

嘉宾简介
《Oracle RAC核心技术解密》(即将出版)作者
Oracle首席技术支持工程师(Principal Technical Support Engineer),2007年加入Oracle 大连技术支持中心,对Oracle数据库产品有比较深刻的认识。
主要负责Oracle RAC,Exadata的技术支持工作,擅长在压力环境下处理复杂的数据库技术问题,多次成功解决国内外客户重要系统的技术问题。除了日常的技术支持工作以外,还负责MOS(https://support.oracle.com)网站上 RAC,Exadata 文档的翻译工作,在Oracle 内部定期进行数据库相关的知识分享,偶尔在Oracle 官方博客(https://blogs.oracle.com/Database4CN/)上发表技术文章。
目前,主要致力于oracle 12C 和 Exadata新特性的研究,知识分享和技术支持工作。
演讲实录
节点管理:这部分功能会负责维护数据库集群的节点(或者叫实例)列表,确保只有集群中的节点能够访问数据库,并且在节点加入集群或者离开集群时更新节点列表。另外,节点管理还负责和集群管理软件进行通信,并向集群注册数据库进程的相关信息,以便访问数据库的各种客户(client)获得相应的信息,这部分的功能作者已经在第五章的组管理(GM)部分进行了比较详细的介绍,这里就不再过多的描述了。
CGS:这部分功能实际上是Oracle RAC 的实例管理的实现方法,他负责实现实例之间的心跳机制;当实例离开或者加入集群时完成数据库集群的重新配置;解决数据库层面出现的脑裂(Split-Brain)。
所以,NM是实现实例管理的基础,而CGS是具体实现的方式,说他们是一回事也没什么问题。
节点列表位图
节点列表是一个位图,它记载了每个节点的当前状态。以一个5节点的集群为例。首先,五个节点全部正常运行。
集群对应的节点列表位图如下图:

节点列表是一个位图,它记载了每个节点的当前状态。以一个5节点的集群为例。首先,五个节点全部正常运行。集群对应的节点列表位图如下图。稍后,接下来,节点2和4 被关闭。
集群对应的节点列表位被更新如下图:

由于集群的所有节点需要具有一致的节点位图信息,所以这个位图会以资源的方式存在,也就是NM资源。当某一个节点启动或者关闭时,集群中的某一个节点会以独占(Exclusive)的方式持有这个资源,并将最新的节点状态信息更新到位图上去,之后发送最新的位图信息给其他的节点,当其他节点收到最新的位图信息之后,所有节点就拥有了相同的节点位图。
RAC 数据中包含了3种心跳
网络心跳(LMON)
磁盘心跳(CKPT+Control file)
本地心跳(LMS,LMD,LMON,LMHB,LCK0)
1、网络心跳
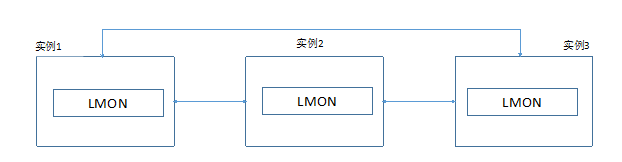
数据库层面的网络心跳是通过LMON进程来实现的,每个实例的LMON进程会定期的通过数据库的私网(Cache Fusion使用的网络)和所有远程实例进行通信,确认其他节点(实例)的状态。如果,某一个实例一段时间之内(默认300秒)不能够响应其他节点发送的网络心跳信息,那么数据库集群就需要进行重新配置,而用户能够看到的最直观的信息就是ora-29740 错误。
2、磁盘心跳
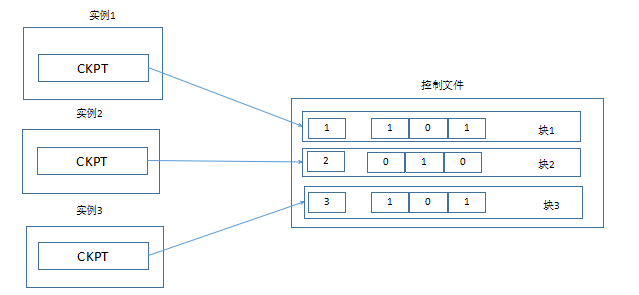
对于RAC数据库,CKPT进程默认会每3秒钟向数据库的控制文件写入本地实例能够访问到的其它实例信息,从而完成数据库实例的磁盘心跳。
3、本地心跳
事实上,本地心跳的概念是从11gR1版本开始被引入的。从11g版本开始,本地的LMS,LMON 和LMD进程会定期检查彼此的状态,如果发现了某一个进程出现了问题(最常见的就是hang(挂起)住),就可以通过重新启动实例的方式来维护数据库集群的一致性。这种行为是通过以下的三个隐含参数来控制的:
_lm_rcvr_hang_check_frequency:这个参数指定了进程之间彼此检查状态的时间间隔。该参数默认值为 60秒。
_lm_rcvr_hang_allow_time:这个参数指定了一个进程处于hang状态的最大超时时间 。该参数默认值为200秒。
_lm_rcvr_hang_kill:这个参数指定了当一个进程处于hang状态的时间超过了_lm_rcvr_hang_allow_time之后,是否允许重新启动数据库实例。该参数默认值为 false
心跳机制
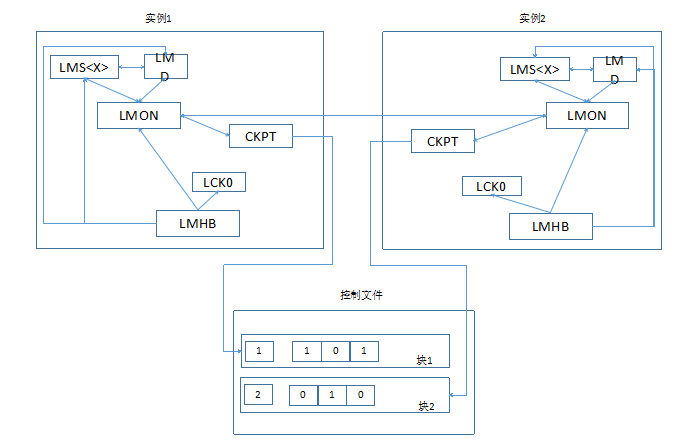
数据库层面的脑裂是指当数据库集群节点之间由于网络问题导致了彼此不能访问的情况,脑裂在绝大部分情况下出现在双节点的数据库集群丢失网络心跳的情况下。所以,数据库层面的脑裂和集群层面的脑裂是比较类似的,但是在处理方式上却有所不同。
首先,两个实例之间的私有网络出现问题。在一段时间之后(默认300秒),两个实例都发现无法和对方进行通信。
然后,每个实例都尝试获得RR 锁(就是有些资料提到的要去抢表决盘,当然这里的表决盘是指控制文件),获得了RR锁的实例访问控制文件中的实例状态,并决定新的集群实例列表。当然,结果一定是获得了RR锁的实例会存活,另外一个实例被驱逐。而最直接的信息就是在数据库的alert log当中出现了原因3的ora-29740 错误。
接下来发生的过程就和正常的数据库重新配置过程一样了。
注意:集群层面处理脑裂的方式和数据库层面是不同的。
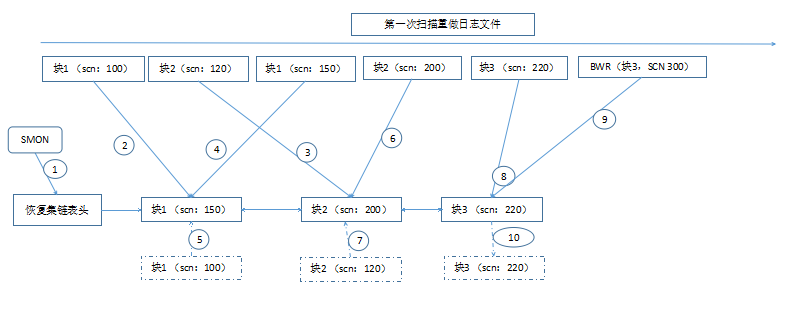
RAC系统中的实例恢复是指当某一个(或多个)实例离开集群后,重新配置主节点会将离开集群实例对应的redo thread中的重做日志文件中对数据的改变(redo entries)应用到数据库。这个过程实际上和单实例当中的实例恢复过程是很类似的,但是由于RAC数据库存在cache fusion, 也就是说同一个数据块可能被多个实例修改,所以恢复的过程可能和单实例有所不同。
阶段一:负责执行恢复实例的SMON进程获得IR(Instance Recoverr)锁,并通知其它实例开始进行实例恢复。之后进行第一次redo log分析,主要目的是为了构建recover set(恢复集)。
阶段二:获取恢复所需要的cache fusion lock。根据recover set 中包含的数据块,向其他实例申请对应数据块所需要的锁和block。
阶段三:开始恢复redo中的数据库改变,根据recover set 中的信息开始介质恢复。在完成实例恢复后,释放IR锁,并通知其它实例恢复结束。
实例恢复—备份集
Q&A精选
【问题1】12c的rac有没有什么重大变化?
【问题2】重构的时候,日志中有重构耗时,这段时间内(10秒左右)进行实例恢复的块涉及和对象是否无法进行dml操作?
【问题3】现在linux都是64位了,hugepage不用配置了,这句话说的对吗?rac 配置huge,一个新装的生产linux rac需要马上配置上huge page吗,系统内存多大,sga多大的库适合配置huge page?
【问题4】对于新手如何学习RAC?
【问题5】BWR是什么?为何包含在了BWR中,就要删除出去?
“DBA+社群”将陆续在各大城市群进行线上专题分享活动,以后的每周二、周四晚上都将成为【DBA+专题分享】的固定时间,欢迎大家积极加入我们。无论是内容还是形式,有好的建议我们都会积极采纳。想参与的小伙伴们可关注我们的微信号:dbaplus 。

扫码关注
DBAplus社群
来自各领域的牛逼DBA正在向我们汇聚








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721