
作者介绍
梁敬彬,福富研究院副理事长、公司唯一四星级内训师,国内一线知名数据库专家,在数据库优化和培训领域有着丰富的经验。多次应邀担任国内外数据库大会的演讲嘉宾,在业界有着广泛的影响力。著有多本畅销书籍,代表作有《收获,不止SQL优化》等。
前两章给大家介绍了发现问题后的整体解决思路,接下来进入SQL优化的局部性思路,这一章我们将学习SQL优化的重要知识:执行计划。
执行计划是什么?如何读懂执行计划?读懂执行计划对我们又有什么用?面对这些疑问,我们从执行计划分析概述、读懂执行计划的关键、从案例中辨别低效SQL、总结思考这四部分入手开始本章的学习分享,如下图所示:
一、执行计划分析概述

执行计划是什么对我们来说其实还是比较好理解的,由于SQL语言是一种傻瓜式语言,一个条件就是一个需求,比如 select * from t1 , t2 where t1.id= t2.id and id=6这样的语句,开发人员实际上只关心能否通过访问t1、t2两个表得到两个表相关联的数据,他们并没有指定该SQL如何执行,也就是说他们不关心该SQL是先访问t1表再访问t2表呢,还是先访问t2表再访问t1表。
对SQL来说,这两种访问方式就是两个不同的执行计划,而且必须做出选择,一次只能有一种访问路径。
那到底选择哪一种呢?答案很简单,哪种执行开销更低,就意味着性能更好,速度更快,我们就选那一种。这种过程就叫作Oracle的解析过程,一般都在1s内即可完成。然后数据库把这个更好的执行计划保存下来放到SGA的Shared Pool里,后续如果再执行同样的SQL,只需要直接在Shared Pool里去获取就可以了,不需要再去分析了。
这就是SQL的执行计划!

等等,刚才好像说得有点偏简单了,数据库根据执行计划开销低不低来选择。可是问题来了,如何知道哪种最低呢?
有人说,让Oracle分别根据不同的执行计划执行一下,比较性能如何,不就成了。这听起来似乎有点道理,是先访问t1还是先访问t2也就是执行2次就知道谁代价更低了。
不过大家有没有注意到and id=6的条件,假如id列上有索引,Oracle就会面临两个选择,一个走id列的索引访问方式,另一个不走索引,走全表扫描方式,是不是感觉又复杂了。假设将语句从from t1 , t2 改成from t1 , t2, t3或者是from t1 , t2, t3, t4,甚至是更多的表呢?请你现在用学过的数学排列组合的方法来判断Oracle会有多少个执行计划,是不是多得有点头晕了,难道你真忍心让该SQL去尝试执行每个执行计划吗?
当然,要是出现某种执行计划极其低效的情况,该SQL可能一直运行着,根本就停不下来,你也别想看到结果。
因此Oracle的执行计划的选择是有套路的。这里有一个重要的关键字:统计信息。有了这个统计信息,Oracle就可以高效快速地完成SQL的解析过程(判断出代价更低的执行计划),还记得前面说过的话吗?一般解析都在1s内完成。

统计信息是什么东西?别着急,我们回到之前的例子from t1 , t2语句。从原理上来说,先访问小表,其成为驱动表,性能更高,因此如果我们知道t1和t2表谁更小,问题就解决了,不需要根据这两个不同的写法分别执行了。
有人说,此时count(*)分别统计两个表就OK了,好简单啊。
真是如此吗?假如表的记录很大,查询不是很慢吗?你如何保障快速完成SQL解析从而选择代价低的执行计划呢?
所以这个大表和小表,是数据库直接告诉这条SQL的。统计信息就是这么来的。
数据库会对库里的每张表都做一个统计,记录每张表的记录数,比如可以通过如下语句来分析t1表和t2表的表及索引的统计信息:
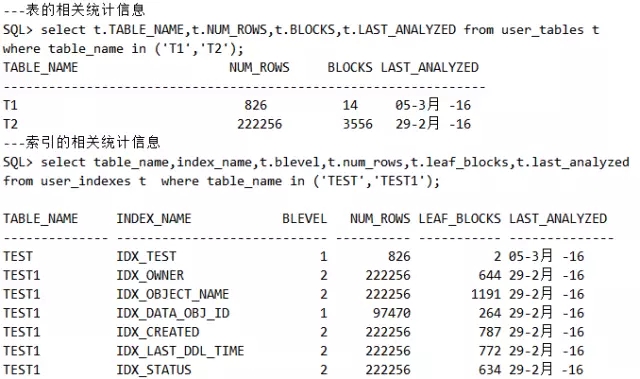
脚本1 查看表和索引的统计信息
可以看出,t1表比t2表小很多,这时Oracle 就会选择让该SQL的执行计划先访问t1表,再访问t2表。不过问题来了,这Oracle 如何知道这个数据呢?难道也是count(*)一把吗?
嗯,这里又有学问了,其实Oracle做这事是很有套路的:
Step1:Oracle会在一个固定的时间将库里的表和索引的相关统计信息进行收集(默认选择周一到周五晚上10点和周六日早上6点),用户可以自己调整收集时间,主要是为了避开高峰期。这么一来,等于用空间换时间,执行计划通过了解数据字典中的这些num_rows和blocks即可知道表的大小。
Step2:大家可能注意到LAST_ANALYZED字段的取值,似乎时间有点早,不像每天都收集的样子,原来Oracle可以专门对表的记录变化量进行管理,当某表一天记录变化量没有超过指定的阈值时,Oracle就不会对该表进行统计信息收集,所以很多时候不少表被第一次收集统计信息后,由于一直很少更新,故很少再有针对该表收集信息的动作。
Step3:收集表和索引信息的动作非常灵活,比如可以只针对分区表的某个分区进行收集,可以在闲时使用并行机制来收集表和索引的统计信息,这可以极大提升性能等等。
如此一来,Oracle收集统计信息的本领真的强大了很多,也怪不得Oracle可以轻松地完成执行计划的解析工作了,原来Oracle有一套强大的处理机制来保障高效获取执行计划。
关于收集统计信息的方法比较多,可以是针对整个数据库的收集,可以是针对整个schema的收集,也可以是针对具体某个表和索引的收集。从操作实用性来看,主要的日常操作都是手动收集某表或者某索引的统计信息,方法如下:

脚本2 收集表和索引的统计信息
如果是针对分区表,则可以指定只收集某分区,具体如下:
exec dbms_stats.gather_table_stats(ownname => 'LJB',tabname => 'RANGE_PART_TAB',partname =>'p_201312', estimate_percent => 10,method_opt=> 'for all indexed columns',cascade=> TRUE) ;
脚本3 针对某分区进行统计信息收集
可以看出,收集统计信息的方法其实非常灵活,具体细节可以多研究dbms_stats.gather_ table_stats的其他参数。从实际案例来看,本节展现的细节已经够用了。
善于动脑的同学可能会发现一个问题,比如Oracle是每天晚上10点收集统计信息,那此时如果是早上9点新建了一张表,Oracle该如何知道这个表的记录大小呢?
确实,这是一个问题,Oracle如何做呢?请看下面我们怎么做。
构造环境,新建一张T_SAMPLE表,发现统计信息果然没有被收集,对应的NUM_ROWS BLOCKS和LAST_ANALYZED都是空的。
set autotrace off
set linesize 1000
drop table t_sample purge;
create table t_sample as select * from dba_objects;
create index idx_t_sample_objid on t_sample(object_id);
select num_rows, blocks, last_analyzed
from user_tables
where table_name = 'T_SAMPLE';
NUM_ROWS BLOCKS LAST_ANALYZED
----------------------------------
脚本4 新建表统计信息收集情况
那咋办?我们用set autotrace on 的方式来跟踪SQL的执行计划,如下:
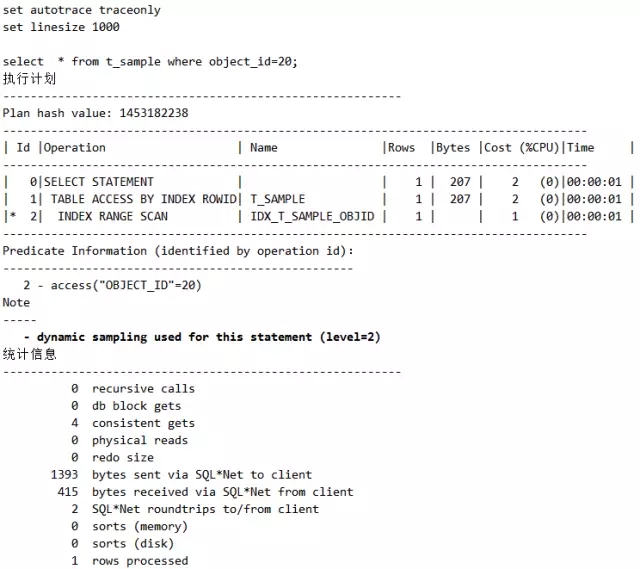
脚本5 未收集统计信息会进行动态采样
请注意看这个dynamic sampling used for this statement (level=2),这是啥呢?这就是动态采样,当一张表是新建表时,Oracle只好动态地收集这个表的相关信息。然后等到晚上10点,再将其收集到数据字典中。
我们可以继续做,比如手工收集统计信息:
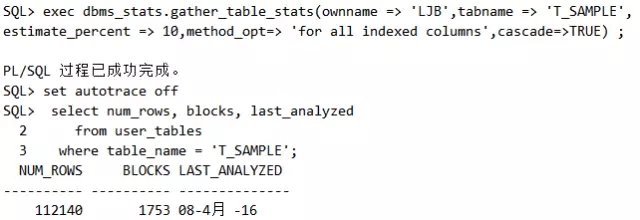
此时我们再跟踪SQL的执行计划,情况就变化了:
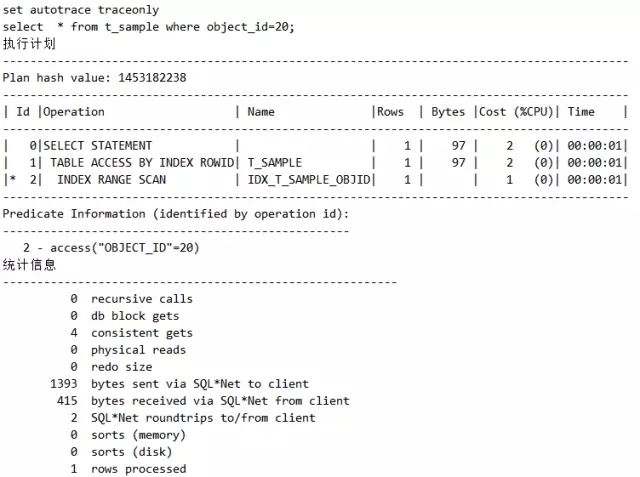
脚本6 收集统计信息后动态采样消失
有什么新发现?没错,dynamic sampling关键字不见了!
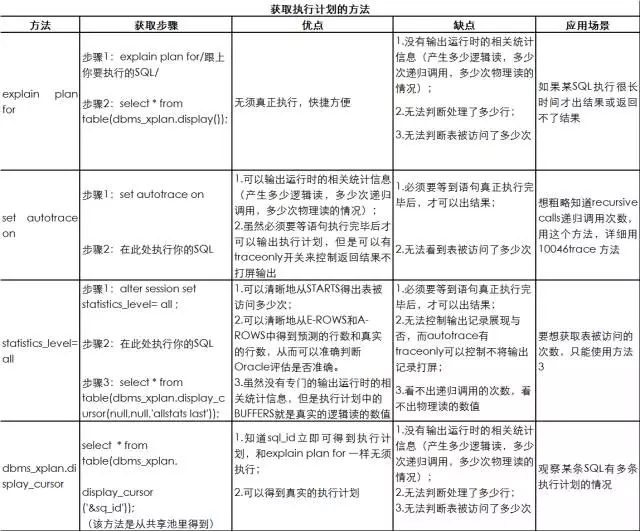
前面大家看到set autotrace on关键字,这是获取执行计划的方法。实际上,在Oracle里获取执行计划的方法有6种。这听起来是不是有些吓人?实际上这些方法各有侧重点,下面一一细看这些方法。

(1)explain plan for获取
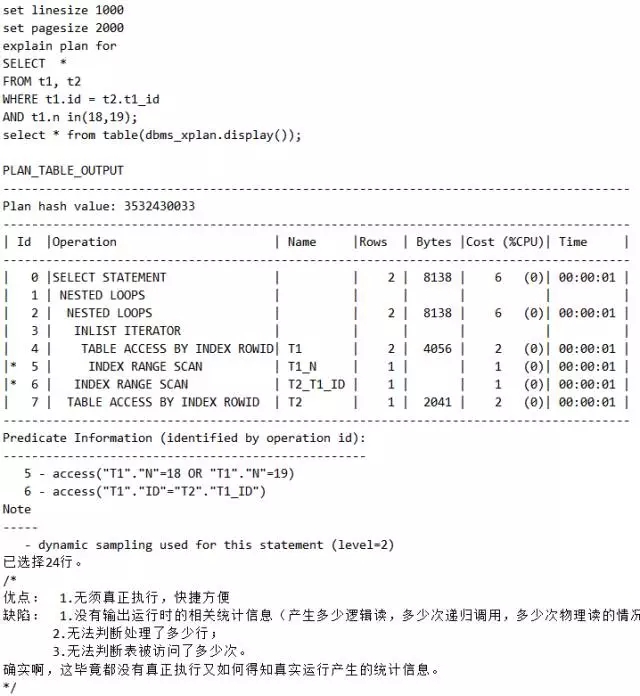
脚本7 explain plan for获取执行计划
(2)set autotrace on
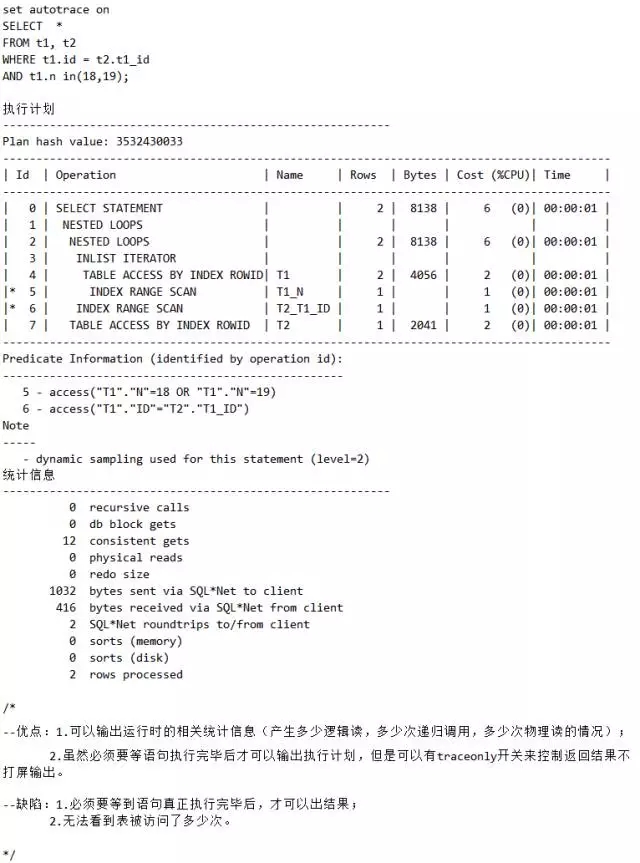
脚本8 set autotrace on获取执行计划
(3)statistics_level=all

脚本9 statistics_level=all获取执行计划
(4)dbms_xplan.display_cursor获取

脚本10 dbms_xplan.display_cursor获取执行计划
(5)事件10046 trace跟踪
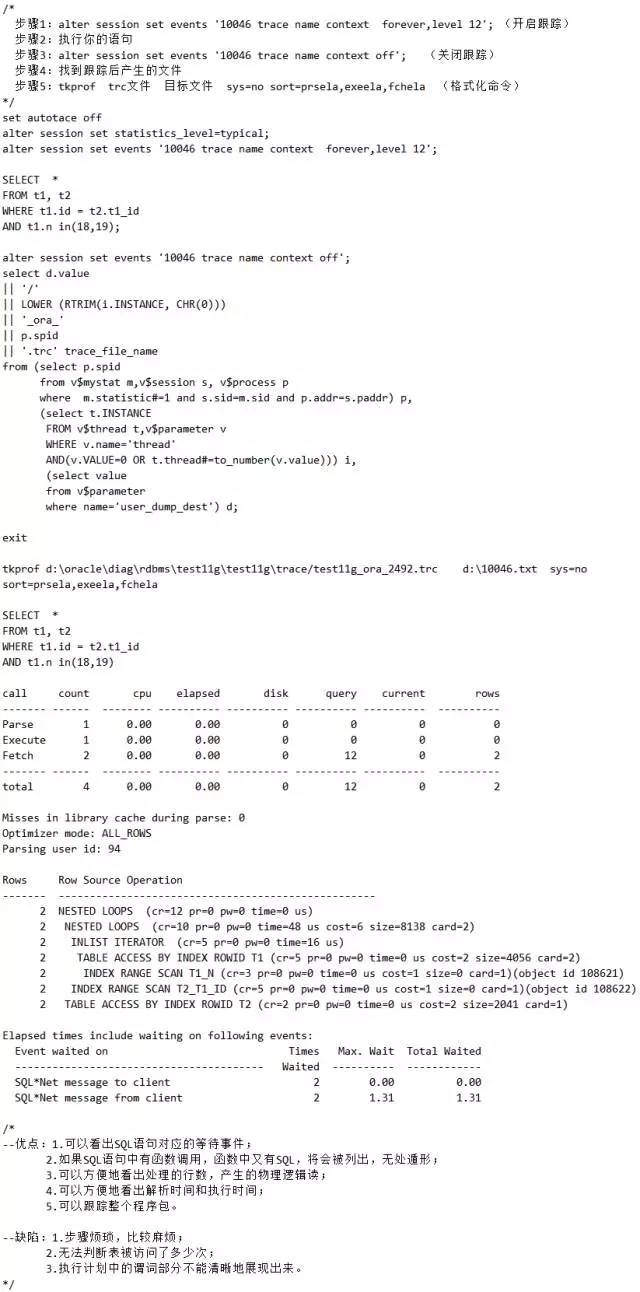
脚本11 10046 trace 获取执行计划
(6)awrsqrpt.sql
*
步骤1:@?/rdbms/admin/awrsqrpt.sql
步骤2:选择你要的断点(begin snap 和end snap)
步骤3:输入你的sql_id
*/
脚本12 awrsqrpt.sql调用获取执行计划

如果某SQL执行很长时间才出结果或返回不了结果,这时就只能用方法1。
跟踪某条SQL最简单的方法是方法1,其次就是方法2。
如果想观察某条SQL多个执行计划的情况,只能用方法4和方法6。
如果SQL中含函数,函数中又套SQL等,即存在多层调用,想准确分析只能用方法5。
要想确保看到真实的执行计划,不能用方法1和方法2。
要想获取表被访问的次数,只能使用方法3。
续表

二、读懂SQL计划的关键
前面讲了关于执行计划和统计信息的一些基础知识,其实真正要读懂执行计划,并不是一件容易的事,首先要善于利用获取执行计划的工具。下面将介绍如何使用这些经典工具,如下图所示:

其次要了解执行计划中Oracle是如何一步一步执行的,我们要做到像Oracle一样去思考。这似乎很难,不过当你从最简单的单独型、联合型开始学习之后,你就会发现,其实这些都很容易。
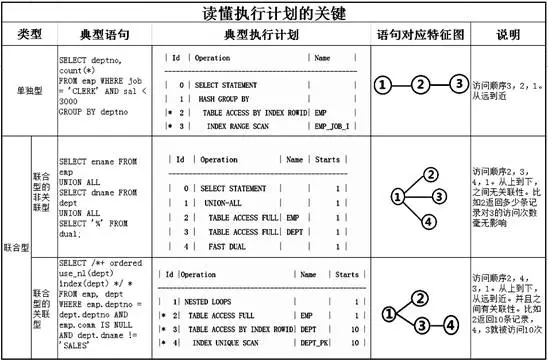
关于执行计划,最重要的一点是要读懂执行的顺序,只有这样,才可以像Oracle一样思考问题。而执行的顺序到底是什么呢?是从远到近,还是从上到下呢?这里我们先定义两种类型:单独型、联合型。首先我们来看看单独型。

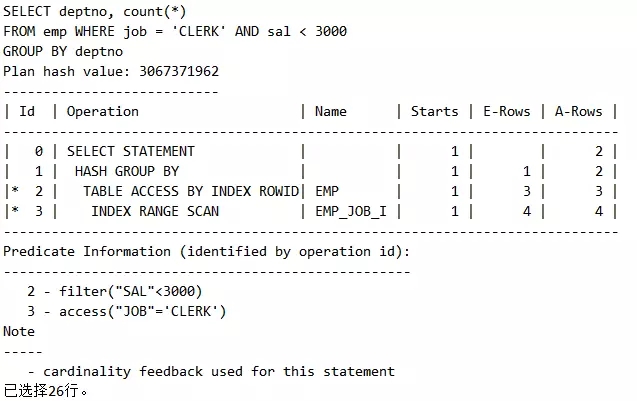
请看下面SQL执行计划Id=3处,通过索引定位JOB='CLERK',然后观察Id=2处,通过rowid回到表中得到sal等其它列,然后根据sal<3000的条件再过滤部分数据。最后完成了deptno动作,请看Id=1处。
脚本13 单独型执行计划的例子
我们把这种执行计划称之为单独型,有一种父子的关系,如下图所示。执行顺序为Id=3,Id=2,Id=1,由远到近地执行。注意看,执行计划中Id=1, Id=2, Id=3有一定的偏移哦,这就是单独型的特征。


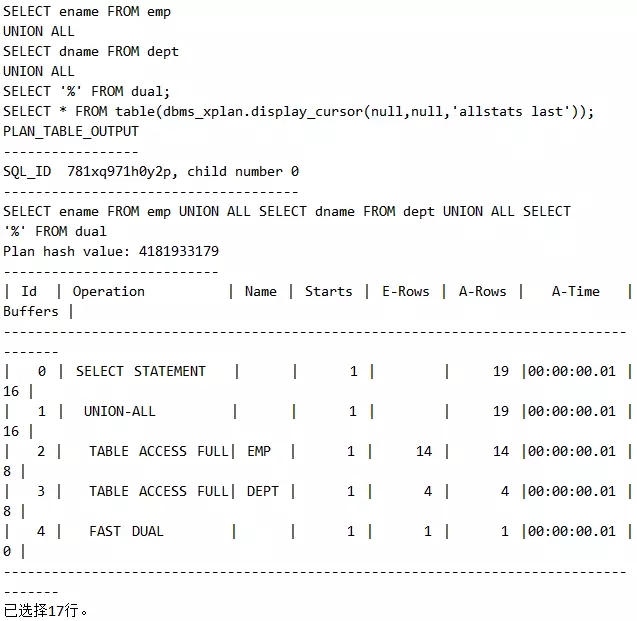
联合型还分为非关联的联合型和关联的联合型,请看下列执行计划,Id=2, Id=3, Id=4三处的语句互相独立,没有谁是谁的孩子,这时执行的顺序就是Id=2, Id=3, Id=4依次进行。
(1)联合型的非关联型
脚本14 联合型的非关联型
下图是我们根据Id描绘的图,这就是典型的联合型。注意看,执行计划中,Id=2 Id=3, Id=4是对齐无偏移的,这就是联合型的特征。
这里顺序很显然是Id=1,Id=2,Id=3,Id=4。请大家注意,Id=2,Id=3,Id=4三处,互相之间毫无关系,这就是非关联的联合型。请注意看Id=2处的A-rows为14,可是Id=3处的Starts依然为1,表示只访问一次,和这个14的结果毫无关系。

(2)联合型的关联型
① 联合型的关联型(NL)
接下来的例子比较经典,请看Id=2和Id=3处,这里显然是联合型,不过我们再观察,Id=2处的A-Rows为10,Id=3处的Starts=10,说明EMP访问的结果集返回多少条,DEPT表就被访问多少次,这是有关联的,这就是联合型的关联型。请回头再看看联合型的非关联型,应该可以明白。
这里其实是联合型和单独型混合的执行计划,请看Id=3和Id=4处,这显然就是单独型,顺序是先Id=4,再Id=3。

脚本15 联合型的关联型
具体的示意图如下,顺序一目了然:Id=2,Id=4,Id=3,Id=1。其中Id=2返回的条数将会决定Id=3和Id=4执行的次数。
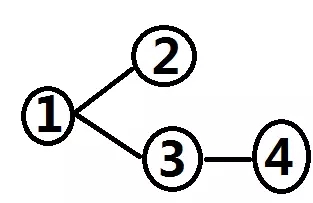
现在,无论多复杂的示意图,我们应该都不会害怕了,都可以轻易地画出执行顺序了。接下来我们对知识进行一个拓展,其实关联型的联合型不见得就一定如同NESTED LOOPS模式一样,驱动表返回多少条,被驱动表就被访问多少次。还有FILTER的模式也是关联型的联合型,具体就有差异,接下来请看下面的例子。
② 联合型的关联型(FILTER)
我们认真观察会发现,Id=2处的A-rows为14,但是Id=3处的Starts却为3,这是何故呢?
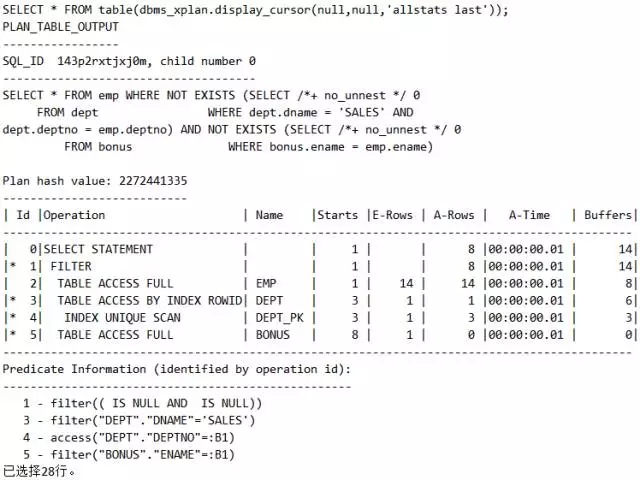
脚本16 联合型的关联型(FILTER)
原因分析:为什么执行计划中Id=3的地方STARTS为3次,因为虽然有8条记录,但是不重复的只有3个(ACCOUNTING、RESEARCH、SALES)。
SELECT dname, count(*)
FROM emp, dept
WHERE emp.deptno = dept.deptno
GROUP BY dname;
DNAME COUNT(*)
-------------------------
ACCOUNTING 3
RESEARCH 5
SALES 6
接下来我们看看为什么执行计划中ID=5的地方STARTS为8次,这是因为返回8条记录。
SELECT ename
FROM emp
WHERE NOT EXISTS (SELECT /*+ no_unnest */ 0
FROM dept
WHERE dept.dname = 'SALES' AND dept.deptno = emp.deptno);
ENAME
------
SMITH
JONES
CLARK
SCOTT
KING
ADAMS
FORD
MILLER
原来如此,FILTER其实对比NESTED LOOPS是一种优化,驱动表返回多少条不重复记录,被驱动表被访问多少次,请注意“不重复”三个字。接下来还有UPDATE的执行计划,由于其和FILTER类似,这里就不做说明了。
③联合型的关联型(UPDATE)

脚本17 联合型的关联型(UPDATE)
Update的情况和Filter类似,这里就不再阐述了。不过接下来要描述的树形查询差异就很明显了。
④联合型的关联型(CONNECT BY WITH FLITERING)
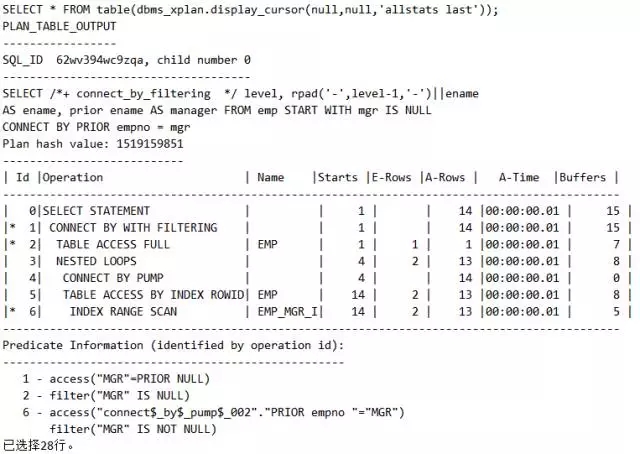
脚本18 联合型的关联型(CONNECT BY WITH FLITERING)
原理分析:为什么执行计划中ID=4的地方STARTS为4次,因为完成4次执行。
第1次得到KING。
第2次得到 JONES、BLAKE、CLARK。
第3次得到 SCOTT、 FORD、 ALLEN、 WARD、 MARTIN、 TURNER、 JAMES、 MILLER。
第4次得到 ADAMS、 SMITH。
为什么执行计划中ID=6的部分执行14次,因为返回14条记录。
SELECT /*+ connect_by_filtering */ level, rpad('-',level-1,'-')||ename AS ename, prior ename AS manager
FROM emp
START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr;
LEVEL ENAME MANAGER
------------------------------
1 KING
2 -JONES KING
3 --SCOTT JONES
4 ---ADAMS SCOTT
3 --FORD JONES
4 ---SMITH FORD
2 -BLAKE KING
3 --ALLEN BLAKE
3 --WARD BLAKE
3 --MARTIN BLAKE
3 --TURNER BLAKE
3 --JAMES BLAKE
2 -CLARK KING
3 --MILLER CLARK
已选择14行。
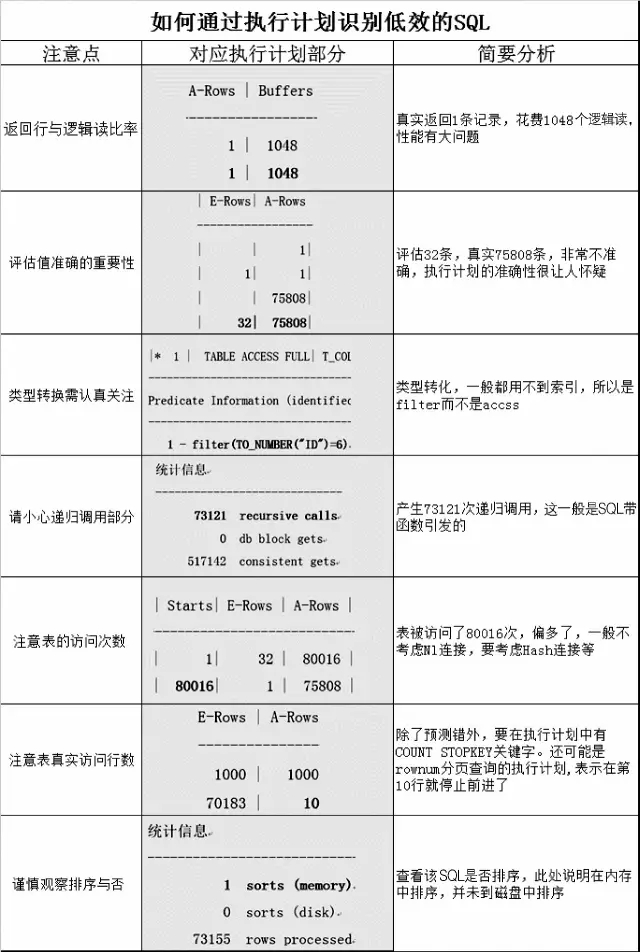
三、从案例辨别低效SQL
如何快速判断SQL执行计划是否高效,其实这是一个知识和经验的完美结合过程。我们可以敏锐地从输出执行计划的关键字中看出执行计划好坏的蛛丝马迹,下面一起来看看都有哪些维度。


脚本19 返回行与逻辑读比率
说明:总共获取1条记录(A-ROWS),产生1048次逻辑读(Buffers),这个肯定有问题!

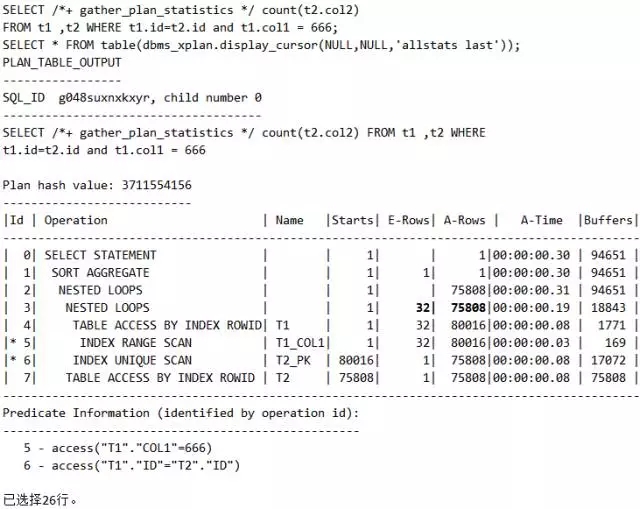
脚本20 评估值准确的重要性

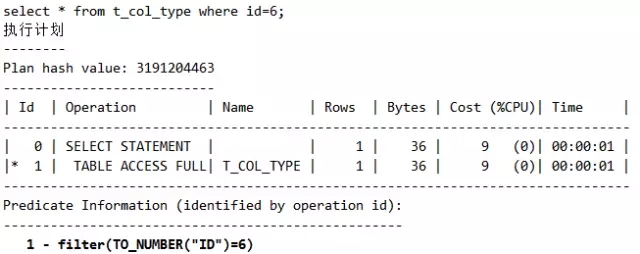
脚本21 类型转换需认真关注

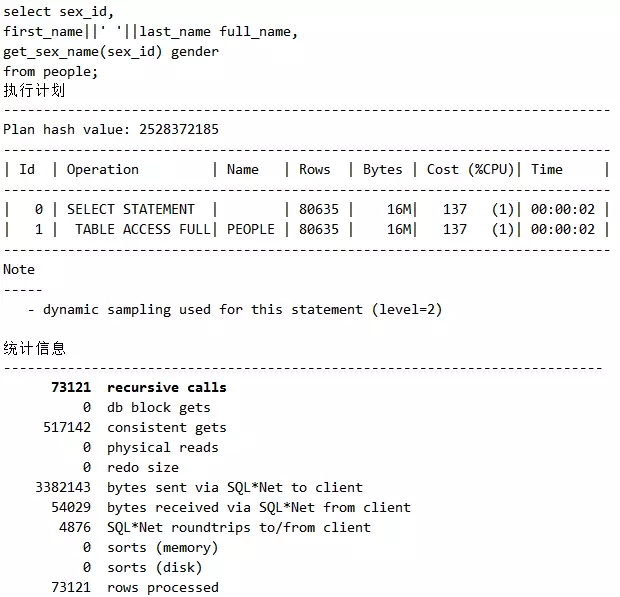
脚本22 请小心递归调用部分


脚本23 注意表的访问次数

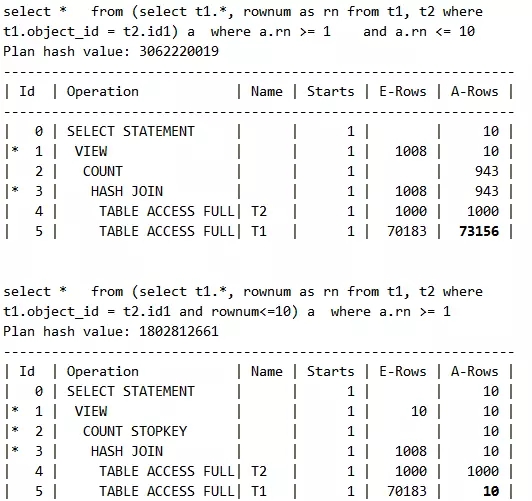
脚本24 注意表真实访问行数

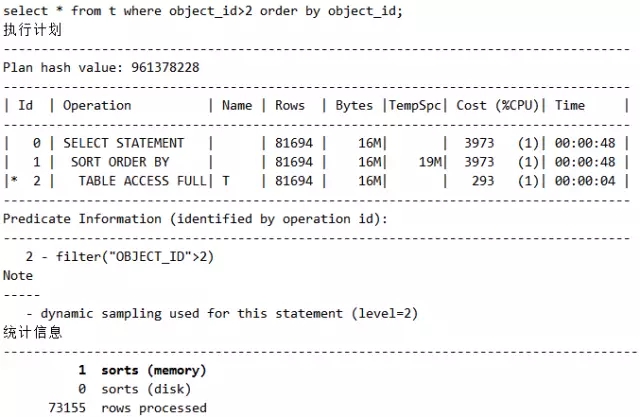
脚本25 谨慎观察排序与否
◆ 近期活动 ◆
Gdevops全球敏捷运维峰会·北京站

报名链接:
http://www.bagevent.com/event/643565#website_moduleId_60229
峰会官网:www.gdevops.com







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721