
作者介绍
梁铭图,新炬网络首席架构师,十多年数据库运维、数据库设计、数据治理以及系统规划建设经验,拥有Oracle OCM、Togaf企业架构师(鉴定级)、IBM CATE等认证,曾获dbaplus年度MVP以及华为云MVP等荣誉,并参与数据资产管理国家标准的编写工作。在数据库运维管理和架构设计、运维体系规划、数据资产管理方面有深入研究。
我们在数据库日常运维过程中,经常会使用数据泵datapump(expdp\impdp)对数据库做导出导入操作,从而实现数据库的部分或全量数据迁移(如搭建测试库、迁移生产库、合并数据库等)。
然而在数据的导出导入过程中,我们会发现比较大的大字段表会很影响整个导出导入效率,甚至无法正常完成。普通表我们可以采取加并行参数(parallel)来提升导出导入效率,但此参数针对于大字段表是无效的,即使加了并行参数,大字段表还是单进程执行导出导入操作。
下面让我通过一个案例来说明要如何使用数据泵来迁移大字段表。
一、背景
有套业务子库(大小大概2T)需要迁移合并至其业务主库,由于是合并操作,在排除使用ADG、XTTS、OGG等迁移方案之后,考虑采用数据泵导出导入的方式进行合并迁移。整个合并迁移时间(包括数据库迁移合并+业务测试)限制在7小时以内,数据库中大部分表通过并发导出导入等优化方式可以在5小时内完成,唯独有一张包含200多G大字段对象的表仅仅是导出花费十几个小时也未完成,直至报错(报快照过久)。通过扩展undo表空间及调整参数undo_retention,最终还是导出失败。
二、分析原因
LOB字段的表导出时即使加并行参数也是无效的,还是单进程在导出表数据,表本身包含220G数据,大字段数据就占202G,数据量比较大,加上源端服务器是普通的X86服务器,数据在导出过程中还会发生变化,最终由于耗时过久,导出失败。

三、解决问题
数据库总共有2T数据,其他1.8T数据通过开并行等手段基本可以在2小时之内导出完成,唯独此大字段表即使导出十几个小时也无法正常完成,所以首先我们要尝试解决并行的问题,通过一定的手段使大字段表的导出能够并发进行。
既然并行参数parallel对大字段表是无效的,在不改变表结构及数据的情况下,我们可以尝试将表从逻辑上拆分成一个一个的小单位,每个小单位拉起一个导出进程,这样就可实现大字段表的并行导出操作。
那如何逻辑拆分大字段表呢?如果表上有日期字段,我们可以按日期字段拆分表,再如表上有区域字段,我们也可以按区域字段做拆分,即使没有特别明显的可以区分数据的字段,我们也可以按rowid去做拆分。
其实按rowid去做拆分是一个很好的方式,因为oracle做数据插入时是无序插入的(同一时刻多个进程对同一张表做插入,数据可能存放在不同的数据块上,并不是一个数据块使用完之后,再插入新的数据块),但了解oracle存储结构的会知道,如果我们不管数据的组成,rowid(rowid是由对象编号+文件号+数据块编号+行号组成)其实是有序的,我们如果按rowid有序的去做拆分,就可以尽量少读数据块(相较于索引扫描及全表扫),从而提升整个导出效率。
准备工作:首先我们创建一张中间表,将表数据的rowid按顺序记录下来(全表扫有序读取相邻的数据块),方便之后做拆分
create table t_test_split as select /*+parallel(4)*/rowid sou_rowid,rownum rn,(select current_scn from v$database) scn from t_test;
虽然合并迁移过程中业务子库是停业务不再读写的,但为了保证数据的一致性,我们还是选择把数据库的scn号记录下来。例如在数据库不停机的情况下,你在搭建OGG环境初始化大字段表时,这里保存的scn号就非常有用了。
正式执行导出导入:源库拉起导出主进程,通过rowid将表拆分成一个一个的小单元,每个小单元拉起一个独立子进程单独导出一部分表数据,子进程导出完成生成一个标记文件用来标记子进程已导出完成。目标库拉起导入的主进程,监控导出的标记文件,一旦发现导出完成的子进程标记文件就开始执行导入,一直到源库小单元全部导出完成为止。
由于案例中的环境在源库和目标库之间设置了nfs共享目录,所以无需scp网络传输导出的数据文件及标记文件
我们用shell来实现大字段表并发导出,首先配置好相关的环境变量,初始化一些实用方法
vi expdp_env_conf.sh
#!/bin/sh
. ~/.bash_profile
#############set var################
#导出路径
expdp_dir=qianyi
#实例名
oracle_sid=test1
#大字段表所属用户
owner=test
#大字段表名
table_name=t_test
#第一步创建的中间表
mid_tab_name=t_test_split
#数据拆分的份数
split_count=10
#并发进程数(无需和数据拆分份数相同,如可将数据拆分成100份,但导出进程最大并发10个
#做完一批在做下一批)
parallel=10
#############set var################
export ORACLE_SID=${oracle_sid}
#define func
#编写一个传入一个SQL,返回SQL查询结果的函数
function getValueBySQL()
{
val=`sqlplus -s / as sysdba<< EOF
set heading offset pagesize 0;
set feedback off;
set verify off;set echo off;
$1;
exit;
EOF`
echo "${val}"
}
#获得实际导数路径
expdp_real_dir=`getValueBySQL "select DIRECTORY_PATH from dba_directories where DIRECTORY_NAME = upper('${expdp_dir}')"`
#每份数据包含多少行数据,如100万行数据分成10份,每份就是10万行
per_cnt=`getValueBySQL "select ceil(count(*)/
${split_count}) from ${owner}.${mid_tab_name}"`
#获得SCN号
scn=`getValueBySQL "select to_char(scn) from
${owner}.${mid_tab_name} where rownum=1"`
我们编写拆分并导出大字段表的主体shell脚本
vi expdp_lob_tab.sh
#!/bin/sh
#初始化环境变量
. ~/.bash_profile
. ./expdp_env_conf.sh
#开始导出数据
echo "`date "+%Y%m%d %T"` expdp data start"
split_num=0
while [[ ${split_num} -lt ${split_count} ]]
do
#查看有没有导出进程,最大只允许发起环境变量中定义的paralle个导出进程
para_cnt=`ps -ef|grep expdp|grep -v ".sh"|grep -v grep|wc -l`
if [ ${para_cnt} -lt ${parallel} ]; then
#del par file
if [ -f "${expdp_real_dir}/expdp_big_tab_${table_name}_${split_num}.par" ]; then
rm -f ${expdp_real_dir}/expdp_big_tab_${table_name}_${split_num}.par
fi
#create par file
cat>${expdp_real_dir}/expdp_big_tab_${table_name}_${split_num}.par<<eofUSERID=' / as sysdba'
DIRECTORY=${expdp_dir}
CONTENT=DATA_ONLY
CLUSTER=N
DUMPFILE=expdp_big_tab_${table_name}_${split_num}.dmp
LOGFILE=expdp_big_tab_${table_name}_${split_num}.log
TABLES=${owner}.${table_name}
FLASHBACK_SCN=${scn}
QUERY='${owner}.${table_name}:"where rowid in (select sou_rowid from ${owner}.${mid_tab_name} where rn between (${split_num}*${per_cnt}+1) and (${split_num}+1)*${per_cnt})"'
eof
#del dmp file
if [ -f "${expdp_real_dir}/expdp_big_tab_${table_name}_${split_num}.dmp" ]; then
rm -f ${expdp_real_dir}/expdp_big_tab_${table_name}_${split_num}.dmp
fi
#exec expdp
par_file=${expdp_real_dir}/expdp_big_tab_${table_name}_${split_num}.par
#这里必须要创建一个子shell,不然无法实现并发导数,如果不创建子shell,直接在主进程拉起导数,则主shell进程需要等待当前发起的导数命令完成才会继续往下执行从而循环发起其他导数进程
sh expdp_exec.sh ${par_file} &
#exec expdp don't build process immediate.It will not be accurate when exec "ps -ef|grep expdp". so sleep 2s;
sleep 2
let "split_num += 1"
else
sleep 10
fi
done
echo "`date "+%Y%m%d %T"` expdp data done"
生成的导数文件如下图:
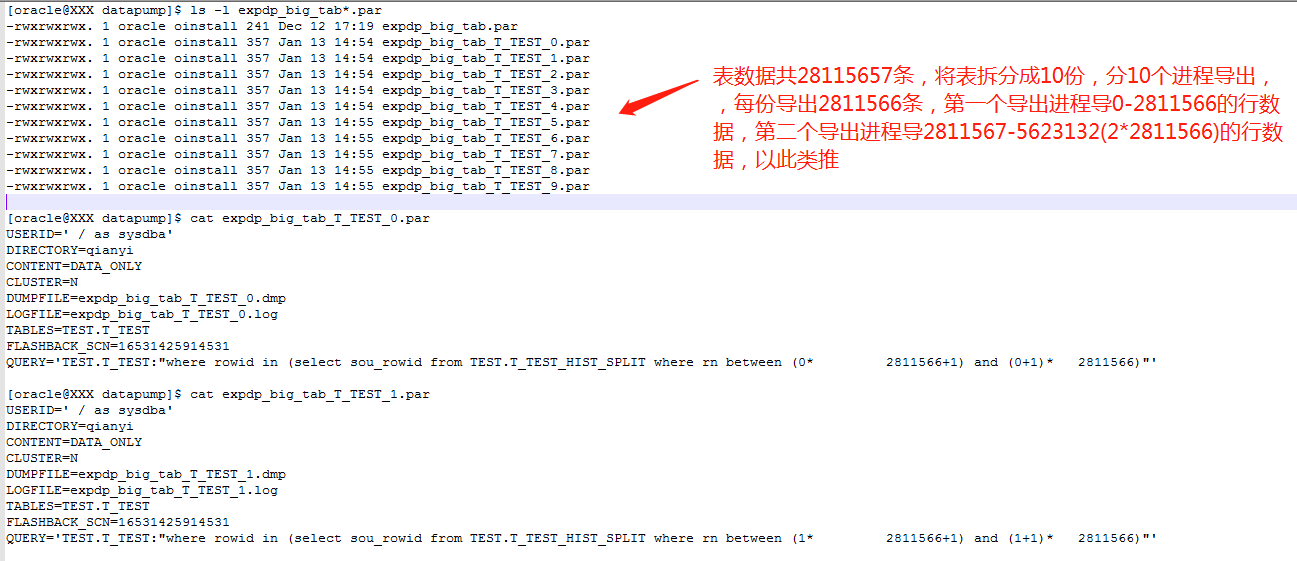
编写拆分并导出大字段表的子shell脚本
vi expdp_exec.sh
#!/bin/sh
. ./expdp_env_conf.sh
par_file=$1
expdp parfile=${par_file}
#每一个导数子进程完成以后生成一个.done后缀的文件,用来告诉导入进程导出已完成,导入进程可以做导入了
done_file_name=`ls "${par_file}"|sed 's/.par/.done/g'`
cat /dev/null>${done_file_name}
nohup sh expdp_lob_tab.sh>expdp_lob_tab.sh.out &
同样的,我们配置导入相关的环境变量,初始化一些实用方法
vi impdp_env_conf.sh
#!/bin/sh
. ~/.bash_profile
#set var
#imp directory
impdp_dir=QIANYI
oracle_sid=target1
owner=test
table_name=t_test
split_count=10
#导入时是无法并行的,当一个导入进程发起后,其他导入进程会等待获取表锁,这里设置为2即可
parallel=2
export ORACLE_SID=${oracle_sid}
#define func
#select value by sql
function getValueBySQL()
{
val=`sqlplus -s / as sysdba<< EOF
set heading off
set pagesize 0;
set feedback off;
set verify off;
set echo off;
$1;
exit;
EOF`
echo "${val}"
}
impdp_real_dir=`getValueBySQL "select DIRECTORY_PATH from dba_directories where DIRECTORY_NAME = upper('${impdp_dir}')"`
home_dir=`pwd`
我们编写导入大字段表的主体shell脚本,和导出主shell基本类似
vi impdp_big_tab.sh
#!/bin/sh
. ./impdp_env_conf.sh
echo "`date "+%Y%m%d %T"` impdp data start"
split_num=0
while [[ ${split_num} -lt ${split_count} ]]
do
cd ${impdp_real_dir}
para_cnt=`ps -ef|grep impdp|grep -v ".sh"|grep -v grep|wc -l`
if [ ${para_cnt} -lt ${parallel} ]; then
impdp_file=`ls *.done 2>/dev/null|head -1|sed 's/.done/.dmp/g'`
if [ -f "${impdp_file}" ]; then
par_file=`ls ${impdp_file}|sed 's/expdp_/impdp_/g'|sed 's/.dmp/.par/g'`
log_file=`ls ${impdp_file}|sed 's/expdp_/impdp_/g'|sed 's/.dmp/.log/g'`
#del par file
if [ -f "${par_file}" ]; then
rm -f ${par_file}
fi
#create par file
cat>${par_file}<<eof
USERID=' / as sysdba'
DIRECTORY=${impdp_dir}
CONTENT=DATA_ONLY
DUMPFILE=${impdp_file}
LOGFILE=${log_file}
TABLE_EXISTS_ACTION = APPEND
eof
#exec impdp
cd ${home_dir}
sh impdp_exec.sh ${par_file} &
#exec impdp don't build process immediate.It will not be accurate when exec "ps -ef|grep impdp". so sleep 2s;
sleep 2
let "split_num += 1"
else
echo "waiting for expdp data done"
sleep 10
fi
else
sleep 10
fi
done
echo "`date "+%Y%m%d %T"` impdp data done"
编写导入大字段表的子shell脚本
vi impdp_exec.sh
#!/bin/sh
. ./impdp_env_conf.sh
par_file=$1
cd ${impdp_real_dir}
#导入过程中将导出已完成的子进程标记文件改名为.done.impdping的后缀文件,以免重复导入
exp_done_file_name=`ls "${par_file}"|sed 's/impdp_/expdp_/g'|sed 's/.par/.done/g'`
imping_file_name=`ls "${par_file}"|sed 's/impdp_/expdp_/g'|sed 's/.par/.done.impdping/g'`
mv ${exp_done_file_name} ${imping_file_name}
impdp parfile=${par_file}
#导入完成以后将导入过程中的标记文件改名为.done.impdp.finish,用来标记导入已完成
imp_done_file_name=`ls "${par_file}"|sed 's/impdp_/expdp_/g'|sed 's/.par/.done.impdp.finish/g'`
mv ${imping_file_name} ${imp_done_file_name}
nohup sh impdp_big_tab.sh>impdp_big_tab.sh.out &
导入完成结果如下图:
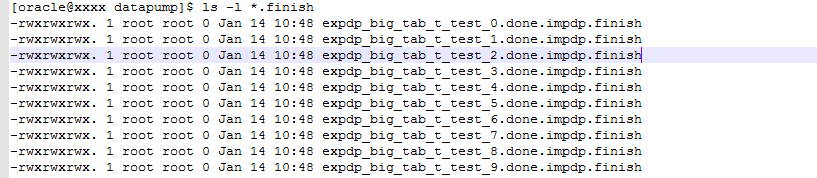
四、成效
原本十几个小时(可能不只这么久,因为十几个小时之后导出报错)无法导出的大字段表,最终两个多小时就导出完成。加上导入时间最终可将整个导出导入时间控制在5小时以内,满足迁移合并时间要求。
五、总结
我们在对大字段表用数据泵做导出导入时,由于并行参数对其无效,如果发现导出导入效率无法满足要求,可尝试人工将表逻辑拆分成小单元,每个小单元独立导出一部分数据,以此来提升导出导入效率。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721