
我们团队内部有一个问题升级机制,即任何故障(业务反馈问题、hang、或者crash等)必须立即升级给直接主管,并在10分钟之内第二次反馈情况。这要求一线团队对基本问题的侦查方法十分了解,并且熟悉环境。当然,绝大部分的客户环境都部署了OSWatcher之类的工具(这些工具我在之前发表的文章《Oracle DBA应该掌握的9个免费工具》中谈到过,详见文末的往期作品链接),所以效率会非常高。但有些客户环境由于条件限制部署不了这些工具。这种情况下,我们怎样才能在10分钟内及时反馈数据库情况呢?
对于一个大团队来说,及时反馈问题,比傻乎乎的去分析更重要。
节假日期间,如果你碰巧分到值班的活,那就更应该读一读这篇文章。
你正一边忙着搞MySQL数据库,一边滑动手机抢节日红包。背后的师父喊了,猴儿,你看看200.123怎么了?
你赶紧把MySQL数据库上正在敲的命令撤回,关闭窗口。(不要小看这个动作,随时关闭不用的窗口,是减少人为失误的法宝之一。)
通过堡垒机你登录到123。
第一步 先看看系统资源使用情况
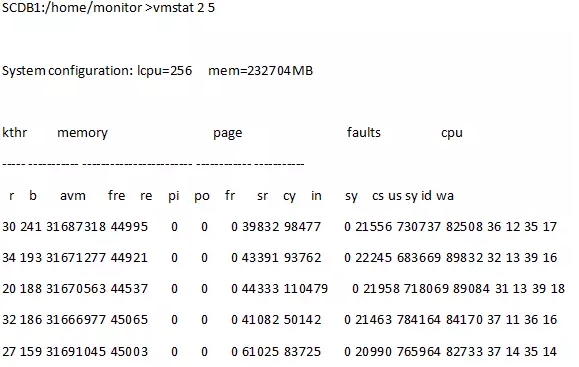
没有换页,运行队列没问题,等待队列平时只有60左右,今天接近200。
CPU空闲率降低了10个百分点,IOwait增加了三五个点。
第二步 检查日志有没有错误
单机系统,先检查alert日志,如果里面有错误,再看相应的trace日志。
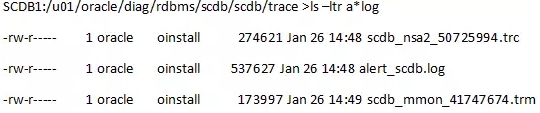
确认日志里是否有报错。
如下的日志文件中,我们可以看到,没有报错。同时我们还能看到,存在联机日志写的时候,cannot allocate新日志的情况,如果经常发生,考虑增加日志组,或者加大日志文件大小。

第三步 查等待事件
其实也可以把查等待放在第二步来做。

看到这么多等待事件,千万别慌。除了排除所谓的“空闲类等待事件”之外,还要注意,有的等待事件并不是很值得关注。
就这里显示的内容来说,我们能看到:
有一个锁等待,属于正常范围。
4个scattered read
100多个sequential read,稍微有点多。
800多个read by other session,多的有点离谱了。
这种情况发生了,就要抓大放小,重点关注800多个这个事件相关的SQL语句、应用程序或终端。

并没有特殊的终端连接特别异常。

我们看到所有这些连接也并非都是同一个SQL_ID执行的。
不过别急,进一步把一个个SQL ID解析成SQL语句后,我们发现,这800多个等待“read by other session”的会话,其实是2个语句:

和

它们的共同点是都对其中一个表进行查询。
通过执行awrsqrpt.sql语句来进一步分析单个sql_id,我们发现,执行频率很高:

相对于近亿条记录的表关联查询来说,每次执行所消耗的IO,是正常的。
表和索引的统计信息都是一天前刚搜集的。实际记录数与统计信息搜集的相比,差异在1%以内,SQL的执行计划没有发生变化。
因此,猴儿反馈给师父,数据库本身没有问题。
某业务执行频率异常导致业务慢(从sqlrpt的信息来看,执行一个查询要耗时3分多钟),CPU利用率比平时高10个点左右。
执行频率有多高呢,1小时执行了上百万次。这个业务正常一小时执行上万次就了不起了。
整个CASE,从师父发出指令,到猴儿反馈信息给师父,正常应该在5分钟以内。
作为一线的工程师来说,最重要的并非是立即解决问题,而是迅速反馈,让更合适的人介入处理,避免问题蔓延。
然后呢?
然后,如若是应用问题,你应该持续跟进应用改进,直到这个问题最终判定为止,形成知识库文档。
如若是数据库本身有问题,问题流转到了更专业的人手上,但作为问题第一负责人,仍然要跟着学习借鉴别人的问题思路,直到问题解决,形成文档,最后这个问题是一个闭环。
1、 read by other session等待事件
这个等待事件是从buffer busy wait这个等待事件剥离出来的。
什么情况会发生这个等待事件呢?
(1)某个会话正在查询某个表的数据,把这些数据从磁盘里读到高速缓存区中,而其他会话这时如果也在请求相同的数据块。如果响应的数据块还没完全读到缓存中,就会发生这样这个等待事件。
(2)因为有会话正在读取数据在内存,因此该事件同时会伴随着sequential read或者是scattered read,一般情况不会孤立存在。
通常怎么做?
(1)由应用侧停止发起异常连接数的业务可能是最好的方式,但不一定能做到。
(2)在应用侧的授权下,kill掉相应会话是可选的方式。
2、 单机数据库,如果这些查完都没有问题怎么办?
上述检查中,关于主机方面,主要看了CPU、内存使用情况。因此,还可以检查磁盘IO信息(iostat,sar –d等),还可以看看网络怎么样(top/topas,netstat等)。以及操作系统方面的日志信息。
3、如果是Oracle RAC数据库呢?
检查多个实例的情况
同时应该看看CRS的日志
检查ASM的情况,ASM默认的参数偏小
4、这个case中,有没有可能是SQL本身的问题?
如果不是因为有SQL基线,确定SQL执行计划没变,正常应该确定SQL是否有优化余地。
做一线运维,尽可能去做好所负责的数据库基线管理,并定期更新。这非常有助于快速分析和定位问题。
作者介绍:杨志洪
【DBA+社群】联合发起人
数据管理专家。Oracle ACE、OCM、 SHOUG/ZJOUG核心成员、DAMA会员/CCF会员,译著《Oracle核心技术》。
在Oracle OOW、DTCC及2015Oracle数据库技术大会等全国性技术会议上发表主题分享,并主办了2014Oracle全国技术巡讲。
2015年创立DBA+社群迅速成为全中国最大的涵盖数据架构师、DBA及中间件的专业社群。
往期作品:
小编精心为大家挑选了近日最受欢迎的几篇热文↓↓↓
(关注订阅号dbaplus,回复以下数字,即可获取相应文章)
回复011,看邹德裕《数据库运维工具化:一切从“简”,只为DBA更轻松》。
回复012,看马育义《Oracle内核系列3-揭秘ASM磁盘头信息》。
回复013,看吕海波《去不去O,谁说了算?》;
回复014,看杨德胜《Oracle故障日志采集“神助攻”—TFA工具详解》;
回复015,看郭耀龙《假事务之名,深入研究UNDO与REDO》;
回复016,看陈能技《基于Docker的开发模式驱动持续集成落地实施》;
回复017,看朱贤文《数据库与存储系统》;
回复018,看卢钧轶《揭秘Facebook数据库备份策略》;
回复019,看杨建荣《看似简单的dual,其实深藏玄机》;
回复020,看黎君原《扒一扒Oracle数据库迁移中的各种坑》。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721