
杨建荣,Oracle ACE-A,YEP成员,现就职于搜狐畅游,拥有6年以上的数据库开发和运维经验,曾任amdocs DBA,负责亚太电信运营商的数据业务支持。擅长电信数据业务,数据库迁移和性能调优。
拥有Oracle 10g OCP,OCM, MySQL OCP认证,对shell,java有一定的功底,曾在2015年数据库大会进行关于数据迁移和升级的主题分享,现在每天仍在孜孜不倦的进行技术分享,每天通过微信,技术博客共享,已连续坚持550多天。
本次演讲主要分享了DB time 抖动的诊断案例,主要分为四个部分:1、问题背景;2、DB time监控中发现的抖动;3、问题分析;4、问题总结。
因为使用的数据库环境多且复杂,数据库不只有Oracle,所以通过gc来统一管理所有的数据库平台定制成本较高,使用zabbix可以满足系统级监控和MySQL等的监控报警,对于Oracle的监控通过扩展的Orabbix来实现。
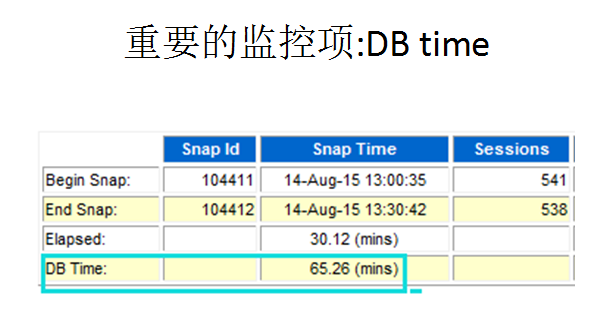
而DB time这个监控项还是比较经典的一个指标,基本是作为DBA查看awr的首选指标。这个指标如此重要,但是似乎Oracle没有提供一个很有效的监控方式。如果逐一从awr报告中抓取就有些麻烦了。下面是一个awr报告中DB time 的例子。
而什么是DB time,我引用了Oracle John Beresniewicz的解释。

简单来说,DB TIME= 所有前台session花费在database调用上的总和时间。
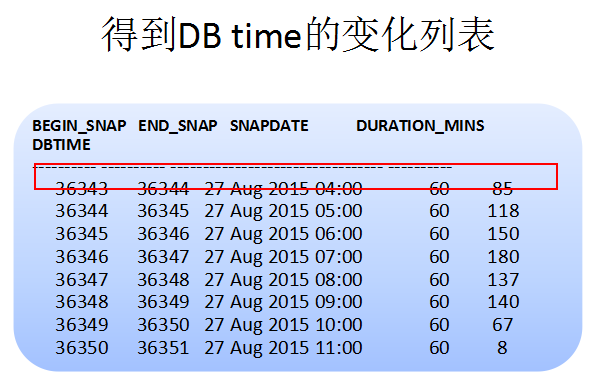
明确了DB time,首先我们进行了第一层定制,这是在定制后得到的DB time情况,得到的是快照点的对应的DB time,比如快照36343~36344,持续60分钟,DB time为85分钟,以此类推。得到这样的DB time列表,还是可以发现很多潜在的问题,可以充分结合awr来进行诊断,但是不足之处还是后知后觉。
这个时候进行了第二层定制,结合v$sys_time_model来和快照中对应的DB time进行关联,得到一个相对接近的DB time值。比如快照在下午1点的DB time为100(转换为秒),我在1点5分的时候通过v$sys_time_model得到一个DB time值160,然后和1点整的DB time值相减,得到的负载情况就是(160-100)/(5*60)=20%
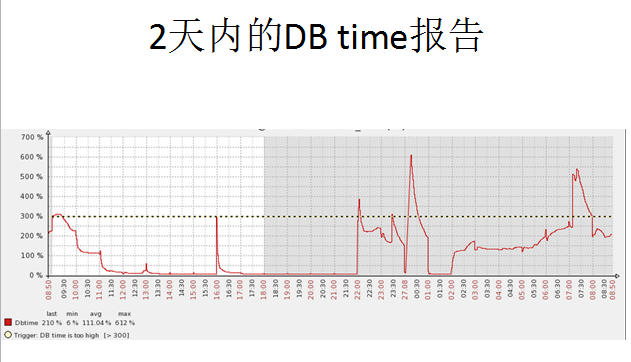
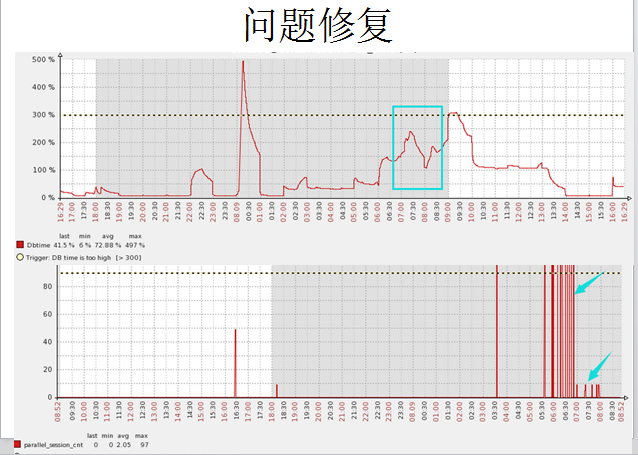
这是一个两天之内的DB time汇总图,可以看到DB time的一些抖动情况。
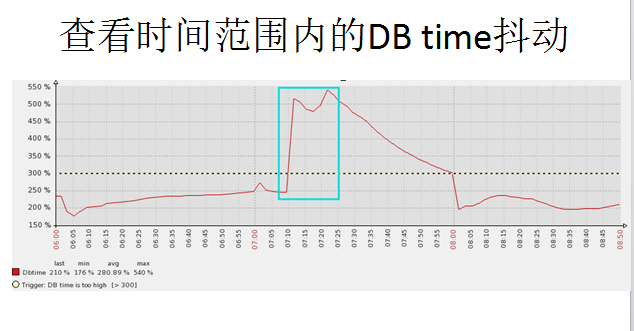
这个图可以看到DB time在短时间内发生了抖动,可以抓取到比较精确的时间点。
接下来的图中我们选用蓝色框中的时间段来具体分析问题,而下面的图是监控数据库中的并行进程的情况,可以看到问题时间段内,并行进程高达100多个。
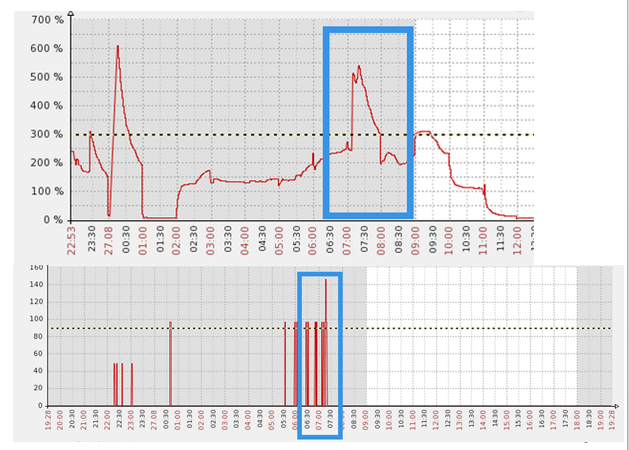
同时,也收到了报警的短信,提示在问题时间点,确实有150多个active session.

通过这些信息和图表,我们可以得到这样的猜想,可能是在特定的时间段内触发了特定的scheduler导致了这个问题。
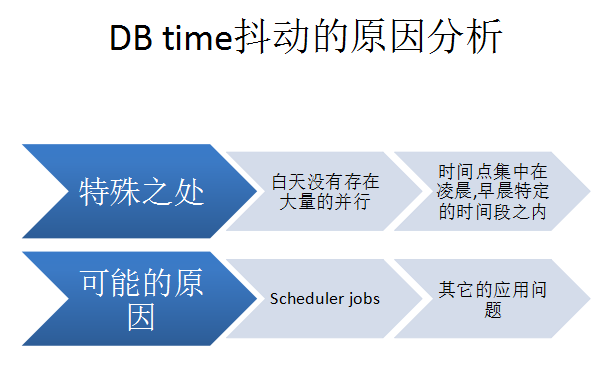
对于这个问题的分析,我是分为4个步骤来一一排查的。

首先查看数据库日志,日志中没有发现任何的异常信息。

接着抓取ASH报告,在服务端使用tns连接到数据库实例,生成的ash报告中的top等待事件如下。而对于标红的等待事件查看metalink说问题可以忽略,奇怪的是ash报告中也得不到任何相关的sql.这里有个潜在的操作问题,先卖个关子。
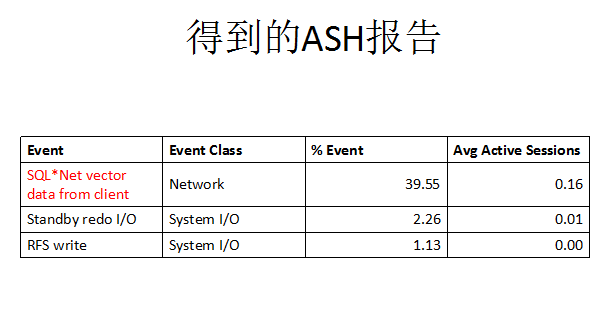
既然数据库日志,ash中都得不到有效的信息,那么我们的猜想就自然落到了scheduler上,结果一查看,还确实有几个scheduler在问题时间段内执行。
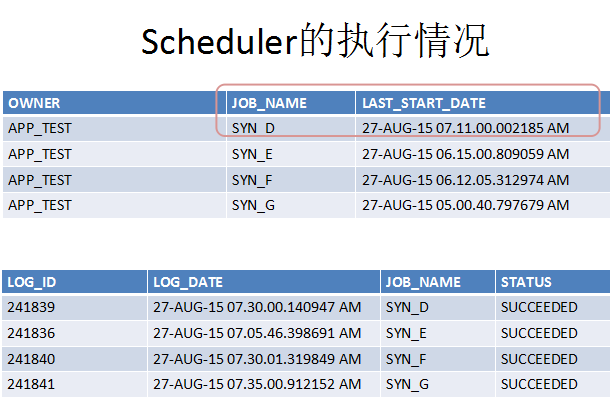
这时候感觉问题已经定位了,我们抓取离问题时间段最近的一个scheduler,可以看到其实这个scheduler就是在做一个物化视图刷新,那么问题很可能在于物化视图刷新上了。
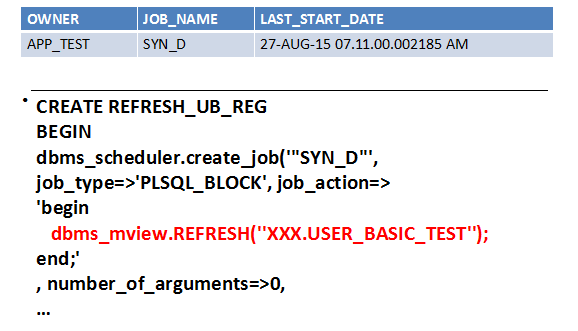
进一步验证,发现这个物化视图的源表在另外一个数据库中,通过db link连接访问。而源表的数据有2亿多条。这个时候猜测感觉应该是物化视图走了全量刷新导致了性能的抖动。
但是在源库中尝试添加物化视图日志却报出了错误,ORA-12000: a materialized view log already exists on table 'USER_BASIC_TEST‘
使用快速刷新和默认的刷新选项,速度都很快。这个时候基本可以排除物化视图刷新的影响了,感觉问题的排查到了山穷水尽的阶段。
既然短时间内存在大量的并行,但是通过日志,ash报告,scheculer中的物化视图刷新都没有找到更多的信息,我开始尝试自己定制监控策略。于是我写了上面的脚本。来定时从数据库中抓取这些并行的信息。

写了这个脚本之后,在后台去跑,每5秒钟检查一次,执行10个小时,这样在第二天上班的时候就能够得到详细的报告了。
第二天查看的时候,果然发现还是有收获的,得到了并行进程的执行情况,列举出了一小部分,而且最重要的是我们定位到了对应的sql_id
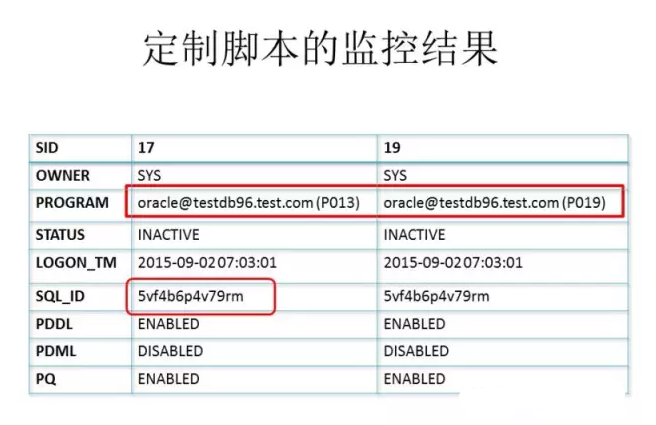
我们来看看这个语句,这个sql结构比较简单,表中的数据量也很大,但是执行计划却走了全表扫描,按照where查询条件是应该走索引的。查看索引发现确实是存在的,为什么存在索引,查询也满足索引触发的条件,但是查询却走了全表扫描呢?

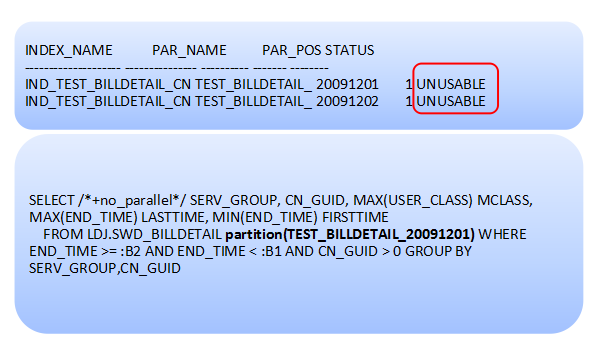
查看分析发现,有部分的分区索引竟然是unusable状态,明白了这一点,解决起来就非常简单了,我们可以rebuile索引分区修复。我们先排除并行的影响,使用Hint no_parallel来看看rebuild分区索引前后的执行计划的情况。
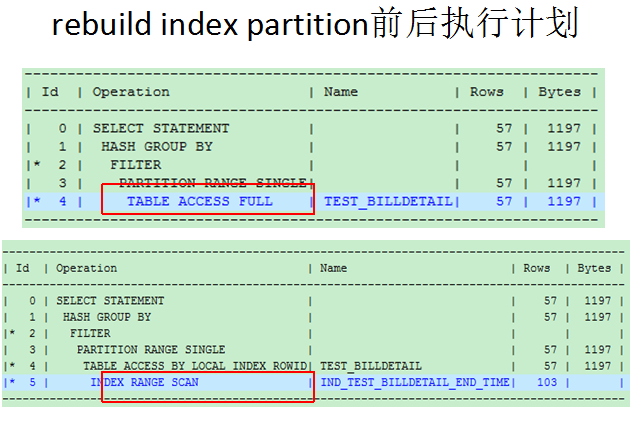
上下图是在rebuild index partition前后的语句执行计划的情况,可以看到rebuild之后,马上走了索引扫描,
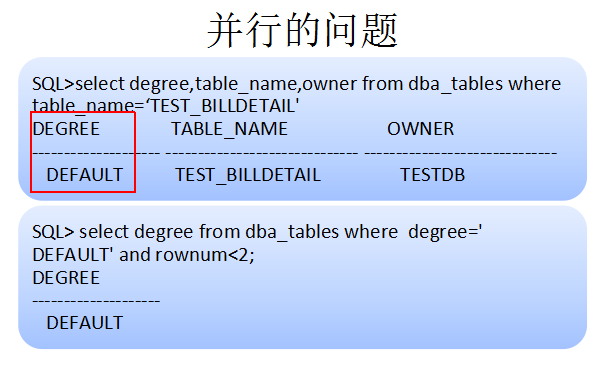
索引失效导致了全表扫描,而对于并行的问题怎么解释呢。进一步分析,发现这个表的并行度是DEFAULT(注意第2个查询语句中DEFAULT前的几个空格)。如果并行度为DEFAULT就会依赖于CPU资源,所以可以看到48,96的并行度。而这个default的由来其实是因为我们使用了类似下面的语句。ALTER TABLE TEST_BILLDETAIL PARALLEL 导致了并行的问题。
明白了这点,问题解决就引刃而解了,我们可以限定一个较低的并行度或者设置并行度为默认的1。最后来说一下为什么ash没有抓取到数据,大家可以仔细分析一下这个操作记录,是在服务端同一个窗口中执行的。其实问题就在于主备切换后,使用tns连接到testdb1其实是连接到了备库,所以得到的ash报告才没有抓取到任何的sql语句,这个问题很可能会误导你。
当然这个问题修复之后,可以看到DB time的抖动变得平稳了。而且并行资源的使用也不会爆发式增长,箭头和框图都可以看出,都基本达到了一个相对合理的范围区间。
通过这个例子可以看到一个DBtime的抖动可能对于DBA来说可能意味着性能的抖动,我们根据这些细小的变化发现很多的潜在问题。这种分析问题的方式就可以达到先知先觉,对于异常操作的感知度也会更加灵敏。因为这个分析过程没有用到awr和ash(想用没用上J),所以可以进一步尝试扩展为自动化的分析。
我们在这个问题的排查中自己也好几次准备放弃,首先就是想当然认为应该是有什么Job在运行导致的问题想就不查了,然后ash报告因为操作失误没抓取到合适的数据,接着自定义脚本的时候最开始漏了sql_id,结果格式混乱,结果又多耽误了一天。不过最后的结果还是可以让人接受的。所以希望大家在分析问题的时候也可以坚持一下,多细心一些。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721