
转载声明:本文为DBA+社群原创文章,转载必须连同本订阅号二维码全文转载,并注明作者名字及来源:DBA+社群(dbaplus)。
专家简介

马育义
【DBA+社群】广州群副
拥有5年DBA运维经验,精通Oracle数据库管理,深入理解Oracle 体系结构,擅长使用RAC、Dataguard、Goldengate等技术解决Oracle数据库运维故障。精通Oracle数据库安装配置、性能诊断、故障处理、备份解决方案的设计与实施。Oracle OCP认证讲师,在Oracle OCP和OCM的培训方面也有较为丰富的经验,曾多次负责广东移动、深圳航空的DBA培训工作。
从10g开始,数据文件的存储除了使用裸设备和文件系统外,还可以存放在ASM中。简单的理解,存放在ASM中的数据文件,日志文件,控制文件,归档日志等等,就是ASM FILE。仅有以下的文件类型可以存放在ASM Diskgroup中:
Control File
Datafile
Temporary data file
Online Redo Log
Archive Log
RMAN backup
Datafile Copy
SPFILE
Disaster Recovery Configuration
Flashback Log
Change Tracking Bitmap
DataPump Dumpset
一个ASM FILE的名字一般以一个”+”和DiskGroup名字开头。 当ORACLE RDBMS KERNEL内核的文件I/O层碰到一个以”+”开头的文件时,就会走到相关ASM的代码层中 而不是调用依赖于操作系统的文件系统I/O。 仅仅在File I/O层面才会认识到这是一个ASM 中的文件,而其上层的内核代码看来ASM FILE和OS FILE都是一样的。
举例:
+DATAA/orcl/datafile/system.256.689832921
格式说明: +DATA/orcl/datafile/tbs_name.asm_filenumber.incarnation_number
orcl:数据库名称
datafile: 文件类型,表示是数据文件
tbs_name: 表空间名
asm file#: 表示ASM file编号,$asm_file.file_number
incarnation number: 从时间戳提取,唯一值。
在一个ASM Diskgroup中仅仅允许存放已知的ORACLE文件类型。假设一个文件通过cp拷贝到ASM Diskgroup中,则该文件的第一个块将被检验以便确认其类型,以及收集其他信息来构建这个文件的完整ASM文件名。 如果其文件头无法被识别,则该文件在DiskGroup中的创建将会报错。
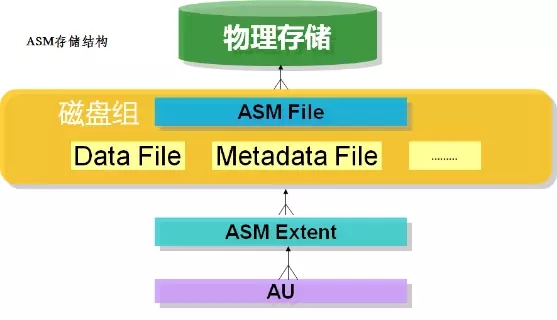
ASM在分配空间时,以AU为单位进行,AU即Allocation units,是组成ASM disk的基本单元。在Oracle 10gR2中,ASM AU的缺省单位大小是1M,相应的条带化大小是128K,可以通过调整_asm_ausize隐含参数来调整AU大小,调整_asm_stripesize控制相应的条带化大小。
11g后可以在创建磁盘组时可以配置AU 大小,AU的允许大小有1、2、4、8、16、32 或64 MB。
所有被ASM所支持的文件类型仍以其file block作为读和写的基本单位。在ASM中的文件仍保持其原有的 Block Size 例如数据文件默认为8k,ASM并不能影响这些东西。值得一提的是在ASM FILE NUmber 1 的FILEDIR中记录了每一种FILE TYPE对应的BLOCK SIZE。
ASM的元数据都存储在ASM磁盘中,用以存放ASM Diskgroup控制信息的数据,Metadata包括了该磁盘组中有哪些磁盘,多少可用的空间,其中存放的File的名字,一个文件有哪些Extent等等信息。
元数据分成2类,一类是物理元数据(Physical Metadata),一类是虚拟元数据(Virtual Metadata)。物理元数据存储在磁盘的固定位置,通常在ASM磁盘头。虚拟元数据后者存储在ASM文件上,和常规的ASM File一样在所有磁盘之间均匀分布。事实上虚拟元数据也是当做一个个ASM File来维护的。
所有的元数据block均是4k大小,并且有checksum信息来确认block是否被损坏。
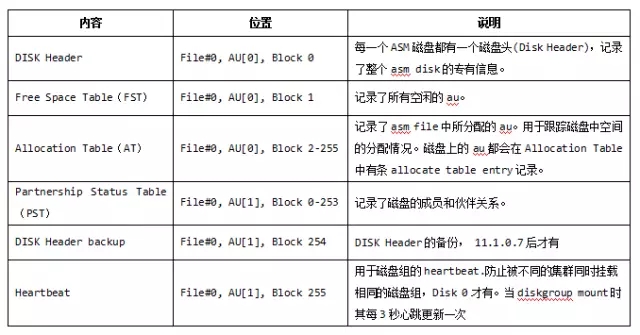
一个ASM DISK的最前面4096字节为disk header,对于ASM而言是block 0 (blkn=0)。ASM disk header描述了该ASM disk和diskgroup的属性,通过对现有disk header的加载,ASM实例可以知道这个diskgroup的整体信息。所以对那些会影响ASM disk header的操作要慎之又慎,同时最好定期备份disk header。
物理元数据存储在磁盘的固定位置,通常在ASM磁盘头,其由以下组成:
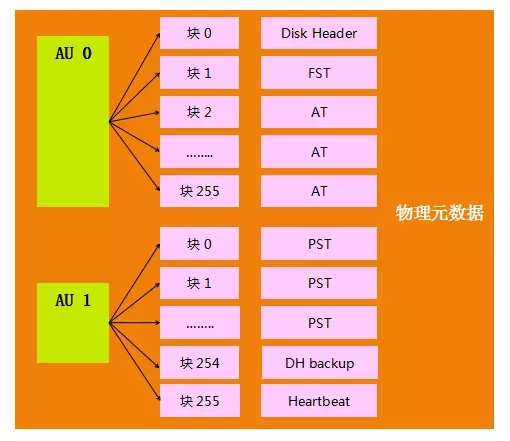
物理元数据用于描述磁盘组的组成、空间分配等内容。而虚拟元数据则用于记录ASM文件在磁盘上的分布,虚拟元数据也存在于ASM文件当中,和其他ASM文件的分布和管理完全相同。虚拟元数据一般包含:
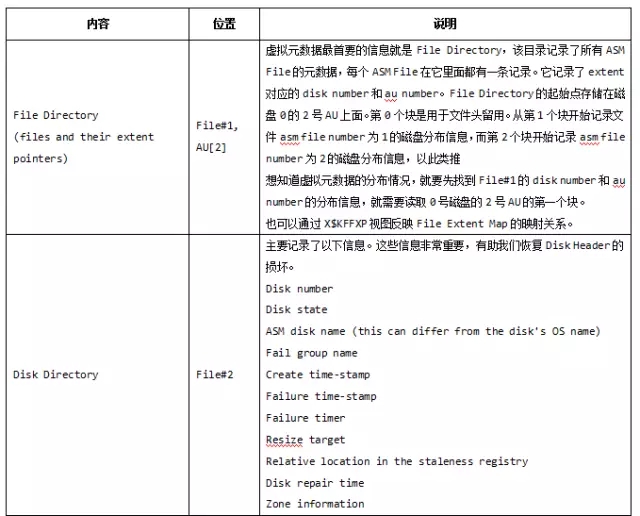
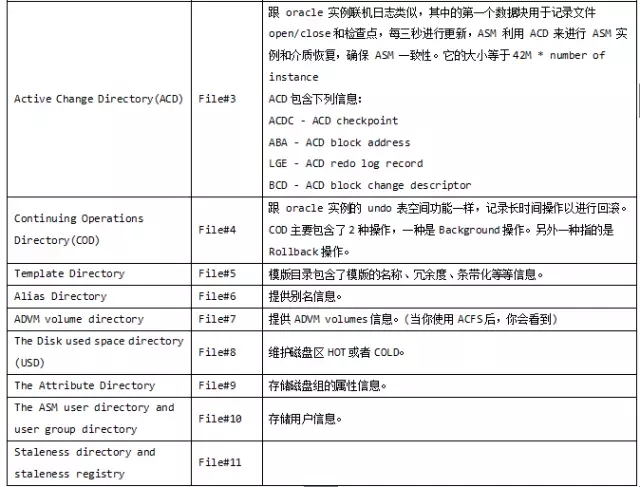
ASM的物理元数据都保存在AU 0和AU 1中,其他的虚拟元数据的位置要到File Directory去查询,该目录记录了所有ASM File的元数据,每个ASM File在它里面都有一条记录,它记录了每个ASM File的extent对应的disk number和au number。
File Directory的起始点存储在磁盘0的2号AU上面。2号AU总共有256个块。每一个块大概4KB。第0个块是用于文件头留用。从第1个块开始记录文件asm file number为1的磁盘分布信息,而第2个块开始记录asm file number为2的磁盘分布信息。以此类推,刚好从asm file number从1-255都保存在2号AU上面。所以File#1至少包含了2个AU,因为我们的数据库文件的file number是从256开始的。
想知道虚拟元数据的分布情况,就要先找到File#1的disk number和au number的分布信息,就需要读取0号磁盘的2号AU的第一个块。
Oracle提供了一个KFOD工具,10gR2以上都有自带,用于列举搜索磁盘。我们先看看测试环境中有哪些共享磁盘:
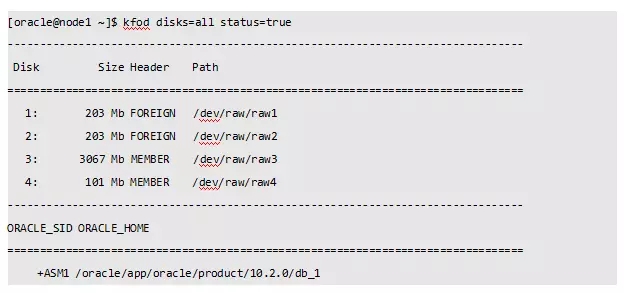
在我的测试环境中,磁盘组DATA有两个磁盘raw3和raw4:

ASM block的查看,Oracle提供了一个kfed工具。11g后可直接在oracle用户下使用,而10g则需要编译一下:

查找File#1的AU分布情况:
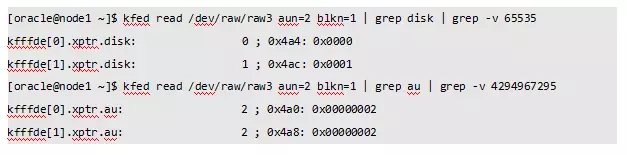
我们可以看到File#1有2个AU:
DISK 0,AU[2]
DISK 1,AU[2]
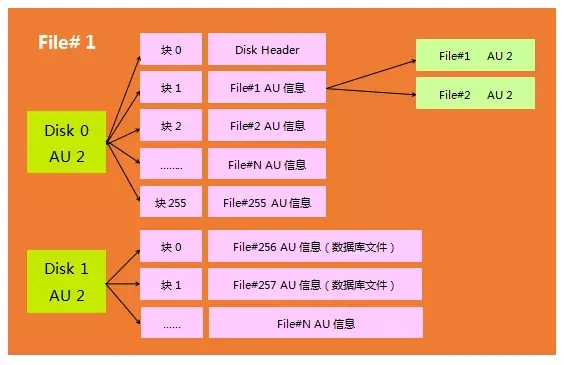
案例:查询控制文件的AU信息
现在我想查看控制文件的AU信息,先计算控制文件的AU信息在File Directory的哪个块:

接下来我们读取1号磁盘的2号AU的第4个块。这个AU是从块0来记录256号文件的。无需进行预留。为什么是第4个块?
260-255=5 默认从0号块开始,所以第4个块代表了260号文件
然后我们查出包括控制文件的AU信息。
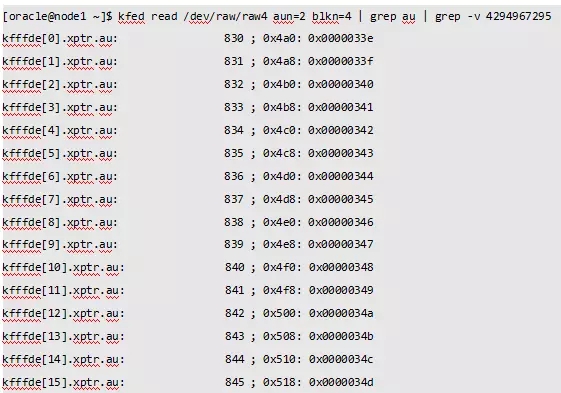
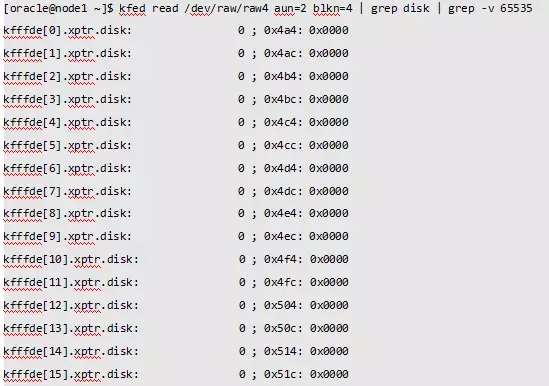
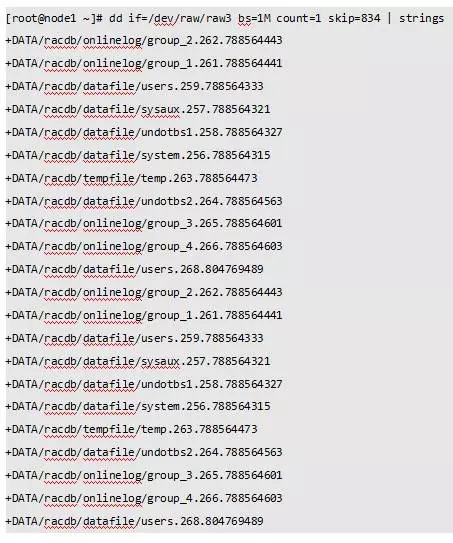
最后我们找一个AU来确认一下是否是控制文件。我们用操作系统的dd命令读取0号文件的第834号AU信息。
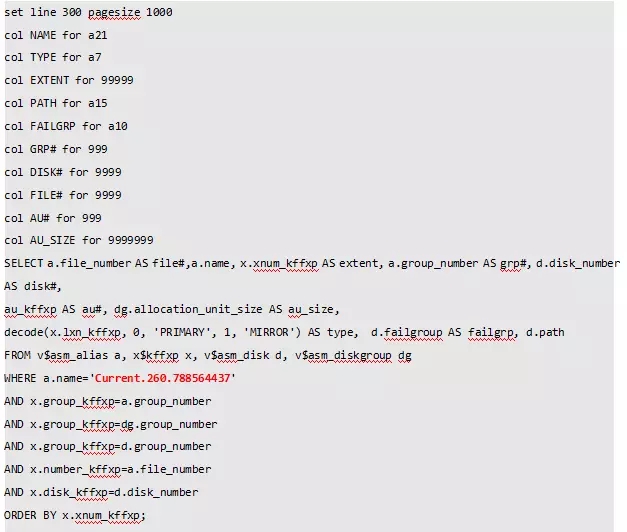
通过视图X$KFFXP可以更直观地查看ASM file的物理分配AU情况。该视图主要是反映了File Extent Map的映射关系。ASM把文件分成多个Extent,而Extent是由AU构成的。
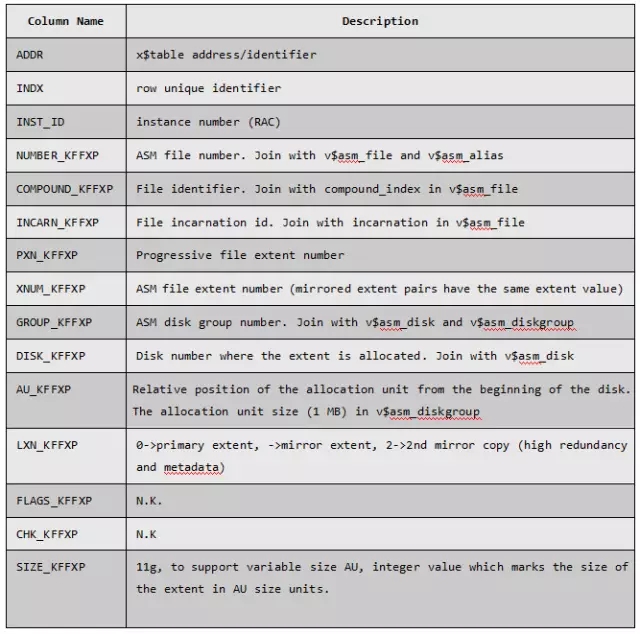
通过X$KFFXP和v$asm_alias、v$asm_disk、v$asm_diskgroup等相连,可以方便地查询到各个ASM File的AU分布情况:
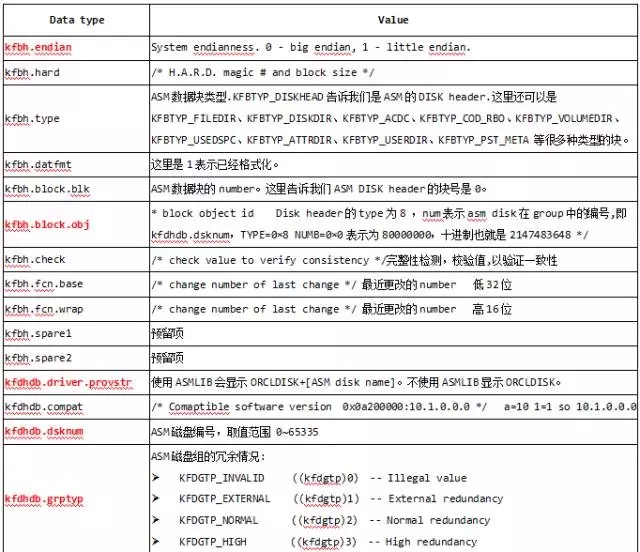
ASM disk header描述了该ASM disk和diskgroup的属性,通过对现有disk header的加载,ASM实例可以知道这个diskgroup的整体信息。
下面是一个典型的disk header的组成:
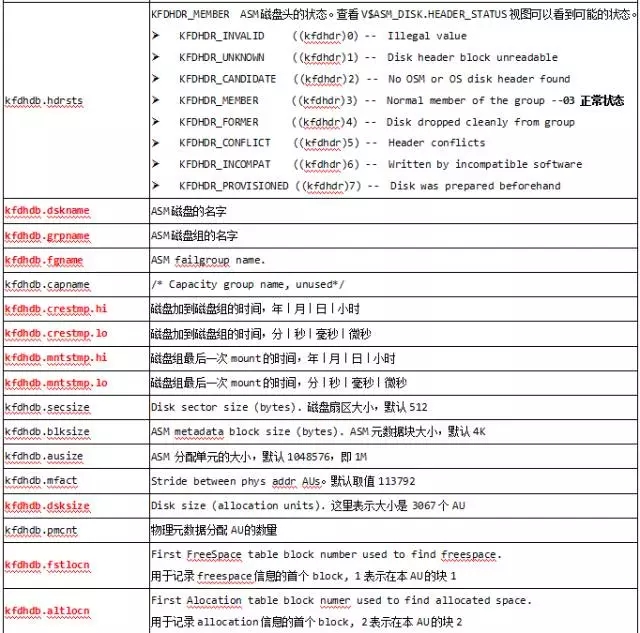
下面的信息是在同一个diskgroup中的所有disk的header上均会复制一份的:
Disk group name and creation timestamp
Physical sector size of all disks in the disk group
Allocation unit size
Metadata block size
Software version compatibility
Default redundancy
Mount timestamp
下面的信息是每一个asm disk独有的:
ASM disk name (not OS path name)
Disk number within disk group
Failure group name
Disk size in allocation units
ASM磁盘头的查看,我们可以直接使用Oracle提供的kfed工具。

但是这样不一样能发现元数据有异常的情况,我们可以使用kfed find命令检验AU[0]所有块的元数据类型是否正常。如果出现非以下结果的块,说明ASM元数据块有所损坏。
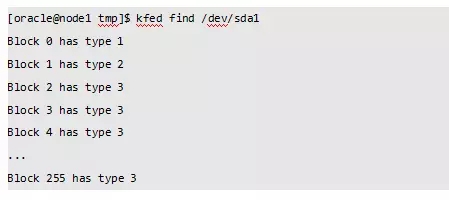
注:以上只是检验元数据块的类型是否正常,如果元数据块中内容有误,目前还是没有办法可以直接检查出来。
ASM磁盘头的重要性无庸置疑,通过观察ASM磁盘头各项含义后,我们发现ASM磁盘头并不类似其他ASM File一样经常变化修改,这使得对ASM磁盘头的备份具体有行性。
对于10.2 到11.1.0.6的ASM,磁盘头的备份方法就是dd或者kfed。
dd备份:

dd恢复演示:
1、模拟磁盘头损坏
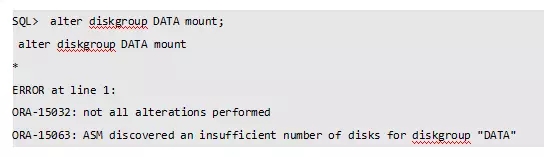
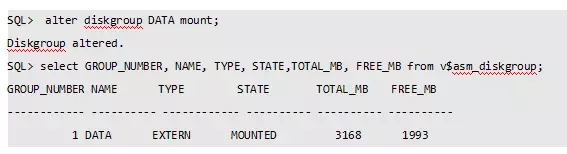
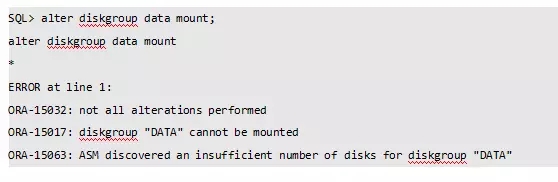
此时再挂载磁盘组报错:
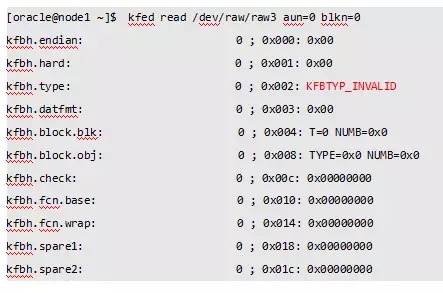
2、检查磁盘头内容
kfed检查ASM 磁盘头,Kfed输出显示磁盘头的信息全部都是0,说明ASM磁盘头被覆盖或损坏了。
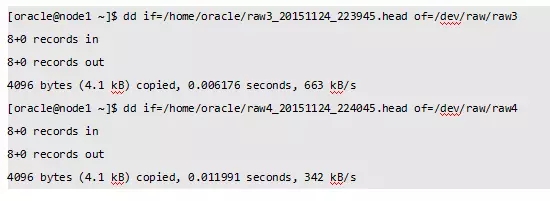
3、使用前面的dd备份恢复
4、重新挂载磁盘组
kfed备份:

kfed恢复:

注意:如果既无dd备份也无kfed备份,则只能手动修复磁盘头,后面有详细介绍。
从10.2.0.5、11.1.0.7、11.2之后ASM磁盘头会自动备份到AU#1的倒数第二个block。对于AU size是1MB的DISKGROUP,每个AU包括block数量=1024KB/4KB=256个,因此备份信息位于AU#1的第254号block(block从0号开始)。当然可以计算得到:
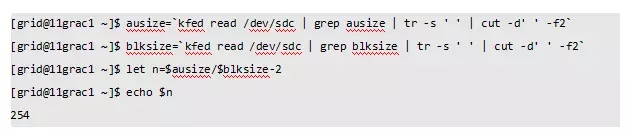
查看ASM磁盘头备份信息,备份信息与ASM disk header信息完全一致(blk、check除外):
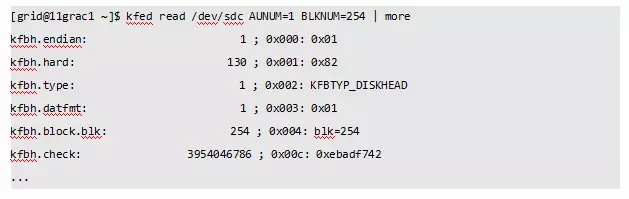
因此可以直接使用kfed命令修复磁盘头。
1、模拟磁盘头损坏
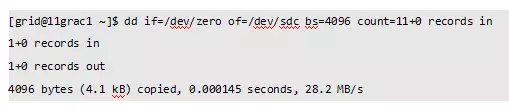
此时再挂载磁盘组报错:
2、kfed修复磁盘头
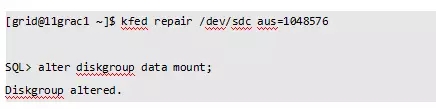
3、查看新的磁盘头
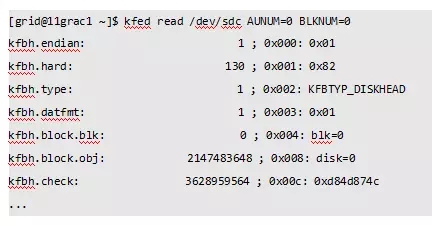
针对10g和11gR1,由于ASM没有自动备份磁盘头。在某些磁盘维护操作时很容易误删除磁盘头数据,此时就只能通过手工重构磁盘头。
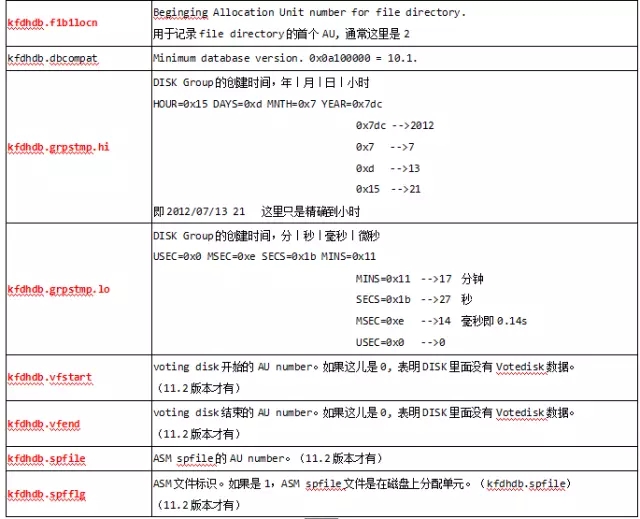
重构磁盘头主要需要修改下列值:
kfbh.endian
kfbh.block.obj
kfdhdb.driver.provstr
kfdhdb.dsknum
kfdhdb.grptyp
kfdhdb.dskname
kfdhdb.grpname
kfdhdb.fgname
kfdhdb.crestmp.hi
kfdhdb.crestmp.lo
kfdhdb.mntstmp.hi
kfdhdb.mntstmp.lo
kfdhdb.dsksize
kfdhdb.fstlocn
kfdhdb.altlocn
kfdhdb.f1b1locn
kfdhdb.grpstmp.hi
kfdhdb.grpstmp.lo
当然还有些情况,需要具体问题具体分析,比如使用了11.2的版本的,就需要有VOTEDISK和SPFILE的那几个参数值,上面列出来的是针对10g和11gR1。
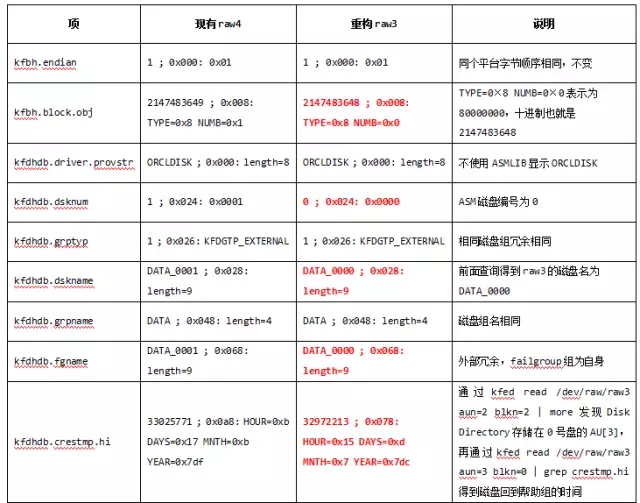
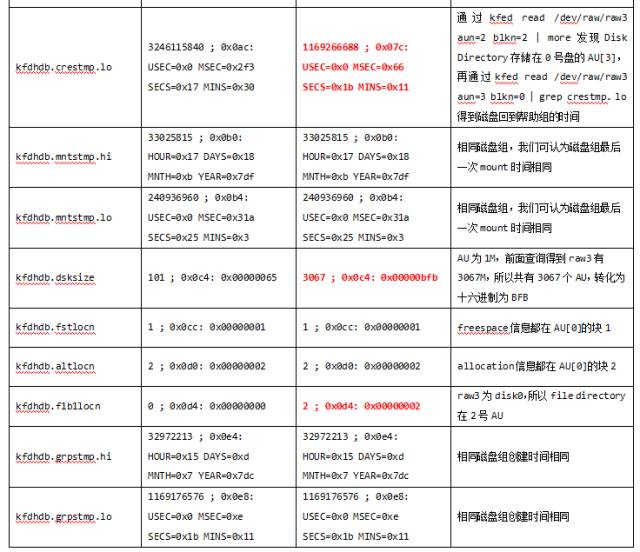
如1.3中所介绍的,Disk Directory包含大量磁盘头信息,是我们手工重构磁盘头的数据来源。而如果只是磁盘组中一块磁盘头损坏,则可以更加方便地参考其他正常磁盘头的信息。
在我的测试环境中,磁盘组DATA有两个磁盘raw3和raw4:

先暴力摧毁raw3的磁盘头:

我们先利用raw4生成一个磁盘头,再重构成raw3的磁盘头:

修改必要的值,与raw3的实际情况配合,以下是要修改的项。
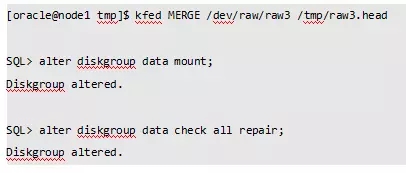
修改/tmp/raw3.head后,写入到raw3的磁盘头中,重新挂载磁盘组成功。
即日起,凡是推送在【DBAplus社群】平台的文章,阅读量超过1000,该文章作者可获得赠书一本。大家如有好的干货文章也可以向我们的订阅号投稿,投稿邮箱:1017465571@qq.com。近期赠书有:白鳝《思想的天空》、杨志洪《Oracle核心技术》……
小编精心为大家挑选了近日最受欢迎的几篇热文:
回复001,看丁俊的《【重磅干货】看了此文,Oracle SQL优化文章不必再看!》;
回复002,看吕海波的《去不去O,谁说了算?》;
回复003,看胡怡文《PG,一道横跨oltp到olap的梦想之桥》;
回复004,看郭耀龙《假事务之名,深入研究UNDO与REDO》;
回复005,看杨志洪《【职场心路】一个老DBA的自白》;
回复006,看周俊《被埋没的SQL优化利器——Oracle SQL monitor》;
回复007,看袁伟翔《揭秘Oracle数据库truncate原理》;
回复008,看杨奇龙《数据库性能测试》;
回复009,看丁启良《LINUX类主机JAVA应用程序占用CPU、内存过高分析手段》;
回复010,看黎君原《扒一扒Oracle数据库迁移中的各种坑》。
DBA+社群是全中国最大的涵盖各种数据库、中间件及架构师线条的微信社群!有100+专家发起人,建有15大城市微信群,6大专业产品群,多达10000+跨界DBA加入队伍。每天1个热议话题,每周2次线上技术分享,不定期线下聚会与原创专家团干货分享,更多精彩,欢迎关注dbaplus微信订阅号!

扫码关注
DBAplus社群
超越DBA圈子,连接的不仅仅是DBA








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721