
作者介绍
邹德裕,轻维软件首席数据库专家,DBAplus社群联合发起人,OraZ产品作者。10年以上运维管理经验,Oracle OCM,精通Oracle9i、10g和11g数据库技术及Linux Unix技术。对数据库系统架构具有深刻的理解,并在数据库诊断、故障排除、优化、架构设计等方面具有丰富的经验。
2013年6月26日,Oracle Database 12.1.0.1.0版本正式发布,随后在2014年7月发布了12.1.0.2.0,在2015年10月27日,Oracle在甲骨文全球大会上发布了Oracle数据库12c 第二版(Oracle 数据库12.2)公开测试版。从最初的版本到目前的版本,Oracle 12c版本在不断迭代更新,并且随着11g的支持期限即将临近,相信Oracle 12c在未来两年内将会得到更多地应用。为此,我们有必要先了解下主流数据库Oracle 12c的一些重要新特性。
由于本人主要从事DBA运维管理工作,所以更多是从DBA管理的角度讲述下Oracle 12c的新特性内容,同时12c新特性涉及到内容非常多,为了详细讲述各特性的作用和原理,计划分别从不同方面讲述12c新特性,本文主要是从内存方面讲述12c新特性。
特性一:扩展的数据库缓存
smart flash cache
在12c中提供了SGA伸展缓存,为数据块提供了二级缓存,能改善OLTP系统读能力和数据仓库的热读及批量修改能力,这种特性有点类似于Oracle Exadata的smart flash cache。对于配置了此设置的数据库,则相应的数据查找流程如下:
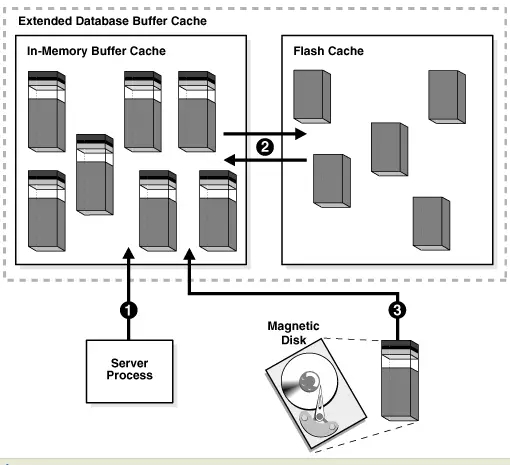
从上图可知,如果使用了Flash Cache,为数据库提供了一个二级缓存,数据从机械磁盘读取的几率将降少,从而提高数据库的响应速度。此特性主要依赖于参数db_flash_cache_file和db_flash_cache_size。
db_flash_cache_file 值为指定路径的名称,如/dev/sda或者/dev/sdb,建议使用由SSD组成的磁盘。
db_flash_cache_size 值为指定缓存的大小。大小一般建议为buffer cache的2-10倍。
如图:

使用此特性优化数据库我们需要考虑以下因素:
数据库所在操作系统必须为Solaris或者Oracle Linux,这点个人觉得使此特性有点鸡肋。
db file sequential read等待事件是一个TOP事件,可以理解成数据库需要改善I/O性能。
系统是否有空闲的CPU资源。
特性二:限制PGA内存使用
pga_aggregate_limit
参数pga_aggregate_limit限制实例分配给PGA内存大小。
在12C之前的版本,PGA的大小是无法得到真正控制的,往往会因为应用程序的异常连接暴涨导致数据库主机内存耗尽,影响了数据库系统的稳定性,此参数解决了因实例分配PGA内存过多引起换页过多,造成的一系列其他问题。当数据库设置了此参数,且PGA内存超出了此内存设置限额,Oracle会自动停止一些不能优化PGA内存的会话,如果还超出,则会直接退出这些会话.此参数的默认值为2G。
特性三:列式存储内存
In- Memory column store
以往存放在数据库的Buffer Cache的数据都是以行形式存放的,在12c中多了一种数据存放在内存的方式,那就是列式存储。目的主要是用于提高类似OLAP特点的SQL查询速度。
Oracle IM数据库允许数据分别以两种方式存储数据。这部分特性是Oracle 12c中重要的内存改变,所以会详细描述此特性的应用和原理。
Oracle数据库使用In-Memory区域存放列格式数据,In-Memory区域被划分成两个池,一个是1MB池,用于存放实际的列格式数据,一个是64K池,用于存放被加载到列格式内存的元数据,每个池的分配情况可以通过视图v$inmemory_area。至于两个池的大小由Oracle内部算法决定,不过In-Memory内存区主要分配给1MB池。

数据库中的对象要被加载到In-Memory 列式内存中,需要指定INMEMORY属性,属性可用于表空间、表、分区(子分区)和物化视图,如果将表空间属性指定为INMEMORY,那么表空间中的表和物化视图默认都具有INMEMROY属性。如指定表空间alter tablespace users default inmemory。
一般情况,具有INMEMORY属性的对象的所有列都会被加载到列式存储内存中,但是我们可以需要将部分列加载,分区表的分区也可以遵循同样的方式。
数据库通过后台进程如ora_w001_实例名将数据块加载到列式内存中。就像表空间由多个区组成,列式内存由IMCU(In-Memory Compression Units)组成。
在列式存储方式中,具有INMEMORY属性的对象,要么在数据库启动的时候根据优先级加载到内存中,要么在被查询或者扫描的时候。列式存储的优先级可以分为7个等级,分别是CRITICAL\HIGH\MEDIUM\LOW\NONE,默认情况是None。对于CRITICAL级别的,数据库在启动的时候就会被加载到列式存储内存中,HIGH级别则是在CRITICAL级别的对象加载完成后,再加载到内存中,但前提是列式存储内存还有足够的空间,后续依此如此,例如alter table IM1 inmemory priority MEDIUM。
接下来,让我们来分析下In-Memory为什么能提高查询速度。
列式存储内存采用压缩方式将数据在内存中存放。压缩可以分为6个级别,比例由2倍-20倍,分别是No Memcompress / Memcompress for DML / Memcompress for query low / Memcompress for query high / Memcompress for capactity low /Memcompress for capactity high,默认情况下,一般使用for query low属性,能为查询提供最佳性能。
For Capactity提供了另外的压缩技术OZIP,能节省更多的压缩空间,但是在使用where谓词过滤的时候,需要进行解压缩,这样会对性能有所影响。
由于分析查询一般只需要查询一个表的小部分列,In-memory可以访问只需要被查询的列,并且直接应用where谓词进行过滤,而无需解压。
Oracle会自动在列式存储的每个列创建索引。在SQL语句中会使用In-Memory存储索引进行数据过滤。存储索引不是像数据库中的索引一样,保存所有列的数据,In-Memory存储索引记录每个IMCU中的列的最大值和最小值。
当使用where过滤的查询时,In-Memory存储索引会在每个IMCU中检查制定过滤的列的值是否在,通过比较索引的最大值和最小值,如果不在,则此IMCU不会被全部扫描。如果在,再通过元数据列表进行数据过滤,元数据存放了每个IMCU不同列值的列表。
对于在IM列式存储中需要被扫描的数据,Oracle IM采用SIMD(单指令处理多个数据值)进程。这个进程允许在一个单CPU指令中一部分列值的集合被一起计算,而不是每次只对每个条目的列计算。
举个例子,在SCOTT用户下存在一个SALES表,假设我们需要统计这个表中PROMO_ID值为9999的数量。表SALES已经被加载到列式存储中。列PROMO_ID的前8个数值被加载到CPU的SIMD注册器中,并且和值9999进行匹配,想匹配的数量将会被记录下来,这整个过程都是在一个CPU指令中完成的(一次性加载的数据多少,取决于数据的类型和数据压缩情况)。

发生在IN-Memory的多表连接操作会非常高效地进行处理,因为充分列用了Bloom filters技术. Bloom filter最初在10G引进的,就是为了提高哈希连接的效率。
以上五个方面除了压缩是通过参数可以干预指定,其他都是Oracle内部自动完成的。
接下来,我们来分析下Oracle IM对于在线事务处理会有怎样的影响。
DML操作的执行一般是通过buffer cache。那么在使用了IM特性的数据库,发生了DML操作IM将会如何处理呢。对于在IM列式存储的每个IMCU,都会自动生成一个事务日志。当DML语句更改了一个对象的行数据时,则在IMCU中相应行的列条目被标示为过期的,并且新版本的行的副本被记录到IM中的事务日志中。为了提供读一致性和保持数据压缩,在IMCU的原始数据不会被立即替代.读一致性是通过SCN进行控制的。
在一个IMCU中存在越多的过期条目,则扫描IMCU将越慢。所以当在一个IMCU中过期的条目达到阀值后,Oracle数据库将会重新加载IMCU的数据。IMCU的重新加载由后台工作进程在线操作,所以数据是一直可用的,在重新加载期间内,在IMCU发生的数据变化都是被记录下来的。
除了标准的重新加载算法外,还有另外一种算法,使用较低优先级的后台进程清除所有过期的条目, 称之为IMCO进程。IMCO进程每2分钟唤醒并且检查是否有加载任务需要完成,如果发现有过期的条目则会发起重新加载。IMCO进程在2分钟时间内进行重新加载,速度和参数inmemory_trickle_repopulate_servers_percent有关,这个参数控制后台进程用于进行重新加载的最大时间百分比,越多的后台进程参与,则更多的IMCU被重新加载,然而消耗的CPU则越多。
控制IM的相关参数
INMEMORY_SIZE决定了分配给IM列式存储的内存;
INMEMORY_QUERY控制优化器查询时候是否使用INMEMORY特性;
INMEMORY_MAX_POPULATE_SERVERS 控制数据加载进程的允许的最大进程数,默认是CPU_COUNT参数值的一半。此值越大则可能进程消耗过多CPU,值太小,则会影响到数据加载速度。
INMEMORY_CLAUSE_DEFAULT 指定了in-memory中的对象的默认优先级。
INMEMORY_FORCE 控制是否使用IN-MEMORY,如果设置为OFF,即使设置了INMEMORY_SIZE参数,也不会将表加载到IM列式存储内存中OPTIMIZER_INMEMORY_AWARE 控制优化器成本计算时是否考虑IM。
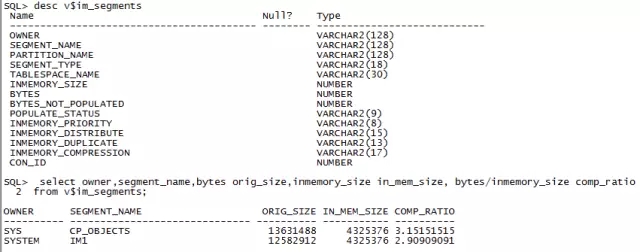
视图v$im_segments和v$im_user_segments显示了哪些对象和列被加载到IM列式存储中:
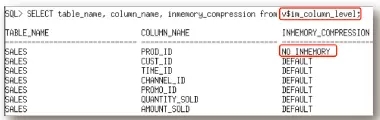
视图v$im_column_level包含了对象中哪些列被加载到列式内存中的,哪些列没有被加载。
特性四:基于对象级别的温度算法
Temperature-based, object-level replacement algorithm
从12.1.0.2开始,在以下场景大表扫描的时候会使用大表缓存:
在单实例和RAC环境中,当设置了参数DB_BIG_TABLE_CACHE_PERCENT_TARGET为非零和Parallel_degree_policy设置为auto时,并行查询就会使用大表缓存。
仅在单实例环境中,顺序排列查询能使用大表缓存。
DB_BIG_TABLE_CACHE_PERCENT_TARGET参数决定了buffer cache中用于查询扫描的大小,如果此参数设置为80,则buffer cache中的80%用于数据块的查询扫描,剩下的20%用于OLTP。
视图v$bt_scan_cache和v$bt_scan_obj_temps提供了相关大表缓存的信息。
以上技术内容来自于Oracle官方资料,是个人对Oralce 12c新特性的初步理解,更深入地研究期待后续在工作中的实践。
总之,在Oracle 12c中提供了多种技术手段用于提高OLAP类型的业务查询性能,在使用新特性时应结合业务的使用场景进行综合考虑,没有哪一种特性能确保一定会使数据库性能得到提升。
相关专题:
◆ 近期热文 ◆
◆ 近期活动 ◆
Gdevops全球敏捷运维峰会上海站

峰会官网:www.gdevops.com









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721