

当然销售情况表只是一个典型的情况,在实际应用中,有各种各样的缺失数据情况。如果决策者看销售情况统计表,他可不希望有的产品按时间序列断断续续,而应该给他提供时间序列连续的分析报表,他可能需要看到每个产品每个时间的销售情况,就算在某个时间没有销售,也必须置0,这样的报表对决策者才有意义,而且可以进行更细粒度的分析,比如使用分析函数对每个产品按年月汇总计算销售偏移量,这样可以方便对比每个产品每个月的销售情况,从而为决策支持提供强大保障。
为了实现将稀疏数据转为稠密数据,Oracle10g提供了Partitioned Outer Join语法,和一般的OUTER JOIN类似(但是不支持Full Outer Join,只支持Left和Right两种),只不过增加了PARTITION BY的语法,根据PARTITION BY将表逻辑分区,然后对每个分区进行OUTER JOIN,这样就可以达到填补缺失行,实现数据稠密化的目的,也相当于对每个分区里的数据OUTER JOIN后进行UNION操作,理解这个很重要,否则经常不知道到底是哪个表哪些列该分区,不知道到底是用LEFT JOIN还是用RIGHT JOIN,在后面的例子会详细分析这个语法如何使用。
目录
Partitioned Outer Join实例
Partitioned Outer Join总结
Partitioned Outer Join语法如下:

Partitioned Outer Join语法很简单,也就是在JOIN的表后面ON条件之前加入PARTITION BY语句即可。上面只列出了最简单的两表(内联视图,视图等其他结果集)连接,多个对象的连接类似,其他复杂的语法结构省略了,语法结构上PARTITION BY是可以放在任何合法连接对象后面的,而且和一般的PARTITION BY没有区别,可以有多个分区列(表达式),然后用外连接,注意一定要搞清楚是用LEFT JOIN还是用RIGHT JOIN,比如第1个语法结构在JOIN之前的对象使用了PARTITION BY,那么就是对第1个对象填充缺失数据,所以必须用RIGHT JOIN,第2个语法结构类似。
当然也可以直接用JOIN,不用OUTER JOIN,但是这样无法填充缺失数据,没有意义,另外注意不能使用86的外连接语法+,这是不行的,必须使用92语法。一般来说,根据需求确定PARTITION BY的键值,PARTITION BY语句要紧跟需要分区的对象后面,然后根据PARTITION BY的位置决定用LEFT JOIN还是RIGHT JOIN,否则可能会出错或获得不正确的结果,如果要起到分区外连接的效果,必须牢牢按照上面两种写法来(PARTITION端要紧跟对应表,并且是非基表),后面会详细分析其他写法的问题。
本节主要从相关实例中研究Partitioned Outer Join的使用,主要实例有填充一维缺失数据、填充多维缺失数据、填充数据到清单表中等。例子中的建表等语句请参考代码poj.sql。
poj.sql
1) 填充一维缺失数据
t表是一个产品销售情况表,数据如下:
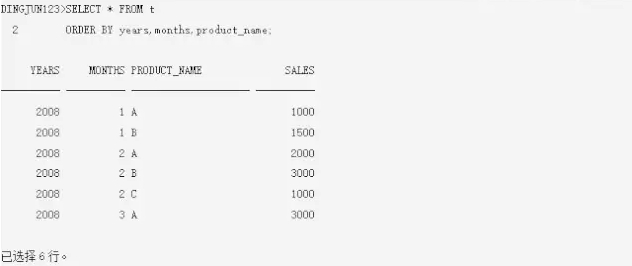
上面的表数据是很简单的,在实际应用中,这个数据可能是语句的中间结果。从结果上可以看到,有2008年1、2、3这3个月的销售数据,但是有些产品的销售数据在某些月份是缺失的,比如2008年1月产品C就没有数据。现在需要一个报表,能够填充所有产品对应2008年前3月缺失的数据,销售字段sales置0,要实现这样的报表,如何做呢?
先来看下传统做法:既然填充每个产品对应月份缺失的数据,那么肯定需要构造一个结果集存储了每个产品每个时间对应的数据,这样再与原始表外连接,则可以达到填充缺失数据的目的,为了实现这个目的,很容易想到需要将表中对应的时间year、month与产品做笛卡尔积(每个部分数据都是唯一的,是这样的数据做笛卡尔积),生成每个产品每个时间的结果数据,然后与原始表外连接。下面用SQL实现:

传统填充缺失数据,往往就要通过笛卡尔积构造完整数据集,然后与原始表外连接。根据上面的SQL,这个结果应该是生成所有产品所有年月的销售数据,如果原始表中没有,则对应缺失年月的数据为0,执行上面的SQL结果为:
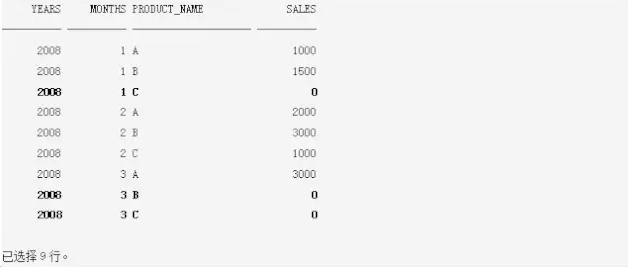
现在填充了3行缺失数据,实现了所有产品对应2008年前3月时间序列上的稠密化报表目的,你是否发现到传统做法比较复杂,这里是很简单的一维缺失数据的填充,如果是多维缺失数据填充呢?在实际应用中SQL经常很复杂,这个销售表t也许都是SQL的中间结果,那么这样的做法需要通过笛卡尔积生成所有组合情况,性能可能不好,而且SQL比较复杂。
下面看10g对填充数据专门做的改进,使用PARTITIONED OUTER JOIN实现数据稠密化工作,更加简单,而且往往性能往往要比传统做法要好。通过前面对PARTITUONED OUTER JOIN的分析以及传统实现数据稠密化的方法,使用PARTITIONED OUTER JOIN只需要对产品进行分区然后和所有时间外连接,则可以补全缺失数据,如下:

一定要理解PARTITIONED OUTER JOIN的两种语法结构,这里的PARTITION BY是紧跟在表t后面的,相当于对每个按product_name分区的每个分区内的行和中间结果m外连接,这样就能补起数据了,相当于每个按product_name划分的行与m外连接的UNION ALL结果,通过这个例子,就可以很好地理解PARTITIONED OUTER JOIN的使用,这样你就能正确用多种方法进行改写了。这个语句的结果和上面的一致,不再列出。如果你理解了上面说的话,就可以使用LEFT JOIN来改写:

执行结果和上面的RIGHT JOIN完全一样的,为什么上面又变成LEFT JOIN了呢?原因是现在t PARTITION BY移到JOIN后面了,当然要左连接所有的时间才可以填充缺失数据,所以要使用第2种语法结构。下面看下此语句的执行计划:

PARTITIONED OUTER JOIN的效果体现在第3到第8步,其中第8步就是将数据排序然后放入分区内,第3步就是外连接产生填充后的结果集,当然这里的MERGE JOIN可以为NESTED LOOP JOIN,也可以使用hint,比如use_nl(m,t)来让它走NESTED LOOP PARTITION OUTER。这个执行计划会与后面改写的语句执行计划做对比,如果没有第3步和第8步,那么PARTITIONED OUTER JOIN是不起作用的。使用PARTITIONED OUTER JOIN的过程如图所示:

上面语句的实现的功能就是3个外连接的UNION ALL结果,其他复杂的数据稠密化以此类推。其实10g的MODEL也可以实现数据填充,但是MODEL语句比较复杂,比如上面可以用MODEL简单改写为:

如果是多维或其它复杂情况的改写,会很麻烦,对于数据稠化建议使用使用10g的PARTITIONED OUTER JOIN。
如果你的分区外连接写法不遵守两种语法结构,那么可能写的语句不报错,但是结果却不是正确的(起不到分区效果,计划里没有PARTITION OUTER),当然也有可能出错,比如上面的RIGHT JOIN改写为:

上面语句不会报错,但是结果:

第一条语句是将本来应该放在表t后面的PARTITION BY移到了m后面,没有实现填充缺失行的目的,原因是ORACLE对这种语法结构不会按照PARTITIONED OUTER JOIN实现填充行的目的进行支持。第二条语句是对基表进行PARTITION BY 操作,应该是对非基表,改为RIGHT JOIN才对。看下执行计划就明白了,计划如下:
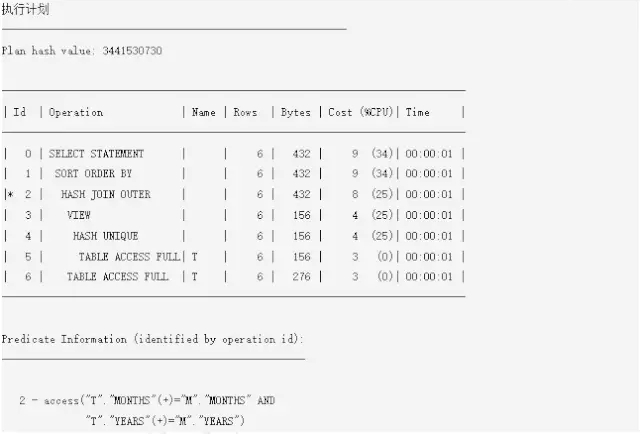
上面这个语句的计划和去掉PARTITION BY的语句计划完全一致,没有原来的第3步和第8步的PARTITION操作。为什么我这么强调PARTITION OUTER JOIN的语法结构呢?因为如果不理解这个语法结构,必然会导致不正确的结果,如果理解了这个语法结构,那么一切就变得很简单,其他改写的错误类似,还有一种错误是直接报错,如下:

为什么会出错,因为这里是LEFT JOIN,那么基表是t,在m后面使用PARTITION BY并且引用了t的字段,那么是引用不到的,所以出错,如果是RIGHT JOIN,则正确,但是又不符合语法结构,导致PARTITION BY白写。只有前面说的两种正确写法才是对的,特别在多表连接以及多维度填充缺失行的时候一定要注意PARTITION BY的位置和其引用的字段有关,一定要放在紧跟要引用的对象后面,然后根据语法结构规则使用LEFT JOIN还是RIGHT JOIN,否则要么不正确,要么错误。
这种语法很奇怪,LEFT JOIN不可以将PARTITION BY放在非基表端,并且PARTITION BY里引用基表列(上面情况),但是可以把PARTITION BY放在基表端,引用非基表列。但是也起不到填充效果,RIFHT JOIN相反。

OK,现在已经实现了数据稠密化工作,那么稠密化工作的意义何在呢?比如要做按时间序列表示销售情况波动图,要求每个产品每个时间序列上都有数据,不产生gap值,是很有意义的,也可以进一步对数据进行明细分析,比如使用分析函数分析对比当月和上月的销售情况,决策人员看到所有产品所有时间点的数据,这样可以很好地做决策,如果你给他缺失行的分析报表,他怎么能看到某个时间点某个产品没有销售呢,如何分析造成此情况的原因呢?下面就做一个使用分析函数对比销售情况的报表:

结果如下:
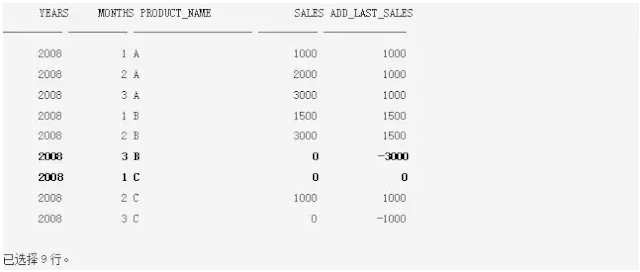
现在这个报表是不是很有意义了呢!决策者可以专门对add_last_sales<=0的数据做分析,找出原因,从而改进销售。
2) 填充多维缺失数据
在例1中已经详细说了使用PARTITIONED OUTER JOIN解决一维缺失数据填充问题,重点讲解了如何理解PARTITIONED OUTER JOIN的语法结构以及注意一些错误问题,其实,理解了例1的内容,多维缺失数据填充思想完全一致,下面就在例1的基础上对销售表t增加一个字段regions,然后填充多维缺失数据。
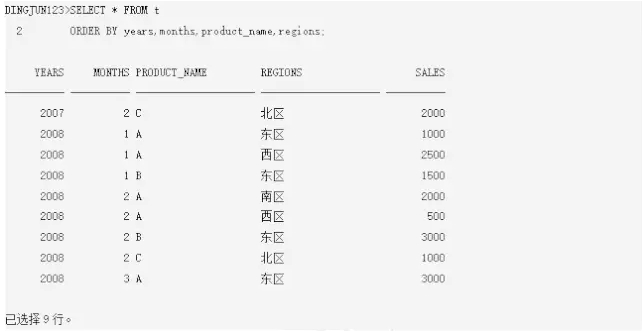
现在按年、产品、区域汇总销售额,结果如下:
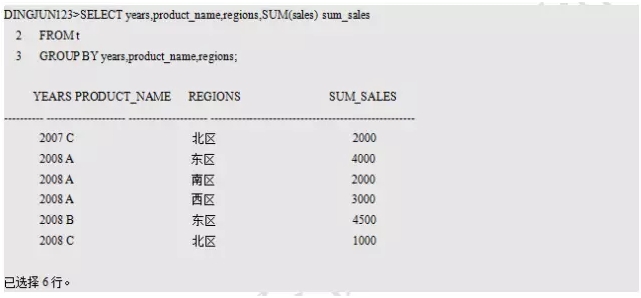
这个报表不是我想看的最终报表,我需要的报表是稠密报表,也就是对于每个产品,横跨所有年、所有区域都应该有汇总数据,但是现在缺失了很多数据,比如对于产品A来说,少了07年4个区域的汇总数据,08年少了北区的汇总数据,最终的报表数据应该有年数目(2)*产品数(3)*区域数(4)=24行记录。
现在需要填补每个产品所有年份和所有区域2维缺失数据,那么怎么做呢?首先需要补全每个产品所有年或者每个产品所有区域的数据,然后按产品和年分区或产品和区域分区再与所有区域或所有年外连接,这样就能填充缺失数据了,所有对2维缺失数据填充可以用2步PARTITIONED OUTER JOIN,当然也可以将年份和区域做笛卡尔积,然后转为1维数据填充,这样的好处很明显,因为年份和区域很少,这样可以减少表的扫描,强烈推荐此方法,见方法4,其他维度的类似。



第3个方法效率要比前2个好点,第4个方法明显最好,因为年份和区域的数据很少,笛卡尔积的数据量也不大,但是如果用两次Partition Outer Join明显扫描的数据增多。这里的测试表也没有建立索引,具体调整和优化过程可以根据实际情况选择,上面4个SQL的结果一致,如下:
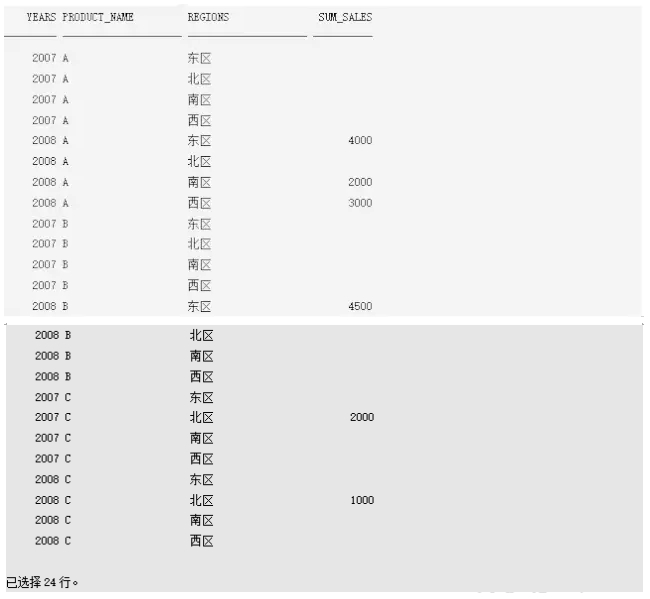
现在对所有产品实现了时间(年)和区域这两个维度的汇总数据填充,总共有24行,符合预期分析的结果。读者应该掌握上面说的从一维到多维数据稠密化的方法,当然,多维数据稠密化也可以用传统方法解决,这里不再叙述。
3) 使用LAST_VALUE填充缺失数据
还有一种填充缺失数据的常用方法是使用LAST_VALUE+IGNORE NULLS(注意使用FIRST_VALUE含义就不一样了,找的就不是最近行了),对指定维度的数据有缺失,则使用最近时间的数据填充,这在报表中是很常见的,这样的报表可以有很好的分析和对比功能。比如:
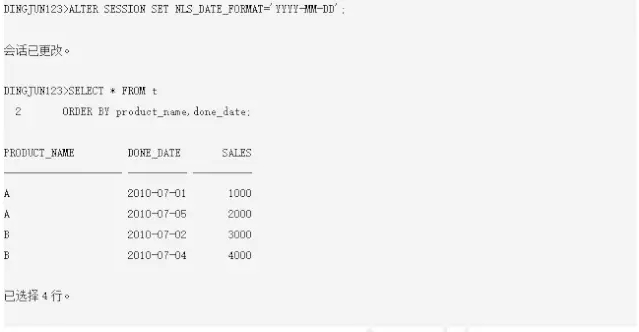
现在需求是:首先对每个产品的所有时间(精确到天)销售实现数据填充,其次如果当天没有销售,则用此产品最近时间的销售数据填充或者增加一行显示当天没有销售的产品的最近时间销售数据。对于实现维度数据的填充,前面已经说了使用PARTITIONED OUTER JOIN,实现产品没有销售则找最近时间此产品的销售,想到了可以使用分析函数LAST_VALUE+IGNORE NULLS实现,11g的LAG也可以加IGNORE NULLS实现(同样不能用LEAD)。SQL如下:

显示结果如下:
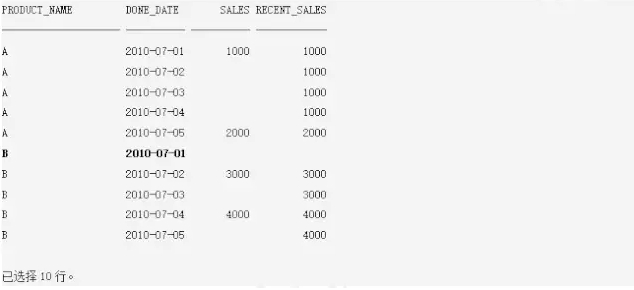
现在实现了上述需求,还有一行recent_sales为空,因为它是产品B的第1个时间点的数据。使用LAST_VALUE+IGNORE NULLS结合PARTITIONED OUTER JOIN实现上述报表是很常见的,实现报表数据稠密化思想主要就是上面这些,当然MODEL语句也可以实现,但是没有PARTITIONED OUTER JOIN简单。
传统方法填补缺失数据,经常需要使用笛卡尔积构造中间结果,然后与原始数据外连接,往往性能不是很好,而且SQL比较复杂,10g提供的PARTITIONED OUTER JOIN的语法简单,可以高效地实现报表数据稠化,使用PARTITIONED OUTER JOIN一定要掌握语法结构中的2种结构:首先确定分区键,然后确定使用LEFT JOIN还是RIGHT JOIN,此语法结构对FULL JOIN不支持。另外MODEL等语法也可以实现类似的功能,但是与PARTITIONED OUTER JOIN相比,就复杂多了,为了很好地使用PARTITIONED OUTER JOIN实现数据稠化,一定要分析清楚需求,然后根据本部分说的使用步骤以及一些注意点,比如如何高效地使用DISTINCT构造结果集(常自己构造或从关联表获取),这样才能正确高效地实现报表数据的稠化。
作者介绍:丁俊
【DBA+社群】联合发起人,新炬网络专家团成员。
性能优化专家,Oracle ACEA,ITPUB开发版资深版主、ITPUB 2010-2013连续4届最佳精华获得者、2011-2014连续4届最佳版主。
十年电信行业从业经验,从事过系统开发与维护、业务架构和数据分析、系统优化等工作。
电子工业出版社终身荣誉作者,《剑破冰山-Oracle开发艺术》副主编。
小编精心为大家挑选了近日最受欢迎的几篇热文:
(关注订阅号dbaplus,回复以下数字,即可获取相应文章)
回复011,看邹德裕《数据库运维工具化:一切从“简”,只为DBA更轻松》。
回复012,看马育义《Oracle内核系列3-揭秘ASM磁盘头信息》。
回复013,看吕海波《去不去O,谁说了算?》;
回复014,看杨德胜《Oracle故障日志采集“神助攻”—TFA工具详解》;
回复015,看郭耀龙《假事务之名,深入研究UNDO与REDO》;
回复016,看陈能技《基于Docker的开发模式驱动持续集成落地实施》;
回复017,看朱贤文《数据库与存储系统》;
回复018,看卢钧轶《揭秘Facebook数据库备份策略》;
回复019,看杨建荣《看似简单的dual,其实深藏玄机》;
回复020,看黎君原《扒一扒Oracle数据库迁移中的各种坑》。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721