
转载声明:本文为DBA+社群原创文章,转载必须连同本订阅号二维码全文转载,并注明作者名字及来源:DBA+社群(dbaplus)。
Flash 闪存卡的性能远超SAS 盘,所以在数据库中使用广泛。 但是online redo log 是否应该存放在闪存卡上一直是有争议的话题。今天由DBA+社群合肥发起人戴明明来谈一谈他通过理论和实际的实验去测试这个问题。
专家简介

戴明明
DBA+社群合肥发起人
Oracle ACE Associate,中国 ORACLE 用户组(ACOUG) 核心成员,中国浙江应用中间件与数据库用户组成员。 超过7年的DBA经验,在Oracle 高可用性方面有一定的经验积累,擅长Oracle数据库诊断、性能调优,热衷于Oracle 技术的研究与分享。从2014年开始一直在研究基于PCIe 闪存卡的数据库解决方案。
Alternative and Specialised Options as to How to Avoid Waiting for Redo Log Synchronization (文档 ID 857576.1)
在这篇MOS的文章中,提到如下一句话:
Oracle 建议把redo log 放在SSD上,这样可以减少延时,提升同步写的性能。
Troubleshooting: 'Log file sync' Waits (文档 ID 1376916.1)
在这篇MOS文章中,Oracle 的建议如下。
Recommendations
Work with the system administrator to examine the filesystems where the redologs are located with a view to improving the performance of IO.
Do not place redo logfiles on a RAID configuration which requires the calculation of parity, such as RAID-5 or RAID-6.
Do not put redo logs on Solid State Disk (SSD)
Although generally, Solid State Disks write performance is good on average, they may endure write peaks which will highly increase waits on 'log file sync'.
(Exception to this would be for Engineered Systems (Exadata, SuperCluster and Oracle Database Appliance) which have been optimized to use SSDs for REDO)
Look for other processes that may be writing to that same location and ensure that the disks have sufficient bandwidth to cope with the required capacity. If they don't then move the activity or the redo.
Ensure that the log_buffer is not too big. A very large log_buffer can have an adverse affect as waits will be longer when flushes occur. When the buffer fills up, it has to write all the data into the redo log file and the LGWR will wait until the last I/O is completed.
这里Oracle 不建议把redo log 放在SSD上,但也补充到,Exadata 系统的redo 是存放在SSD上的。
MOS上也提到如下一句:
Oracle 的意思是说SSD 写性能很好,但是可能某个时刻出现写高峰,从而导致更高的log file sync。 注意这里是may,是可能。
Flasn 闪存卡使用的Flash 介质有三种型号:SLC,MLC,TLC。
民用级的SSD 采用的是MLC和TLC,而采用TLC,容量大,因受民用价钱的约束,民用级的SSD, OP值都比较低,一般在10%以内,当满盘写之后,性能会下降,并且写放大系数也会比企业级的SSD高,在这种情况下,确实可能出现oracle 说的may的可能性。
但企业级的PCIE Flash采用的是MLC,OP值可以达到27%,OP值高,写放大系数可以控制的更低,大的OP可以给闪存卡提供更好的性能。所以在这种情况下,不会出现oracle 说的write peaks。
在MOS 中,Troubleshooting: 'Log file sync' Waits (文档 ID 1376916.1)。 Oracle 提到XD 上redo log 是放在SSD盘的。然后有另外一篇MOS文章:
Using 4k Redo Logs on Flash and SSD-based Storage (文档 ID 1681266.1)
现在的存储都支持4k的扇区,而上一代存储多采用512 bytes的扇区。 扇区即每次最小IO的大小。
4k 扇区有两种工作模式:native mode 和 emulation mode。
1)Native mode,即4k模式,物理和逻辑的block大小一样,都是4096 bytes。 但native mode 的缺点是需要操作系统和软件(如DB)的支持。 Oracle 从11gR2 之后,就支持4k IO操作,操作系统方面, Linux 内核在2.6.32 之后都支持4k IO操作。
2)emulation mode:也称512e。 在该模式下,物理块还是4k,但逻辑块是512 bytes。 这种模式主要是为了向后兼容。 但在该模式下,底层物理还是4k进行操作,所以就会导致Partial I/O 和4k 对齐的问题。
在emulation mode下,每次IO操作大小是512 bytes,底层存储平台的IO操作必须是4k大小,如果要读512 bytes的数据,实际需要读4k,是原来的8倍,这个就是partial IO。 另外在512 bytes 写的情况下,实际也是先读4k 的物理block,然后更新其中的512 bytes的数据,在把4k 写回去。 所以在emulation mode下,增加的工作会增加延时,降低性能。
在Oracle 数据库的文件中,默认情况下,datafile的block 是8KB,控制文件是16KB,所以都没有partial IO的问题,唯有online redo log,默认是512 bytes,存在partial IO的问题。
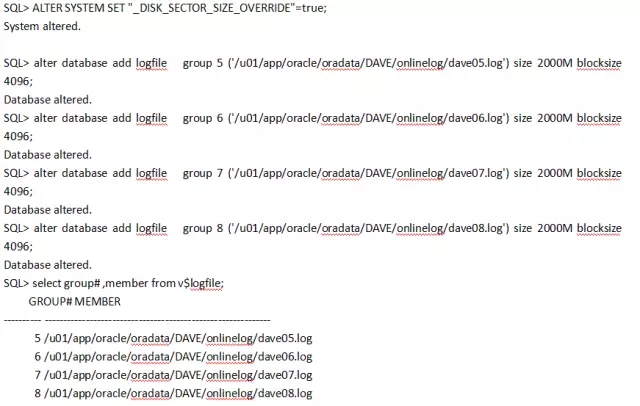
默认情况下,Oracle online redo log file 是512 bytes 的block size。 从Oracle 11gR2 开始,可以修改redo log 的Blocksize 为512,1024,4096。
如:alter database add logfile group 5 size 100m blocksize 4096;
当然,前提条件是底层的存储支持4k 扇区。 对于native mode 的存储,修改redo log block size 没有问题。 如果是emulation mode存储,物理上4k扇区,但逻辑上是512 bytes 扇区,那么修改就可能会触发如下错误:
只要确认底层存储物理是4k的扇区,那么可以设置_disk_sector_size_override参数为true,来覆盖扇区的设置。该参数支持动态修改:
ALTER SYSTEM SET “_DISK_SECTOR_SIZE_OVERRIDE”=”TRUE”;
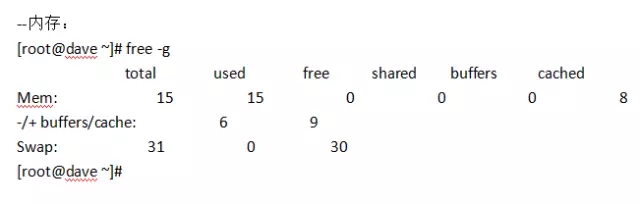

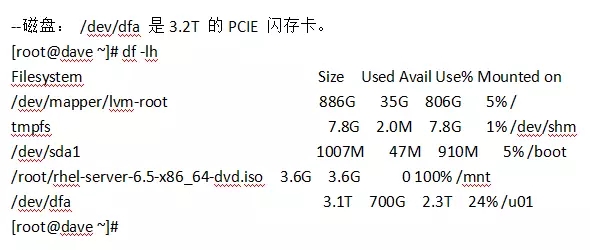
测试工具: HAMMER DB
测试数据量: 5000个warehouse
--数据库: 12.1.0.2
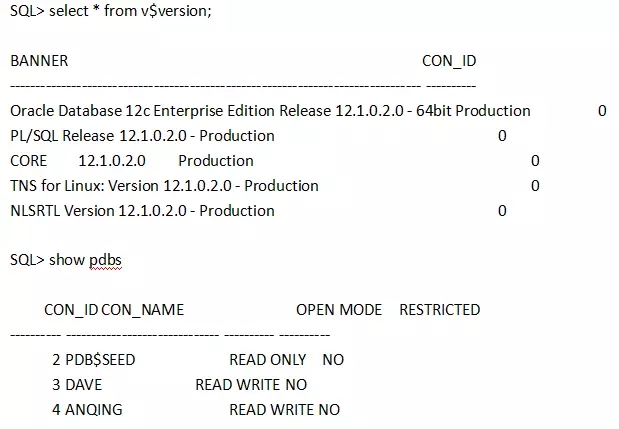
测试用的PDB是ANIQNG。
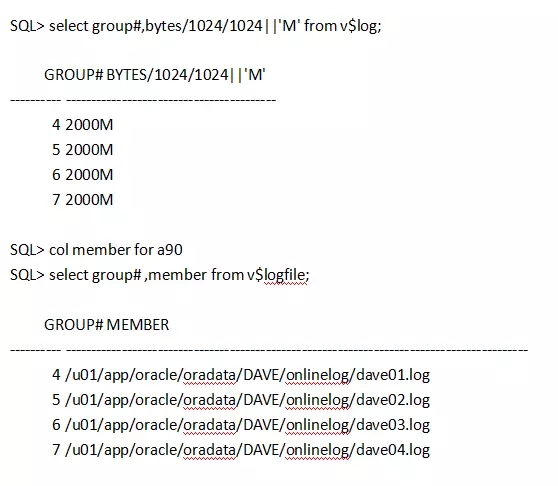
3.2.2 先创建一个快照
SQL> execute dbms_workload_repository.create_snapshot();
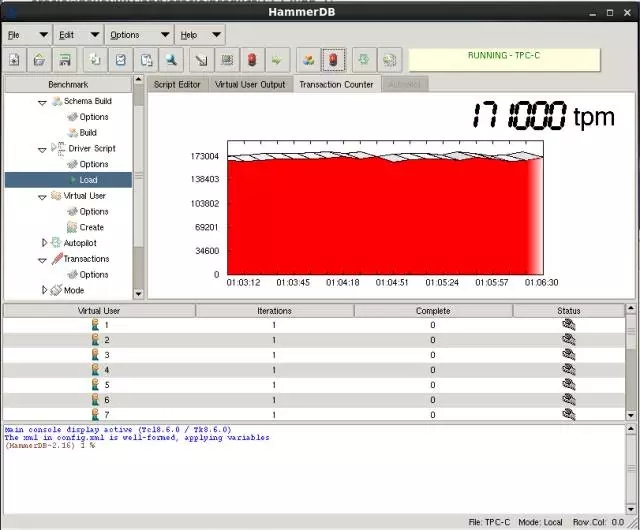
在创建一个AWR 快照:
SQL> execute dbms_workload_repository.create_snapshot();
PL/SQL procedure successfully completed.
生成AWR 报告:
SQL>@?/rdbms/admin/awrrpt.sql
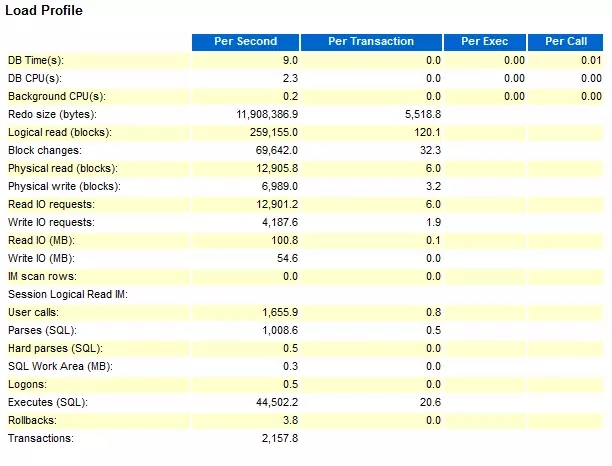
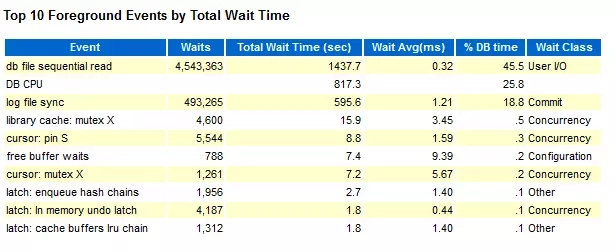
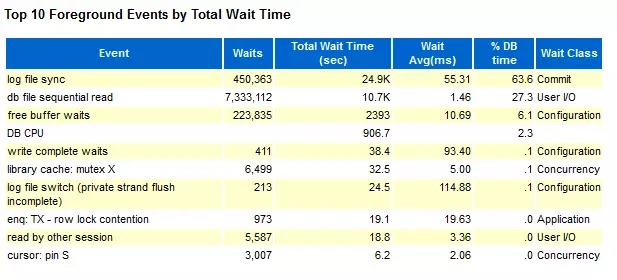
我们这里只看2个部分:Load Profile 和 Top 10 Foreground Events by Total Wait Time

SQL> execute dbms_workload_repository.create_snapshot();
在之前同等的20个virtual 用户下,根本无法压到最大值:
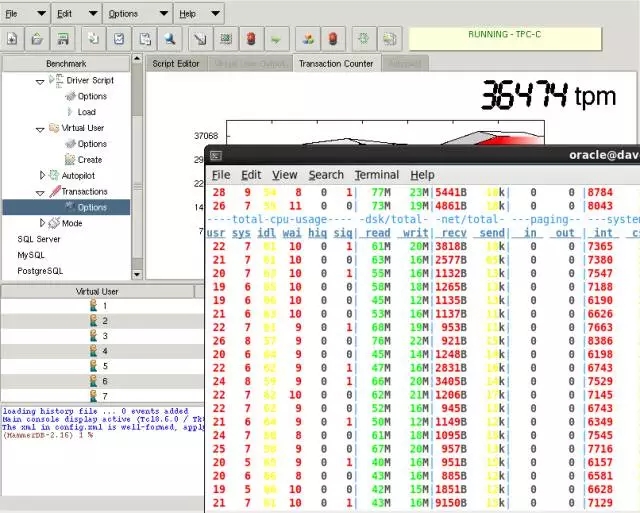
修改成120个virtual user:
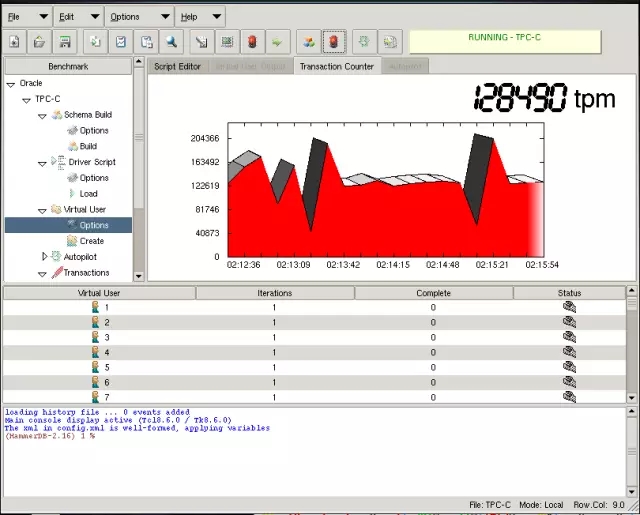
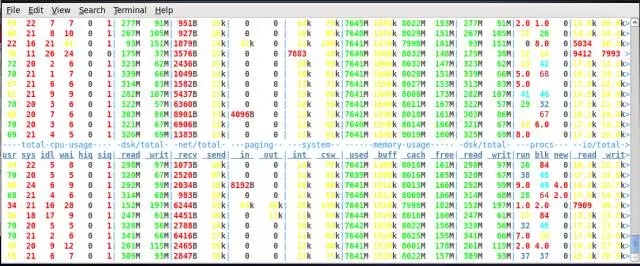
在创建一个AWR 快照:
SQL> execute dbms_workload_repository.create_snapshot();
PL/SQL procedure successfully completed.
SQL> @?/rdbms/admin/awrrpt.sql
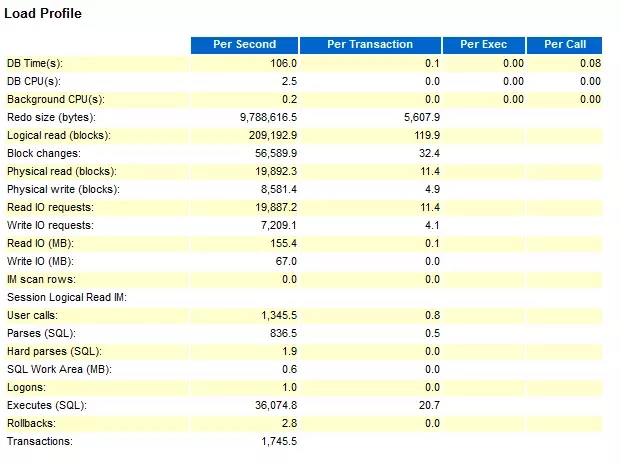
把redo log 迁移到PCIE SSD上,然后使用4k的blocksize。

我们这里确实是4k的sector size。
SQL> execute dbms_workload_repository.create_snapshot();
使用20个virtual 进行压测:
SQL> execute dbms_workload_repository.create_snapshot();
PL/SQL procedure successfully completed.
SQL> @?/rdbms/admin/awrrpt.sql
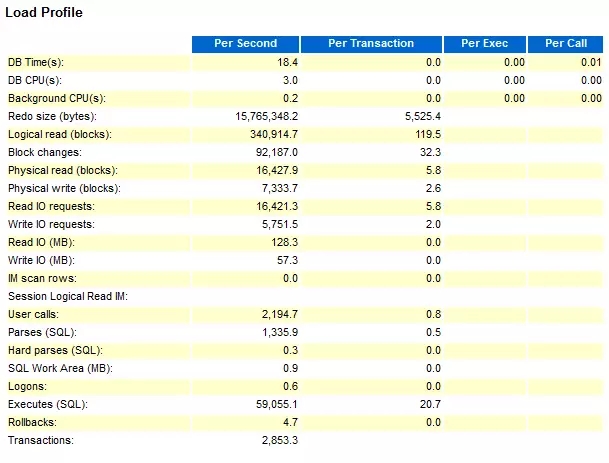
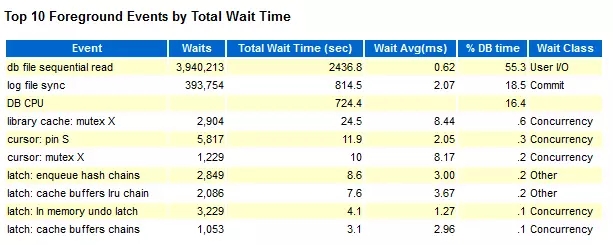
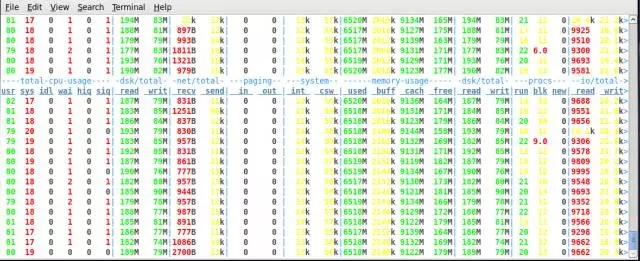
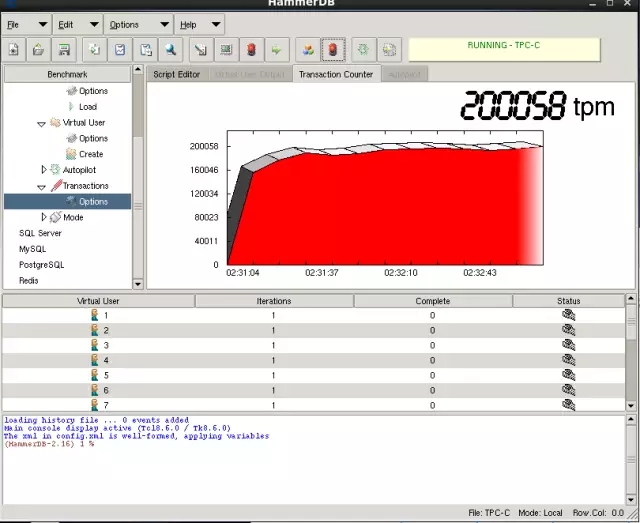
测试压力的方法,就是把系统的CPU 压倒100%,看最大的TPM,最终对比数据如下表:
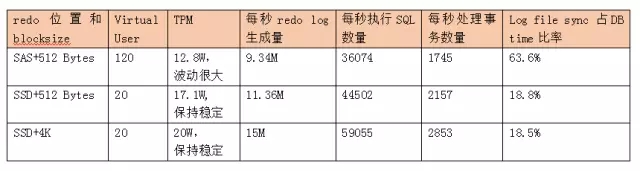
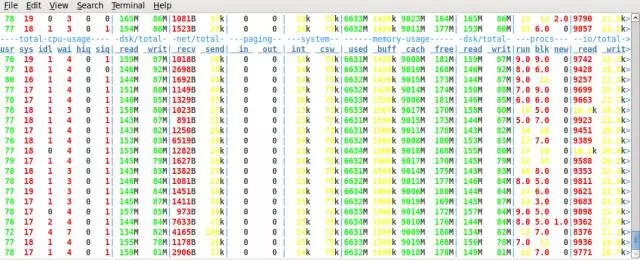
从这个数据对比,可以看出,在使用SSD的情况下,log file sync占DB time的比率下降非常明显,从63.6% 到18.5%,性能也有明显的提升。 并且从测试结果看,在使用SAS 盘的情况下,TPM 波动更加明显,这个可以直接从Hammer DB的测试截图看出。
总结:根据实测数据,在Oracle 数据库下,使用4k 的online redo log 加企业级的PCIE Flash闪存卡可以明显提升系统的性能,而不用担心使用PCIE Flash对性能的不利影响。
即日起,凡是推送在【DBAplus社群】平台的文章,阅读量超过1000,该文章作者可获得赠书一本。大家如有好的干货文章也可以向我们的订阅号投稿,投稿邮箱:1017465571@qq.com。近期赠书有:白鳝《思想的天空》、杨志洪《Oracle核心技术》……
小编精心为大家挑选了近日最受欢迎的几篇热文:
回复001,看丁俊的《【重磅干货】看了此文,Oracle SQL优化文章不必再看!》;
回复002,看吕海波的《去不去O,谁说了算?》;
回复003,看胡怡文《PG,一道横跨oltp到olap的梦想之桥》;
回复004,看郭耀龙《假事务之名,深入研究UNDO与REDO》;
回复005,看宋日杰《Oracle后台专家解决library cache锁争用的终极武器》;
回复006,看周俊《被埋没的SQL优化利器——Oracle SQL monitor》;
回复007,看袁伟翔《揭秘Oracle数据库truncate原理》;
回复008,看郑晓辉《存储和数据库不得不说的故事》;
回复009,看楼方鑫《数据库中间层,这样定制可能更好》;
回复010,看黎君原《扒一扒Oracle数据库迁移中的各种坑》。
DBA+社群是全中国最大的涵盖各种数据库、中间件及架构师线条的微信社群!有100+专家发起人,建有15大城市微信群,6大专业产品群,多达10000+跨界DBA加入队伍。每天1个热议话题,每周2次线上技术分享,不定期线下聚会与原创专家团干货分享,更多精彩,欢迎关注dbaplus微信订阅号!

扫码关注
DBAplus社群
超越DBA圈子,连接的不仅仅是DBA








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721