
其中运行root.sh脚本是最关键的阶段。接触过很多 SR 都是在这个阶段出现错误导致安装失败。如果问题修复后,需要先deconfigure 已有的配置,然后再运行root.sh。从11.2.0.2版本开始支持重复运行root.sh脚本,也就是说修复问题后,可以直接再运行root.sh,并且从上次失败的地方继续安装(类似”断点续传”)。这个特性在12c中又得到增强。实现这个功能主要是通过将安装阶段信息记录到checkpoint文件和OCR文件来实现:
11.2 checkpoint文件位置:
$ORACLE_BASE/Clusterware/ckptGridHA_${nodename}.xml
12c checkpoint文件位置:
$ORACLE_BASE/crsdata/$hostname/crsconfig/ckptGridHA_${nodename}.xml
下面分享一个安装12.1.0.2 集群GRID/GI, 运行root.sh 脚本失败的案例。
案例分享
在Linux系统上安装12.1.0.2 集群GRID/GI软件,节点2运行root.sh失败,屏幕的错误信息:

以上错误说明节点2无法确认节点1安装状态是否完成。Root.sh是如果来确认节点1安装是否完成呢?需要检查日志:

以上信息说明节点2首先执行cluutil -exec -keyexists -key checkpoints.firstnode命令来查看OCR中的key: SYSTEM.rootcrs.checkpoints.firstnode,失败后又尝试执行OCRDUMP命令,但是OCRDUMP命令也失败。接下来分析OCRDUMP命令也失败的原因:
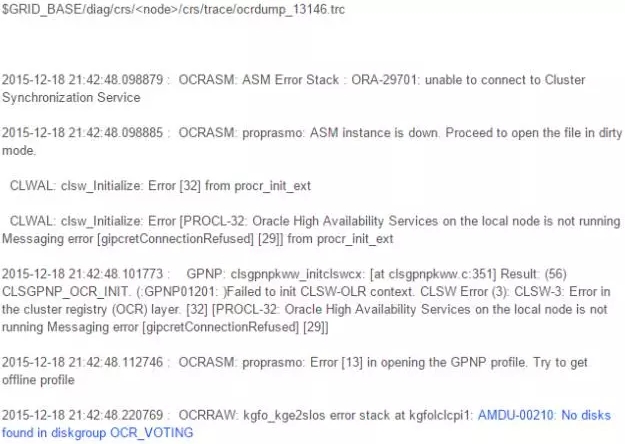
以上信息提示无法连接ORA-29701 CSS和PROCL-32 OHASD这些都是正常的,因为节点2集群没有启动,这些错误可能会干扰我们分析问题。关键的错误信息是AMDU-00210: No disks found in diskgroup OCR_VOTING,也就是说节点2没有找到ASM disk导致OCRDUMP失败,因此无法确认节点1安装的状态是否完成。接下来我们执行kfed确认ASM disk是否有问题:


在节点1查看/dev/raw/raw1显示disk 类型是KFBTYP_INVALID,并且kfdhdb.vfstart有值,说明raw1在节点1是正常的asm disk,并且是vote disk。但是节点2查看相同的disk,显示完全不同的信息。正常情况下,配置的共享设备raw1在节点1和节点2看到的信息应该是一致的,但是这个case中节点1和节点2看到的是不同的信息,说明共享disk配置是不正确的。
同时,在节点1手动执行OCRDUMP确认key SYSTEM.rootcrs.checkpoints.firstnode是存在的,并且状态是” SUCCESS”。

最后,修改UDEV配置文件(/etc/udev/rules.d/99-oracle-asmdevices.rules)后问题解决。
本文转载自Oracle Blogs
博客地址(https://blogs.oracle.com/Database4CN/entry/12c%E6%96%B0%E7%89%B9%E6%80%A7_root_sh%E8%84%9A%E6%9C%AC%E6%94%AF%E6%8C%81checkpoints%E6%96%87%E4%BB%B6%E5%AE%9E%E7%8E%B0%E9%87%8D%E5%A4%8D%E8%BF%90%E8%A1%8C)
小编精心为大家挑选了近日最受欢迎的几篇热文↓↓↓
(关注订阅号dbaplus,回复以下数字,即可获取相应文章)
回复011,看邹德裕《数据库运维工具化:一切从“简”,只为DBA更轻松》。
回复012,看马育义《Oracle内核系列3-揭秘ASM磁盘头信息》。
回复013,看吕海波《去不去O,谁说了算?》;
回复014,看杨德胜《Oracle故障日志采集“神助攻”—TFA工具详解》;
回复015,看郭耀龙《假事务之名,深入研究UNDO与REDO》;
回复016,看陈能技《基于Docker的开发模式驱动持续集成落地实施》;
回复017,看朱贤文《数据库与存储系统》;
回复018,看卢钧轶《揭秘Facebook数据库备份策略》;
回复019,看杨建荣《看似简单的dual,其实深藏玄机》;
回复020,看黎君原《扒一扒Oracle数据库迁移中的各种坑》。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721