
12月17日,【DBA+社群】创始人、数据管理专家杨志洪老师,在【DBA+社群】上海群进行了一次主题为“XTTS,又一个值得你重视的Oracle数据库迁移升级利器”的线上分享。小编特别整理出其中精华内容,供大家学习交流。同时,也非常感谢杨志洪老师对DBA+社群给予的大力支持。
杨志洪
【DBA+社群】上海发起人
数据管理专家。Oracle ACE、OCM、 SHOUG/ZJOUG核心成员、DAMA会员/CCF会员,译著《Oracle核心技术》。
在Oracle OOW、DTCC及2015Oracle数据库技术大会等全国性技术会议上发表主题分享,并主办了2014Oracle全国技术巡讲。
2015年创立DBA+社群迅速成为全中国最大的涵盖数据架构师、DBA及中间件的专业社群。
既然说是又一个数据库迁移、升级的利器,那自然而然的,要说到,其他的利器是什么?
我印象里的第一个,是exp/imp,没错,这是一对组合,那是使用svrmgrl的年代。Svrmgrl从Oracle9i起就没有了,但是exp/imp到今天仍然可以用,就如同catproc和catalog一样。
Catproc这对神器我在《职场心路:一个老DBA的自白》里有提到(文章里笔误成cataproc了),从这里,我才开始用正眼看Oracle数据库。
说到这里,我要顺便勘误下这篇文章的一个错误。Part I第四节,原文有一段“最后在舍友的指点下,让程序员把开票查询功能从3秒钟降低到1分钟,问题迎刃而解”。正确的应该是,“最后在舍友的指点下,让程序员把开票查询功能的频率从3秒钟降低到1分钟,问题迎刃而解”。同时,顺便强调下所谓的优化,纵观十几年的服务历程,优化问题的需求,应该是最轻松,且效果最好的。如果您听懂了,那么恭喜你。如果您没懂,可以私下找我聊。
话说回来,exp/imp做迁移太慢了,但是2002年~2004年的时候,大部分的迁移升级工作我都是用它做的。
Oracle从一家传统数据库厂商,能够在最近两年几乎彻彻底底的变为了一家Cloud的企业,实在是因为老拉里的基因本身就是不断挑战,不断革新自己。不论是从他跨界把SUN公司从临死状态搞活,还是帆船赛屌丝逆袭,用大数据勇夺第一。就算是个小小的数据迁移工具,他都是在不断改进。从另一个侧面来说,那些叫嚣去O的小伙伴们,先把O学好了,也许更合适些。
因为exp/imp太慢了,所以Oracle9i开始,老拉里提供了全新的expdp/impdp,速度杠杠的,特别是impdp比imp的提升,那真是数量级的。我这些年招人面试,问到做过哪些数据库迁移/升级,用什么手段/方法时,绝大多数也是这2个。
显然,Oracle迁移升级工具还有很多。比如存储级的复制,比如Oracle的DG,比如DBlink,以及DBUA,以及我们近几年用得最多的升级迁移割接神器---Oracle GoldenGate。
嗯,关于Oracle GoldenGate,回头邀请一位从开始接触Oracle开始一直研究OGG的小伙伴来分享。
因为2015年,我们在一些项目上,有电信运营商的,有电网的,有金融行业的,嗯,还挺多的行业项目的升级迁移上用到了XTTS,积累了不少经验。所以我今天挑了这个主题。
在此,感谢下我团队的小伙伴,大兵和海鹏,今天的分享,幕后更多是他们的功劳。特别是大兵,我们团队里成长非常迅速的小伙子。如果你想快速成长,要一个发挥的舞台,欢迎发简历给我,yangzhihong#shsnc.com 。北京、上海、杭州、广州,3年以上Oracle经验,聪明好学,愿意成长的。我保证你2年后,完全会惊讶自己居然成长这么快!
那接下来就是今天的主题xtts了
观今宜鉴古,无古不成今,表空间传输作为一项从8i时代就开始诞生的技术,在每个版本中借鉴着当时主客观原因不断地发生着巨大的进步。

从8i,tts技术的诞生,引入了相同平台相同块大小之间的表空间传输。到了9i,tts开始支持同平台中,不同块大小的表空间传输。
10g时代,不仅引入了跨平台的表空间传输方案,也就是我们说的xtts;10gR2开始支持传输整个数据库。
11gR1开始,可以传输表空间中的某个特定分区。
在11.2.0.4开始,为了应对越来越大的数据量,而停机时间甚至还在减少的情况,出现了新的解决方案—使用增量备份方式的xtts。

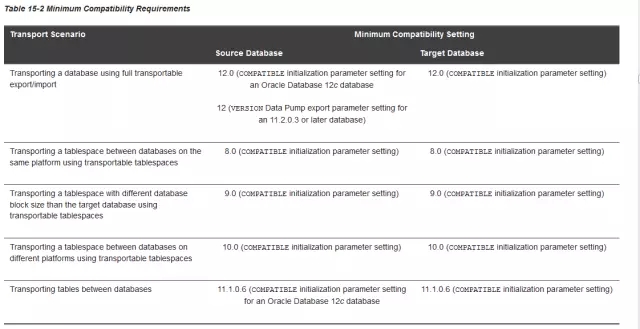
上表也是官方文档中对于数据传输各场景的版本支持汇总。
说了这么多,有些dba朋友就要问了,xtts的具体实现是怎么样来的呢?
不急,今夜依然漫长,先从传统的xtts典型步骤开始说起。

大家可以发现,对于传统的xtts的步骤来说:
第一步将表空间置为只读就意味着停机,而总体停机时间中整体数据文件的传输占了很大的比重。
基于优化这部分时间消耗的考量,11gR4开始出现了一样新的技术--xtts via 增备。
在源端库保持正常运行的时候传送所有的数据文件,通过不断生成的增量备份并恢复,使正式停机时间越来越短,我们来看下它所涉及操作的停机时间轴。
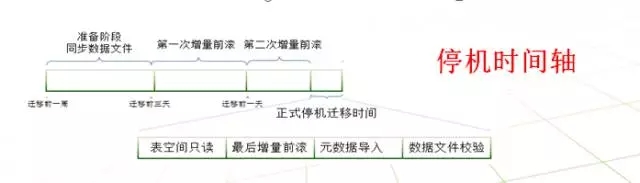
为了减少正式的停机时间,oracle在xtts中引入了rman的增量备份前滚功能。通过一次又一次的增量备份,使停应用的时间主要包含四个方面:将表空间置为只读,最后进行一次增量前滚,元数据导入,数据文件校验,如上图所示。和传统的表空间传输相比,通过减少数据文件的传输时间,而大大减少了整体停机时间。
当然新技术有新门槛,并不是所有场景下都便于使用这个技术,综合xtts所需要的版本特性,操作复杂度,对于使用增备方式的xtts的适用场景,做了如下总结:

版本和平台限制源于新特性的使用,是硬性规定;那么为什么说一定要TB级操作和停机时间在4小时这个区间呢?
大家看完后面的分享就会知道,增备方式的xtts操作还是较为复杂的,对于小数据量的迁移,可以用其它较为简便的方式来进行代替,减少无谓的人力。
至于停机时间,这是稍后我们给大家给出的一个最佳实践中的停机区间。
有道是万丈高楼平地起,一次完成的迁移也少不了完善的检查,下述是检查项中最为重要的。

具体请参考1454872.1 Transportable Tablespace (TTS) Restrictions and Limitations: Details, Reference, and Version Where Applicable 完成必要检查。
只要地基打的牢,风吹高楼也不怕
三山半落青天外,一水中分白鹭洲,前戏都说完了,接下来从使用的角度开始介绍,这项迁移家族中的新武器增备方式xtts的。
首先,我们先了解下增备xtts的四大阶段:

关于初始化阶段,很简单着重在脚本和参数的配置

rman-xttconvert_2.0.zip,目前官方提供的用来执行整个操作步骤的驱动脚本。
这里需要注意的是环境变量$TMPDIR,当考虑到种种情况,需要将表空间分批传送时,需要指定不同的$TMPDIR目录。
然后就是最重要的参数配置了(上图中列出的最为重要的配置参数)
其中包括要传输的表空间,系统版本,不同同步方式需要用的目录制定
参数解释如下。

具体参数请结合自身的实际使用情况,结合文档进行配置
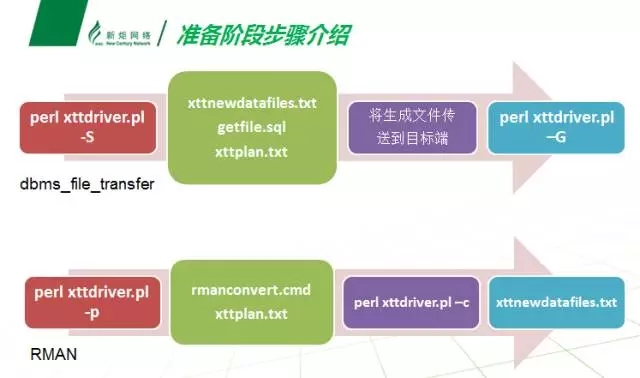
对于准备阶段,也就是将所有的数据文件同步到目标端的这个阶段,增备xtts提供了两种方案,上图是执行操作的一个步骤流。
dbms_file_transfer会根据源端的目录结构传送到目标端时配置成相同的目录结构,但是容易触发bug,整个准备阶段的同步过程中容易间断,需要后期使用rman单独数据文件的方式传送失败的数据文件。
Rman方式目前为止比较稳定,但是它会将所有的数据文件后缀改名为xtf,并且每一个批次的数据文件只能传送到一个目录下。比较适用于asm的情况。
不管使用哪种方式完成准备阶段,增量前滚阶段的步骤都是一致的。
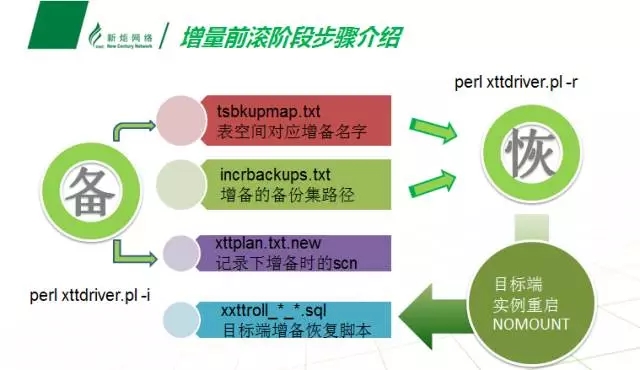
在源端执行-i参数后,会直接生成增量备份和临时文件,将之传送到目标端后-r参数开始恢复即可。
在增量备份阶段还是有以下部分需要注意:

增量备份是基于xttplan.txt中的记录进行的,如果在每次增备后没有替换该文件,下一次的增备又会基于之前记录的scn开始进行。




原库使用增量备份,每一次平均消耗两个power 6 cpu的使用率,需要考虑到原库的负载情况开始增备。如果原库的配置较高,可以同时进行几个批次的备份,不过要注意,目标端恢复只能单个批次进行。
最后说下升级的主要步骤:

步骤虽然简单,还是有不少注意事项:

上述的注意事项,基本集中在元数据导入时,那么问题来了,元数据导入出错怎么办?

删除所有的表空间后重新导入,只有50%的成功几率,oracle的原话如下:
The import process can modify the file headers at various points during the import, especially when transportable=always is used; it not currently possible to tell at which point in the import process that has happened, not even from a timestamp. The only thing you can do is drop* all of the tablespaces that have been plugged into the target and retry the entire TTS import. If it errors, you will need to recopy/convert all the datafiles again. You cannot do only a partial-tablespace import, as the export file references all tablespaces
不过这只是之后用于补救的方法了,前期的检查可以将这种50%的赌博解决于发生前。
看完了具体使用的四个阶段,也了解了不少注意事项,大家对增备xtts的感觉如何?
在分享我们的最佳实践之前,先和大家分享一下我们在得出最佳实践之前,一次完整升级的用时情况。
在本次迁移中,数据量7.5T,数据文件大小在8T,目标端使用文件系统
每个文件目录1T,使用rman进行传输,分为8个批次进行传输。
准备阶段全同步,受限于远程挂载的中转目录网络带宽因素,每个批次耗时总计2.5小时。
增量前滚阶段,同样受限于网络带宽因素,八个批次同步一天的增量数据,需要总计2.5小时的操作过程。

在正式迁移中,因为操作的批次较多和网络带宽受限,导致了最后一次增量前滚耗时也在2小时以上。
这之后开始进行了元数据的导入。
正式迁移当天,在元数据导入阶段中,统计信息导入耗时3小时。其余部分导入耗时40分钟。二次导入系统表空间对象耗时30分钟。
下图是元数据导入时,各方面时间所占比重
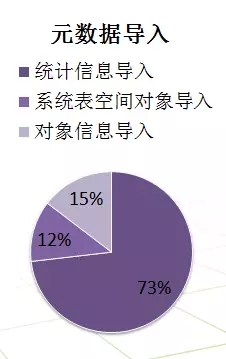
在本次迁移中,统计信息在首批元数据导入中,这一批的元数据导入是无法开启并行,以致时间消耗过久,占总体比重70%以上。
每次迁移都有不同的发现,针对这次迁移实施,事后总结如下:
1.挂载共享存储存放增备的时候,要加大网络带宽
2.迁移时尽量减少批次,操作越多越容易出错
3.元数据导入时排除统计信息
4.二次对象导入时开启并行
我们回顾下在使用增备xtts迁移时,总结的一些已知bug
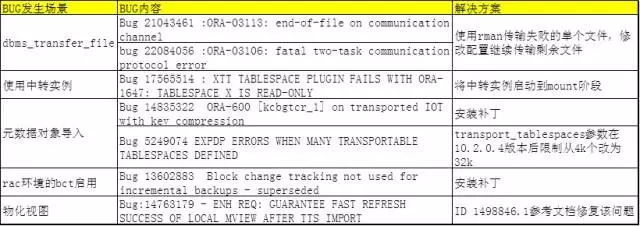
大家可以发现,大部分bug已经有了workaround。这里有一点要说一下,就是使用在准备阶段使用dbms_transfer_file包进行传输时,遇到的两个bug仍然处于开发人员跟进状态,我们在遇到后,和原厂讨论暂时使用rman传输单个文件的方式进行规避。
不过呢这也是属于治标不治本,并没有从源头上将dbms包执行失败导致的问题进行修复。
上面细数了迁移的每个具体步骤和一直的bug列表,接下来将会和大家分享一下关于使用增备xtts迁移的最佳实践。
其实也谈不上参数上的最佳实践了,只是经验所得的四个建议和一大杜绝。

目前准备阶段使用dbms包遇到的bug过多,同步过程极易打断,不建议使用。
目标端使用一个大目录或者asm磁盘组,目的在于减少同步批次,简单最不容易出错。
中转目录的挂载则是考虑到正式迁移时消耗在增量备份上面的时间。
至于元数据导入,相信各位之前看过前一页的朋友们应该不会再有疑问了
然后就是一大杜绝了,在后面我们会有介绍添加了数据文件的补救方法,不过因为要改很多文件,甚为麻烦,也希望大家不要在漫长的迁移期间为自己增加无谓的工作量了。
Xtts因为整个操作步骤繁多,时间周期漫长,在各个阶段都存在不少的深坑,接下来,我们看下xtts的常见深坑。
首先和大家强调一定要开启XTTDEBUG环境变量,便于我们在出现问题时的定位。

这是两个文档中没有提及的错误,在迁移实施中较为常见,不过因为是在非停机时间段内,所以不影响正式迁移的时间。
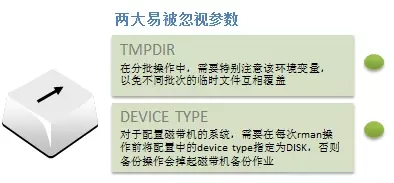
当批次过多时,这两个参数越容易出问题,当我们的临时文件出现错乱时,想要补救将要消耗很大的心力。

这两类容易出问题的对象mos上也有专门的文档去修复了,结合文档内容进行整改。

最后就是和大家分享下两种常见场景下的补救措施。
屋漏偏逢连夜雨的时候,我们要相信那是柳暗花明又一村的开始,遇到错误不可怕,研究并解决才是我们做技术的职业素养。
首先是准备阶段全同步文件到一半出错了怎么办。



还有就是前面提到的一大杜绝,在整个迁移过程中,源端添加了数据文件怎么办。
在dbms包的情况我们需要修改三个文件去保证。
如果是rman同步,则只需要修改xttplan.txt和xttnewdatafiles.txt即可。
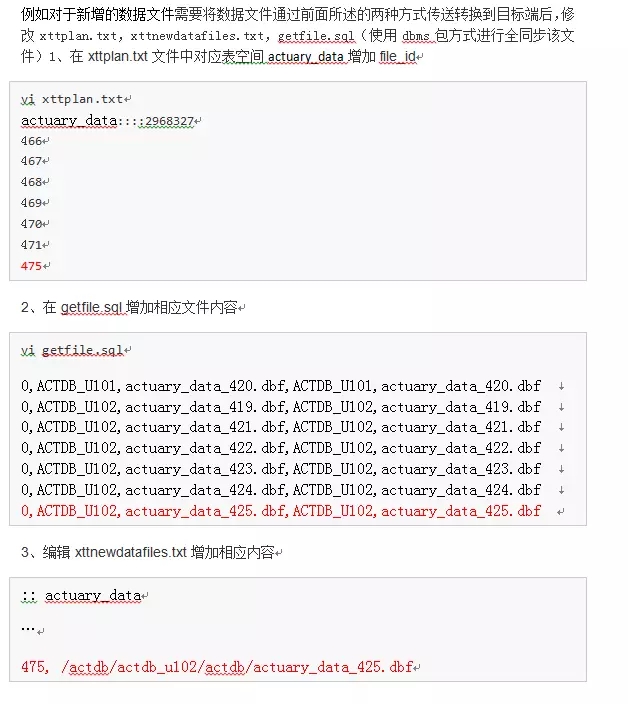
至此,补救完成,我们的迁移又可以继续进行了。
以上增备xtts的分享就结束了,作为迁移大家庭中的一员,大家不要因为其理论上的停机时间而盲目的选择它,古诗云“梅须逊雪三分白,雪却输梅一段香”。最适合的,才是最好的。
Q1:看杨老师介绍说11204的新功能,是要求源和目标都是这个版本以上?还有生产环境可能有文件包含特殊字符或乱码(文件名有空格),该如何处理?
A1:源端10.2.0.1以上版本就好,要求目标是11.2.0.4。 空格,上述例子中可以看到,要把空格加上去。当然,如果源库有条件整改,最好整改成正常的状态再做后续工作。
Q2:中转机是什么作用,是否必需?源和目标都是asm,是否必需用文件系统中转机过渡?
A2:中转实例,是用于目标端非11.2.0.4版本情况下,如果目标端11.2.0.4,则不是必须。这种情况看比较少,就是目标端非得用11.2.0.3这种版本的时候。
再次感谢数据管理专家杨志洪老师,对DBA+社群活动给予的大力支持!
“DBA+社群”将陆续在各大城市群进行线上专题分享活动,以后每周一、周三晚上为【DBA+专业群】的固定时间,每周二、周四晚上为【DBA+各城市群】的固定时间,每周五晚上为【DAMS架构师精英群】的固定时间,欢迎大家积极加入我们。无论是内容还是形式,有好的建议我们都会积极采纳。
想入群的小伙伴们请关注DBA+社群微信公众号:dbaplus,回复“加群”即可。
小编精心为大家挑选了近日最受欢迎的几篇热文:
回复001,看杨志洪《【职场心路】一个老DBA的自白》;
回复002,看丁俊的《【重磅干货】看了此文,Oracle SQL优化文章不必再看!》;
回复013,看吕海波《去不去O,谁说了算?》;
回复014,看黎君原《扒一扒Oracle数据库迁移中的各种坑》;
回复015,看郭耀龙《假事务之名,深入研究UNDO与REDO》;
回复016,看陈能技《基于Docker的开发模式驱动持续集成落地实施》;
回复017,看朱贤文《数据库与存储系统》;
回复018,看楼方鑫《数据库中间层,这样定制可能更好》;
回复019,看王佩《基于Docker的mysql mha 的集群环境构建实践》;
回复020,看王津银《互联网运维的整体理念与最佳实践》。
DBA+社群是全中国最大的涵盖各种数据库、中间件及架构师线条的微信社群!有100+专家发起人,建有15大城市微信群,6大专业产品群,多达10000+跨界DBA加入队伍。每天1个热议话题,每周2次线上技术分享,不定期线下聚会与原创专家团干货分享,更多精彩,欢迎关注dbaplus微信订阅号!

扫码关注
DBAplus社群
超越DBA圈子,连接的不仅仅是DBA








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721