
作者介绍
梁铭图,新炬网络首席架构师,十多年数据库运维、数据库设计、数据治理以及系统规划建设经验,拥有Oracle OCM、Togaf企业架构师(鉴定级)、IBM CATE等认证,曾获dbaplus年度MVP以及华为云MVP等荣誉,并参与数据资产管理国家标准的编写工作。在数据库运维管理和架构设计、运维体系规划、数据资产管理方面有深入研究。
一、背景
随着大数据平台普及,越来越多企业建立以hadoop为核心的大数据平台,将许多原来传统数据仓库的工作转由hadoop来完成。
在数据仓库规划当中,一般会直下而上划分为ODS操作数据存储、DWD数据仓库明细、DWS数据服务以及ADS应用数据存储等。而ODS操作数据存储是数据从应用数据库(生产数据库)进入数据仓库系统的第一步。在实际项目当中,我们客户的系统往往使用的是Oracle为主的应用,那么我们在构建数据仓库ODS的过程中,我们往往需要从Oracle数据库同步数据到hadoop大数据平台当中。
而数据同步一般分为数据离线(批量)同步和数据实时同步两种。这两种数据同步方式各有擅长,一般来说:
数据离线同步的数据有如下特点:
数据量巨大且保存时间长;
在大量数据上进行复杂的批量运算;
数据在计算之前已经完全到位,不会发生变化;
能够方便的查询批量计算的结果。
结合项目实际使用,本文主要介绍一下我们常用的三种Oracle到hadoop的离线数据同步的工具。
二、工具介绍
Sqoop是一款开源的常用数据同步工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
1)架构
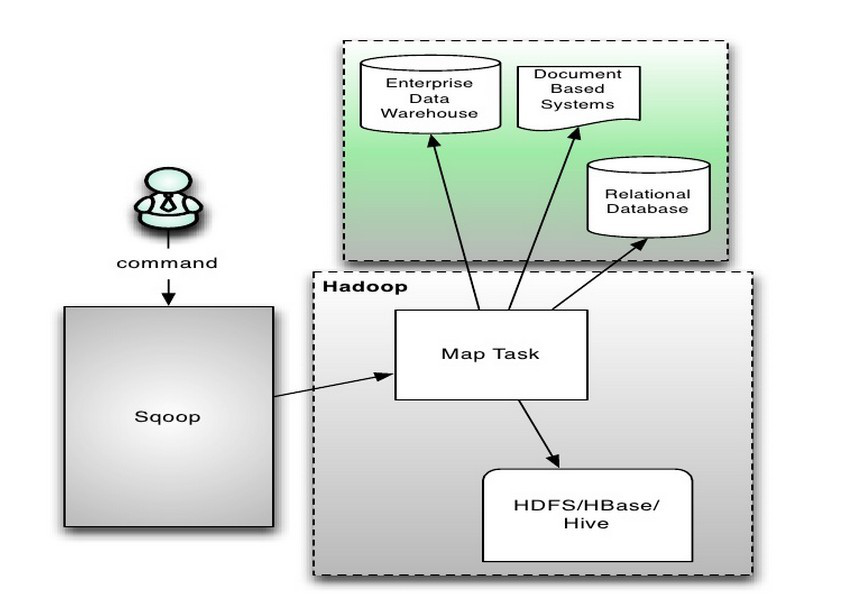
架构主要由三个部分组成:Sqoop、HDFS/HBase/Hive、Database。以导入到RDBMS为例,用户向 Sqoop 发起一个命令之后,这个命令会转换为一个基于 Map Task 的 MapReduce 作业。Map Task 会访问数据库的元数据信息,通过并行的 Map Task 将数据库的数据读取出来,然后导入 RDBMS 中。sqoop主要通过JDBC和关系数据库进行交互。理论上支持JDBC的database都可以使用sqoop和hdfs(Hive)进行数据交互。
2)安装部署
①安装环境
hadoop-2.7.2, hive-2.1.0, sqoop-1.4.6
②下载及安装
地址:
http://mirrors.hust.edu.cn/apache/sqoop/1.4.6/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
解压:
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz sqoop-1.4.6
③配置sqoop-env.sh
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/home/hadoop/SW/hadoop
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/home/hadoop/SW/hadoop
#set the path to where bin/hbase is available export
export HBASE_HOME=/home/hadoop/SW/hbase
#Set the path to where bin/hive is available
export HIVE_HOME=/home/hadoop/SW/hive-2.0.0
#Set the path for where zookeper config dir is
export ZOOCFGDIR=/home/hadoop/SW/zookeeper
④添加所须包至sqoop/lib下
我这里用到了Oracle,所以添加包:ojdbc6.jar。
如果是Mysql,可添加包:mysql-connector-java-5.1.38.jar。
⑤配置环境变量
vim /etc/profile
添加以下内容:
#Sqoop
export SQOOP_HOME=/home/hadoop/SW/Sqoop-1.4.6
export PATH=$PATH:$SQOOP_HOME/bin
保存执行生效:
source /etc/profile
3)数据传输
①Import(RDBMS TO Hadoop)
Import工具从关系型数据库将表导入到HDFS(HIVE),表的每一行在HDFS中代表独立的纪录。纪录的格式可以是text files或二进制文件(Avro或sequenceFiles)。
下面的测试案例继续使用Oracle的表名为temp_xinju_zjy_ecell, 纪录条数为16753条,导入到HIVE(HDFS)。具体语句为:
a)命令行如下:
sqoop import -D mapred.job.queue.name=xinju --hive-import --connect 'jdbc:oracle:thin:@(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST =
IP地址)(PORT = 1521))(LOAD_BALANCE = yes)(failover = on)(CONNECT_DATA =(SERVER = DEDICATED)(SERVICE_NAME = bighead)(FAILOVER_MODE =(TYPE = SELECT)(METHOD = BASIC)(RETRIES = 180)(DELAY = 5))))' -m 1 --username xinju --password 密码 --table TEMP_XINJU_ZJY_ECELL
参数介绍:
-D mapred.job.queue.name=xinju 选择资源队列名
--hive-import: 导入到HIVE里面,会自动在HIVE中预建表,不加该参数,则默认只到HDFS层面
--connect <jdbc-uri>:指定JDBC列连串
--username <username> :RDBMS的用户
--password <password>:RDBMS的用户对应的密码 (生产系统建议以文件形式传递账号密码保证安全)
-m 进程并发数,这里因为数量较少,选择了1
--table : Oracle内的源表
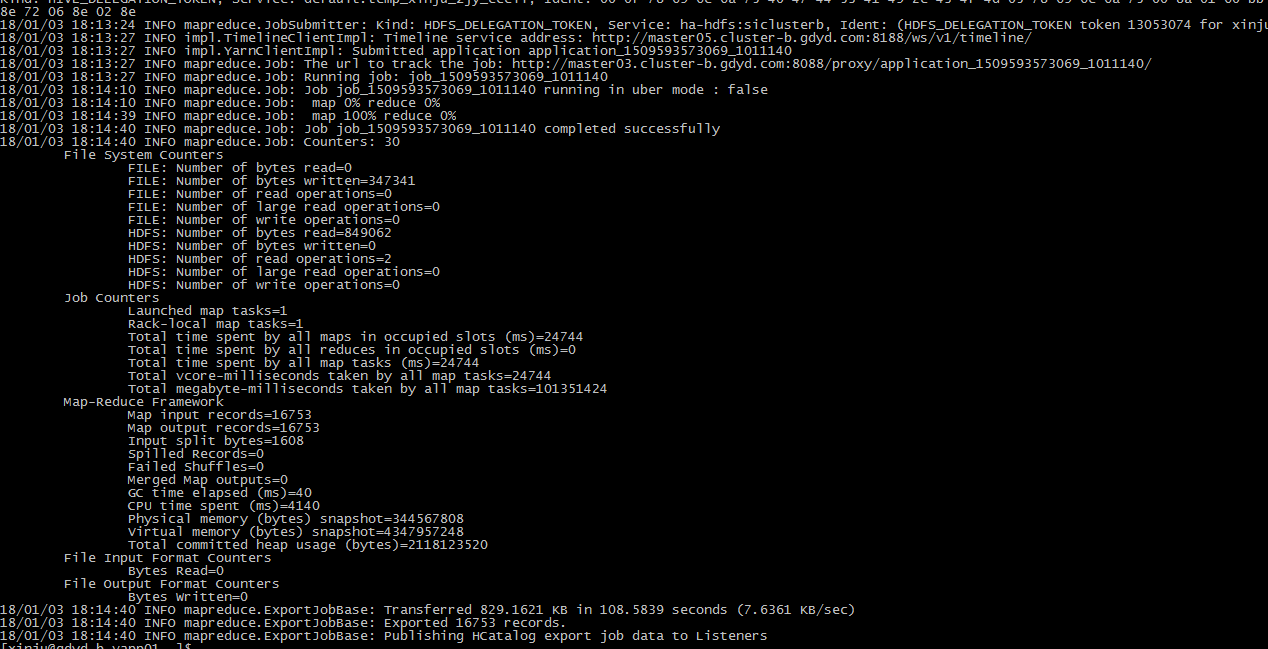
b)执行截图

②Export(Hadoop TO RDBMS)
Export工具从HDFS导数到关系型数据库(本例使用Oracle),目标表需要先在RDBMS中创建,根据用户自定义的分隔符,将输入文件解析成行纪录。
Export有三种模式:INSERT MODE(默认),UPDATE MODE, CALL MODE,其中数据仓库中主要用INSERT MODE方式,UPDATE MODE主要为更新RDBMS中某些纪录数据,而CALL MODE方式,Sqoop则会调用存储过程来更新行纪录。
下面的测试案例采用INSERT MODE方式。HIVE中源表名为temp_xinju_zjy_ecell,纪录条数为16753条,导出到Oracle的表名为temp_xinju_zjy_ecell(与HIVE同名)。具体导出步骤为:
a)在Oracle创建待装载数据的表
create table temp_xinju_zjy_ecell(
ecell_oid number,
ecell_name_en varchar2(400)
)nologging;
b)在sqoop所在的客户端上执行以下命令
sqoop export -D mapred.job.queue.name=xinju -Dorg.apache.sqoop.export.text.dump_data_on_error=true --connect 'jdbc:oracle:thin:@(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST =
IP地址)(PORT = 1521))(LOAD_BALANCE = yes)(failover = on)(CONNECT_DATA =(SERVER = DEDICATED)(SERVICE_NAME = bighead)(FAILOVER_MODE =(TYPE = SELECT)(METHOD = BASIC)(RETRIES = 180)(DELAY = 5))))' \
--username xinju \
--password 密码 \
--hcatalog-table temp_xinju_zjy_ecell \
--columns ECELL_OID,ECELL_NAME_EN \
--table TEMP_XINJU_ZJY_ECELL
参数介绍:
-D mapred.job.queue.name=xinju 选择资源队列名
--connect <jdbc-uri>:指定JDBC列连串
--username <username> :RDBMS的用户
--password <password>:RDBMS的用户对应的密码 (生产系统建议以文件形式传递账号密码保证安全)
--hcatalog-table <table-name>:HDFS关联的HIVE表名
--columns <col,col,col…>: 指定导出的列名
mapred.job.queue.name: 资源队列名
--table:要导入到的关系数据库表(需要大写)
c)执行截图
关于sqoop更多的用法,请参考Apache下的官网链接:
http://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html
ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。在从Oracle抽取到Hadoop大数据平台过程中,我们在数据同步的过程中往往会先抽取(extract)后,直接加载(load)至大数据平台。这样做的目的在于:
通过减少转换操作,减少对源数据库(Oracle)的压力。
充分利用大数据平台并行计算能力,将转换(transform)。
留下一份与源数据库(Oracle)结构和内容相同的数据集,便于后续数据问题排查。
ETL的工具非常多,开源的有kettle,商用的有powercenter,datastage等等,我们项目中一般是使用公司研发提供基于kettle封装的一套ETL工具。
1)首先,建立一个Oracle的数据源
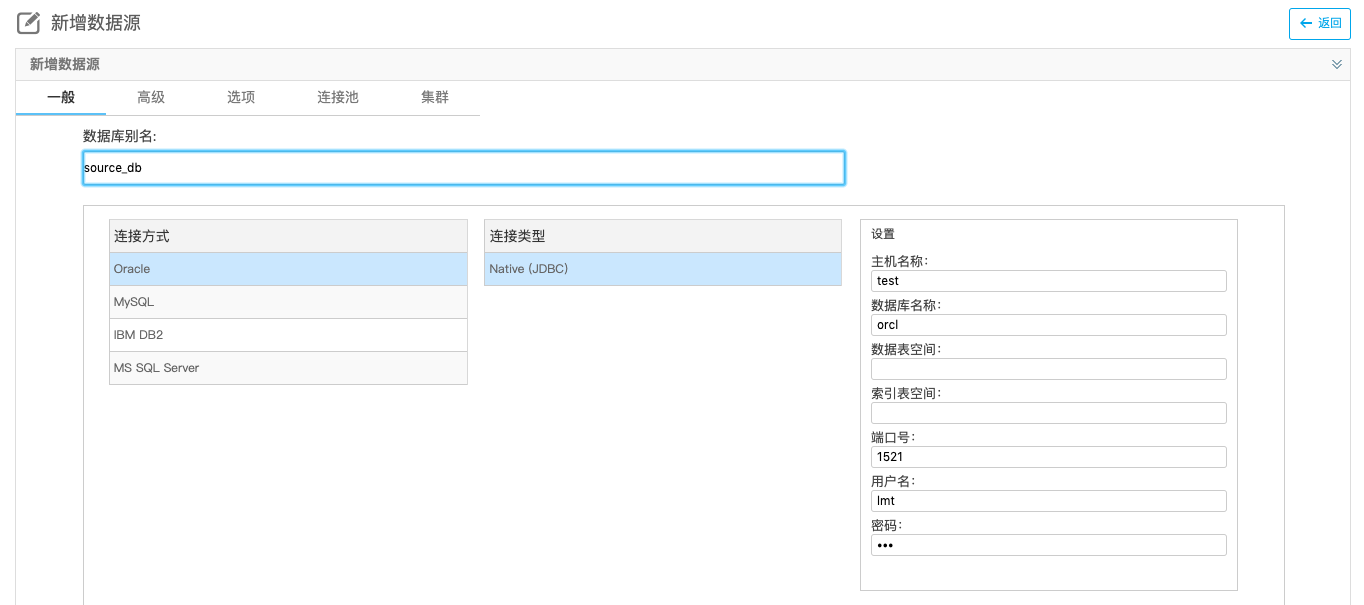
输入跟Oracle数据库相关的信息,主机名、数据库名、端口号、用户、密码之类。
2)创建一个转换

3)从左边的对象列表中拖一个表输入到操作区域

输入数据源同步的表的关键信息,工具会自动完成SQL语句的生成。如有需要也可以再次编辑SQL语句。

4)再向操作区域拉一个HDFS的输出对象
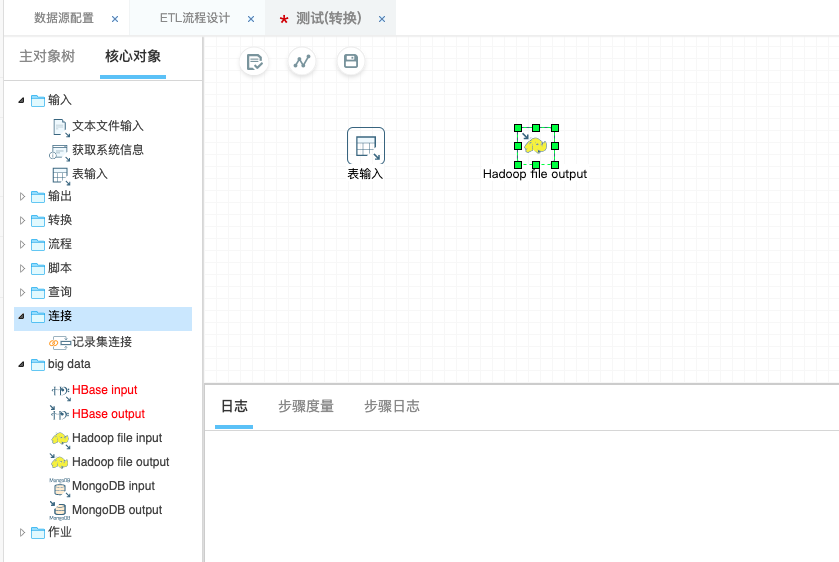
输入连接hadoop以及HDFS文件夹和文件名称。
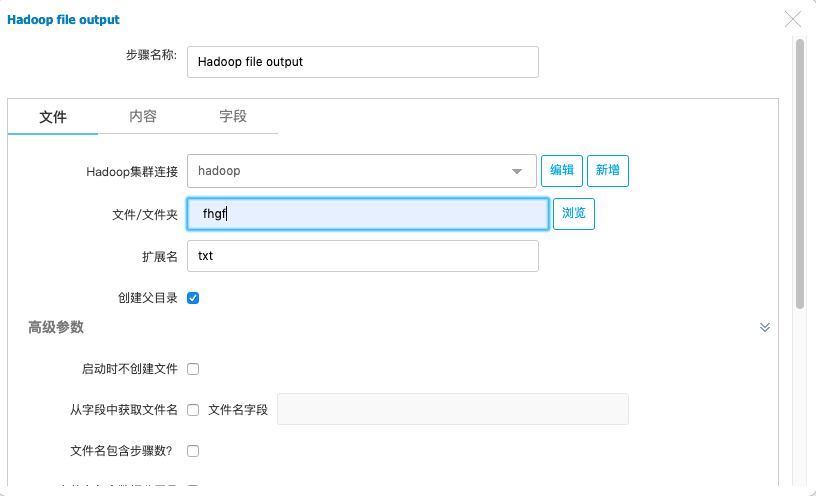
5)将两个数据对象用步骤线连接起来并且保存

6)执行和测试转换逻辑
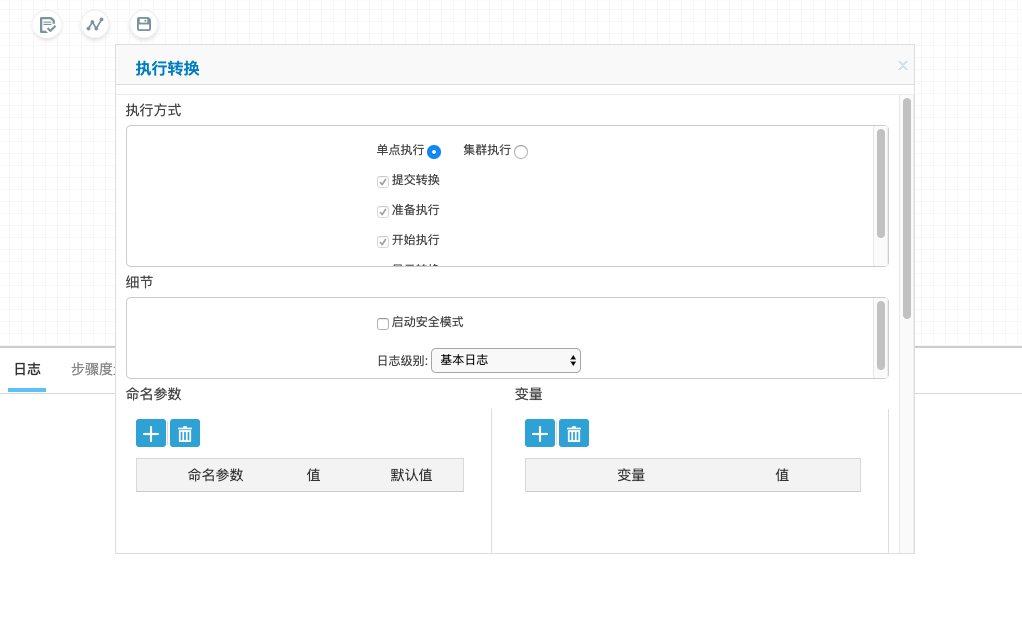
查看转换日志并检查HDFS相关文件是否正常。

7)构建定时调度转换任务,完成数据同步
当然,上述只演示了一个表的简单数据同步,实际过程中往往会同步成百上千的表。这些同步作业也远比示例中的复杂,但是由于使用ETL工具,有可视化的界面,无代码编写上手操作简单,功能也比较强,各种管理功能和日志保存完善,深受项目现场实施人员的欢迎。
Oracle Big Data Connectors 是一个用于集成Hadoop处理与数据仓库操作的软件套件。
Big Data Connectors 的设计利用了 Apache Hadoop的最新特性,可将Hadoop集群和数据库基础架构相连接,以利用海量结构化和非结构化数据提供关键业务洞察。
项目中我们主要使用了BDC的Oracle SQL Connector for HDFS(简称osch)功能,该功能将数据拉入数据库中,数据的移动是通过使用SQL在Oracle数据库中选择数据来启动的。用户可以将数据加载到数据库,或使用Oracle SQL 通过外部表查询Hadoop中的数据。
1)架构

由Oracle数据库以及部署在Oracle系统上面的Hadoop client,osch组件和Hadoop集群组成。原始数据以Hdfs(HIVE)存储于Hadoop集群,Oracle通过osch以外部表的形式在数据库系统内直接读取Hdfs上的数据,或并行直接路径装载数据到Oracle数据库。
2)安装部署
①安装环境
Oracle SQL Connector for HDFS环境要求如下:
a)Hadoop集群
Cloudera's的版本要求在5(CDH5),Hortonworks的版本在2.4.0和2.5.0。
JDK(分布式的在Cloudera's或Hortonworks上)。
Hive 1.1.0, or 1.2.1 (如果需要从HIVE导出)。
b)Oracle数据库和Hadoop客户端
Oracle Database 12c (12.2.0.1 and 12.1.0.2) , Oracle Database 11g release 2 (11.2.0.4 or later).
Hadoop客户端版本与Hadoop集群版本一致(CDH5, or Hortonworks Data Platform 2.4.0 and 2.5.0)。如果Hadoop集群有Kerberos安全认证,则需要在集群KDC中心注册oracle主机用户信息,同时oracle主机下的/etc/krb5.conf需要增加关于KDC中域名信息。
Hadoop客户端和Hadoop集群相同版本的JDK。
②在Oracle安装配置hadoop客户端
只需要安装Hadoop jar文件和配置文件,不需要勾选所有选项。
a)下载hadoop客户端
按照2.1安装环境,下载对应版本的客户端(CDH5, or Hortonworks Data Platform 2.4.0 and 2.5.0)。
b)解压文件
解压文件,并复制到Oracle的某一固定路径如/usr/osch_hadoop。
c)环境变量设置
设置HADOOP_HOME为/usr/osch_hadoop,并在PATH变量中增加HADOOP_HOME/bin。
设置JAVA_HOME为JDK的安装路径如/usr/bin/java。
d)安全设置
如果Hadoop集群有Kerberos安全认证,则需要在集群KDC中心注册oracle主机用户信息,同时oracle主机下的/etc/krb5.conf需要增加关于KDC中域名信息。
e)验证HDFS文件是否可访问
生效以上环境变量信息,并敲入如下命令:
$ hdfs dfs -ls /user
如果现实的内容同Hadoop集群一样,则表示成功,否则需要重新修改上面的步骤。
f)RAC配置
如果Oracle是RAC,则需要在每个节点上进行如上操作,且每个节点需配置一致的参数和路径信息。
③安装Oracle SQL Connector for HDFS
a)下载Oracle SQL Connector for HDFS
Oracle Big Data Connectors Software下载地址:
http://www.oracle.com/technetwork/bdc/big-data-connectors/downloads/index.html
可选择下载我们只需要的功能Oracle SQL Connector for HDFS。
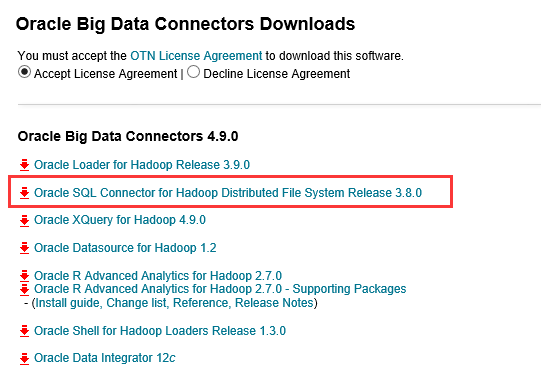
下载的压缩文件结构如下:
orahdfs-<version>
bin/
hdfs_stream
hdfs_stream.cmd
doc/
README.txt
examples/
sql/
mkhive_unionall_view.sql
jlib/
ojdbc7.jar
oraloader.jar
ora-hadoop-common.jar
oraclepki.jar
orahdfs.jar
osdt_cert.jar
osdt_core.jar
log/
b)解压文件
unzip oraosch-<version>.zip
unzip orahdfs-<version>.zip 到指定路径
c)变量设置
编辑orahdfs-<version>/bin/hdfs_stream文件,设置:
PATH变量,将hadoop的bin目录添加进去,如/usr/lib/hadoop/bin。
JAVA_HOME变量,设置JAVA安装目录,如/usr/bin/java。
d)安全设置
同2.2中的安全设置,如果已经设置,则不需要重新设置。
e)验证hdfs_stream生效
$ ./hdfs_stream
Usage: hdfs_stream locationFile
如果看不到usage等信息,有可能是权限不够,可进行授权:
$ chmod 755 OSCH_HOME/bin/hdfs_stream
f)RAC设置
如果Oracle是RAC,则需要在每个节点上进行如上操作,且每个节点需配置一致的参数和路径信息。
g)创建hdfs_stream存放的数据库目录
进入数据库,创建目录,如果是RAC,需要确保所有节点均可访问。
SQL> CREATE OR REPLACE DIRECTORY osch_bin_path AS '/etc/orahdfs-<version>/bin';
h)Oracle数据库用户权限设置
给要使用oracle sql connector for HDFS的数据库用户以下权限:
CREATE SESSION.
CREATE TABLE.
CREATE VIEW.
EXECUTE on the UTL_FILE PL/SQL package.
READ and EXECUTE on the OSCH_BIN_PATH directory created during the installation of Oracle SQL Connector for HDFS. Do not grant write access to anyone. Grant EXECUTE only to those who intend to use Oracle SQL Connector for HDFS.
READ and WRITE on a database directory for storing external tables, or the CREATE ANY DIRECTORY system privilege. For Oracle RAC systems, this directory must be on a shared disk that all Oracle instances can access.
A tablespace and quota for copying data into the Oracle database. Optional.
例如创建数据库用户xinju,该用户需要使用osch功能,则权限需要:
CONNECT / AS sysdba;
CREATE USER xinju IDENTIFIED BY password
DEFAULT TABLESPACE xinju
QUOTA UNLIMITED ON xinju;
GRANT CREATE SESSION, CREATE TABLE, CREATE VIEW TO xinju;
GRANT EXECUTE ON sys.utl_file TO xinju;
GRANT READ, EXECUTE ON DIRECTORY osch_bin_path TO xinju;
GRANT READ, WRITE ON DIRECTORY external_table_dir TO xinju;
3)数据传输
①Export(Hadoop TO RDBMS)
BDC的OSCH只提供从Hadoop到Oracle的导入功能,不提供Oracle到Hadoop的导入功能。
a)配置环境变量
export OSCH_HOME=/app/bighead/orahdfs-3.8.0
export HADOOP_CLASSPATH=/app/bighead/orahdfs-3.8.0/jlib/*:$HADOOP_CLASSPATH
b)创建外部表
hadoop jar $OSCH_HOME/jlib/orahdfs.jar oracle.hadoop.exttab.ExternalTable \
-D oracle.hadoop.exttab.preprocessorDirectory=OSCH_BIN_PATHB \
-D oracle.hadoop.exttab.sourceType=text \
-D oracle.hadoop.exttab.tableName=temp_xinju_20180110 \
-D oracle.hadoop.exttab.locationFileCount=16 \
-D oracle.hadoop.exttab.dataPaths="/apps/hive/warehouse/xinju/temp_xinju_zjy_dgcache_alldg/000000_0" \
-D oracle.hadoop.exttab.columnNames="day_id,lte_soc_httpsvruser_005,lte_soc_httpsvruser_007,dl_rate,lte_soc_httpsvruser_001,lte_soc_httpsvruser_002,get_rate" \
-D oracle.hadoop.exttab.defaultDirectory=bdc_pathB \
-D oracle.hadoop.connection.url=jdbc:oracle:thin:@//IP地址:1521/xinju \
-D oracle.hadoop.connection.user=xinju \
-D oracle.hadoop.connection.password=密码 \
-D oracle.hadoop.exttab.fieldTerminator="," \
-D oracle.hadoop.exttab.nullIfSpecifier=null –createTable
主要参数说明:
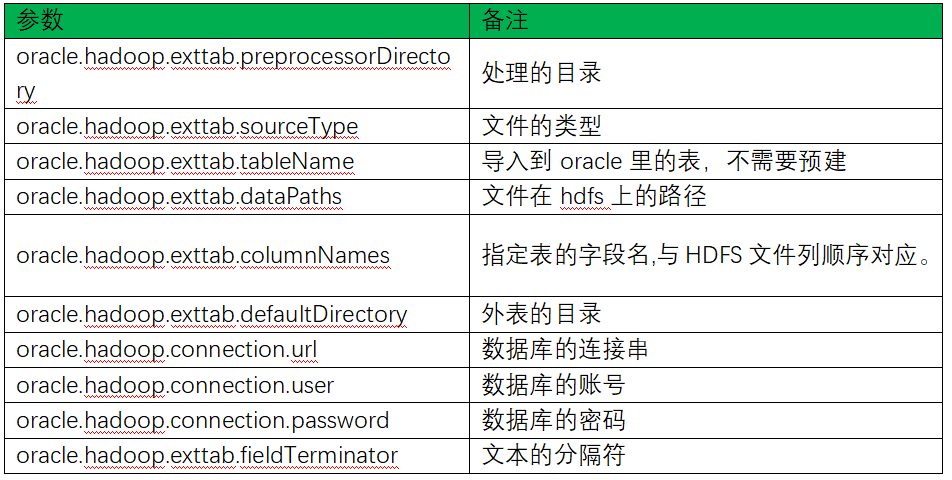

c)创建内部表
create table temp_xinju_20180111(
start_date_time number,
day_id number,
lte_soc_httpsvruser_005 number,
lte_soc_httpsvruser_007 number,
dl_rate number(19,4),
lte_soc_httpsvruser_001 number,
lte_soc_httpsvruser_002 number,
get_rate number(19,4)
) nologging
d)把外部表数据并行装载到内部表(并行度大小看CPU负荷及数据量)
sqlplus -S "xinju/密码@IP地址:1521/xinju" <<EOF
alter session enable paralle dml parallel 16;
insert into temp_xinju_20180111(day_id,lte_soc_httpsvruser_005,lte_soc_httpsvruser_007,dl_rate,lte_soc_httpsvruser_001,lte_soc_httpsvruser_002,get_rate)
select day_id,lte_soc_httpsvruser_005,lte_soc_httpsvruser_007,dl_rate,lte_soc_httpsvruser_001,lte_soc_httpsvruser_002,get_rate from temp_xinju_20180110;
commit;
alter session disable paralle dml parallel;
EOF
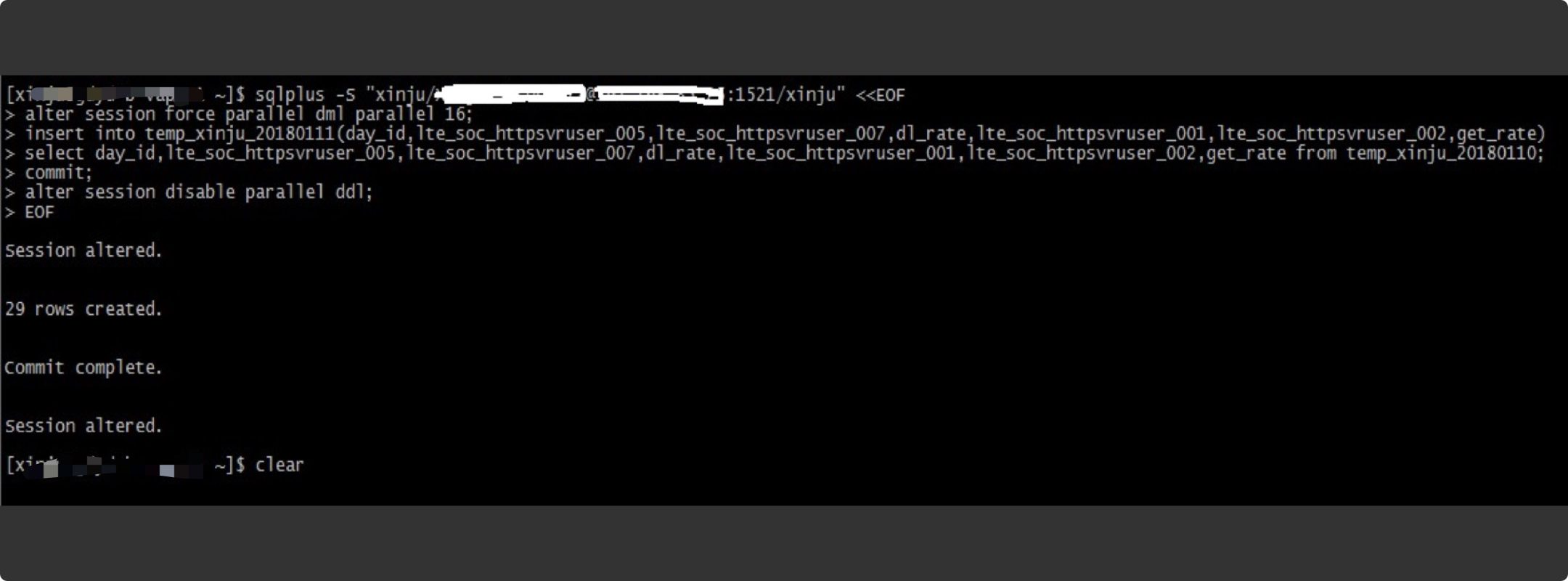
e)删除外部表
hadoop jar $OSCH_HOME/jlib/orahdfs.jar oracle.hadoop.exttab.ExternalTable \
-D oracle.hadoop.exttab.preprocessorDirectory=OSCH_BIN_PATHB \
-D oracle.hadoop.exttab.sourceType=text \
-D oracle.hadoop.exttab.tableName=temp_xinju_20180110 \
-D oracle.hadoop.exttab.locationFileCount=16 \
-D oracle.hadoop.exttab.dataPaths="/apps/hive/warehouse/xinju/temp_xinju_zjy_dgcache_alldg/000000_0" \
-D oracle.hadoop.exttab.columnNames="day_id,lte_soc_httpsvruser_005,lte_soc_httpsvruser_007,dl_rate,lte_soc_httpsvruser_001,lte_soc_httpsvruser_002,get_rate" \
-D oracle.hadoop.exttab.defaultDirectory=bdc_pathB \
-D oracle.hadoop.connection.url=jdbc:oracle:thin:@//IP地址:1521/xinju \
-D oracle.hadoop.connection.user=xinju \
-D oracle.hadoop.connection.password=密码\
-D oracle.hadoop.exttab.fieldTerminator="," \
-D oracle.hadoop.exttab.nullIfSpecifier=null –drop
数据同步的工具其实还有很多,这里只列举了一些我们项目常用的。除此以外,其实实际项目中还有通过canal、GoldenGate、Flume、kafka等工具构建数据实时同步和计算的场景。这里就这些数据同步的场景需要因此实际情况来选择。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721