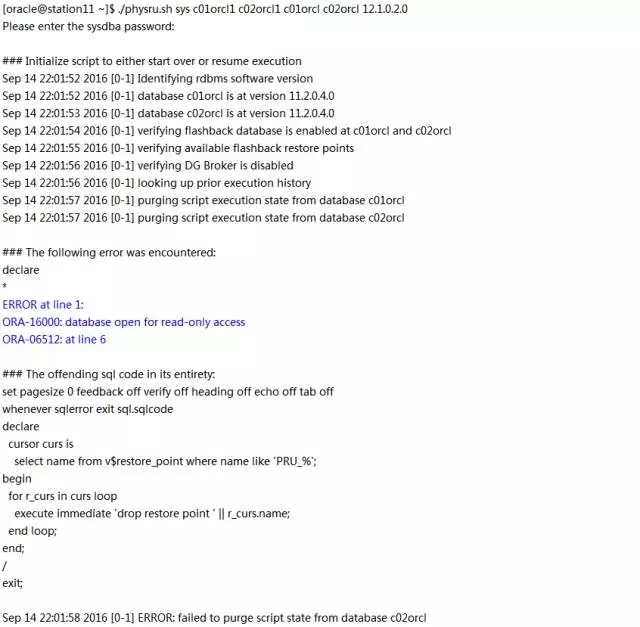
这次出错信息又变成别的了。但是这次看出来physru.sh正提醒我们关闭c02orcl的Active Data Guard功能,需要重新启动c02orcl到mount状态,并且开启Recover Managed Standby进程。照做后,还需要再删除两次出错遗留的痕迹:删除station13上的/u01/app/oracle/product/11.2.0/dbhome_1/dbs/PRU_0001_c02orcl_f.f。(还要确认c02orcl的闪回区在+FRA上)
在station13上执行:


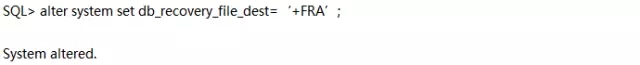
再次在station11上执行physru.sh(在出现提示“Please enter the sysdba password:”时输入“oracle_4U”):

先不输入。
以上physru.sh执行过程说明如下:在Stage 1 中主备库各创建一个保障闪回还原点PRU_0000_0001。PRU_0000_0001在后面的Stage 4(第一次Swithover)来临前都有效, 可将两个数据库回到升级前状态。 Stage 2 将要转换现有的物理Standby数据库c02orcl为Transient Logical Standby数据库。这一步是整个0停机升级过程的关键。只要转换成功,事务就仍能从主库源源不断同步到备库。physru.sh脚本中与这一步相关最关键的SQL语句如下:
脚本3779行到3809行(不能直接展示脚本内容,做了图像模糊处理):
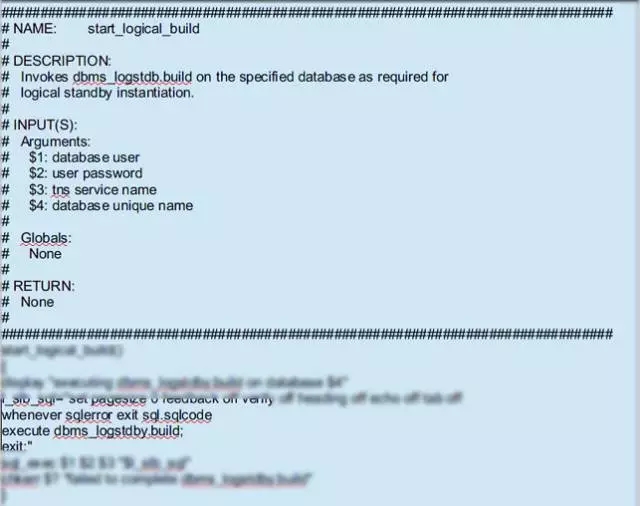
4-1-station11.png
脚本3811行到3866行(不能直接展示脚本内容,做了图像模糊处理):

4-2-station11.png
分析以上两段脚本得知转换前物理Standby备库只能启动一个实例才能执行dbms_logstdby.build。其实也可以直接根据提示做以下准备工作:
在station13上执行:
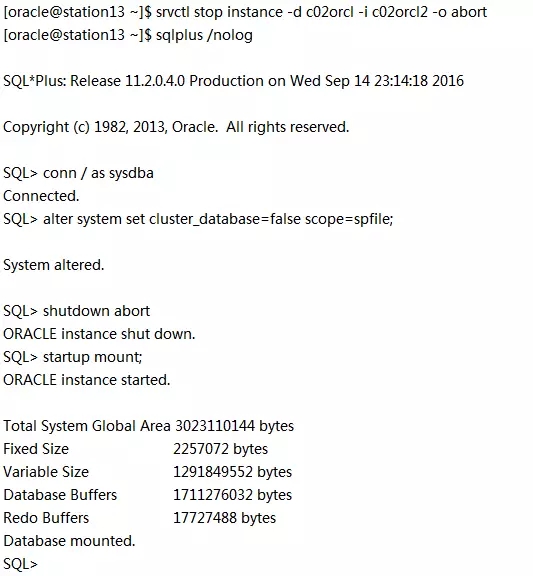
回到station11上,输入“y”:

逻辑Standby有许多对象是不支持主备库同步的。在继续 physru.sh脚本前,请查看station11的/home/oracle/physru_unsupported.log(即调用physru.sh的位置)会列出这些对象。这些对象包括:sys拥有的对象、用以支持物化视图的表、全局临时表、带压缩的表和包含bfile,rowid,urowid等字段类型的表等等。
只要生产环境不涉及这些对象,就可以安全回答"y"。如果涉及这些对象,就要额外考虑这些对象的同步问题,再回答"y"。本文附录中有physru_unsupported.log全文。
回到station11上,输入“y”:

到此 physru.sh的第一执行成功结束。也意味着升级过程到达stage2:c02orcl变成Logical Standby。
在station11上查看:

在station11上查看脚本执行过程中的/u01/app/oracle/diag/rdbms/c01orcl/c01orcl1/trace/alert_c01orcl1.log:

在station13上查看:
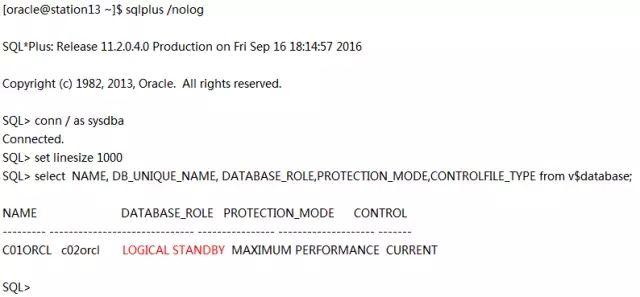
在station13上查看脚本执行过程中的/u01/app/oracle/diag/rdbms/c01orcl/c01orcl1/trace/alert_c01orcl1.log:

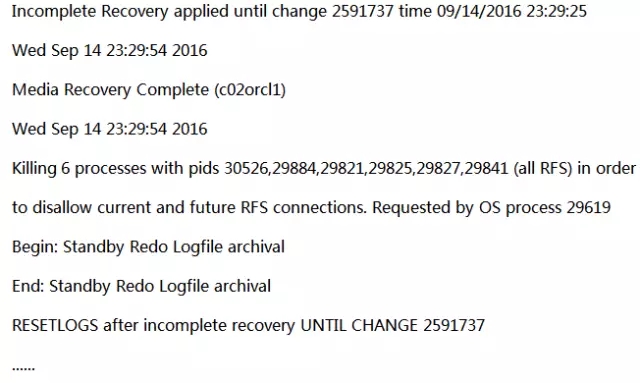


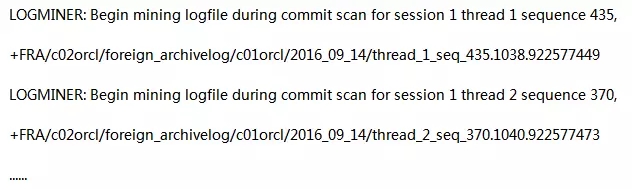
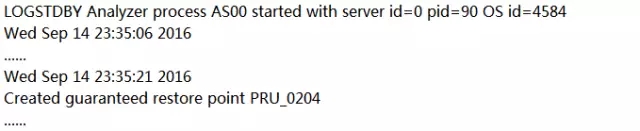
最后,如果执行physru.sh脚本出错。我们需要 c02orcl回到第一次执行前的状态。使用以下步骤把Transient Logical Standby数据库转回物理Standby数据库:

4、在Transient Logical Standby上执行dbua
因为dbua要求c02orcl所有实例都要启动,所以我们需要把被physru.sh脚本折腾成单实例的c02orcl重新启动成RAC数据库。
在3.3中physr.sh脚本执行完后,由于未说明的Bug ,在station13上的/u01/app/oracle/product/11.2.0/dbhome_1/dbs目录下会生成一个多余的spfilec02orcl1.ora文件。这个文件破坏了c02orcl数据库的正确配置,请一定将其删除。在station13上执行:

确保“+FRA/C02ORCL/foreign_archivelog/c01orcl/”有从c01orcl传送来的所有日志,确保 c02orcl上的Logical Standby Apply紧紧跟随主库,在station13上执行:
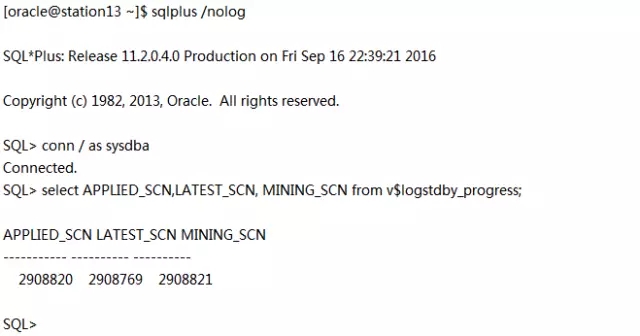
确保 LATEST_SCN<=APPLIED_SCN,在c01orcl上更新一个表做下测试Real Time Logical Apply:
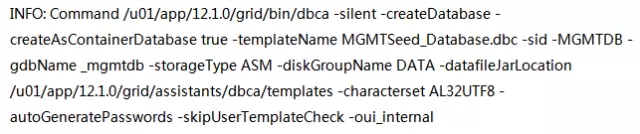
station11、station12、station13和station14都以oracle用户预先采用“software-only installation”选项在/u01/app/oracle/product/12.1.0/dbhome_1目录下安装了12.1.0.2.0版本的数据库软件。c02orcl这个Transient Logical Standby数据库已经准备好从11.2.0.4升级到12c了。我们将使用dbua这个工具来进行升级。
在station13图形界面上以Oracle用户执行:
5-1-station13.png
5-2-station13.png
5-3-station13.png
5-4-station13.png
5-5-station13.png
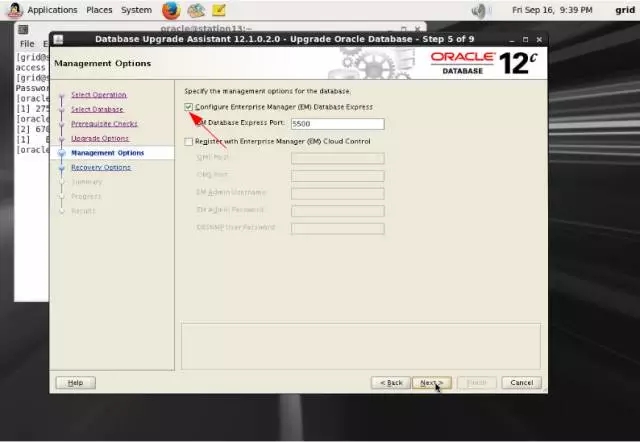
5-6-station13.png
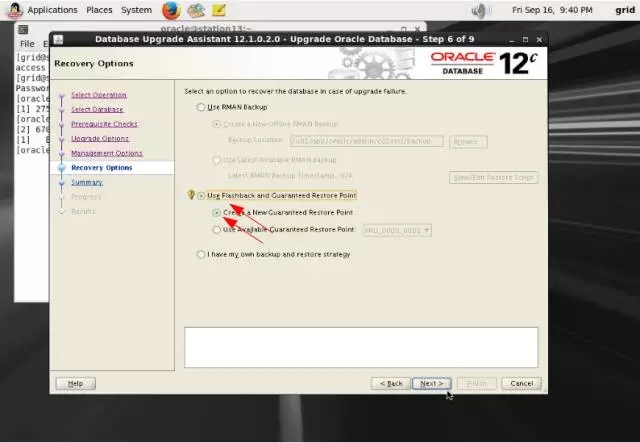
5-7-station13.png
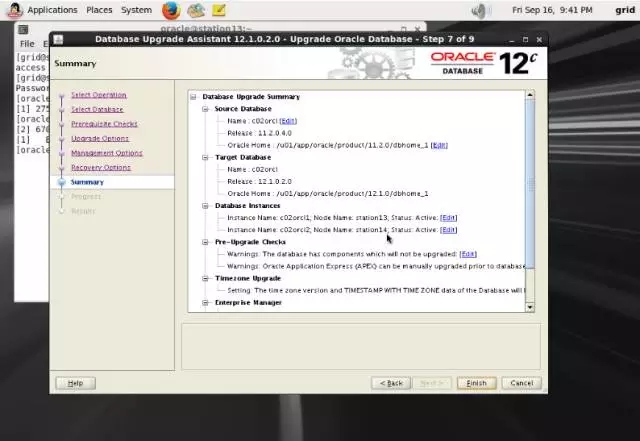
5-8-station13.png
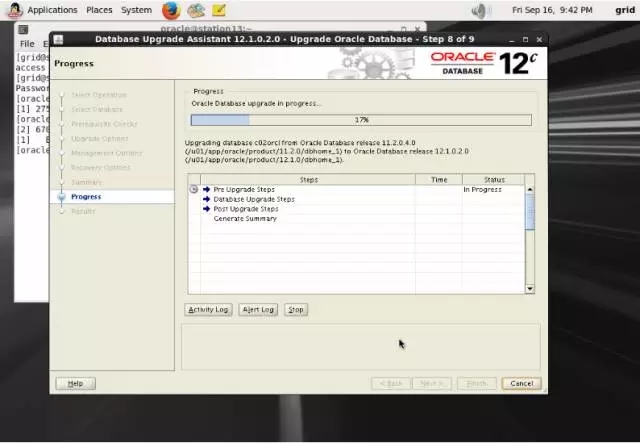
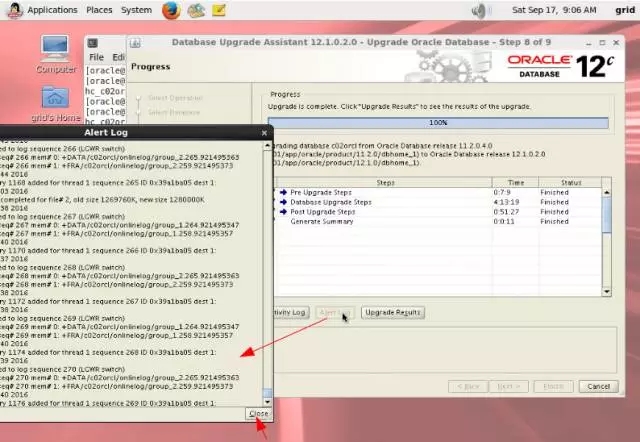
5-9-station13.png
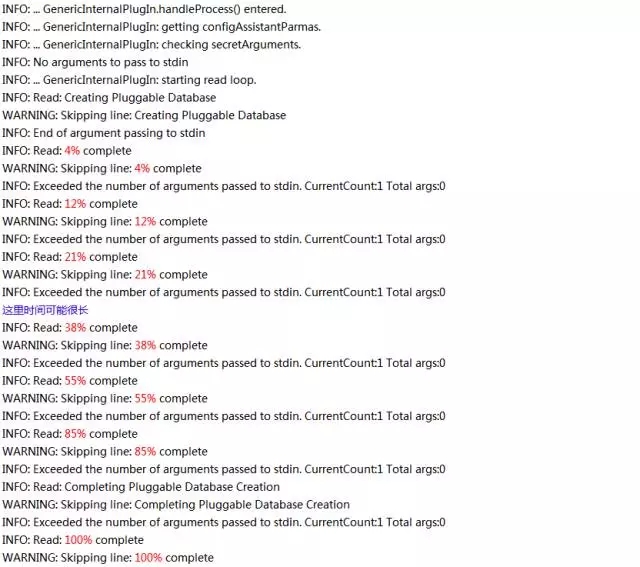
在进度条运行过程中,我们也可以到此目录下/u01/app/oracle/cfgtoollogs/dbua/c02orcl/upgrade1看日志。在截屏所示的“Pre Upgrade Steps”的这一步,c02orcl数据库会自动被关闭。然后只有一个实例启动起来以进行之后的升级。
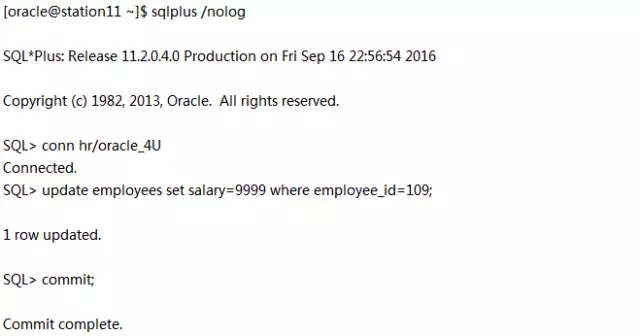
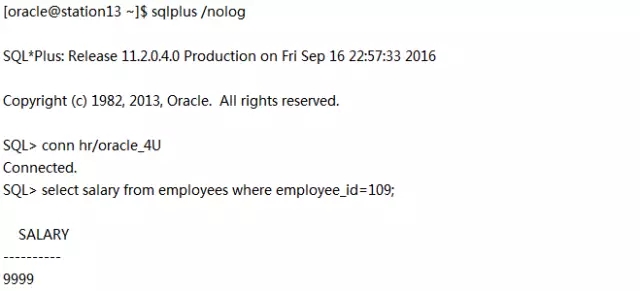
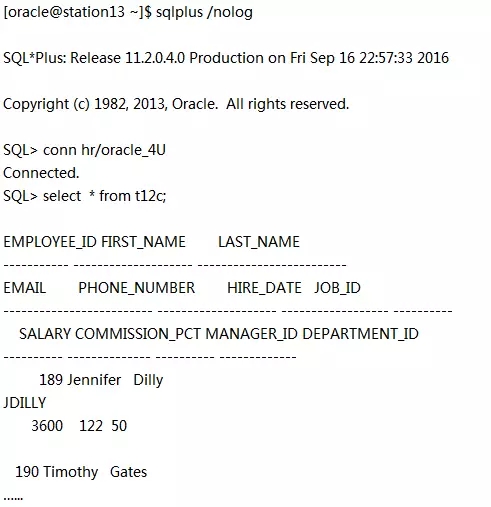
在备库c02orcl升级过程中,主库c01orcl依然打开着支持前台业务,所有在主库上执行的事务将仍然能够在c02orcl升级后应用在它身上。为了证明这一点,就在此刻,我们在c01orcl上执行:

在c02orcl升级之后,我们要在c02orcl(Transient Logical Standby)上去找这个表。
5-10-station13.png
5-11-station13.png
到此station13和station14这两台主机上的c02orcl成功升级完成,请把station13上/home/oracle/.bash_profile文件以Oracle用户改成:

改后要以Oracle用户使其生效:

请把station14上/home/oracle/.bash_profile文件以Oracle用户改成:

改后要以Oracle用户使其生效:

把station13上的/etc/oratab文件内容从:

改成:

把station14上的/etc/oratab文件内容从:

改成:

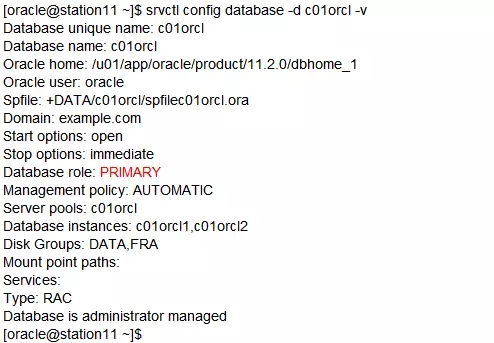
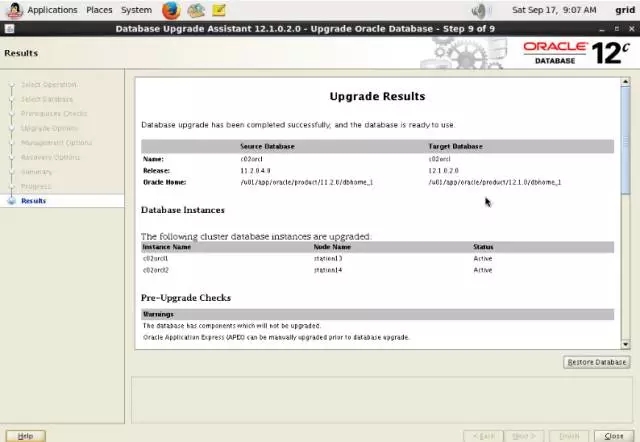
对c02orcl做一下验证:
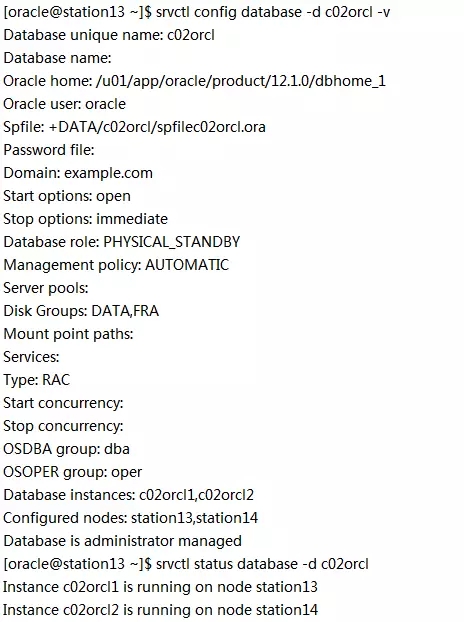
“Database role”显示成“PHYSICAL_STANDBY”是最早11.2.0.4MAA注册在集群件里造成的,不必介意。数据库真实的role是“Transient Logical Standby”。
下面来更新12c目录下的网络配置文件:


在 station13上以grid用户,把/u01/app/12.1.0/grid/network/admin/listener.ora文件改成:
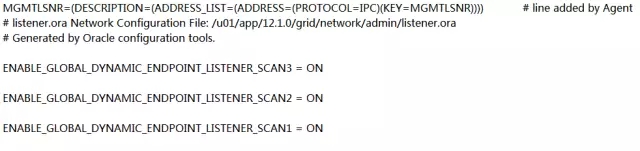



在 station14上以grid用户,把/u01/app/12.1.0/grid/network/admin/listener.ora文件改成:

在 station13上以grid用户执行:

确保“+FRA/C02ORCL/foreign_archivelog/c01orcl/”有从c01orcl传送来的所有日志,确保 c02orcl上的Logical Standby Apply紧紧跟随主库,在station13上执行:
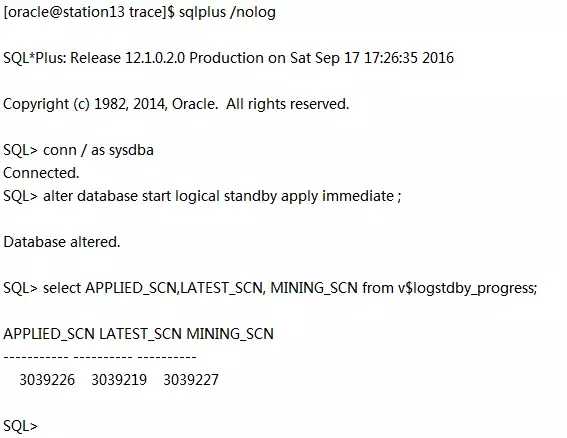
确保 LATEST_SCN<=APPLIED_SCN,验证但是在c01orcl建的表t12c是否存在:
5、第二次执行physru.sh
在station11上执行(在出现提示“Please enter the sysdba password:”时输入“Oracle_4U”):

先不输入。
在Stage 4中验证了c02orcl这个Transient Logical Standby数据库和主库c01orcl同步。在Stage 4的最后,执行标准的Dataguard Switchover,使c02orcl成为新主库,而c01orcl成为新的Transient Logical Standby数据库。在Stage 5中,c01orcl将闪回到之前的保障闪回还原点PRU_0000_0001。这样使c01orcl回到物理Standby的状态,并能在之后的 Media Recovery过程中紧紧地跟随上c02orcl。为此目的需要在station11上执行:

回到执行physru.sh的窗口:

6、手工重配置cluster01以便使用12.1.0.2数据库软件直接打开c01orcl到mount的状态
c01orcl已经闪回到之前的保障闪回还原点PRU_0000_0001。这样c01orcl已经由逻辑Standby回到物理Standby。如前所述station11、station12、station13和station14都以oracle用户预先采用“software-only installation”选项在/u01/app/oracle/product/12.1.0/dbhome_1目录下安装了12.1.0.2.0版本的数据库软件。接下来,我们要手工重配置cluster01以便使用12.1.0.2数据库软件打开c01orcl到mount的状态。
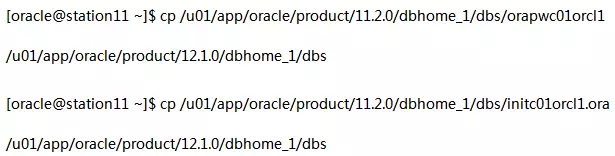
在station11上以Oracle用户执行:
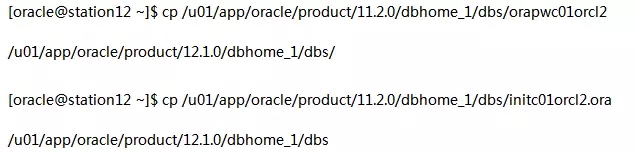
在station12上以oracle用户执行:
为了让12c数据库软件能够有权限访问ASM磁盘组。需要在station11和station12上都以root用户执行setasmgid:


在GI中重新注册12c的RAC数据库资源:

请把station11上/home/oracle/.bash_profile文件以Oracle用户改成:

改后要以Oracle用户使其生效:

请把station12上/home/oracle/.bash_profile文件以Oracle用户改成:

改后要以Oracle用户使其生效:

把station11上的/etc/oratab文件内容改成:

把station12上的/etc/oratab文件内容改成:
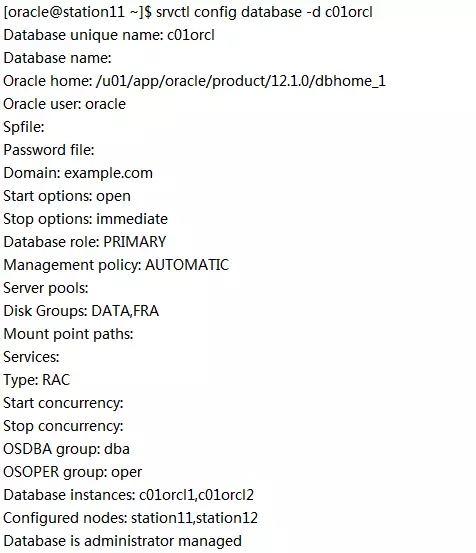
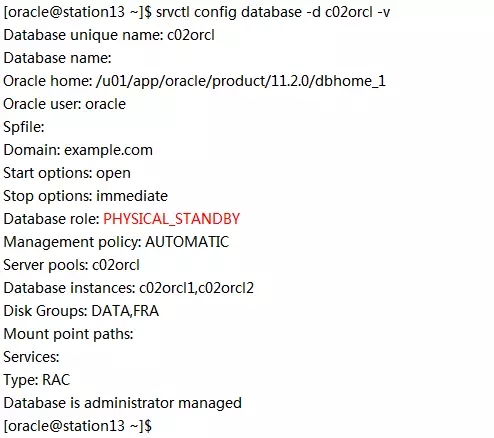
对c01orcl做一下验证:

“Database role”显示成“PRIMARY”是最早11.2.0.4MAA注册在集群件里造成的,不必介意。数据库真实的role是“PHYSICAL_STANDBY”。
下面来更新12c目录下的网络配置文件:

在 station11上以grid用户,把/u01/app/12.1.0/grid/network/admin/listener.ora文件改成:



在 station12上以grid用户,把/u01/app/12.1.0/grid/network/admin/listener.ora文件改成:


在 station11上以grid用户执行:
由于生产环境在之前的过程中于 +FRA中积累了大量的日志,因此建议开始3.7步骤前,尽快把station11、station12、station13和station14上的归档日志备份并移动到磁带机腾出+FRA的空间。以上建议也适用于我们的实验环境。
7、最后一次执行physru.sh
在station11上执行(在出现提示“Please enter the sysdba password:”时输入“oracle_4U”):

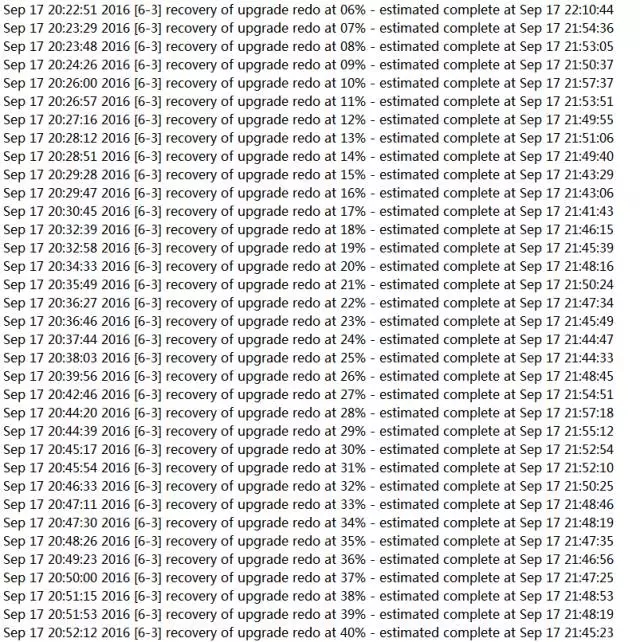

先不输入。
在Stage 6中要把c02orcl经历dbua时的所有日志通过网络传送到c01orcl并进行物理APPLY。c01orcl的物理Standby身份才能进行这种sys schema的同步(逻辑Standby是不会理睬sys schema的)。在dbua时,我们手动做的两事务(改109号员工工资和创建t12表),也会被同步到c01orcl这个物理Standby。
在Stage7中只是做Dataguard Switchover再把c01orcl变为主库。
回到执行physru.sh的窗口:

先不输入。
根据提示,在station13上执行:

回到执行physru.sh的窗口:


从以上Stage8的统计信息可以得出结论,primary services offline的时间只有短短的2分钟。而且这2分钟几乎都是Dataguard Switchover时产生的。在随后的3.8节中我们还要验证一下数据的完整性。
8、三次成功执行physru.sh后的善后工作
要想充分享受Rolling Patch这套12cMAA带来的好处,还要做一下的善后工作:
(1)打开c01orcl的所有实例
在station11上以oracle用户执行:

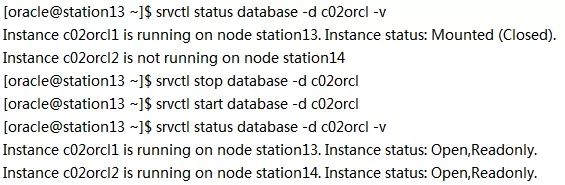
(2)打开c02orcl的所有实例
在station13上以oracle用户执行:
(3)验证在dbua过程中做的两个事务在主备库中都存在
在station11上以oracle用户执行:

在station13上以oracle用户执行:

(4)重新启用Datagurad Broker
在station11上以Oracle用户执行:

在station13上以Oracle用户执行:

在station11上以Oracle用户执行:

(5)主备库设置compatible参数为12.1.0.2.0
为了使用12c的新功能,我们要提升compatible参数的值。但是改动compatible参数要慎重,因此在改动之前应该做充分测试。比如闪回数据库不能闪回到改动该参数之前。正因为如此,首先让我们删除所有的保障闪回还原点(physru.sh在成功退出前已经删除了它创建的保障闪回还原点PRU_0000_0001,我们只需要删除dbua创建的那个就行了)。另外在Dataguard环境中要先升备库的compatible参数的值,再升级主库的compatible参数的值。
在station13上以Oracle用户执行:
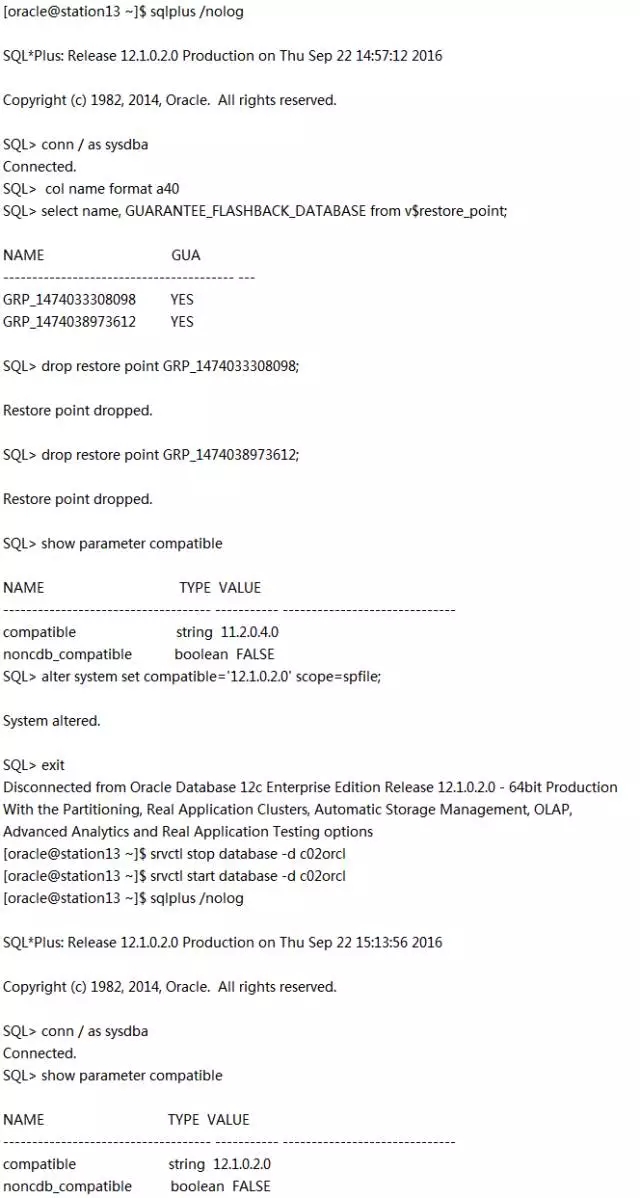
在station11上以Oracle用户执行:

四、总结
我们已经完成了Oracle MAA 从11.2.0.4滚动升级到12.1.0.2的过程。利用物理Standby->逻辑Standby->物理Standby的转换,整个升级过程中前台业务暂停的时间只有短短的2分钟,几乎可以认定是无影响。
附件:
physru_unsupported.log完整内容:
station11、station12、station13和station14的网络配置文件和克隆脚本以及其他脚本(本文中提到的physru.sh脚本是MOS的财产,做了加密)下载:
stage1_after.install.11g.primary.database.configure.11gmaa.zip
stage2_after-upgrade-12c-grid-infrastructure_NEED_MOS_ACCOUNT_TO_DECRYPT.zip









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721