
梁铭图,新炬网络首席架构师,十多年数据库运维、数据库设计、数据治理以及系统规划建设经验,拥有Oracle OCM、Togaf企业架构师(鉴定级)、IBM CATE等认证,曾获dbaplus年度MVP以及华为云MVP等荣誉,并参与数据资产管理国家标准的编写工作。在数据库运维管理和架构设计、运维体系规划、数据资产管理方面有深入研究。
上回说到某运营商客户的核心系统数据库从IBM AIX小型机环境迁移到某国产数据库一体机,同时数据库版本从11g直接升级为19c。在上月已经实现两个地市迁移到一体机的19c上,尽管过程顺利完成,但是从实操过程中,亦暴露了TimesTen Cache Group重建速度较慢,存在操作时间超时的风险。因此,有必要对此过程进行优化。
TimesTen(简称TT)是Oracle开发的一个内存关系型数据库。它支持SQL并提供了响应时间极短且吞吐量极高的应用程序,可满足各行业高性能和高吞吐量应用程序的需求。同时,TT与Oracle DB的整合性非常好,与其他内存缓存(如Redis等)不同,它提供了原生的Cache Group机制,可以实现Oracle DB中的表与TT内存库的表的实时同步,无需程序过多干预。
Cache Group是在TT中cache的Oracle数据表的一个集合。
Cache Group里的多张子表(child tables)要与主基表(root table)有外键约束关系,且一个Cache Group只能有一张基表(root table)。一个data store可以有多个Cache Group;一个data store里,一张表只能cache在一个Cache Group里。
Cache Group一般可分为两种类型:TT自动管理(System-managed)和用户管理(User-managed)。
其中TT自动管理又有建立三种类型的Cache Group:
只读Read Only:TT中只读,DML在Oracle中。TT中DML可通过Passthrough传递到Oracle。
同步Synchronous writethrough (SWT):DML操作先在TT中进行,然后通过Cache Agent进程在Oracle中提交,若此时出现错误,则TT中也会被rollback。效率低下,应用不多。
异步Asynchronous writethrough (AWT):DML操作先在TT中进行,提交返回,Cache Agent检查log buffer或transaction log file异步将DML操作在Oracle中执行。
在我们的实践中,主要使用只读Read Only形态的Cache Group为主。因为在此应用中,Cache Group的作用是将Oracle数据库中涉及用户的信息同步到TT中,为在TT中运行的计费程序提供用户相关信息。
在数据迁移过程中,我们使用GoldenGate已经将11g数据库中的两个地市的schema迁移到X86一体机的Oracle 19c数据库中。升级的大致示意图如下:
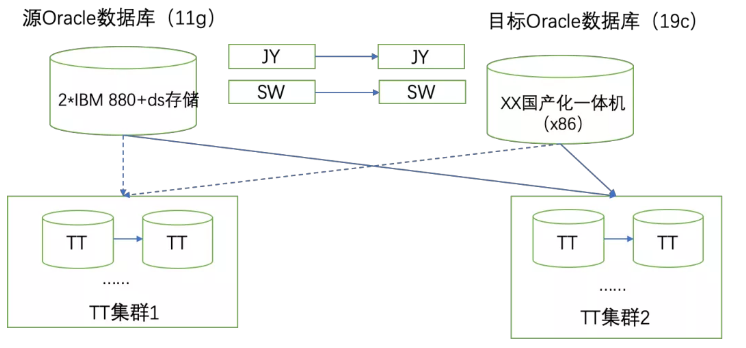
其中数据库架构中有两个TT的集群,每个TT集群都有若干套主备架构的TT内存数据库。物理Oracle数据库与TT内存库之间使用Cache Group机制同步物理库中的若干关键表到内存库中。
1)主要环境信息
源Oracle库主机:IBM E880
源Oracle库操作系统:AIX7.1
源Oracle库版本:11.2.0.4
是否RAC:是
目标库主机:国产X86一体机
操作系统:Redhat 7.6
目标库版本:19.5
是否RAC:是
TT主机:IBM P780(powerPC)
TT操作系统:AIX7.1
TT库版本:11.2.2.8.43
2)实际操作步骤大致如下
我们将会关闭原11g数据库的所有业务应用,确保没有修改写入。
停止GoldenGate的实时同步,检查JY以及SW两份数据在目标端以及源端的一致性。
删除原11g数据库中两TT集群的所有Cache Group,如上图虚线所示。
重新创建基于19c数据库的TT集群Cache Group,如上图实线所示。
在实际操作中,前面的几个操作步骤都很顺利,问题出现在第4步。
检查后台数据,发现几个数据量较大的库表加载缓慢,只加载了整表大概三分之一的数据。
TT的Cache Group重建速度比预期要慢得多,造成四个步骤实际操作时间超时完成。由于后续工程中的迁移数据量远比本次迁移大,为了后续割接可以顺利地在工程计划时间窗口内完成,我们需要对这个过程进行分析和优化。
首先,我们怀疑问题是否出现在TT主机和网络之间,但问题是之前的TT Cache Group也是在此网络和主机之中。经过详细测试我们也确实排除了这个可能。
我们重新将问题目光聚焦于新环境的X86平台19c数据库当中。于是我们调用了Cache Group重建前面多个时间片的Oracle AWR报告,看看有什么收获。果然,在AWR报告中发现当时Oracle有明显的GC等待事件堆积情况。

在RAC环境,有Cache Fusion(内存融合)机制,可以实现多节点的缓存数据共享,如果比较频繁,就会有大量的GC相关等待事件。说白了GC等待就是跨节点访问内存数据,引起在RAC节点间通过网络进行节点内存之间的数据复制。针对这个问题,我们分析认为此事件发生的主要原因是,平时这些数据TT Cache Group数据同步都在11g双节点RAC数据库节点2上。而迁移到Oracle 19c 6节点的RAC后,数据同步会分散在多个节点执行,就会有过多的GC等待。
而普遍处理GC等待的处理方法,基本都是分割应用,或者分割表,尽量避免频繁的多节点数据访问。因此,优化TT Cache Group加载问题也可以遵从这个思路。回顾我们的割接方案,实际上可以得到一个非常简单的分割方法。因为我们迁移到19c上的数据已经按照schema做好了业务隔离,所以在创建Cache Group的时候也按照schema去划分就可以了。
根据这个思路,我们细化了重建TT Cache Group的步骤,将创建JY和SW两份数据的创建TT Cache Group放在单独的RAC节点中执行。RAC节点间的数据访问就不会有冲突和重复,借此降低GC等待的发生概率。大致如下示意图:
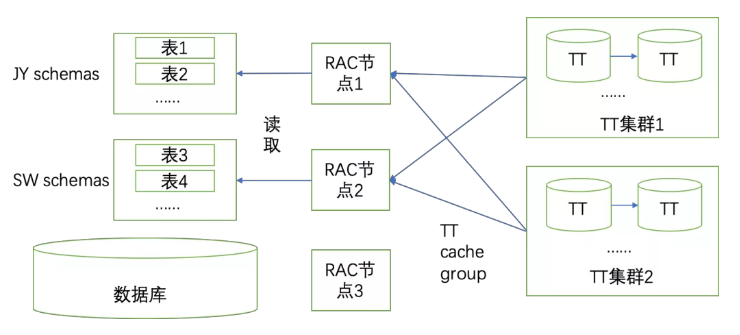
确定优化方案之后,经过后续的测试,效果良好,总体同步时间有明显的缩短。在后续的一次三地市割接中启用此优化方案,将Cache Group重建的时间压缩到原来的1/3左右,此问题得到有效解决。
TT Cache Group的重建是大量数据读取的过程,每个表的Cache Group重建需要遍历一次该表的所有数据。由于两个TT集群中又涉及多套TT库,每个TT库都需要重建Cache Group,所以相关数据会有大量的读取操作。
如果不对数据读取进行隔离和拆分的情况下,就会对数据读取分散到RAC的所有节点中,也就出现我们第一次割接工程中出现的问题,大量的GC等待的情况。
因此,必要的数据规划不但是业务应用需要注意,在一些特殊的场景下,也是必须单独进行优化的。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721