
袁伟翔,新炬网络高级专家,长期服务于运营商,精通Oracle数据库故障诊断、内核技术,具有10多年数据库开发运维经验。
我们在日常工作中,就像西天取经的僧人,总是会遇到各式各样的“妖怪”。这些“妖怪”总是一个又一个的阻挡在我们面前,你必须想办法击败它们。
听说小A同学最近遇到了一个很妖的问题,就这个问题我们来采访一下小A同学。
小B:你觉得RAC GC问题一般在什么情况下会产生?
小A:这个问题嘛其实很简单,我们要先从Oracle RAC的机制说起,RAC是一种共享磁盘的体系结构,多个服务器上的实例会同时打开数据库,并缓存磁盘中的数据。而当在一个节点上执行SQL,需要请求的buffer在remote实例上时,就会使用心跳进行传输。此时在本地节点上可能就会观察到GC类的等待事件。一般大量GC问题都是应用交叉访问引起的。
小B:那这一次的GC问题是应用交叉访问导致的吗?
小A:这次并不是,因为很多时候我们观察到系统权限类的SQL语句也在等待大规模的gc buffer busy acquire。
小B:系统语句?
小A:对,就是下面这个语句,他也产生了很多的GC。
select event,p1,p2,p3 from v$session where sql_id='05uqdabhzncdc'
EVENT P1 P2 P3
---------------------------------------------------------------- ---------- ---------- ----------
gc buffer busy acquire 1 46842 1
gc buffer busy acquire 1 46842 1
gc buffer busy acquire 1 46842 1
gc buffer busy acquire 1 46842 1
gc buffer busy acquire 1 46842 1
gc buffer busy acquire 1 46842 1
gc cr request 1 46842 1
gc buffer busy acquire 1 46842 1
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID 05uqdabhzncdc, child number 1
-------------------------------------
select role# from defrole$ d,user$ u where d.user#=:1 and
u.user#=d.user# and u.defrole=2 union select privilege# from sysauth$
s,user$ u where (grantee#=:1 or grantee#=1) and privilege#>0 and not
exists (select null from defrole$ where user#=:1 and
role#=s.privilege#) and u.user#=:1 and u.defrole=3
Plan hash value: 552533229
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 7 (100)| |
| 1 | SORT UNIQUE | | 2 | 30 | 7 (29)| 00:00:01 |
| 2 | UNION-ALL | | | | | |
| 3 | NESTED LOOPS | | 1 | 14 | 2 (0)| 00:00:01 |
|* 4 | TABLE ACCESS CLUSTER| USER$ | 1 | 7 | 1 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN | I_USER# | 1 | | 1 (0)| 00:00:01 |
|* 6 | INDEX RANGE SCAN | I_DEFROLE1 | 1 | 7 | 1 (0)| 00:00:01 |
| 7 | NESTED LOOPS | | 1 | 16 | 2 (0)| 00:00:01 |
|* 8 | TABLE ACCESS CLUSTER| USER$ | 1 | 7 | 1 (0)| 00:00:01 |
|* 9 | INDEX UNIQUE SCAN | I_USER# | 1 | | 1 (0)| 00:00:01 |
| 10 | INLIST ITERATOR | | | | | |
|* 11 | INDEX RANGE SCAN | I_SYSAUTH1 | 1 | 9 | 1 (0)| 00:00:01 |
|* 12 | INDEX UNIQUE SCAN | I_DEFROLE1 | 1 | 7 | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("U"."DEFROLE"=2)
5 - access("U"."USER#"=:1)
6 - access("D"."USER#"=:1)
8 - filter("U"."DEFROLE"=3)
9 - access("U"."USER#"=:1)
11 - access((("GRANTEE#"=:1 OR "GRANTEE#"=1)) AND "PRIVILEGE#">0)
filter( IS NULL)
12 - access("USER#"=:1 AND "ROLE#"=:B1)
小B:这个语句感觉没什么问题啊,这是查数据字典权限的,执行计划很好,关键表走的UNIQUE SCAN,应该很快就返回结果的。
小A:是的,正常情况都是秒出结果的,并不会产生GC等待。但是我们这个有点小异常,经常看到100-200个GC等待事件。
小B:那究竟是什么问题呢?
小A:我们先来看AWR报告吧,从11.2.0.4我们就可以通过来Interconnect Ping Latency Stats查看网络延迟类的问题了。

你注意看,这是2节点的AWR报告。报告里ping 1和ping 3节点的延迟非常的高。这里分别是做了500字节和8KB的ping,平均延迟都是30几ms和10几ms。我们在看oswatch,从节点1到节点2的traceroute可以看到正常时间点是0.1ms,慢的时候足足5ms。
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
zzz ***Fri Sep 6 10:00:10 CST 2019
traceroute to 192.168.187.129 (192.168.187.129), 30 hops max, 60 byte packets
1 sid1-priv (192.168.187.129) 0.126 ms 0.103 ms 0.100 ms
traceroute to 192.168.187.130 (192.168.187.130), 30 hops max, 60 byte packets
1 sid2-priv (192.168.187.130) 5.015 ms 5.096 ms 5.074 ms <<<<<<<<<<<<<<<<<<<<<<<<<<<
traceroute to 192.168.187.131 (192.168.187.131), 30 hops max, 60 byte packets
1 sid3-priv (192.168.187.131) 1.286 ms 1.176 ms 1.156 ms
zzz ***Fri Sep 6 10:00:41 CST 2019
traceroute to 192.168.187.129 (192.168.187.129), 30 hops max, 60 byte packets
小B:嗯,这么看来,是网络问题啊,网络延迟这么高,GC高那应该是理所当然的!
小A:错了,表面看是网络延迟问题,但是经过我们的验证发现,把数据库停下来之后,网络延迟就消失了。当没有业务运行的时候,延迟都在0.00几,这说明是业务的压力上来导致的延迟。
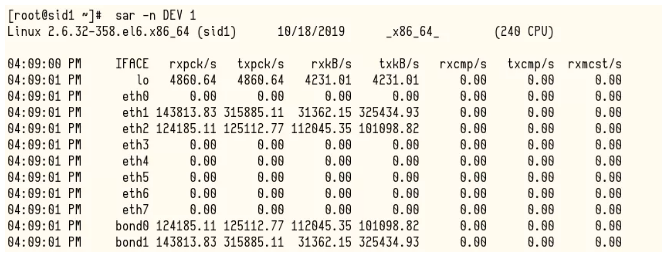
这里bond0是双网卡绑定的私网的地址。rxkb/s是每秒收包的数量,而txkb/s是每秒发包的数量。这里数据库运行的时候每秒收发都上100MB/S了。
小B:那这个问题,怎么处理的?
小A:这个问题说实话是比较妖的,按照道理说这个网卡是万兆网卡,不至于100MB/S就处理不过来了,我们开始怀疑肯定是硬件之类的问题,或者是网络配置的问题,于是我们首先和其他数据库主机做了对比,就发现这个网卡的绑定模式和其他数据库不太一样。这个网卡的绑定模式是4。
说到网卡绑定模式,主要有7种模式。分别是:
mode=0 round-robin轮询策略(Round-robin policy)
mode=1 active-backup主备策略(Active-backup policy)
mode=2 load balancing (xor)异或策略(XOR policy)
mode=3 fault-tolerance (broadcast)广播策略(Broadcast policy)
mode=4 lacp IEEE 802.3ad 动态链路聚合(IEEE 802.3ad Dynamic link aggregation)
mode=5 transmit load balancing适配器传输负载均衡(Adaptive transmit load balancing)
mode=6 adaptive load balancing适配器负载均衡(Adaptive load balancing)
当前我们采取的是动态链路聚合模式,这种模式必须是两块网卡具备相同速率和双工模式才行。而且还需要交换机的支持。这种模式本身也没太大的问题,不过不是很常用。
一般应用的是mode=0的轮询策略、mode=1的主备策略,还有mode=6的负载均衡方式。由于其他数据库使用的是mode=1,唯独这个使用的是mode 4,首先怀疑的就是这个点。
但是因为停机时间一个月只有一次,没有办法进行测试,这次大家集体商量之后,决定双网卡绑定工作模式改造的同时,把网卡、网卡插槽、网线都更换一下。彻底的排除硬件上网络可能出现的问题。
小B:嗯,那做完这些操作之后,变好了吗?
小A:没有,当我们把这些操作都做了,数据库启动之后,白天工作时间段延迟依旧很高。
小B:额,那不是没找到问题的根源?
小A:是的,我们又仔细的检查了一遍,这次发现主要来源于oswatch中的mpstat,可以看到在业务高峰期cpu 15的%soft,总是100%。这个发现是非常重要的。
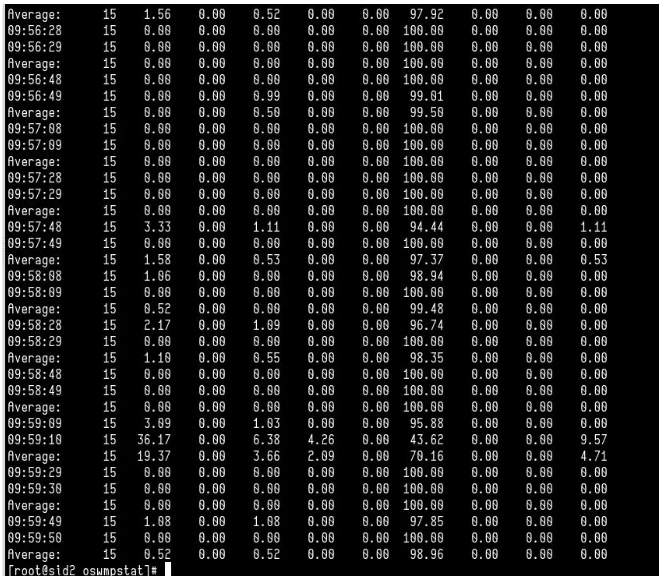
在网上搜索一番,可以发现大量的网卡软中断导致的网络延迟。
小B:越来越精彩了,这块属于网络问题了,我们DBA遇到这种问题该怎么办呢?
小A:我们要研究啊。DBA什么事情都要干,必须追求卓越。
网卡与操作系统的交互其中一个就是方式就是中断,网卡在收到了网络信号之后,主动就发送中断到cpu,而cpu会立即停止其他事情对这个中断信号进行处理。
由于数据包速率的增长,带来的中断渐渐超过了单个cpu核可处理的范围。从而导致了网络延迟和丢包。
在这里我还要提高Linux上的一个服务,叫做irqbalance。该服务就是专门解决网卡性能问题的,用于优化中断分配,将中断尽可能的均匀的分发给各个cpu core,充分利用cpu多核,提升性能。
虽然开启了这个服务,但是我们实际情况是网卡中断就绑定在特殊的cpu 15上面。我们必须把这个中断手动重新绑一下。这个就不得不提到中断亲缘性(smp_affinity)设置。只有 kernel 2.4 以后的版本才支持把不同的硬件中断请求(IRQs)分配到特定的 CPU 上,这个绑定技术被称为 SMP IRQ Affinity。当前操作系统版本是RedHat 6,内核是2.6的。我们可以查看操作系统自带的说明:Linux-2.6.31.8/Documentation/IRQ-affinity.txt
至于绑定方式,因为购买的是华为服务器,在华为服务器的性能优化最佳的附录里面,会有网卡中断绑定的方法介绍。

操作方法有点复杂:
① 首先我们需要停止irqbalance服务。
Service irqbalance off
② 确认哪块网卡是私有网卡,然后执行下列语句,查看分配给网卡的中断号。
cat /proc/interrupts | grep -i ethx
③ 查看中断号和cpu绑定的情况,根据上面的中断号查看和cpu的亲缘性。
cat /proc/irq/126/smp_affinity
④ 中断绑定,将ethx的N个中断绑定到不同的cpu。
echo 16 > /proc/irq/126/smp_affinity
如果觉得麻烦,可以直接使用华为驱动包中提供的脚本。
当然做了这个操作之后缓解了一下症状。之前都是压到一个cpu核上造成100% soft,现在感觉还是压在一个核上,那么这个又是什么问题呢?在网上搜到了一篇美团点评的帖子,是这么理解这个问题的。
当给中断设置了多个cpu core后,它也仅能由设置的第一个cpu core来处理,其他的cpu core并不会参与中断处理,原因猜想是当cpu平行收包时,不同的核收取了同一个queue的数据包,但处理速度不一致,导致提交到IP层后的顺序也不一致,这就会产生乱序的问题,由同一个核来处理可以避免了乱序问题。
参考链接:https://tech.meituan.com/2018/03/16/redis-high-concurrency-optimization.html
小B:问题还是没解决啊,看来也是有限制的。
小A:是的,当然也可以优化,根据上面的文档,咱们也可以把Oracle数据库的LMS进程的亲缘性设置到指定的cpu上去,然后把中断设置到另外的cpu上去,互相不冲突就可以解决了。但是我们没这么做,因为LMS进程比较多,主机上出cpu也比较多,设置起来较为麻烦,我们最后是通过参数优化来解决的。
第一个优化方式,是IRQ coalescing,中断合并主要是为了做延迟跟cpu开销之间的权衡。当网卡适配器收到一个帧之后,不会立即的对系统产生中断,而是等一段时间,收集到更多的包之后再一次性的处理,这会降低cpu的负载,但是会产生等待时间。
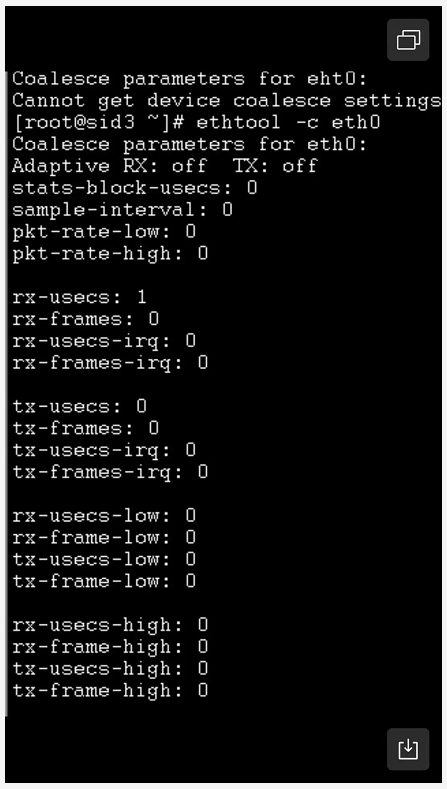
自适应模式使网卡能够自动调节中断聚合,在我们的机器上可以看到是没开启的。在自适应模式下,驱动程序将检查流量模式和内核接收模式,并在运行中估算合并设置,以防止数据包丢失。这里我们可以建议启动自适应模式。
# ethtool -C ethx adaptive-rx on
第二个优化的手段是,UDP根据源IP和目的IP,按照哈希结果将数据流分发到网卡的不同接收队列中。
# ethtool --config-ntuple ethx rx-flow-hash udp4 sdfn
在做了上面两个操作后,软中断的cpu使用率下降到了30%-60%之间,起到了明显的改善,处理中断的cpu只要不是100%,网络延迟丢包也就不存在了。后续观察网络的延迟都是在0.01ms以下,数据库的GC等待事件也随之消失了。
小B:嗯,这个问题真是麻烦啊,还好你们一直坚持排查。
小A:那当然,DBA得追求卓越,把问题都搞清楚然后再解决。虽然这个问题是一只很厉害的“妖怪”,一度让我们很困扰,但是打败了这只“妖怪”之后,我们像经历了一次脱胎换骨,对网络问题又加深了理解,还是收获很大的。
小B:嗯,感谢分享,确实收获颇多,以后我也要像你一样在技术上追求卓越!








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721