

Oracle企业版有一项非常厉害的技术:并行查询,也就是说一个语句可以雇佣多个服务器进程(parallel slaves也叫PX slaves)来完成这一个查询所需要的结果。
并行操作不仅仅能够充分利用主机的CPU资源,也能够充分利用系统的IO资源、内存资源,这看起来是一个优点,但是也需要看情况,如果数据库系统没有太多的空闲CPU、空闲IO或空闲内存资源,那么并行技术是否要使用非常值得考虑,甚至即使系统有着很多的CPU空闲资源,但是IO资源已经远远不够,那么同样需要考虑是否要使用并行(并行往往产生大量的IO)。
鉴于并行操作的工作方式,不能让它在系统中被滥用,否则可能导致系统的资源很快的被耗尽。并行操作本身也是复杂的,它有着很多串行执行所不具备的概念,例如table queue,数据分发方式等等,并且阅读并行语句执行计划的方式也与串行可能会有所不同。
并行操作的目的是为了提升语句执行的线性度,如果一个语句串行执行的时间为4分钟,那么通过指定4个并行来操作,可以加快查询执行时间为1分钟,当然这只是一种预期,现实的情况往往不能达到这种线性度。有一些消耗和事实需要了解:
雇佣并行进程本身需要一些时间,这些时间往往比较短,如果进程池中没有可用的并行进程,那么还需要操作系统去spawn出需要的并行进程,这时数据库可能会遭遇os thread startup等待。如果语句执行时间只有数秒,你要考虑它是否适合使用并行。
QC进程给PX slaves分配工作,这会消耗一些时间,这个时间一般也非常短。例如QC进程需要给每个PX slave进程分配扫描ROWID的范围。
如果并行查询要返回大量的数据给客户端,那么仅有的一个QC进程本身可能会成为瓶颈。
由于Oracle的并行执行采用的是生产者消费者模型,因此一般DOP为4的查询,最终雇佣的PX slaves为8,再加上QC进程本身,一共会占用9个系统进程,你要认识到付出的这些是否值得。
在Exadata下即使使用串行查询,由于在IO层面默认就是并行,因此Exadata下的语句并行效果没有非Exadata下好。
为了让并行能够非常好的发挥作用,有一些要求需要被满足:
非常有效率的执行计划,如果执行计划本身非常糟糕,使用并行可能并不能多大程度上改善语句的执行效率。
数据库系统有着充足的资源可用。这点已经在文章的开头提到过。
工作量的分配没有明显的倾斜,大家都熟悉短板理论,如果某一个PX slave干了绝大部分的活,那么最终的响应时间最大的瓶颈就是它。
也许上面的很多概念和术语你还不清楚,没关系,我们下面的内容都会介绍到。使用并行首先应该考虑的问题是如何分配工作量,在串行执行的情况,这个问题不用考虑,只有一个进程干活,所有的工作都是由它来完成,但是如果使用了并行操作,那就意味着有多个进程在干同样一件事,工作的分配就显得非常的重要。
对于单表的并行操作,工作量的切分是比较简单的,Oracle也没有设计任何复杂的算法,它一般是按照ROWID或者分区(假如它是分区表的话)来分配工作。例如下面的并行查询:

上面的SQL及其执行计划显示,对表test以并行度2进行了记录数的统计,Id为5的行源Operation部分为:PX BLOCK ITERATOR,这是一个在并行操作中经常能看到的一个操作,代表了QC进程按照ROWID把表做了切分,每个PX slave扫描表的不同范围,然后每个PX slave聚合出自己所扫描部分的记录数(Id=4,SORT AGGREGATE ),最后把结果发送给QC,QC进一步聚合这些PX slaves的结果形成一个记录返回给客户端。
通过SQL MONITORING可以看到的更为直观(下图),绝大部分的工作都是通过蓝色的PX slaves来完成的,然后这些PX slaves把各自做过预聚集的结果发送给(行源ID为3)QC做最终的聚合。

不过我们随着后续的学习会发现,这里的这个例子只雇佣了一组PX slaves进程,这在Oracle并行的世界中是一个特殊案例。按照Oracle的生产者、消费者模型,一般会雇佣两组PX slaves,一组作为生产者扫描数据,另一组作为消费者把从生产者接收过来的数据做各种加工。(不过这个例子可以把QC作为消费者看待)。
本文大量使用了SQL MOMITORING工具,如果你对这个工具还不熟悉,请参阅我的另一篇文章: http://www.jianshu.com/p/ce85dd0c05ab
我们对SQL进行简单的改造,增加ORDER BY部分,看看结果会怎么样。


同样我们通过SQL MONITORING来进行可视化解析,【操作】列出现了两种不同颜色的PX slaves,红色的PX slaves作为生产者正在扫描表HASH_T1,然后把扫描到的数据分发给蓝色的PX slaves消费者,PX slaves消费者接收到这些数据后并做排序然后把结果集发送给QC。 这个例子虽小,但是五脏俱全,在Oracle并行执行中,一个可以并行的操作单元(树)称为Data Flow Operator,一个QC代表了一个DFO单元,一个查询可以有多个DFO单元(DFO tree),例如典型的像union all语句,就可以有多个DFO单元,不同的DFO单元之间也可以并行。
具备了Oracle并行执行生产者和消费者的概念,继续看上图中的【名称】列,会发现有TQ10001,TQ10000的东西,这个是啥?
上面已经提到Oracle并行操作有生产者和消费者的概念,生产者和消费者分别代表着一组进程,他们之间需要传递消息和数据,那么他们是靠什么来进行传递消息和数据的呢?这就是table queue的作用。 继续以上图为例:

这里一共包含了两组PX slaves,一组为红色的生产者,一组为蓝色的消费者,生产者通过ID为6,7的行源扫描表HASH_T1,同时通过ID为5的行源把扫描结果写入table queue TQ10000(PX SEND RANGE),消费者从table queue TQ10000读取数据然后做排序(PX RECEIVE),消费者对于已经完成排序的结果通过table queue TQ10001发送给QC进程,QC进程把接收到的结果聚合后发送给客户端。
对于单表(无JOIN)的数据切分是非常简单的,只需要按照ROWID做切分就可以保证结果的正确,因为多个并行slaves之间没有数据的交叉,也就不会有数据的丢失,而且按照ROWID切分也非常容易保证每个PX slave的工作量均匀。但是如果是两表的JOIN呢?你如何保证1/N的X表的记录和相对应的1/N的Y表的记录在一个并行操作内(也就是由一个并行进程处理)?两个表都按照ROWID来切分是不能保证的。 为了让例子足够的简单,可以通过如下例子来进行描述:
集合一: 【1,3,5,7,9,11】
集合二: 【1,9,3,6,7,8,5】
假如要求使用并行度2来判断,【集合二】和【集合一】有多少数据有交集,该如何实现? 我们模拟通过ROWID来切分,把【集合一】按照顺序切分为2部分:
set 1:1,3,5 =>进程1
set 2:7,9,11=>进程2
我们再使用同样的办法,把【集合二】切分为2部分:
set 3:1,9,3 =>进程1
set 4:6,7,8,5 =>进程2
通过上面一系列的操作我们把2个集合都切分为了2份,然后我们通过进程1对set 1与set 3做join,进程2对set 2与set 4做join,OK? 显然是不行的,因为最终的结果集是不对的。
两个集合做JOIN正确的结果是:3,5,7,9
但是按照上面的算法,set 1和set 3的结果集为3,set 2和set 4的结果集为7,最终的结果集为3,7,丢失了5,9两个结果。
因此不能为了加快查询的速度而不保证结果正确性对对数据进行随意切割。那么Oracle是如何做的?如何保证进程读取了X表的1/N的数据与Y表相对应的1/N数据?
从这里看出了引入了数据分布算法的重要性,也解释了为什么运行并行度N需要2N个并行slave来完成工作,一组进程用来扫描表X,然后把数据按照分布算法把数据分发给另一组进程Y,这样表X的数据分布完成后,Y的表记录要根据X表的分布算法来决定自己的分布方式。你看到这里可能有些地方可能还看不明白,没关系,后续有足够的内容让你明白这些操作。
继续前面的例子:
【集合一】:1,3,5,7,9,11
【集合二】:1,9,3,6,7,8,5
broadcast的分发方式为(这里假设并行度为2):
Oracle首先需要产生2组PX slaves,一组为生产者包含2个PX slave进程,一组为消费者,同样包含2个PX slave进程,(注意生产者和消费者角色是可能互换的)。
每个生产者PX slave按照ROWID切分,扫描1/2的【集合一】,然后广播给每一个消费者的PX slave,最终每一个消费者的PX slave都有一份全量的【集合一】。
然后每个消费者的PX slave进程按照ROWID切分,扫描【集合二】,然后与【集合一】做关联判断,最终得出结果集。
这里的关键是,每个消费者的PX slave都持有了全量的【集合一】,因此不需要再对集合二有任何的分发需要,只需要按照ROWID扫描然后再进行JOIN操作就能够保证结果的正确性。
集合一:【1,3,5,7,9,11】
分发后为:
set1: 1,3,5,7,9,11 =>进程1
set2:1,3,5,7,9,11 =>进程2
集合二:【1,9,3,6,7,8,5】
分发后为:
set 3: 1,9,3,6 =>进程1
set 4: 7,8,5 =>进程2
set 1,set 3的结果集为1,3,9,set 2和set 4的结果集为5,最终的结果集为1,3,5,9,这样不但把工作量做了比较均匀的切分,而且保证了结果的正确性。
这里我们通过一个具体的查询例子再来看一下整个过程:

表T1的数据量为70,表T4的数据量为343000。


我们通过添加hint pq_distribute(t1 none broadcast)强制让hash join左边的表进行了广播分发,根据SQL MONITORING的输出,我们做如下分析:
(行ID 9,8,7),生产者红色进程(【操作】列)按照ROWID做切分扫描表T1,然后把扫描的结果写入table queue,以广播方式做分发,ID为7的行源PX SEND BROADCAST操作代表了广播的分发方式。
行ID6,5,蓝色的消费进程(【操作】列)接收到红色PX slave广播的数据,然后构建HASH TABLE。每一个蓝色的消费PX slave都接收到了全量的T1表 的数据,根据【实际行数】列可以显示这一点,表T1总共70行的数据经过广播分发后,实际产生了70*2(并行度)=140行的记录。
行ID 11,10,蓝色的消费进程按照ROWID切割扫描T4表并与前面构建的HASH TABLE做JOIN。
这里并没有对T4进行任何的分发,认识到这一点很重要,蓝色的消费进程只需要按照ROWID范围扫描即可,因为T1表的数据在每个消费者的PX slave都保持着全量。
这里我们做一个阶段性的总结:
对于broadcast分发方式来说:
HASH JOIN右边的表不用分发。
BROADCAST方式, 没有结果不对的风险,因为消费者的每个PX slave持有了全部的HASH JOIN左边表的数据,每个消费者进程都持有一个完整的HASH TABLE。
HASH JOIN左边表 如果小的话,分发代价不大。但是随着并行度DOP的提高或者左边表数据量的增大,分发的代价会越来越大。
如果左边表小的话,BROADCAST的执行计划具有非常好的扩展性。
第一组PX进程扫描HASH JOIN左边表广播给第二组PX slave,CPU,内存,竞争都会有消耗,竞争的消耗来自于第一个组的每一个进程扫描的数据都要广播给第二组的每一个进程,如下图:

replicate代表每个并行进程都全量扫描hash join左边的表,不按照rowid做区分,由于数据是被每一个进程全量扫描的,因此不需要再对数据做分发,也就只需要一组PX slaves。

观察操作列只有一组蓝色的PX slaves进程,这里没有涉及到数据的分发:
2个进程全量扫描reptest表,然后构建hash table(全量的hash table)
扫描完成后,2个进程按照ROWID范围扫描hash_t1表,由于2个进程持有了全量的reptest表的hash table,因此对于hash_t1表不需要分发。扫描hash_t1表过程中探测hash table。
就像上面提到的,broadcast/replicate分发方式有一个问题是,因为消费者的每一个PX slaves要持有完整左边表的记录, 因此适合左边表比较小的情况。如果对于两个大表的HASH 连接,Oracle一般使用HASH的分发方式。例如还是上面的例子:
【集合一】:1,3,5,7,9,11
【集合二】:1,9,3,6,7,8,5
【集合一】和【集合2】按照同样的HASH 函数分发后,总能保证有关联的数据对在一起,这样就能保证结果集的正确性。但是这样的方式,多出了一个代价,那就是对于【集合二】也需要做HASH分发,会多出一些CPU资源的消耗,相对于广播的分发方式,只有【集合一】需要做分发。
我们来看一个具体的例子:


首先红色的生产者PX slaves按照ROWID切分并行扫描表HASH_T1,然后依据HASH算法把记录通过table queue TQ10000分发给特定的蓝色的消费者PX slave。
蓝色的消费者从table queue TQ10000接收到数据后构建HASH TABLE。
上面2步操作完成后,红色的生产者PX slaves继续按照ROWID切分并行扫描表HASH_T2,然后按照HASH算法把记录通过table queue TQ10001分发给特定的蓝色消费者PX slave,蓝色消费者PX slave从table queue TQ10001接收数据并与前面构建的HASH TABLE做JOIN。最后每个蓝色的消费者PX slave把自己聚合的结果通过table queue TQ10002发送给QC。
注意:
【实际行数】列,记录按照HASH分发后并没有增加。
对hash_t2扫描过程,由于数据需要分发,因此会有同时2组PX slaves同时活跃。
HASH分发有着很好的扩展性,每个进程有部分的HASH 表,而不是完整的HASH表,每一行只会分发给一个特定的PX SLAVE。而不是像broadcast分发把每一行广播给每一个SLAVE。
但是就像上面已经指出过,待对HASH JOIN左边表分发完毕后,同样对于HASH JOIN右边的表也需要进行分发,多了一次分发的代价,增加了一些CPU和内存的成本。
错误的分发方式可能会对并行执行带来非常大的性能问题,Oracle 12C介绍自适应的并行分发方法,hybrid hash,在真正执行过程中,再决定该使用何种分发方式,Oracle 优化器要做到这一点,使用了statistics collector,它在语句运行过中统计语句的一些运行时信息,例如返回记录的数量等等。需要注意使用了HYBRID-HASH后,每次语句执行,都要通过statistics collector来动态决定使用的并行分发方式。
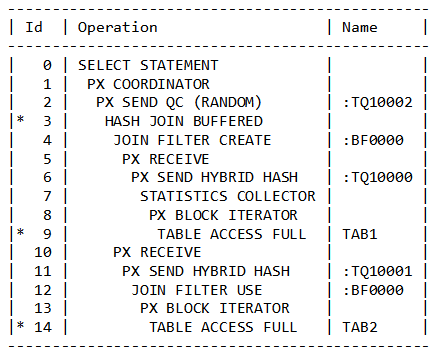
例如上面的执行计划,观察行源ID 7,并行执行过程中会统计结果集的返回值数量,如果返回的结果集数量小于并行度*2,那么会使用广播方式来进行数据分发,反之则使用HASH的数据分发方式,作为回应,在行源ID 为6的分发方式确定后,行源ID 11再决定使用round-robin还是hash分发。
我刚做DBA那会,一些老DBA告诉我如何看并行执行计划,那就是把PX相关的操作都统统抹去,然后再看,例如:

我们把相关的PX等操作都全部去掉,最终和串行执行的如下文本是"等价"的:
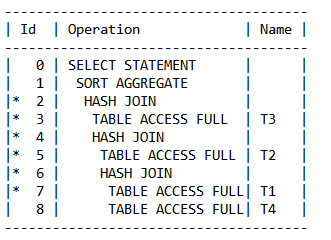
真的等价吗? 在串行执行过程中,对于上面执行计划的执行顺序是这样的:
扫描T3表,构建hash table,扫描T2表,构建hash table,扫描T1表构建hash table,最后扫描T4表,扫描到的每一个记录都要探测前面所产生的3个hash table。
但是并行执行的执行顺序并不一定是按照上面描述的顺序,对于并行执行计划的阅读要跟随table queue的创建顺序,它代表着并行执行中数据分发的顺序。因此就上面的并行执行,执行顺序为:
扫描table T1,构建hash table,之所以首先扫描T1,是因为table queue的编号TQ10000 是最小的。
根据table queue TQ10001的位置知道,然后扫描table T4并与上面的hash table做hash join。
根据table queue TQ10002的位置知道,接着扫描table T2,构建hash table,然后,上面两步产生的结果集与这个hash table做hash join。
根据table queue TQ10002的位置知道,最后扫描table T3,构建hash table,然后上面三步产生的结果集与这个hash table做hash join。
v$pq_tqstat视图是非常特别的,它的内容只记录在QC进程的私有PGA中,而且只在 并行查询结束后内容才会被填充,因此如果并行执行过程中,你取消了查询,那么查询这个视图依然不会有任何结果,因为它只存在进程的PGA中,因此你不能通过另一个会话去查询它。 可以通过它了解并行执行过程中数据是如何通过table queue分发的。举两个例子:
HASH_T1数据量9999999

例如我们对hash_t1 以并行度4进行记录统计,执行完成后,查看v$pq_tqstat视图:
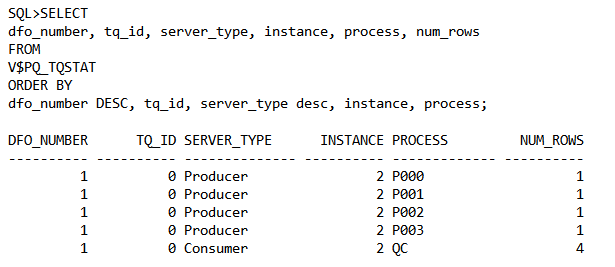
4个生产者把各自扫描到的记录做了汇聚各自产生一个记录并把它写入table queue,QC通过table queue接收了这四个记录。注意NUM_ROWS代表的是PX slaves通过table queue写入、读取的数据量,可以通过NUM_ROWS的值非常容易看出并行进程的工作量是否均匀,是否有并行倾斜存在。
再看一个复杂点的例子:
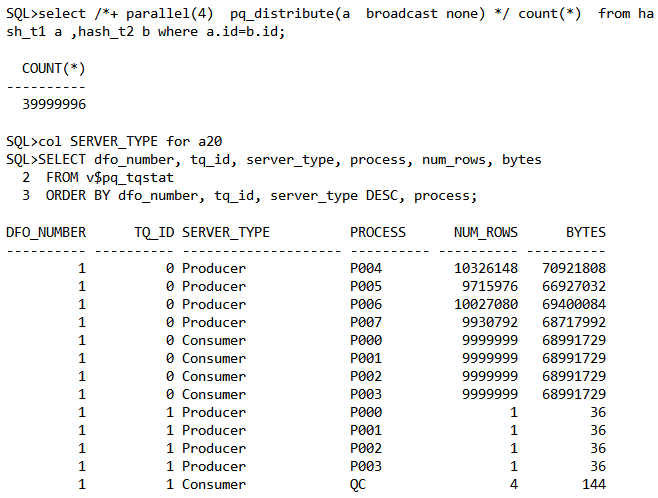
观察SQL的hint部分,强制让hash join的左边表使用了broadcast的分发方式,结合上面的输出和下面的图一起看,每个红色的生产者先按照ROWID范围扫描HASH_T2,然后把数据通过table queue TQ10000广播给蓝色的消费者,由于采用了并行度4,因此其实每个生产者真正写入table queue中的数据量是扫描数据量的4倍(9999999 是真实的记录数,经过广播分发产生了9999999 *4 的记录数),消费者从table queueTQ10000中接收数据后构建hash table,每个消费者PX slave都构建了表hash_t2完整的的hash table,然后蓝色消费者开始扫描hash_t1,并与之前构建的hash table做join,最后每个蓝色消费者把各自最终形成的预聚合结果发送给QC(这里其实已经转化了角色变为了生产者),QC接收到4条记录。

根据上面的介绍,你已经知道了,一个并行操作内一般会具有两组PX slave进程,一组为生产者,一组为消费者。生产者通过table queue发送数据,消费者通过table queue接收数据。而且对于消费者和生产者模型,有一个很大的限制是:一组DFO单元最多只能有两组PX slave进程,之所以有这个限制,一方面可能是Oracle公司为了保持并行代码的简洁性,一方面由于每个PX slave进程之间和每个PX slave与QC之间都要维持一个通信通道(table queue)用于传递消息和数据,如果允许的PX slave有太多组,可能会导致通信通道指数级增长。
例如一个DOP为5的并行操作,PX slave之间需要的通道数为55,PX slave与QC之间的通道数为25,共需要(5+2)5=35个通道。可想而知,如果Oracle允许一个并行操作内有3组PX slave,需要维持的连接数有多少,我们假设当前服务器共运行了50个并行,那么三组PX slave进程产生的通道数为5050*50=125000个,还不包括PX slave与QC之间的通道,吓尿了不?
如果进程之间传递消息的通道数多但不占用数据库资源可能也并不是什么大的问题,但是事实不是这样的,进程之间传递消息的通道的内存占用大小是由参数parallel_execution_message_size控制的,在11GR2版本这个参数的值为16K,在以前的各个版本这个参数的值可能大小并不一样(每个版本都有增大的趋势),在非RAC环境下,每个通道的大小最大可以为3parallel_execution_message_size,在RAC环境下,每个通道的大小最大可以为4parallel_execution_message_size。
例如一个DOP为20的查询,非rac环境下通道所占用的内存最大可能为: PX进程的通道内存+QC、PX进程之间的通道内存=202016K3+22016K3=21120K,接近21M的内存。 通道的内存默认是在large pool中分配,如果没有配置large pool则在shared pool中分配。
计算通道内存的公式:
单节点
(NN+2N)316k
RAC节点
(NN+2N)416k
其实不是hash join的缺陷。 我们已经介绍过生产者消费者模型,它有一个很大“缺陷”是,一个并行操作内,最多只能有2组PX slave,2组PX slave通过table queue来传递消息和交互数据,因此在一组SLAVE在读table queue的时候,不能同时去写另一个table queue。是不是不太好理解? 我们通过一个例子来进行描述:


这个例子里我通过hint pq_distribute(b hash hash)强行让数据以hash方式进行分发,关注行源ID为3的操作,出现很陌生的一个操作:hash join buffered,不要被这个buffered名字所迷惑,它代表着数据暂时不能向上流动,必须先暂时存放在这里,语句的执行顺序是这样的:
首先红色的生产者PX slave扫描hash_t3表,并对扫描的记录按照HASH分发方式把相关记录写入table queue TQ10000
蓝色的消费者PX slave从table queue TQ10000接收数据并构建hash table。
上面操作结束后,红色的生产者继续扫描hash_t1表,并对扫描的记录按照HASH分发方式写入table queue TQ10001
蓝色的消费者PX slave从table queue TQ10001接收数据,并与上面的HASH TABLE做探测,但是结果并不能写入table queue TQ10002,而是先暂时缓存起来(hash join buffered的由来)
等HASH分发完成之后(也就是这两组PX slave不活跃以后),然后由一组PX slave把结果集通过table queue TQ10002发送给QC。
为什么要这样?貌似是没有道理的。
这就是因为hash分发要求对hash join的右边也要进行分发,分发操作涉及了2组PX slave进程,一组负责扫描,一组负责接收数据,也就是一组PX slave把扫描的数据写入table queue,一组负责从table queue读取数据,这个时候不能 再进行数据的分发操作,因为join的结果集不能写入另一个table queue TQ10002。
如果结果集较大的话,这个可能在一定程度上会导致消耗很多临时表空间,导致大量的磁盘读写IO,进而引起性能降低。
如果确实产生了这种情况,可以通过改用broadcast分发来避免出现这种情况,因为broadcast分发对于hash join的右边并不需要进行分发


例如改成broadcast后,hash join buffered操作已经消失了。
我们有必要介绍一下布隆过滤,它在11GR2之后版本的并行里有非常大的作用。bloom filter并非Oracle的发明,bloom filter技术出现的时候Oracle软件还未诞生,它在1970年由Burton H.Bloom开发出来,布隆过滤到什么?
布隆过滤或者说布隆过滤器,是一种数据结构,它能够快速的判断一个数据是否属于一个集合,hash join本身是非常消耗资源的,也是非常慢的,布隆过滤比hash join快很多。
关于布隆过滤的详细介绍请参照:http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html

布隆过滤器基于一个有M位的数组,例如上图数组的大小有18位,初始化的时候全部的值都为0,如果要理解布隆过滤是如何工作的,必须要知道在什么情况下,这些标志位需要置为1,上图中{X,Y,Z}代表着一个集合,这个集合有3个值(元素),仔细观察每一个值都延伸出了三个线,在这里代表着每一个值都经过3个HASH函数计算,计算出来的值的范围是从0-17(数组的长度),例如,X经过3次HASH函数计算,值分别为:1,3,13,然后对应的标志位被置为1,Y,Z同理把相应的标志位置为1。经过一番HASH计算,{X,Y,Z}集合的所有元素都已经经过了HASH计算,对应的标志位也都置为了1,然后我们再探测另一个集合,这里另一个集合的元素为W,W同样需要经过相同的3个HASH函数计算,并且检测对应的位置是否为1,如果对应的位置都为一,那么W可能(仅仅是可能)属于这个集合,如果有任何的位置不为1,那么这个W一定不属于这个集合。由于布隆过滤并不对值进行精确的匹配(而HASH JOIN是需要精确匹配的),因此可能会有一些不该属于集合的值穿越了布隆过滤器。
布隆过滤器有如下特点:
构建布隆过滤数组要求的内存非常小,经常可以完全放入在CPU的cache中。当然布隆过滤的数组越大,布隆过滤误判的可能性也就越小。
由于不需要精确匹配,因此布隆过滤的速度非常的快,但是有一些不该出现的值可能会穿越布隆过滤器。

布隆过滤有啥用呢?也许你是一位有着丰富经验的老DBA,那么你对PX Deq Credit: send blkd 、PX Deq Credit: need buffer等待事件也许就比较熟悉。
经过上面的介绍,我们已经具备了很多的知识,table queue,生产者消费者模型等等,一组消费者PX slave写入table queue,另一组通过读取table queue来获取数据,完成进程间数据的传递,但是一定会出现一种情况,当一组生产者PX slave在往table queue中写入数据的时候,发现table que中的内存已经满了,没有剩余内存可以写了,这种情况大部分时候都意味着消费者PX slave从table queue中消费数据过慢,过慢最大可能原因是由于消费者不得不把table queue中读取到的数据溢出到磁盘,从内存读取数据写入磁盘是个很慢的操作,因此在这种情况下,就会遭遇PX Deq Credit: send blkd 、PX Deq Credit: need buffer等待,如何优化?这种情况下,布隆过滤就发挥了作用。
如果优化器认为表X返回1000条记录,表Y需要扫描一亿条记录,但是经过HASH JOIN后,有90%都不需要返回,这种情况下使用布隆过滤在进行HASH分发前预HASH JON。这样经过布隆过滤器,有大量的记录就被布隆过滤器所淘汰,最后HASH JOIN右边的结果集就变得非常小,也就让HASH 分发的数据量变得非常的小,大大减少了出现PX Deq Credit: send blkd 、PX Deq Credit: need buffer的概率。如果不使用布隆过滤,进程不得不传递大量的数据给另一组进程,增加了内存,CPU,增加了两组进程的进程间竞争。
不要期待布隆过滤是完美的,他能消除掉大部分的行,但是不是 所有的行,因此有一些不需要的数据会穿过布隆过滤器达到第二组进程。
无论你使用的是手工指定DOP,还是使用11G的AUTO DOP,运行时的DOP都有可能与你预期的不一样:可能被降级。可能会有很多种原因导致并行被降低,例如,当前系统中可用的并行进程已经不能满足需要的DOP,或者你已经使用了Oracle的资源管理器对并行度做了限制,等等。
监控并行度降低的最好工具是oracle 12.1版本的SQL MONITORING,例如:

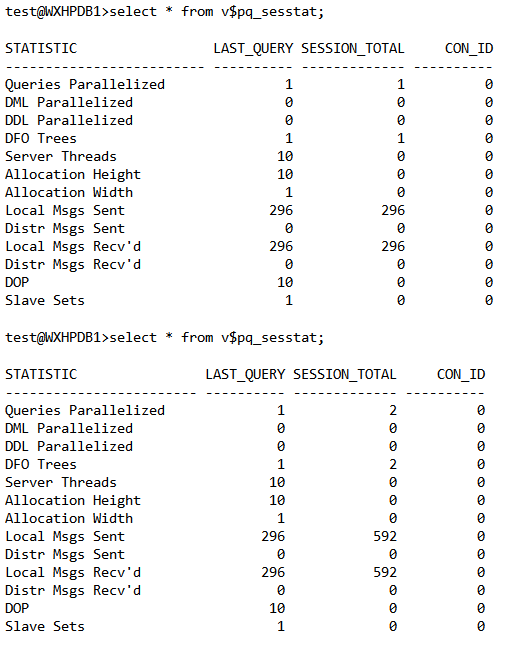
如上图,在【一般信息】部分,将你的鼠标放在Execution Plan部分的蓝色小人上,将会出现一些并行度的信息,例如上图中,运行时间的DOP为4,实际请求的并行服务进程为10,实际分配的并行服务进程为4,并行度被降低的百分比为60%。
为了找出语句被降级的理由,你可以点击【计划统计信息】部分,PX COORDINATOR行源的其他列,如下图,用红色框标记:

点击后出现:

以下是被降级的一些代码说明:

我这里的情况是,由于系统可以使用的并行进程不足导致分配并行资源失败。 如果你不方便使用EMCC,也可以通过视图观察到并行度降级的情况,但是被降级的理由,暂时还没有视图反应(或者我还不知道,如果你知道请告诉我)
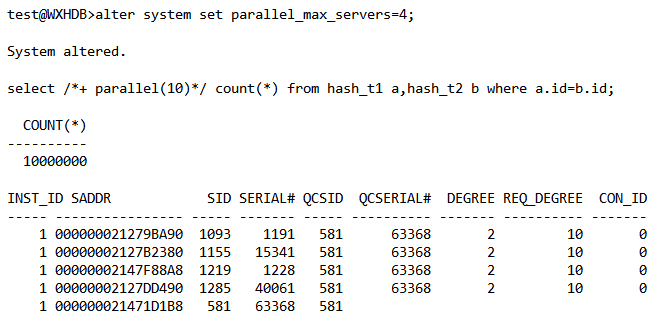
DEGREE 列为实际的并行度,REQ_DEGREE 为请求的并行度。 有一些手段可以避免并行度降级,例如如果使用的是ORACLE 11G版本,可以使用自动并行管理功能,然后结合在语句级指定并行度。因为自动并行度功能一单被打开,并行语句排队功能将被启用,如果语句运行时发现没有足够的可用并行进程,那么会排队等待,直到有满足目标的可用并行进程。
一些命令可以有多个DFO单元,因为每个DFO单元最多可以使用2个PX slaves set,如果一个命令有多个DFO单元,那么它就可以使用超过2个PX slaves set,可以在执行计划里看到是否使用了多个DFO单元:


行ID为6和12的行源两处都有coordinator标识,这意味着这个命令使用了2个DFO单元。

通过SQL MONITORING也可以看到这个命令具有了2个并行组,理论上每个DFO单元之间可以同时进行并行操作,但是我们这个例子里,两个DFO单元之间的执行顺序是,先执行DFO单元1,再执行DFO单元2,可以通过【时间表】列看到,第一个DFO单元先活跃,等结束后,第二个DFO单元开始活跃。
从上图还可以看出,DFO单元2复用了DFO单元1的并行进程,没有重新产生新的并行进程,从并行进程编号上可以看出这一点。SQL MONTIRONG是不是超级好用?
SQL MONITOR:
http://pan.baidu.com/s/1gfO2DtL
Parallel原理实现:
http://pan.baidu.com/s/1i5xun9F
12C IN-MEMORY:
http://pan.baidu.com/s/1ge7r1oZ
Oracle Memory Management and HugePage:
http://pan.baidu.com/s/1dFdPLEp
沃趣科技高级技术专家,主要参与公司一体机产品、监控产品、容灾产品、DBaaS平台的研发和设计。
曾就职于东软集团、阿里巴巴集团,Oracle ACE组成员,DBGEEK 用户组发起人,ITPUB认证博客专家,ACOUG、SHOUG核心成员。
对Oracle并行机制、数据库异常恢复方法、ASM等有深入的研究,人称”Oracle Internal达人”,对企业数据库架构设计、故障恢复、高并发下数据库性能调优有丰富的经验。擅长从等待时间角度分析解决数据库性能问题,是OWI方法论的提倡者和践行者。
全球敏捷运维峰会【北京站】
2016年6月11日,DBA+社群联合运维帮、Linux中国开启全球敏捷运维峰会第二站:北京站!峰会力邀来自百度、新浪、58到家、小米、搜狐畅游、浙江移动、新炬网络、日志易等互联网与传统企业的资深大咖,汇聚500+行业精英!原价169元的门票限时免费,原价599元的VIP票,限时199元(优惠码:dbavip)!快扫码抢座吧~









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721