
来源:三墩IT人 订阅号
作者:唐小丹(浙江移动数据库管理员)
卢进文(新炬网络资深DBA)
又一个核心系统去IE成功了,操作系统从AIX换为Linux,Oracle数据库从11.2.0.3升级到11.2.0.4,整体CPU利用率稳定运行在10%之内。
但是,有一个停复机业务的SQL犹如脱缰的野马,执行时间从几毫秒变到几百秒(执行时间的变化过程中,执行计划没有发生改变,表中的数据有变化),变成升级过程的插曲。本文将详细分析这个SQL的优化过程,展示一个不符合Oracle优化器的SQL语句,扭转起来到底有多费神。
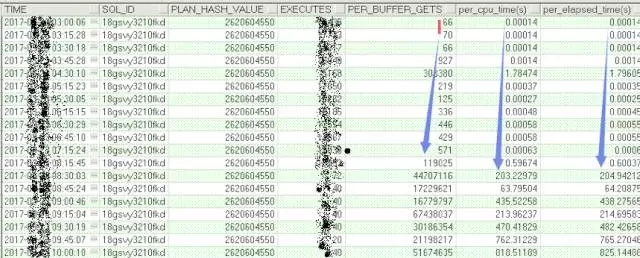
我们可以看到,在8点15这个snapshot,15分钟内执行了10000多次(一万多次复机),之后每15分钟处理效率极低,只有40次。
语句(下述语句均经过脱敏)并不复杂:
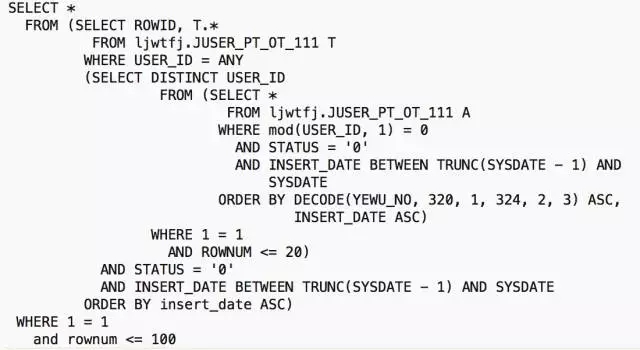
迁移之前,正确的执行计划如下,使用了USER_ID作为关联条件,做一个NL嵌套循环即可完成查询:
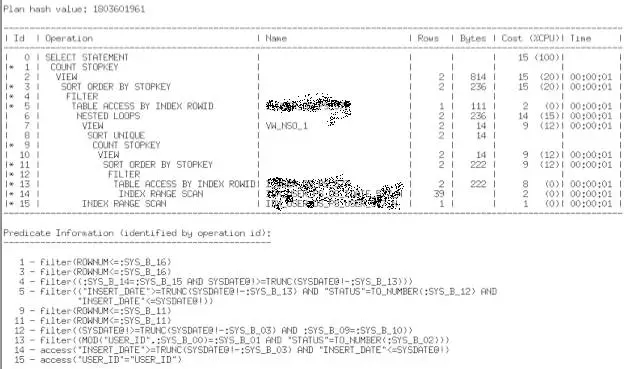
迁移之后,执行计划变了,执行时间从几毫秒暴涨到几十秒上百秒。哪里发生问题了?

对该语句做一个10053跟踪,看看中间出了什么问题?
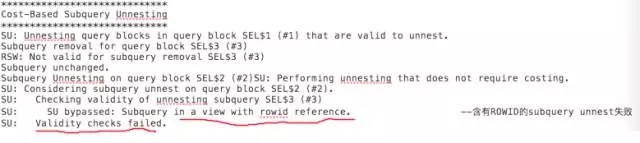
在《踩坑CBO,解决那些坑爹的SQL优化问题》一文中,丁俊做了CBO优化器组件的描述:
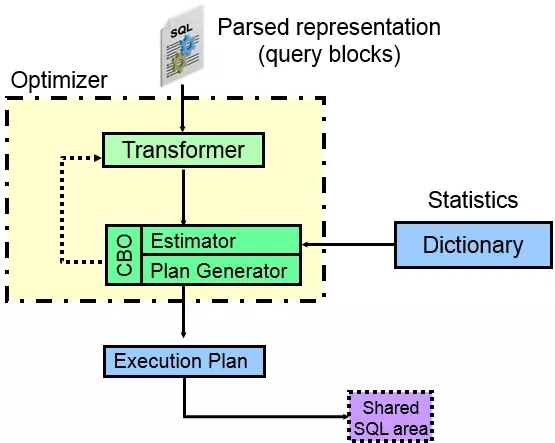
从上图可以看出,一条SQL进入Oracle中,实际上经过解析会将各部分进行分离,每个分离的部分独立成为一个查询块(query blocks),比如子查询会成为一个查询块,外部查询又是一个查询块,那么Oracle优化器要做的工作就是各查询块内部走什么样的访问路径更好(走索引、全表、分区?),其次就是各查询块之间应该走什么样的JOIN方式以及JOIN顺序,最终计算出哪种执行计划更好。优化器的核心就是查询转换器、成本估算器以及执行计划生成器。
这次遇到的语句之所以执行计划没有走“正确”:本质是subquery unnest没有做成功,导致FILTER失败。而失败的根源是触犯了CBO的底线,跟山东辱母案一样。
简单说,由于子查询中包含rowid和distinct,所以视图合并查询失败先执行外层查询,外层查询的每一行驱动执行一次子查询,因为外层条件返回行数高达数万条,因此,子查询被驱动查询数万次,效率低下。
通常情况,这种时候我们就会祭出SQL Profile大杀器,在不修改SQL语句的情况下把SQL优化好。这通常是管用的,但是在11.2.0.4里,它跟段誉的六脉神剑一样存在失灵的可能性。很不巧的是,我们运气实在有点好,从少商剑用到少泽剑,所有“原本”可以使用的Profile都失灵了。
最后查询转换是由对应参数控制,在我们的优化过程中尝试了SQLTXPLORE,把FIX control接近1200个参数都打开关闭了一下,也没有发现正常执行计划。一般Oracle已经fix的BUG,是可以通过XPLORE发现并解决的,然而这条SQL没有发现正常计划。
因此,这个问题是Oracle为了避免在类似这种SQL中写ROWID故意限制的,那么对开发编写SQL有什么启发呢?要符合规范,特别是关键字最好要用别名。
接下来我们谈谈SQL的改写。
传统的方法都不能用,那么我们就尝试着改写SQL语句。语句本身并不复杂,操作都在一张表内完成(要查询2次),从停复机接口表中抽出最近一天产生的停机用户,排除去重,给出ROWID,复机服务根据ROWID去复机。
所以兄弟们想到一个临时解决方案,将第一个子查询结果物化:
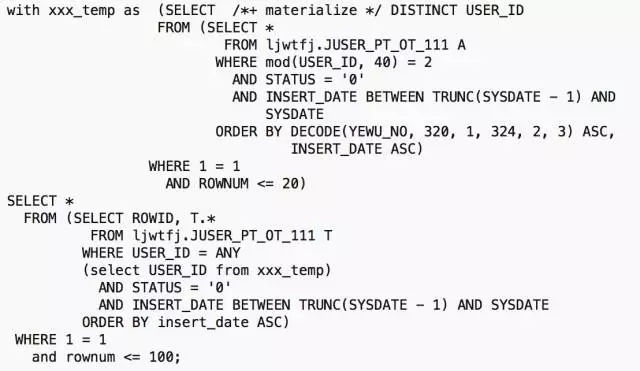
执行计划如下:
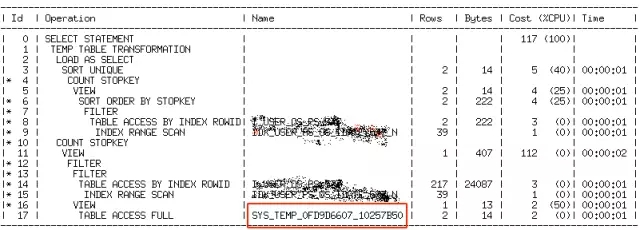
这个执行计划跟没有改写前的形式很像,区别在于将子查询结果物化,进而提升了语句效率。
实际生产运行看,基本效率没有问题,但是在业务小高峰,存在一定积压的时候,性能会有些许异变。
Oracle MOS文章Query Referencing ROWID ofSubquery With Join Fails With ORA-01445(文档 ID1929880.1)中,详细说明了开发商原来的SQL语句写法存在问题。
A rowid is only defined for individual rows in a table, so it is not legal to select a rowid from a subquery unless each row from that subquery can be guaranteed to be uniquely associated with exactly one row in one table. Therefore, the subquery may have only one item in its FROM list; that item must also have a rowid; and the subquery must not use DISTINCT, GROUP BY, or anything else that might gather multiple rows into one.
简单翻译一下:rowid仅仅用来明确识别表中的特定行,因此除非能保证从子查询中查询出的每一行能够与表中的一条记录严格一一匹配,否则在子查询中使用rowid是不合法的(不符合Oracle要求的)。也就是说,子查询输出中能且仅可以有一个输出项,这个输出项可以有一个rowid,并且这个子查询中不可以有DISTINCT、GROUP BY或其他可能会将多个行变为一个行的关键字。
很不幸,我们的语句里,既有ROWID还有DISTINCT。
参考Oracle给出的解决方案:

参照,对原生产SQL语句做第二次改写(重复部分忽略)。改成JOIN方式,避免子查询相关查询转换,同时里层用别名,外层用ROWID交付给其他服务接口使用:
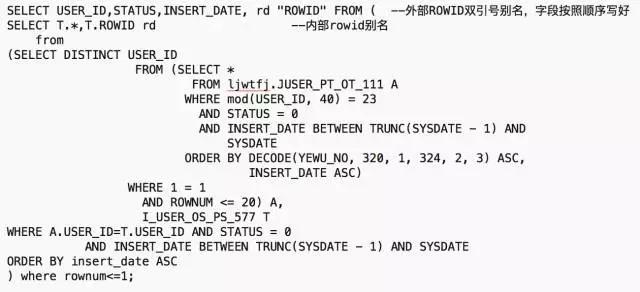
执行计划:
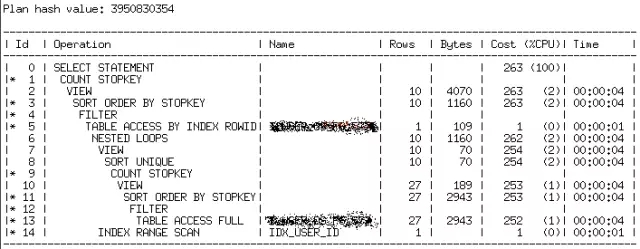
我们可以看到,执行计划重新用回了NL嵌套循环。COST值有变化,其中一个表用到了全表扫描,但是应为表大小总量可控,整体效率性能依然很高。
波波同学深入研究了业务逻辑,提出了一种创新思路,整个SQL建议改写为:

只对停复机接口表做一次查询,该表数据量本身不大(记录数通常在10万以内),是否走索引效率都会很高。
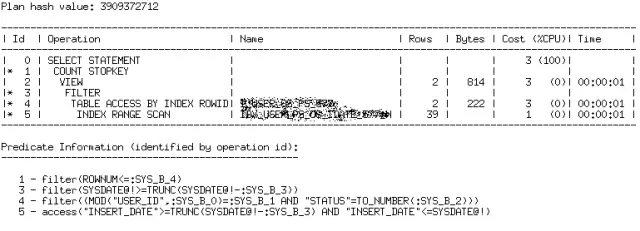
所以优化器理解起来就更容易,执行计划也就更简单,效率更高。
修改语句的逻辑是,在没有业务积压的情况下,复机顺序不严格按照停机顺序进行,只要处理得够快,复机时间早或者晚个几毫米对最终用户来说是无感知的。
这个案例说到这里,有没有给你带来什么启示?
从问题发生到结案,DBA团队尝试过索引重建、统计信息搜集、HINT、重建表、SQL profile绑定等多种方式,最终通过SQL改写解决。
对于DBA来说,不仅仅要懂得数据库的基本原理、基本技术,还应该更加多往业务端走一走,懂业务的DBA会更加高效、卓越。
我们之所以要去开发SQL审核平台,初衷就是要让开发/应用程序的SQL语句书写更合规,更加按照符合数据库的优化器行为去做,将潜在问题扼杀在萌芽状态。
并且,只有通过大量类似的大规模客户案例的充实,才能让SQL审核平台越来越臻于完善,SQL审核的有效识别率从80%提升到90%,以及更多。
更深入地了解Oracle优化器,学习10053事件和hint,可以参考社群文章:
详细了解SQL审核平台,可以参考:








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721