

转载声明:本文为DBA+社群原创文章,转载必须连同本订阅号二维码全文转载,并注明作者名字及来源:DBA+社群(dbaplus)。
目录
监听状态正常,应用反馈时断时连
Listener进程crash
ORA-12514 TNS 监听程序当前无法识别连接描述符中请求服务
11G SCAN LISTENER无法注册服务故障
Listener hang
TNS-12535 TNS-00505处理
应用测试连接不上数据库,连接直接报TNS-12547: TNS:lost contact处理
由Oracle的Listener引起的报错很多,很大一部分是由于配置不当导致的。通常,我们要么从tnsnames.ora找原因,要么从lisntener.ora找原因。基本上,我们从Oracle连接的时候报出的错误代码可以快速查到原因。
下面介绍的几类故障及处理方法,难度稍微要大一些
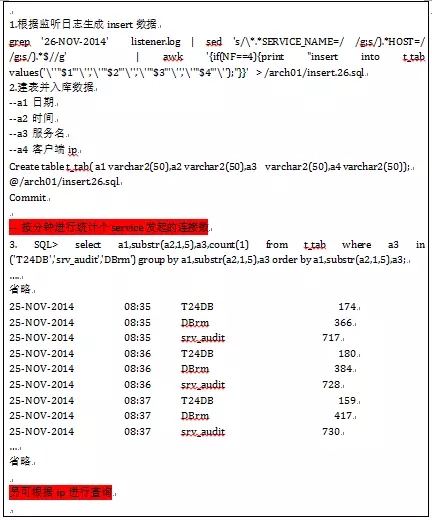
故障现象:
客户端新发起的短连接时断时连,如下所示:

故障原因:
因短连接持续性发起连接耗尽监听ip 1521端口资源,导致监听无法正常处理连接请求。
超过每秒50次连接则需要关注,可通过tail -20f listener.log 观察,如持续性快速刷屏则可能已经出现连接风暴.

故障解决/日志分析:
故障环境:
操作系统为:SunOS 5.10
数据库版本:Oracle 10.2.0.4
故障现象:
Listener进程已经crash, 查看主机数据库监听日志listener_ngsetdb3/4.log如下:

系统日志:

故障分析:
Listener进程crash是由于IPMP出现故障所致,Listener随后在探测不到服务节点时,直接crash。Oracle MOS文章Solaris Cluster 3.x: IPMP group failure impact [ID 1006916.1]对此有详细描述:在Sun Cluster中,短暂的网络故障会导致IPMP组失败,并触发资源组切换。并且,它会在38秒后回切!
处理方法:
查看监听日志listener.log跟系统日志(/var/adm/ messages)。
手动重启两个节点的Listener,Oracle提供了一个解决方案:修改/etc/default/mpathd文件下的IPMP FAILURE_DETECTION_TIME变量值,即将失败检测时间从默认的10秒(10000)增加到20秒(20000)以上

注:修改该参数需要重启mpathd服务。
故障现象:
客户端无法通过监听连接数据库
故障原因:
1.实例未注册到listener中,可通过lsnrctl status 查看
2.oracle process达到上限无法建立新的连接。
故障解决:
手工注册数据库,alter system register;
检查数据库用户连接分布情况,并show process 查看连接限制
Select username,count(1) from v$session group by username order by 2 asc;
Ps :大部分情况由开发商程序bug引起。
故障现象:
scan listener 无法注册service服务
故障原因:
bug 13066936
故障解决:
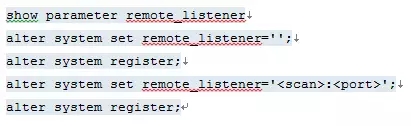
任意环境
从其他应用主机tnsping发现延迟很大
查看监听状态报如下错:
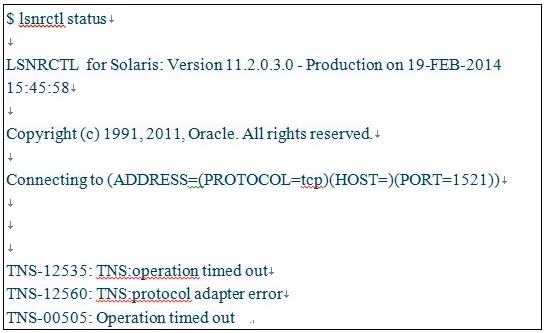
listener.log有如下报错:
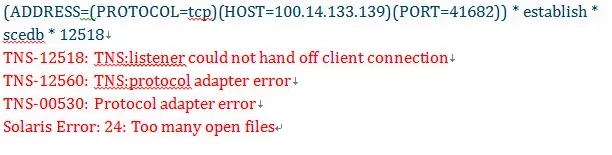
故障分析:
Too many open files意味着Maximum Number Of Open Files Per Process 达到了上限。因此listener hang住的原因是该limit设置过小。
将oracle用户的soft limit提升为至少1024,然后重新oracle用户登录,检验ulimit合格后,重新启动数据库和监听。
具体解决办法如下:
在/etc/system增加以下行
set rlim_fd_max=65536
set rlim_fd_cur=4096
重新登录ORACLE并检验oracle用户的限制
su – oracle
ulimit -Ha
ulimit –Sa
重新启动数据库和监听
任意环境
Db alert日志报如下错误:

故障分析:
一个客户端连接整个步骤:
客户端发起一个connection连接监听
监听启动一个专属进程(服务器进程,也就是我们通常说的LOCA=NO进程)用于接收这个connection
在专属进程启动之后,监听会将这个connection传递给这个专属进程
专属进程通过这个connection来跟客户端握手
专属进程跟客户端信息交换需要建立一个session
session打开
当在以上的第3步到第4步时客户端关闭,所以当专属进程尝试跟客户端联系时发现连接已关闭时,就会报出我们看到的错误!!
错误一般是由于程序异常断开导致超时,11g R1如果出现如上的错误信息会写入到sqlnet.log,11g R2会写入到alert.log,
其实出现此错误是正常的现象。
处理方法:
如果不想这样的信息打印在alert日志中,
在sqlnet.ora设置
DIAG_ADR_ENABLED = OFF
在listener.ora设置
DIAG_ADR_ENABLED_
重启监听
环境:HP-UX 11.31 ia64
数据库版本:11.2.0.4
故障现象:
应用测试连接不上数据库,连接直接报TNS-12547: TNS:lost contact。
但查看监听状态,CRS状态,数据库状态均正常。CRS日志、CSS日志及AGENT日志均无报错。
故障分析:
应用连接数据库直接报TNS-12547: TNS:lost contact
监听日志发现一直在报连接失败:
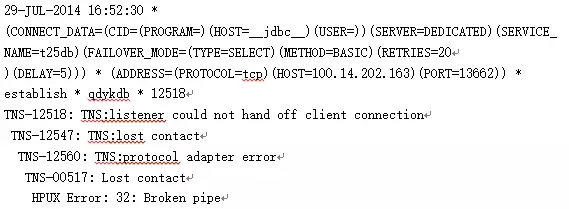
问题导致的原因有在32位平台中当listener.log超过2G会报这个错。
ORACLE_HOME下的一些执行文件权限不对也会导致相同的错误,但我们这个是64位的,排除第一种,
所以去查询执行文件的权限是否正常。
处理方法:
1、 通过对比发现部分执行文件少了S权限,做了relink all,重新同步执行文件
2、 由于数据库使用的是ASM,磁盘属组为asmadmin,故对比问题节点及正常节点DB ORACLE_HOME下属组为asmadmin的文件,将问题节点文件权限修正即可解决问题。
小编精心为大家挑选了近日最受欢迎的几篇热文:
回复001,看杨志洪《【职场心路】一个老DBA的自白》;
回复002,看丁俊的《【重磅干货】看了此文,Oracle SQL优化文章不必再看!》;
回复003,看胡怡文《PG,一道横跨oltp到olap的梦想之桥》;
回复004,看陈科《memcached&redis等分布式缓存的实现原理》;
回复005,看宋日杰《Oracle后台专家解决library cache锁争用的终极武器》;
回复006,看郑晓辉《存储和数据库不得不说的故事》;
回复007,看袁伟翔《揭秘Oracle数据库truncate原理》;
回复008,看李海翔《MySQL优化案例:半连接(semi join)优化方式导致的查询性能低下》;
回复009,看丁启良《LINUX类主机JAVA应用程序占用CPU、内存过高分析手段》;
回复010,看徐桂林《以应用为中心的企业混合云管理》。
DBA+社群是全中国最大的涵盖各种数据库、中间件及架构师线条的微信社群!有100+专家发起人,建有15大城市微信群,6大专业产品群,多达10000+跨界DBA加入队伍。每天1个热议话题,每周2次线上技术分享,不定期线下聚会与原创专家团干货分享,更多精彩,欢迎关注dbaplus微信订阅号!

扫码关注
DBAplus社群
超越DBA圈子,连接的不仅仅是DBA








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721